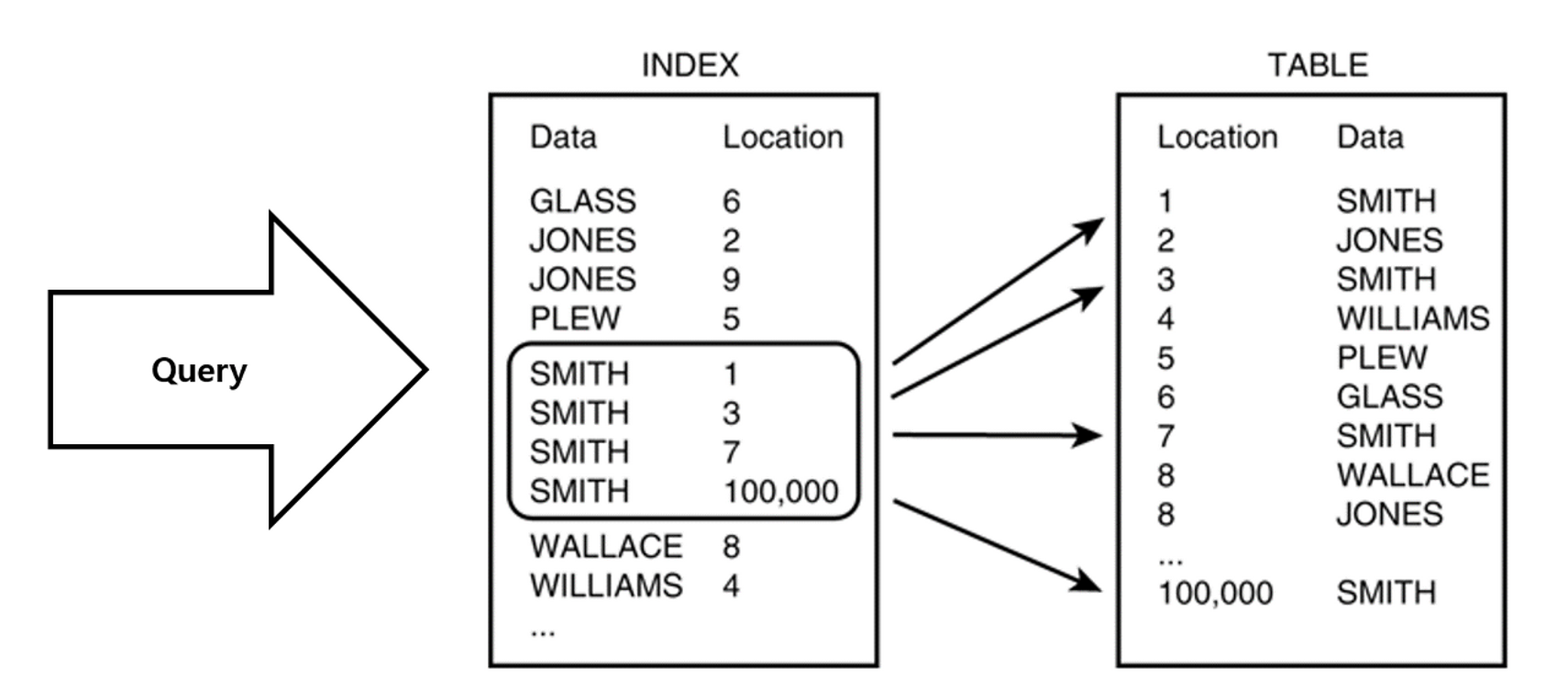
개요
- 오늘 면접질문으로 인덱스의 종류가 무엇이 있냐고 질문이 들어왔다.
- 솔직히 당황스러웠다. 클러스터 인덱스와 논클러스터 인덱스 혹은 유니크 인덱스에 관련한 질문이였는데
일반적인 인덱스의 동작 방식에 대해 설명을 준비했는데, 인덱스의 종류가 B 트리 인덱스, 유니크 인덱스 외에도 여러 종류가 있는 것이 아닌가..
