수직적 규모 확장(vertical scaling) VS 수평적 규모 확장(horizontal scaling)
- 수직적 규모 확장( 스케일 업 )
- 정의
- 서버에 고사양의 자원( 더 좋은 CPU , 더 많은 RAM 등) 을 추가하는 행위
- 정의
- 수평적 규모 확장( 스케일 아웃 )
- 정의
- 더 많은 서버를 추가하여 성능을 개선하는 행위
- 정의
스케일 업 장단점
- 장점
- 서버로 유입되는 트래픽의 양이 적은 경우
- 단순함.
- 단점
- 한 대의 서버에 CPU 나 메모리를 무한대로 증설할순 없음.
- 자동복구(failover) 나 다중화(re-dundancy) 방안을 제시하지 않음.
- 만약 서버에 장애가 발생하면 웹/ 앱은 완전히 중단됨.
스케일 아웃은 언제 쓰이냐?
- 위와 같은 단점때문에 대규모 어플리케이션에서는 대부분 스케일 아웃의 방법이 쓰인다.
- 서버가 만약 다운되는 경우 사용자는 웹 사이트에 접속할 수 없을것이고, 그에 대비하여
부하 분산기혹은로드밸런서가 사용된다.
로드 밸런서
-
정의
-
부하 분산 집합(load balancing set) 에 속하는 웹 서버들에게 트래픽을 고르게 분산하는 역할을 한다.
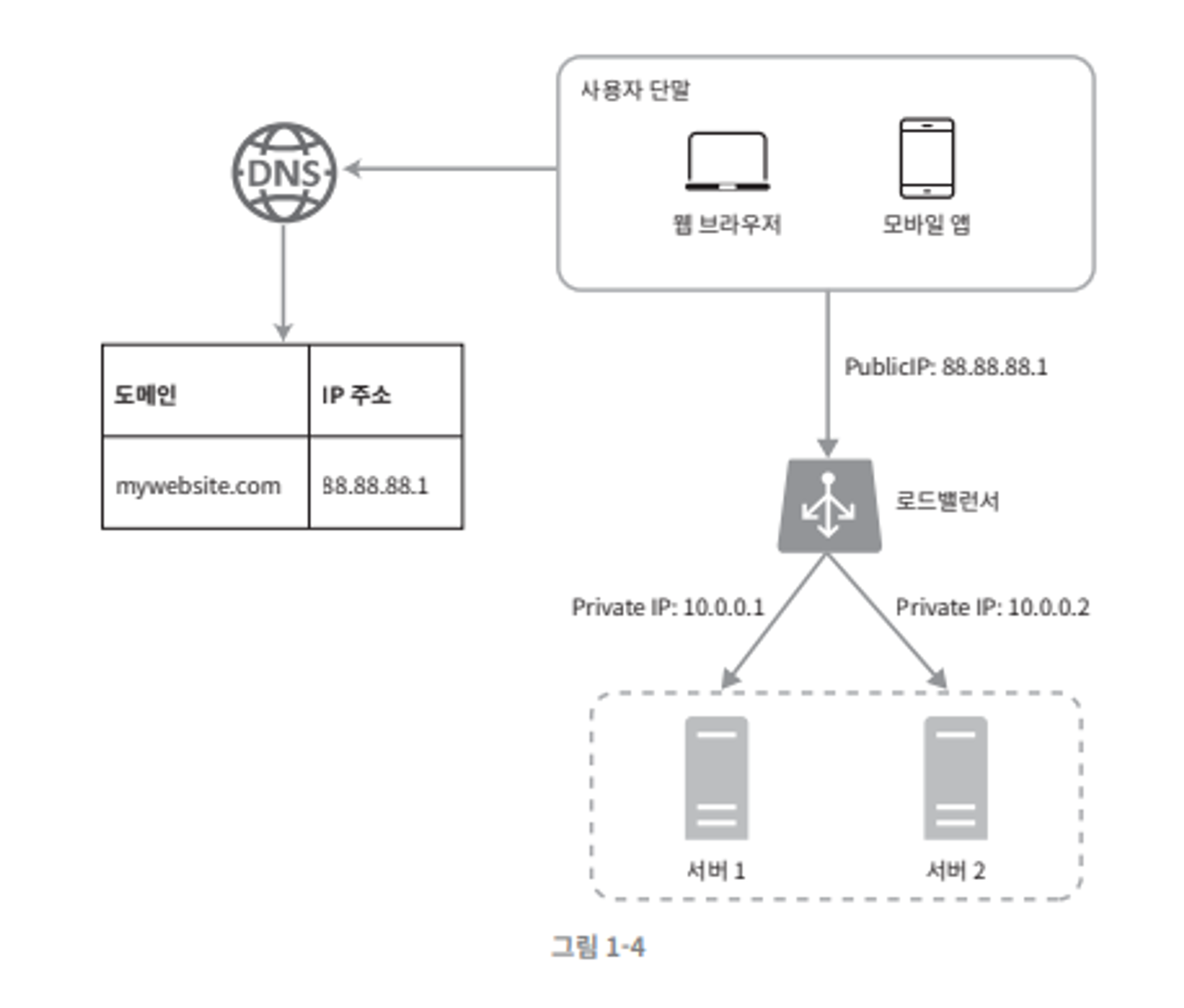
