Spark란?
Apache Spark는 대규모 데이터 병렬 처리 및 분석을 위한 오픈 소스 분산 컴퓨팅 엔진입니다.
Spark는 클러스터 환경에서 데이터를 병렬로 처리할 수 있게 해주며, 단일 노트북 환경에서 실행할 수도 있지만, 수천 대의 서버로 구성된 엄청난 규모의 클러스터에서도 실행할 수 있어 빅데이터를 빠르게 처리할 수 있습니다.
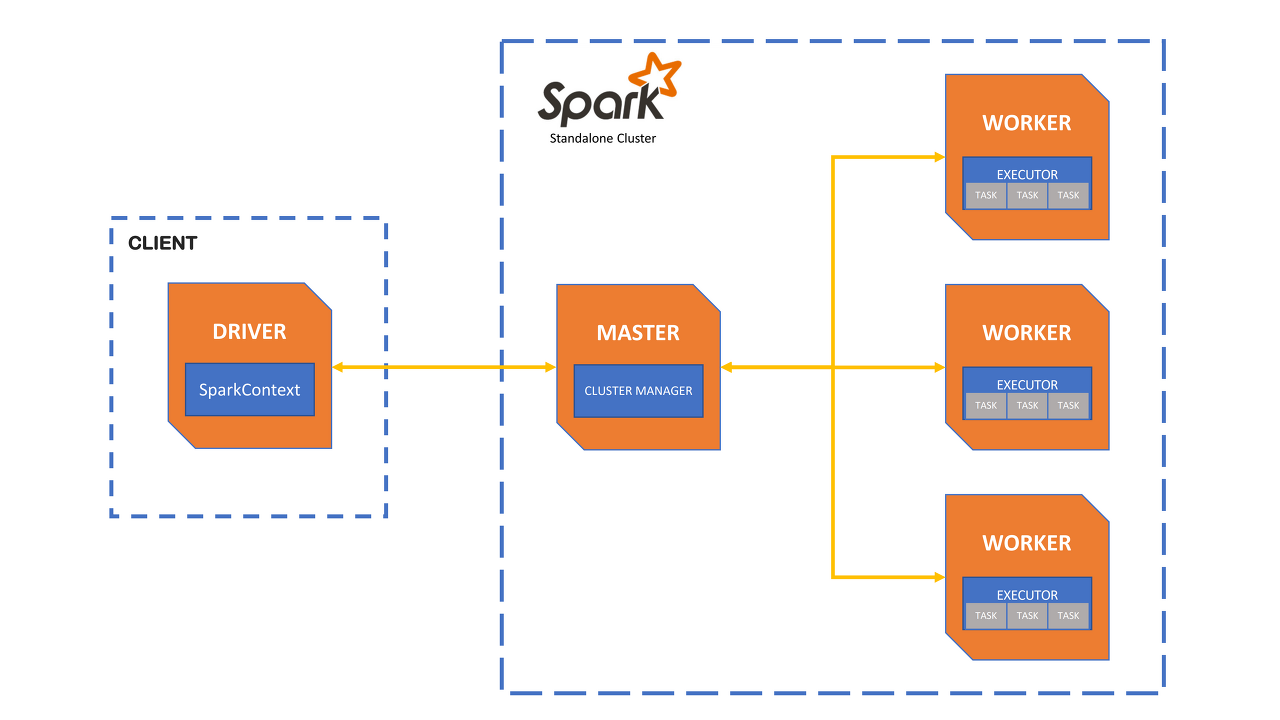
Spark의 기본 아키텍처
컴퓨터 클러스터는 여러 컴퓨터의 자원을 모아서 하나의 컴퓨터처럼 사용할 수 있게 만드는 것입니다.
클러스터를 구성한 후에는, 클러스터들의 작업을 조율할 수 있는 프레임워크가 필요한데, 스파크는 바로 그 역할을 하는 프레임워크입니다.
Spark 애플리케이션은 Driver 프로세스와 다수의 Executor 프로세스로 구성됩니다.
- Driver 프로세스: 클러스터 노드 중 하나에서 실행되며, 애플리케이션의 main() 함수를 실행합니다. 작업을 조율하고 클러스터 자원을 관리합니다.
- Executor 프로세스: 드라이버 프로세스가 할당한 작업을 수행하며, 클러스터 노드에서 실행됩니다.
PySpark란?
PySpark는 Apache Spark의 Python API로, Python 프로그래밍 언어를 사용하여 Spark의 기능을 활용할 수 있게 해줍니다. PySpark는 Spark의 모든 구성 요소(Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX)를 Python에서 사용할 수 있게 합니다.
PySpark의 도입 이유
- Python Pandas의 한계: Pandas는 메모리 내(in-memory) 처리 방식으로, 모든 데이터를 메모리에 적재한 후 처리합니다. 메모리 용량을 초과하는 대용량 데이터는 처리할 수 없습니다.
- 확장성: PySpark는 클러스터 환경에서 데이터를 분산 처리할 수 있어, 단일 시스템의 메모리 제한을 극복하고 훨씬 더 큰 데이터를 처리할 수 있습니다.