- 일단 각설, 데이터 베이스의 인덱스의 경우에는 데이터 검색 성능을 최적화하기 위해 사용되는 DB 구조라고 한다.
종류
Clustered Index ( 클러스터드 인덱스 )

정의
- 데이터베이스 테이블의 물리적인 순서를 인덱스의 키 값 순서대로 정렬하는 것을 말한다고 한다.
특징
- 테이블 당 하나만 존재할 수 있으며, 데이터의 물리적인 순서와 인덱스의 순서가 같기 때문에 빠른 검색이 가능하다.
왜 테이블 당 하나의 클러스터드 인덱스만 사용이 가능한가?
- 테이블의 데이터가 하나의 순서로만 정렬될 수 있음을 의미한다.
- 인덱스 - 테이블의 일부로서, 실제 데이터와 함께 저장된다고 한다.
해당 방식의 장점?
- 실제 데이터와 함께 저장되어 불필요한 디스크 공간을 추가적으로 유발하지 않는다고 한다.
아직 이해가 안된다면..
- 전화번호부를 생각하면 된다고 한다. 전화 번호부의 경우 사람들의 성( last name - - ;) 에 따라 알파벳 순으로 정렬이 되어 있다.
- 만약
김씨를 전화번호부에서 찾고 싶은 경우, 전화번호부의김섹션으로 바로 이동 할 수 있다. - 해당 방식이 클러스터드 인덱스의 방식과 유사하다.
- 데이터베이스에서 클러스터드 인덱스를 사용하는 경우, 특정 기준( 성 ) 에 따라 데이터가 물리적으로 저장된다고 한다.
실습해보자
CREATE TABLE orders (
order_id INT NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (order_id)
);- 이게 뭐야 할것이다.
- 기본적으로 MySQL 에서 InnoDB 스토리지 엔진을 사용하는 경우
테이블은 기본 키를 클러스터드 인덱스로 자동으로 사용한다고 한다.- 그래서 pk 를 기준으로 하여 모든 데이터가 정렬되어 들어가게 되는 것이다.
- 또한 pk 외의 다른 값을 클러스터드 인덱스로 삼을 수 없어서, 사실 DB 설계할때는 생각할 일이 있을까 싶다.
Non-Clustered Index (논클러스터드 인덱스)

정의
- 데이터가 저장된 테이블과 별도의 공간에 위치하며,
- 테이블의 데이터와 다른 순서로 정렬 수 있다.
- 데이터의 위치를 가리키는 포인터를 사용하여 데이터를 찾는다고 한다.
특징
- 별도의 저장 공간
- 테이블의 데이터와는 별도의 공간에 저장됩니다.
- 인덱스가 테이블 데이터와 다른 구조를 가지고 있음.
- 여러 개 생성 가능
- 하나의 테이블에 여러 개의 논클러스터드 인덱스를 생성가능하다.
- 다양한 검색 요구 사항에 맞춰 여러 인덱스를 사용할 수 있다.
- 검색 최적화
- 논클러스터드 인덱스는 특정 컬럼에 대한 검색을 최적화가능하다.
- 클러스터도 인덱스로 커버되지 않는 쿼리에 유용하다.
언제 쓰나??
- 일단 SQL 에서 일반적으로 PK 를 거는 경우에는 클러스터드 인덱스로 구성되며, PK 외에 다른 유니크 인덱스가 존재하는 경우에는 논클러스터드 인덱스로 구성이 된다.
- 기본 키 외에 다른 열에 유니크 인덱스 등을 설정하는 경우, 논클러스터드 인덱스로 유니크 인덱스가 배치되게 됩니다.
- 논클러스터드 인덱스의 경우 별도의 인덱스 테이블에 (
추가된 인덱스 키 값)과 해당 데이터의 포인터를 저장하게 됩니다.