- 위 그림과 같이 다중화된 서버에 현재 서버가 부담하고 있는 트래픽의 양을 고려하여 고르게 트래픽을 분산시킨다.
-
-
접근 방법
- 로드밸런서의 공개 IP 주소로 접속한다.
- 웹 서버는 클라이언트의 접속을 직접 처리하지 않고,
- 로드 밸런서는 서버에 할당된
사설 IP같은 같은 네트워크에 속한 서버간의 통신에 사용되는 주소로 접속한다.
- 로드 밸런서는 서버에 할당된
-
FALIOVER 발생시 케이스
- 서버 1이 다운되는 경우
- 모든 트래픽은 서버 2로 전송된다.
- 웹 사이트로 유입되는 트래픽이 UP
- 하나의 서버를 추가하여
로드밸런서가 3대의 서버가 트래픽을 고르게 분산받는다.
- 하나의 서버를 추가하여
- 서버 1이 다운되는 경우
데이터베이스 다중화
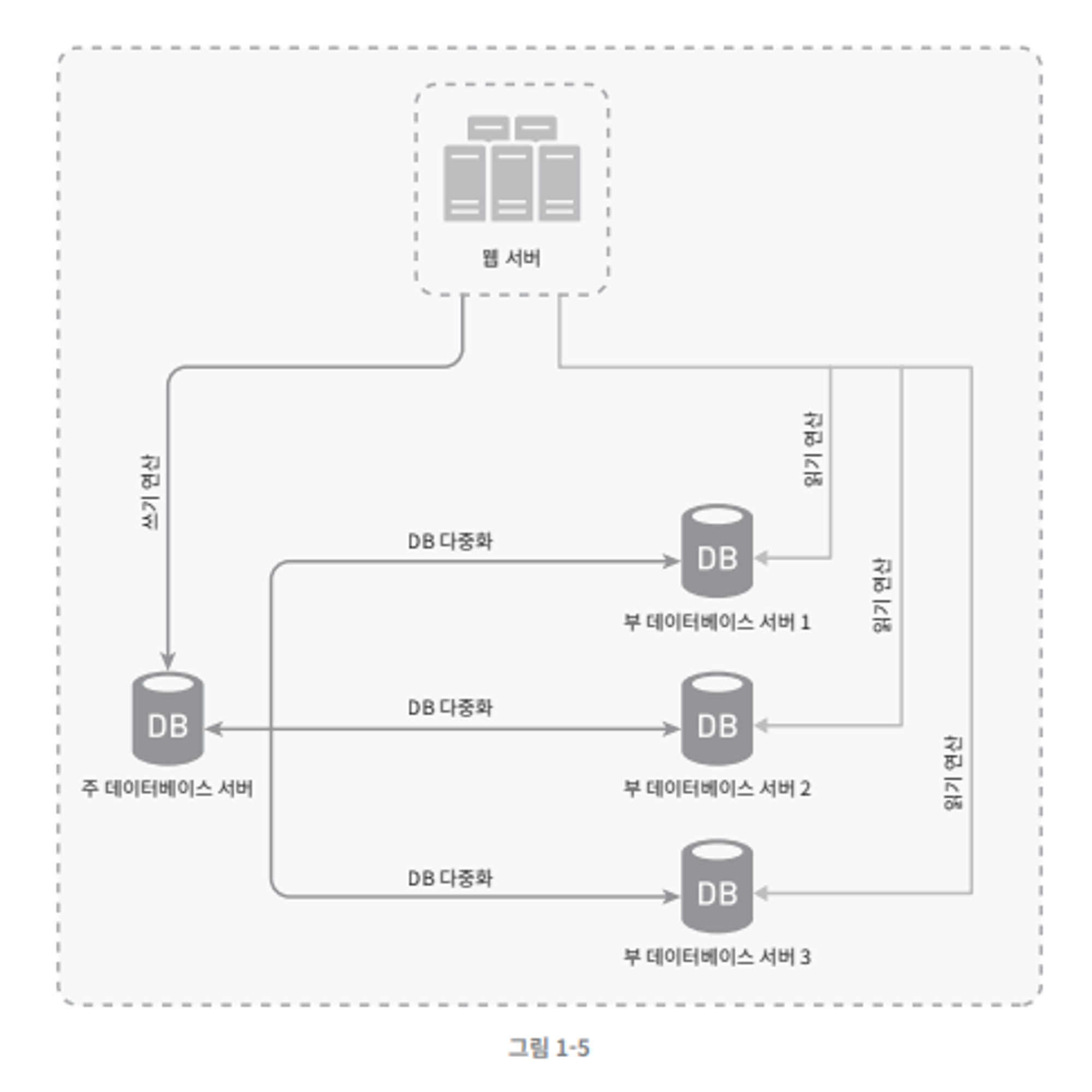
- 보통 위와 같은 구조로 설정된다.
- Master - Slave 구조로 되어 있으며, Master DB 에서는 (
쓰기연산) 만을 수행한다. - Slave DB에서는
읽기 연산만을 수행한다.
- Master - Slave 구조로 되어 있으며, Master DB 에서는 (
다중화의 장점
- 성능