PySpark의 장점
- 확장성: 클러스터 환경에서 대규모 데이터를 효율적으로 처리할 수 있습니다.
- 호환성: Hadoop, HDFS, Hive 등 다양한 빅데이터 도구와 통합이 용이합니다.
- 인터랙티브 분석: Jupyter Notebook과 같은 도구와 결합하여 데이터 분석을 손쉽게 수행할 수 있습니다.
- 다양한 기능: 머신 러닝, 그래프 처리, 실시간 데이터 스트리밍 등 다양한 기능을 제공합니다.
PySpark의 단점
- 성능: 순수 Scala나 Java로 작성된 Spark 애플리케이션에 비해 성능이 떨어질 수 있습니다.
- 디버깅 어려움: 분산 환경에서의 디버깅이 어려울 수 있습니다.
- 복잡성 증가: 대규모 데이터 처리 및 분산 컴퓨팅의 복잡성을 완전히 숨길 수는 없습니다.
- 추가 설정 필요: Spark 클러스터 설정과 관리에 대한 추가적인 노하우가 필요합니다.
PySpark와 다른 도구 비교
Pandas
장점
-
데이터 분석의 사실상 표준
-
풍부한 기능
단점
-
메모리 제약
-
대규모 데이터 처리에 부적합
비교
1. PySpark는 분산 환경에서 대규모 데이터를 처리할 수 있어 더 큰 확장성을 제공합니다
PySpark.pandas:
pyspark.pandas는 Pandas API를 PySpark 환경에서 사용할 수 있게 해주는 라이브러리입니다.
이는 기존의 Pandas 사용자들이 PySpark의 분산 데이터 처리 기능을 손쉽게 사용할 수 있게 합니다.
하지만 멀티인덱스, 시각화, 고급 데이터 조작 기능(pivot, melt, stack/unstack 등)에 대한 기능이 제한적입니다.
또한 PySpark.pandas는 분산 처리에 최적화되어 있지만, 작은 데이터셋에 대해서는 오히려 성능이 떨어질 수 있습니다.
Hadoop MapReduce
장점
-
데이터 처리의 표준: Hadoop MapReduce는 분산 데이터 처리의 표준으로 오랜 기간 사용되어 왔습니다. 대규모 데이터셋을 병렬로 처리하는 데 있어 검증된 기술입니다.
-
큰 커뮤니티와 지원: 오랜 역사를 가진 만큼, 많은 사용자와 방대한 양의 문서가 존재합니다. 문제 해결과 최적화에 필요한 리소스를 쉽게 찾을 수 있습니다.
단점
-
복잡한 코딩: MapReduce 프로그래밍 모델은 복잡하고 저수준입니다. 데이터 처리 작업을 Map과 Reduce 함수로 분할해야 하므로, 개발자가 많은 노력을 기울여야 합니다.
-
느린 처리 속도: Hadoop MapReduce는 디스크 기반의 중간 데이터를 많이 생성하기 때문에 I/O 오버헤드가 큽니다. 따라서 실시간 처리나 빠른 응답이 필요한 작업에는 적합하지 않습니다.
비교
-
PySpark는 더 빠른 속도와 간결한 코드를 제공합니다. PySpark의 API는 고수준으로, 데이터 처리 로직을 더 직관적이고 간단하게 작성할 수 있습니다.
-
PySpark는 인메모리 컴퓨팅을 사용하여 중간 데이터를 메모리에 저장하고 처리하므로, Hadoop MapReduce보다 훨씬 빠르게 작업을 수행할 수 있습니다.
Dask
장점
-
Python 네이티브: Dask는 Python 생태계에서 자연스럽게 동작하며, Pandas와 NumPy와 같은 라이브러리와 쉽게 통합됩니다. Python 사용자에게 친숙한 인터페이스를 제공합니다.
-
유연한 병렬 컴퓨팅: Dask는 동적 태스크 스케줄링을 통해 유연한 병렬 컴퓨팅을 지원합니다. 사용자 정의 작업을 병렬로 실행할 수 있어 다양한 워크로드에 적합합니다.
단점
-
성숙도 낮음: Dask는 비교적 새로운 프로젝트로, 대규모 프로덕션 환경에서의 검증이 충분하지 않습니다. 일부 기능이나 안정성 면에서 Spark에 비해 미흡할 수 있습니다.
-
Spark만큼의 확장성 부족: Dask는 작은 클러스터나 로컬 머신에서 잘 동작하지만, 대규모 클러스터 환경에서는 Spark만큼의 확장성을 제공하지 못할 수 있습니다.
비교
-
PySpark는 대규모 데이터와 작업에 더 적합합니다. Spark의 인메모리 컴퓨팅과 최적화된 실행 엔진 덕분에, 매우 큰 데이터셋을 빠르게 처리할 수 있습니다.
-
PySpark는 Spark 생태계와의 통합이 잘 되어 있습니다. Spark SQL, MLlib, GraphX 등 다양한 구성 요소와 함께 사용할 수 있어, 종합적인 데이터 처리와 분석 작업에 유리합니다.