B-Tree Index (B-트리 인덱스)
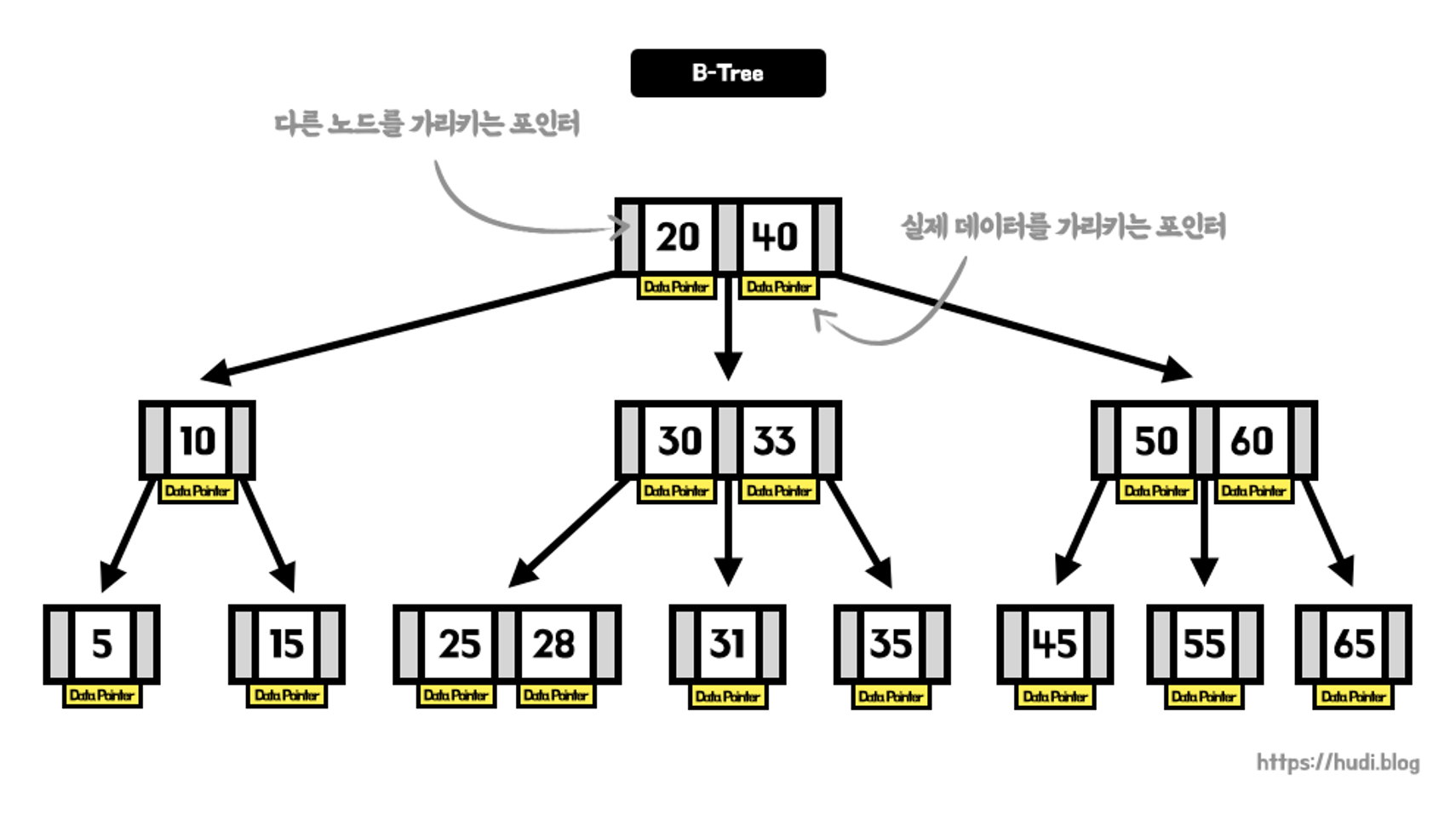
정의
- 균형 잡힌 트리 구조를 사용하는 인덱스 입니다.
