엘라스틱 서치 구성
jvm 설정
- ES 는 JVM 에서 실행된다.
권장
- 최소 크기와 최대 크기를 동일한 값으로 설정한다. ( 리소스를 많이 소모하는 메모리 할당 프로세스 방지)
- 노드에서 사용 가능한 메모리의 절반 정도를 JVM 에 할당해야함.
- 나머지는 OS 나 File System Cache 에서 사용한다.
예
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"- 현재는 로컬 도커에서 돌리기에, 그냥 1g 할당으로 결정했다. 로컬은 32기가이나 es 만 돌리진 않기에.. 만약 별도 서버에 es 만 호스팅하는 경우 해당 메모리의 절반정도는 할당한다고 한다.
노드 설정
- 싱글 노드의 경우 es 는 파일을 수정할게없ㄷ음.
- es cluster 설정의 경우 다음 설정을 올바르게 지정해야함
# 하나의 클러스터 내의 모든 노드에서는 동일한 클러스터명을 사용해야 함
cluster.name: lab-cluster
# 정의되지 않은 경우 호스트 이름으로 설정
node.name: node-a
# 노드의 HTTP 리스너용 포트
http.port: 9200
# 노드의 TCP 통신용 포트
transport.tcp.port: 9300
# 데이터 디렉터리용 파일 시스템 경로
path.data: /mnt/disk/data
# 로그 디렉터리용 파일 시스템 경로
path.logs: /mnt/disk/logs
# 초기 마스터 후보 노드 목록
cluster.initial_master_nodes:
# 클러스터 내 다른 노드의 목록
discovery.seed_hosts:
# 엘라스틱서치가 실행되는 서버의 IP 주소
network.host: 0.0.0.0동적 설정
- cluster/settings api 를 통해 action.auto_create_index 설정 업데이트 가능
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "logs*"
}
}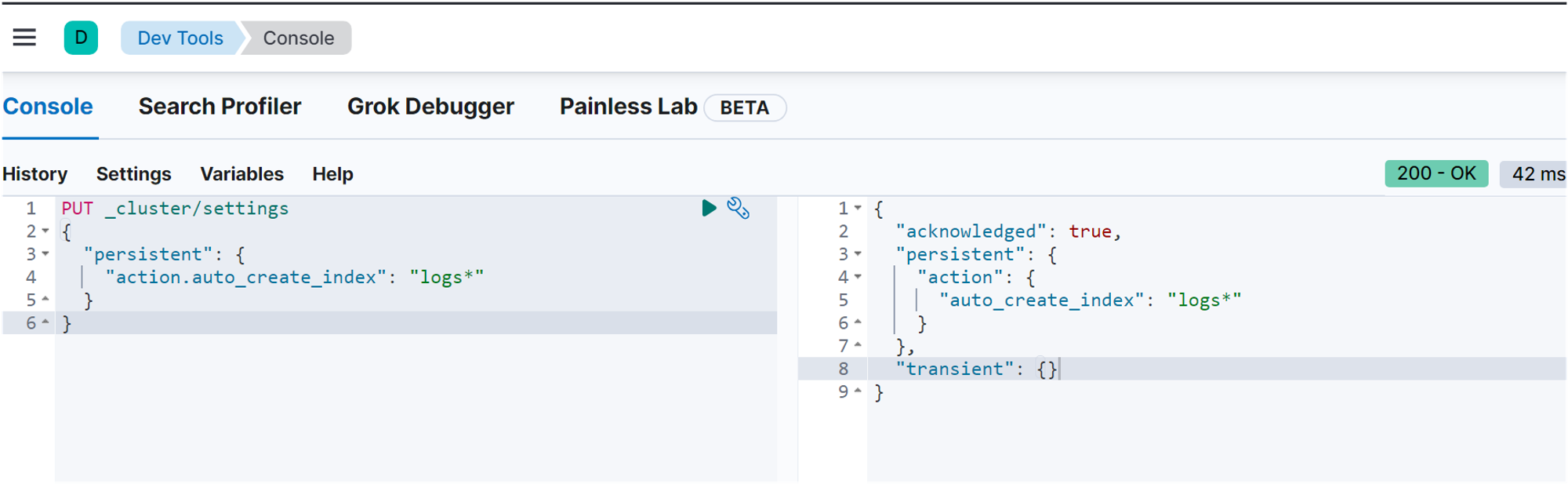
- logs 로 시작하는 모든 인덱스 이름에 해당 규칙이 적용된다.
- 만약
logs로 시작하는 이름의 존재하지 않는 인덱스로 데이터를 보내는 경우 - es 가 자동으로 해당 이름의 인덱스를 생성, 데이터를 저장함.
- 장점
- 사용자가 매번 수동으로 인덱스 설정할 필요가 없음
- 보통 로깅 시스템에서 유용하다고 한다.
03. 데이터 색인과 검색
- REST API 로 es 를 쉽게 사용가능.
