🔴DBMS
💠1. SQL
1-1. SQL 기능에 따른 분류
- 데이터 정의어(DDL)
-> 테이블이나 관계의 구조를 생성하는데 사용하며,
Create, Alter, Drop문 등이 있다.- 데이터 조작어(DML)
-> 테이블에 데이터를 검색, 삽입, 삭제, 수정하는데 사용하며
SELECT, INSERT, DELETE, UPDATE 문 등이 있다.- 데이터 제어어(DCL)
-> 데이터의 사용 권한을 관리하는데 사용하며
GRANT, REVOKE 문 등이 있다.
1-2. 데이터 조작어 - 검색
- select 문의 구성 요소
select employee_id, last_name / *
from employees
where job_id = 'SA_REP'
select 속성이름(들)
from 테이블이름(들);1-3. 별칭
- as : 별칭, 알리아스
1-4. dual
- oracle에서 기본으로 제공하는 dummy table
- 오라클 자체에서 제공되는 테이블
- 간단하게 함수를 이용해서 계산 결과값을 확인 할 때 사용하는 테이블
- dual테이블은 사용자가 함수(계산)를 실행할 때 임의로 사용하는데 적합하다.
- 함수에 대한 쓰임을 알고 싶을때 특정 테이블을 생성할 필요 없이 dual 테이블을
사용하여 함수의 값을 리턴받을 수 있다.
💠2. JOIN(조인)
2-1. join이란
- 두 개 이상의 테이블을 서로 연결하여 데이터를 검색할 때 사용하는
방법으로 두 개의 테이블을 마치 하나의 테이블인 것처럼 보여주는 것이다.
2-2. join의 기본 사용 방법
- 두개의 테이블에 하나라도 같은 컬럼이 있어야 한다.
- 두 컬럼의 값은 공유 되어야 한다.
- 보통 조인을 위해서 기본키(Primary Key)와 외래키(Foreign Key)를 활용한다.
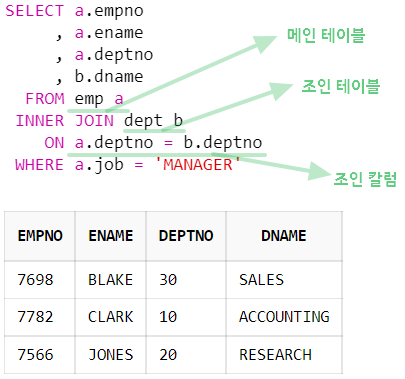
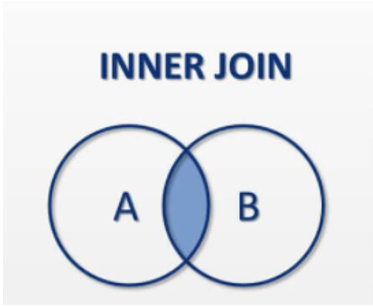
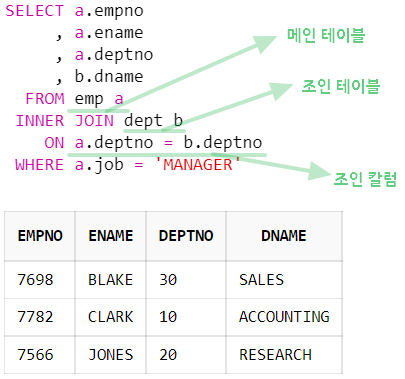
2-3. inner join
- 각테이블에서 조인 조건에 일치되는 데이터만 가져온다.
- inner join은 '교집합'이라고 말한다.
2-4. outer join
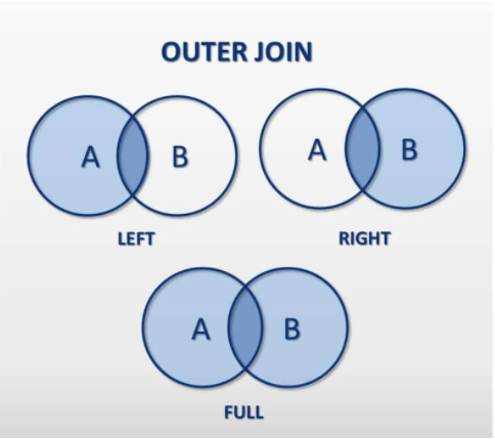
- 조인 조건에 일치하는 데이터 및 일치하지 않은 데이터를 모두 select한다.
- 조인 조건에 일치하는 데이터가 없다면 NULL로 가지고 온다.