- 데이터베이스에서 검색, 삽입, 삭제 등의 동작을 일정한 시간 안에 이루어질 수 있도록 설계됨.
- 모든 리프 노드가 같은 레벨이라!.
특징
- 균형 잡힌 구조
- 모든 리프 노드가 같은 깊이에 있어서 트리가 한쪽으로 치우치지 않는다.
- 효율적인 검색
- 키 값들이 정렬된 상태로 유지되어, 빠른 검색이 가능함.
- 동적인 데이터 조정이 된다.
- 데이터 삽입, 삭제 시 트리의 균형을 자동으로 맞추며 재조정함.
구조
- 루트 노드
- 트리의 최상위, 검색 시작점
- 브랜치 노드
- 중간 노드
- 다른 노드로의 포인터를 가지고 있으며, 해당 포인터를 통해 어느 노드로 이동할 것인지 가이드
- 리프 노드
- 트리의 가장 하단에 위치한다.
- 실제 데이터 또는 데이터의 포인터를 가지고 있다.
인덱스 작동 원리
- 검색
- 루트 노드 ~ 키 값 비교하면서 리프 노드까지 내려간다.
- 이진 탐색을 통해 원하는 데이터를 찾는다.
- 삽입
- 새로운 데이터를 삽입
- 노드가 가득차면 분할 → 균형을 유지한다.
- 트리 전체에 걸쳐서 발생함.
- 삭제 ( 이건 동작 방식이 엄청 어려움.. 사실 이걸로 부족함 )
- 데이터 삭제시 B - 트리는 노드의 최소 키 개수를 유지하기 위하여 노드를 병합하거나 키를 재분배한다.
Hash Index (해시 인덱스)
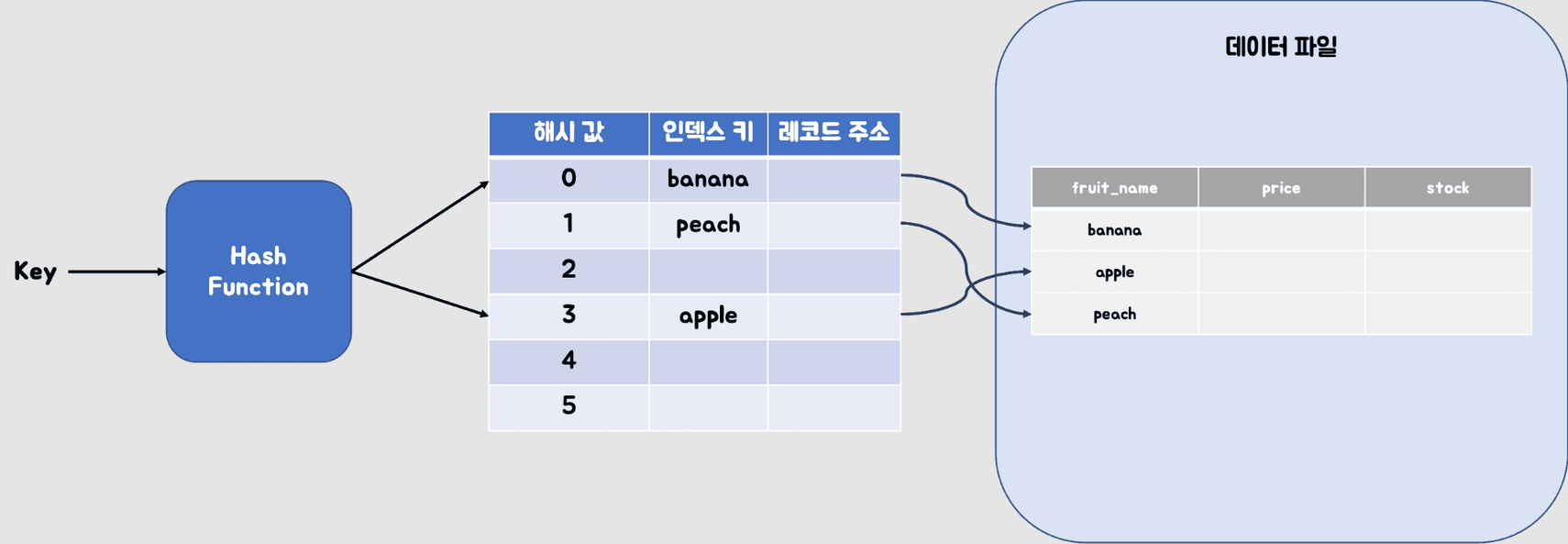
개요
- 데이터베이스에서 빠른 데이터 검색을 위해 사용되는 인덱스 유형 중 하나임.