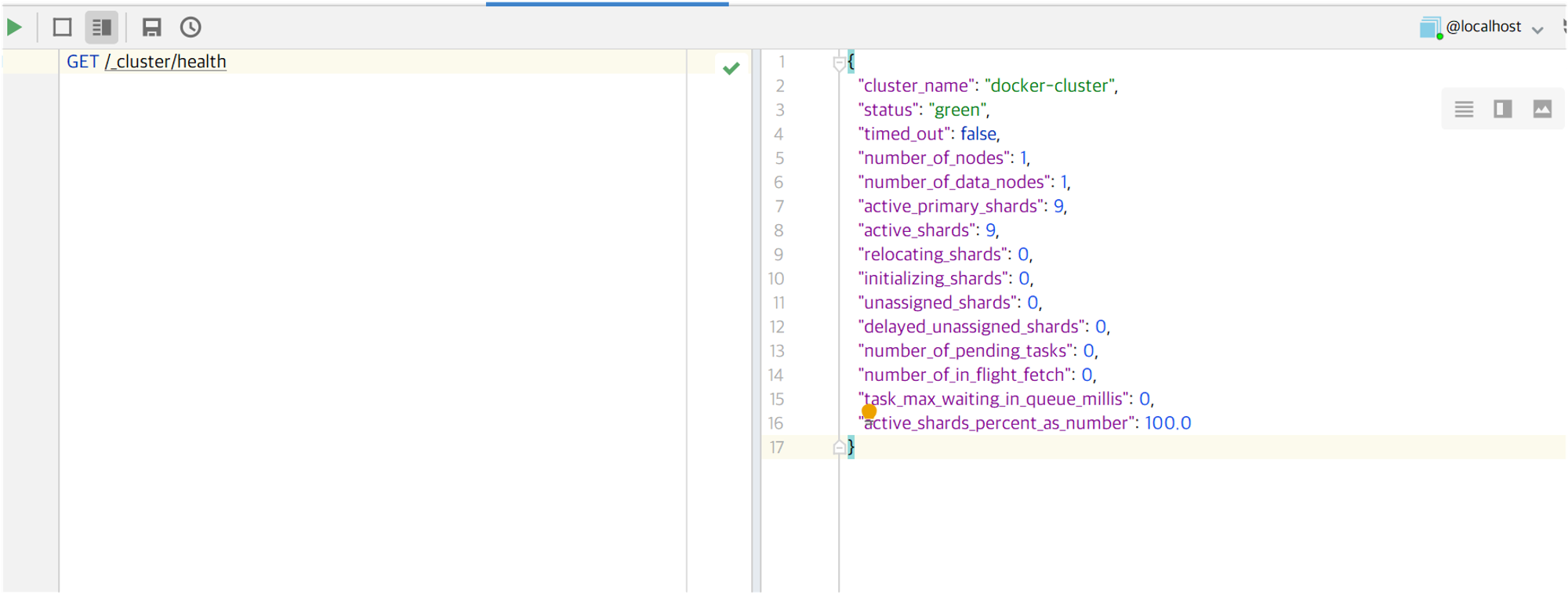
- 이런식으로 헬스 체크가 가능함.
es 인덱스 내부 구조 설명
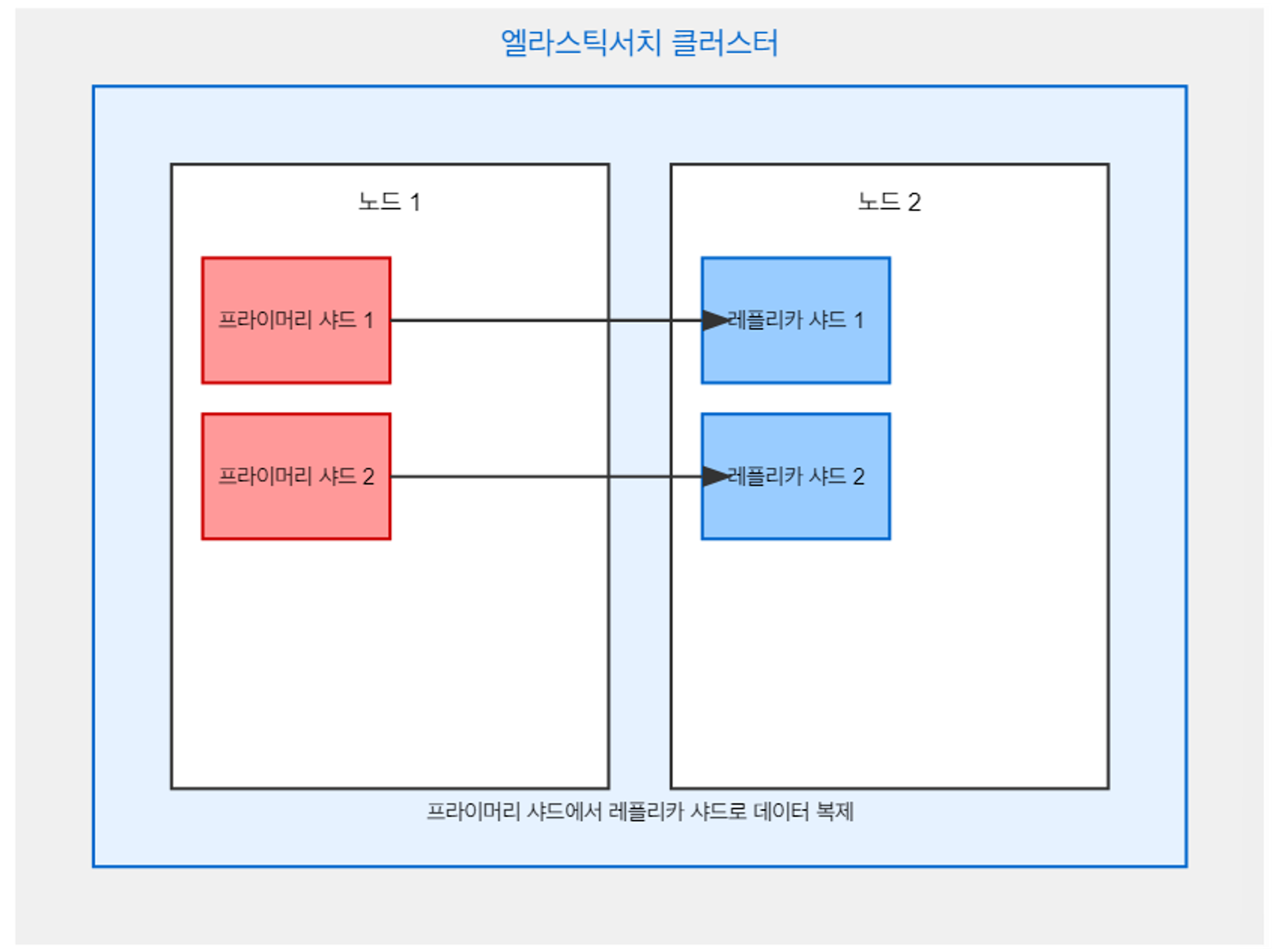
- 인덱스의 구조
- 관련 문서를 저장하고 구조화하는 장소
- SQL DB 테이블과 유사함.
- 샤드 구성
- 인덱스는 여러 개의 프라이머리 샤드로 구성된다.
- 각 프라이머리 샤드는 고가용성을 위하여 레플리카 샤드로 복제된다.
- 샤드의 특성
- 각 샤드는 루씬 인덱스의 인스턴스이다.
- Primary 샤드
- 읽기 || 쓰기 요청을 처리 가능하다
- 레플리카 샤드
- 읽기 전용
- 데이터의 일관성
- 문서는 프라이머리 샤드에서 색인한 뒤에 레플리카 샤드로 복제된다.
- 레플리카 샤드 업데이트 후에 색인 요청이 승인된다.
- 읽기 일관성을 보장함.!
- 고가용성 및 확장성
- 프라이머리와 레플리카 샤드의 경우 항상 서로 다른 노드에 할당된다.
- 프라이머리 샤드 손실이 나는 경우, 레플리카 샤드가 승격되고 새 레플리카가 생성된다.
- 읽기 확장성
- 레플리카 샤드는 독립적으로 검색 요청이 응답이 가능하다.
- 레플리카 샤드 추가로 읽기 확장성 구현이 가능하다.
- 쓰기 확장성
- 인덱스는 여러 프라이머리 샤드로 구성이 가능
- 샤드가 클러스터 전체에 고르게 분산되어 쓰기 확장성 달성
es 색인 과정과 인덱스 생성 관련
- 색인
- 문서를 ES 인덱스에 기록하는 작업임.
Create Index API를 사용해 인덱스 생성가능.- 콘솔에서 별도로 생성도 가능
PUT my-index
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-index"
}
인덱스가 생성됨.- 인덱스 조회
GET my-index
{
"my-index": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "my-index",
"creation_date": "1722314647502",
"number_of_replicas": "1",
"uuid": "VxWpTBd6QvmSFZ4DyGtT-Q",
"version": {
"created": "8050099"
}
}
}
}
}- 클러스터 내의 전체 인덱스 조회
GET /_cat/indices
yellow open my-index VxWpTBd6QvmSFZ4DyGtT-Q 1 1 0 0 225b 225b- 인덱스 생성시 세부 사항 설정
PUT my-other-index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-other-index"
}- 인덱싱 검색 성능을 극대화 시키려면, 전체 노드에 고르게 데이터를 분산해야함
- 보통 로깅의 경우
- 하나의 큰 샤드에 분배
- 고 성능의 데이터 조회가 필요한 경우
- 하나의 작은 샤드에 분배하는 방식
- 보통 로깅의 경우

이전 블로그 : https://oth3410.tistory.com/