- Outer Join은 inner join과는 다르데 주(main)테이블이 어떤 테이블인지가
중요하다. 그래서 어떤 테이블이 중심이 되느냐에 따라 다시
left outer join, right outer join, full outer join으로 세분 할 수 있다.- left outer join : 왼쪽 테이블이 중심
- rigth outer join : 오른쪽 테이블이 중심
- full outer join : 양쪽 테이블 모두가 중심
💠3. left outer join
select *
from tableA left outer join tableB
-> 왼쪽테이블 tableA가 기준이 된다
-> 조인 조건에 부합하는 데이터가 조인 당하는 테이블(오른쪽)에 있으면
해당 데이터를 가지고 오고, 부재하면 NULL로 select 된다.💠4. right outer join
select *
from tableA right outer join tableB
-> 오른쪽 테이블이 기준이 된다.
-> 조인 조건에 부합하는 데이터가 조인 당하는 테이블(왼쪽)에 있으면
해당 테이터를 가지고 오고, 부재하면 NULL로 select 된다.💠5. full outer join
select *
from tableA full outer join tableB
-> 양쪽 테이블 모두가 기준이 된다.
-> 조인 조건에 부합하는 데이터가 조인 당하는 테이블에 있으면
해당데이터를, 부재하면 NULL로 select된다.💠6. ANSI join vs ORACLE join
- SQL은 데이터베이스를 관리하기 위해 만들어진 프로그래밍 언어이며,
데이터베이스를 관리해주는 대부분의 DBMS들은 SQL사용한다. 물론, DBMS자체의
특수성 때문에 SQL의 사용법이 조금씩 다르기도 하지만, 큰 틀에선 나름대로의
보편성을 가지고 있다.- 이를 위해 미국 국립 표준 협회(ANSI)에서도 SLQ에 대한 보편적인 문법을
제시하고 있는데, 그것이 바로 ANSI Query이다.
💠7. 서브쿼리(subQuery)란?
- MainQuery에 반대되는 개념으로 이름을 붙인 것
- 메인쿼리를 구성하는 소단위 쿼리
- select, insert, delete, update 절에서 모두 사용 가능
- 서브쿼리의 결과 집합을 메인 쿼리가 중간 결과값으로 사용
- 서브쿼리 자체는 일반 쿼리와는 다를바가 없다.
중첩 서브쿼리
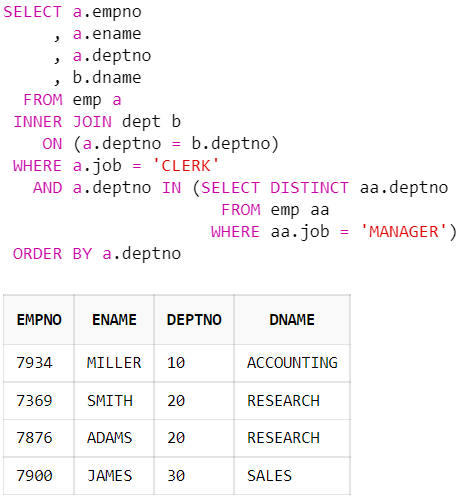
💠8. Oracle data type
8-1. 데이터 타입
- 데이터 타입이란 컬럼이 저장되는 데이터 유형을 말합니다. 기본 데이터 타입은
문자형, 실수, 소수 자료형 등의 여러 데이터를 식별하는 타입이다.
8-2. 문자 데이터 타입

8-3. 고정길이와 가변길이
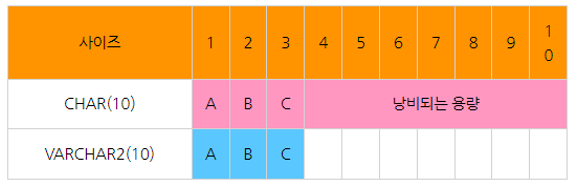
- 가변길이란 실제 입력된 데이터 길이에 따라서 크기가 변하는 것을 의미한다.
8-4. 숫자형 데이터 타입

- 숫자 타입은 대부분 NUMBER형을 사용한다.
- NUMBER(P,S) : P는 소수점을 포함한 전체 자릿수를 의미하고, S는 소수점 자릿수를
의미한다.NUMBER는 가변숫자 길이이므로 P,S를 입력하지 않으면 저장 데이터의
크기에 맞게 자동 조절된다.
입력값 타입 저장되는 값
123.89 NUMBER 123.89
123.89 NUMBER(3) 124
123.89 NUMBER(3,2) 오류
123.89 NUMBER(4,2) 오류
123.89 NUMBER(5,2) 123.89
123.89 NUMBER(6,1) 123.98-5. 날짜 데이터 타입

- 일반적으로 DATE를 사용한다.