- 해시 테이블 기반
- 특정 키 값을 해시 함수를 통해 해시 코드로 변환함.
- 해당 해시 코드를 사용하여 데이터를 저장하거나 검색함.
작동 원리
- 해시 함수
- 키 값을 입력으로 받아 고정된 크기의 해시 코드를 출력하는 함수입니다.
- 이 함수는 동일한 키 값에 대해 항상 같은 해시 코드를 반환한다.
- 해시 테이블
- 해시 코드를 인덱스로 사용하여 데이터를 저장하는 테이블
- 각 해시 코드는 테이블 내의 고유한 위치에 해당함.
- 충돌 처리
- 2 개 이상의 키 값이 동일한 해시 코드를 가지는 경우
충돌처리를 위한 매커니즘 - 체이닝, 오픈 어드레싱 이 있다.
- 위에 대해서는 별로 궁금하기 싫어서 나중에 공부하련다..
- 2 개 이상의 키 값이 동일한 해시 코드를 가지는 경우
장점
- 빠른 속도
- 상수 시간 접근
- 간단한 구조
- 해시 테이블 자체 구조나 단순함.
단점
- 순서 보장이 안됨
- 데이터의 순서대로 검색하거나 범위 검색이 안됨..
- 메모리 낭비
- 해시 테이블 크기가 고정되어 있어서, 데이터의 양에 따라 메모리를 효율적으로 사용하지 못할 수 있다고 함
- 충돌 처리
- 해시 기반이기에 충돌 처리를 생각해야함..
- 충돌이 많아지는 경우 해시 자료구조 특성상 검색 속도가 극단적으로 최악이면 O(n) 의 크기만큼 늘어나게 된다.
Bitmap Index (비트맵 인덱스)
동작
- 각각의 값 ( 성별 - (남 | 여) ) 에 대해 비트 배열을 생성함.
- 데이터베이스의 각 행은 비트 배열에서 하나의 비트로 표현된다고 한다.
- 해당 값이 행에 존재하면
1, 없으면0
예시
- 성별 속성에 대한 비트맵 인덱스는
- 테이블안에 성별 컬럼에 5개의 데이터가 [ 남 여 중성 남 여 ] 로 구성되어 있음.
남비트맵- 1 0 0 1 0
- 해당 테이블안에서 남자를 탐색하는 경우
비트맵 인덱스만을 보고도 1번 3번 4번 회원이 남자구나 ! 라는 사실을 알 수 있다.
- 비트 연산을 통하여 복합 쿼리사용가능
- 비트 연산을 통해
남자가 아닌 회원을 찾고 싶으면,남자비트맵 인덱스의 비트를 반전시킨후에, 나머지성별을 탐색할 수 있다.
- 비트 연산을 통해
Full-Text Index (전문 인덱스)
- 데이터베이스 내의 텍스트 데이터에서 키워드 검색을 가능하게 하는 인덱스의 유형이다.
- 대량의 텍스트 데이터에서 특정 단어나 문구를 빠르게 찾아내는 기능을 한다.
- 주로 뉴스 기사, 책, 블로그 글 등의 텍스트 데이터를 검색할 때 사용함.
동작 원리
- 텍스트 데이터를 분석해 중요한 데이터( 키워드) 를 추출한다.
- 이 단어들의 데이터베이스 내 위치를 기록하고,
- 검색 쿼리가 수행되는 경우 해당 인덱스를 사용해 빠르게 데이터를 찾는다.
예시
- 박상준 이펙티브자바 꿀팁 전수
박상준이펙티브자바꿀팁전수같은 키워드를 추출하고, 해당 키워드 들이 문서 내에서 어디에 위치하는지 기록함.
장점
- 게시물 내용같은 것을 효율적으로 검색이 가능
- 복잡한 쿼리 지원
-
문구 검색, 불용어 처리, 동의어 처리 등 복잡한 텍스트 검색의 요구사항을 지원한다고 함.
불용어
- 별로 중요하지 않은 단어
- ~
의, ~가등은 인덱싱에서 제외되거나 후순위로 밀린다고 함.
동의어 처리
- 검색어와 유사한 다른 단어들도 함께 검색 결과에 포함시키는 기능
스마트폰검색 ,휴대폰,모바일등의 동의어가 검색 결과에 포함될 수 있다.
-
단점
- 디스크를 사용하기에..
- 저장 공간을 많이 사용함..
- 업데이트 비용이 큼
- 텍스트 데이터가 자주 변경되면 전문 인덱스 업데이트시에 상당한 자원이 소모
- es 가 있는데 굳이?
솔직히 작은 어플리케이션에는 사용할만할 것 같다.
Composite Index (복합 인덱스)
- 두개 이상의 컬럼을 결합하여 생성된 인덱스
- 특정 쿼리 연산에서 여러 컬럼을 동시에 사용할 때 검색 성능을 향상시키기 위해 사용된다.
복합 인덱스의 작동 원리
- 지정된 컬럼들의 조합으로 구성된다.
- 인덱스 내에서는 해당 컬럼들이 정의된 순서대로 데이터를 정렬한다.
- 해당 특성 땜시
- 복합 인덱스는 쿼리가 인덱스의 첫 번째 컬럼부터 순서대로 사용할 때 가장 효율적이라고 한다.
- 해당 특성 땜시
예시
이름 생년월일 컬럼에 대한 복합 인덱스가 있다고 가정해본다면, 이 인덱스는 먼저 이름 으로 정렬된다.
그 다음 생년월일 로 정렬된다
이름만을 조건으로 하거나이름생년월일모두 조건으로 하는 쿼리에서 효율적으로 작동한다.
복합 인덱스의 장점
- 성능 향상
- 여러 컬럼을 조건으로 하는 쿼리에서 검색 성능이 크게 향상
- 정렬 그룹화 최적
- 쿼리 결과의 정렬이나, 그룹화 작업을 최적화 간으
- 인덱스 커버링
- 쿼리가 인덱스에 포함된 컬럼만을 사용하는 경우, 실제 데이터에 접근하지 않고, 인덱스에서 결과를 바로 가져올 수 있음.
- 근데 이런 상황이 과연 많을지..? 모르겠음.
단점
일단 일반적인 인덱스의 단점을 다 가져감
- 별도의 공간을 쓰고
- 유지 관리 비용이 비쌈
- 업데이트 삭제 삽입 시에 인덱스도 업데이트 되어야함.
주의!
- 가장 많이 사용되는 컬럼을 인덱스의 앞쪽에 배치하는 것이 좋음
- 불필요한 복합 인덱스는 공간과 성능에 부정적인 영향.. → 이건 당연하지
- 그래서 보통 테이블마다 3 ~ 4 개 정도를 개인적으로는 max 라고 봄
아 손가락 아파

이전 블로그 : https://oth3410.tistory.com/