💠9. DDL(Data Definition Lanuage)
- 데이터의 구조를 정의하기 위한 테이블 생성, 삭제 같은 명령어
- CREATE : 테이블 생성
- DROP : 테이블 삭제
- ALTER : 테이블 수정
- TRUNCATE : 테이블에 있는 모든 데이터 삭제
💠10. 데이터 조작어(Data Manipulation Language)
- 데이터 조회 및 변형을 위한 명령어
- select : 데이터 조회
- insert : 데이터 입력
- update : 데이터 수정
- delete : 데이터 삭제
10-1. insert
insert into 테이블명 values (값1, 값2, .. ); -> 전체컬럼 insert into 테이블명 (컬럼1, 컬럼2, ...) values (값1, 값2, ...); -> 특정컬럼
10-2. update
update 테이블명 set 컬럼1 = 값, 컬럼2 = 값, .. where 조건;
10-3. delete
delete 테이블명 where 조건;
10-4. DROP VS TRUNCATE VS DELETE
- DROP
-> 만들었던 테이블이 싹 삭제가된다. 존재 자체를 삭제
- TRUNCATE
-> 데이터만 통 삭제
-> 테이블이 삭제되는 명령어는 아니고 테이블 안에있는 모든 레코드들을
제거하는 명령어이다.
-> 테이블을 DROP 했다가 CREATE하는 행위
-> 모든 행을 삭제하는데에는 가장 빠르고 효율적인 방법이다.
- DELETE
-> 데이터를 골라서 삭제
-> DELETE는 조건에 해당하는 것만 지울 수도 있고 전체를 지울수도 있는
이유가 한줄 한줄 삭제하기 때문이다.
💠11. COMMIT
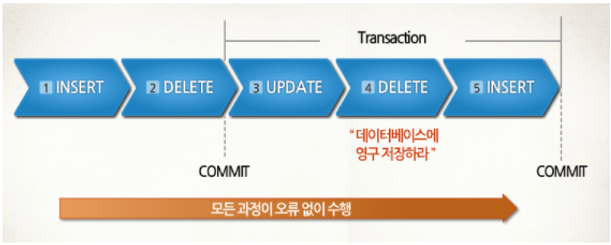
- 모든 작업을 정상적으로 처리하겠다고 확정하는 명령어이다.
- 트랜젝션의 처리 과정을 데이터베이스에 반영하기 위해서, 변경된 내용을
모두 영구 저장한다.- COMMIT 수행하면, 하나의 트랜젝션 과정을 종료하게 된다.
- TRANSACTION 작업은 하나의 작업단위. INSERT, UPDATE, DELETE 작업 내용을
DB에 저장한다.- 이전 데이터가 완전히 UPDATE된다.
- 모든 사용자가 변경한 데이터의 결과를 볼 수 있다.
💠12. ROLLBACK
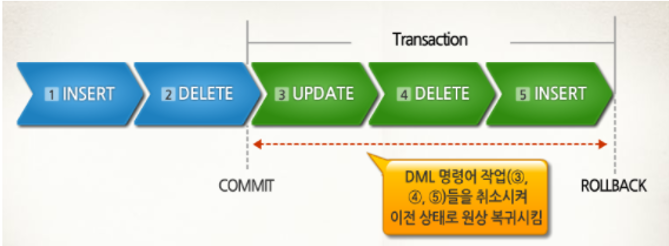
- 작업 중 문제가 발생했을 때, 트랜젝션의 처리 과정에서 발생한 변경 사항을
취소하고, 트랜젝션 과정을 종료시킨다.- 트랜젝션으로 인한 하나의 묶음 처리가 시작되기 이전의 상태로 되돌린다.
- TRANSACTION(INSERT, UPDATE, DELETE)작업 내용을 취소한다.
- 이전 COMMIT한 곳까지만 복구한다.
- 트랜젝션 작업 중 하나라도 문제가 발생하면, 모든 작업을 취소해야 하기
때문에 하나의 논리적인 작업 단위로 구성해 놓아야 한다.- 문제가 발생하면, 논리적인 작업의 단위를 모두 취소해 버리면 되기 때문이다.
💠13. COMMIT, ROLLBACK 명령어의 장점
- 데이터 무결성이 보장된다.
- 논리적으로 연관된 작업을 그룹화 할 수 있다.
💠14. 자동 commit, 자동 rollback 되는 경우
14-1. 자동 rollback 되는 경우
- 비정상적인 종료
14-2. 자동 commit
- DDL문(create, alter, drop, truncate)
- DCL문(grant, revoke) 사용권한
- insert, update, delete 작업 후, commit하지 않고 오라클 정상 종료시에
commit 명령어 입력하지 않아도 정상 commit 후 오라클 종료
💠15. 데이터 제어어(Data Control Language)
- 사용자에게 권한 생성 혹은 권한 삭제 같은 명령어
- GRANT : 권한 생성
- REVOKE : 권한 삭제
💠16. 컬럼속성(무결성 제약 조건)
- not null : 널값이 입력되지 못하게 하는 조건
- unique : 중복된 값이 입력되지 못하게 하는 조건
- check : 주어진 값만 허용하는 조건
- primary key(PK) : not null + unique의미
- foreign key(FK) : 다른 테이블의 필드(컬럼)을 참조해서
무결성을 검사하는 조건
16-1. primary key(PK)
- 기본키 역시 기본적인 제약조건들은 테이블을 생성할 때 같이 정의된다.
- 테이블당 하나만 정의가능하다.
- PK는 NOT NULL + UNIQUE의 기능을 가지고 있다.
- 주키 / 기본키 / 식별자 등으로 불리고 있다.
- 자동 INDEX가 생성되는데 이는 검색 키로서 검색 속도를 향상킨다.
💠17. Foreign key(외래키)
- 외래키, 외부키, 참조키, 외부 식별자 등으로 불린다. 흔히 FK라고 한다.
- FK가 정의된 테이블을 자식 테이블 이라고 칭한다.
- 참조되는 테이블 즉 PK가 있는 테이블을 모두 부모 테이블 이라고 한다.
- 부모테이블은 자식의 데이터나 테이블이 삭제된다고 영향을 받지 않는다.
- 참조하는 데이터 컬럼과 데이터 타입은 반드시 일치해야 한다.
- 참조할 수 있는 컬럼은 기본키(PK) 이거나 UNIQUE 만 가능하다.
(보통 PK랑 엮는다)
💠18. 삭제 옵션
18-1. on delete cascade
- 참조되는 부모 테이블의 행에 대한 delete를 허용한다.
- 즉, 참조되는 부모테이블 값이 삭제되면 연쇄적으로 자식 테이블 값
역시 삭제된다.
18-2. on delete set null
- 참조되는 부모 테이블의 행에 대한 delete를 허용한다.
- 부모테이블의 값이 삭제되면 해당 참조하는 자식테이블의 값들은
null값으로 설정된다.
💠19. View(뷰)
- view는 table과 유사하며, 테이블처럼 사용한다.
- 테이블과는 달리 데이터를 저장하기 위한 물리적인 공간이 필요하지
않은 가상 테이블이다.- 데이터를 물리적으로 갖지 않지만 논리적인 집합을 갖는다.
- 테이블과 마찬가지로 select, insert, update, delete명령 가능하다.
💠20. 시퀀스(Sequence)
- 연속적으로 번호를 만들어 주는 기능
- 자동으로, 순차적으로 증가하는 순번을 반환하는 데이터베이스 객체이다.
20-1. 시퀀스 구분
create sequence 시퀀스 이름 increment by n : 증가값을 설정, 2 -> 2씩 증가, 기본값 1 start with n : 시작값 설정, 기본값 1 maxvalue n : 시퀀스의 최대값을 설정 minvalue n : 시퀀스의 최소값을 설정 cycle/nocycle : 시퀀스를 반복적으로 사용하지를 설정 cache n : 시퀀스 속도를 개선하기위한 캐싱여부 지정
💠21. index
21-1. 인덱스란?
- 조회속도를 향상시키기 위한 데이터베이스 검색 기술
- 색인이라는 뜻으로 해당 테이블의 조회결과를 빠르게 하기 위해 사용
- 즉 인덱스가 필요한 이유는 인덱스를 생성해 줌으로써 조회 속도를
빠르게 할 수 있다.
21-2. 인덱스가 불필요한 경우
- 데이터가 적은(수천만건 미만) 경우에는 인덱스를 설정하지 않는게
오히려 성능에 좋다.- 조회보다 삽입, 수정, 삭제 처리가 많은 테이블
21-3. unique index
- 인덱스를 사용한 컬럼의 중복값들을 포함하지 않고 사용할 수 있는 장점
create unique index 인덱스명 on 테이블명(컬럼);
21-4. non-unique index
- 인덱스를 사용한 컬럼에 중복 데이터 값을 가질 수 있다.
create index 인덱스명 on 테이블명(컬럼);
개발자 박찬의 노트