- 쓰기와 읽기의 분리로, 병렬로 처리될 수 있는 질의의 수가 늘어난다.
- 안정성
- DB 서버 가운데 일부가 파괴되어도 데이터는 보존된다.
- 가용성
- 데이터를 여러 지역에 복제해둔다.
- 하나의 DB서버에 장애가 발생해도 다른 DB 서버의 데이터를 가져와서 계속적으로 서비스할 수 있다.
데이터베이스 서버의 가용성을 유지하는 방안
- Slave == Replica DB 에 장애가 발생하는 경우
- 부 서버가 1대
- 모든 읽기 연산은 주 DB 로 전송
- 다운된 부 DB 대체로 새로운 부 DB서버가 추가된다.
- 부 서버가 여러 대
- 읽기 연산은 나머지 부 서버로 분산
- 새로운 부 DB 가 추가되고 장애 서버를 대체함.
- 부 서버가 1대
- Master == Primary DB 에 장애 발생
- 부 서버 한대
- 부 DB가 새로운 Master DB가 된다
- 모든 연산은 Master 에서 수행된다.
- 새로운 부 서버가 추가됨.
- 부 서버가 여러 대인 경우
- 나머지 부 서버 중 하나가 새로운 Master 가 됨
- 장애로 인한 데이터 손실 방지를 위해 복구 스크립트를 실행하여
- 새로운 Master 에서 최신으로 데이터 동기화를 수행한다.
- 부 서버 한대
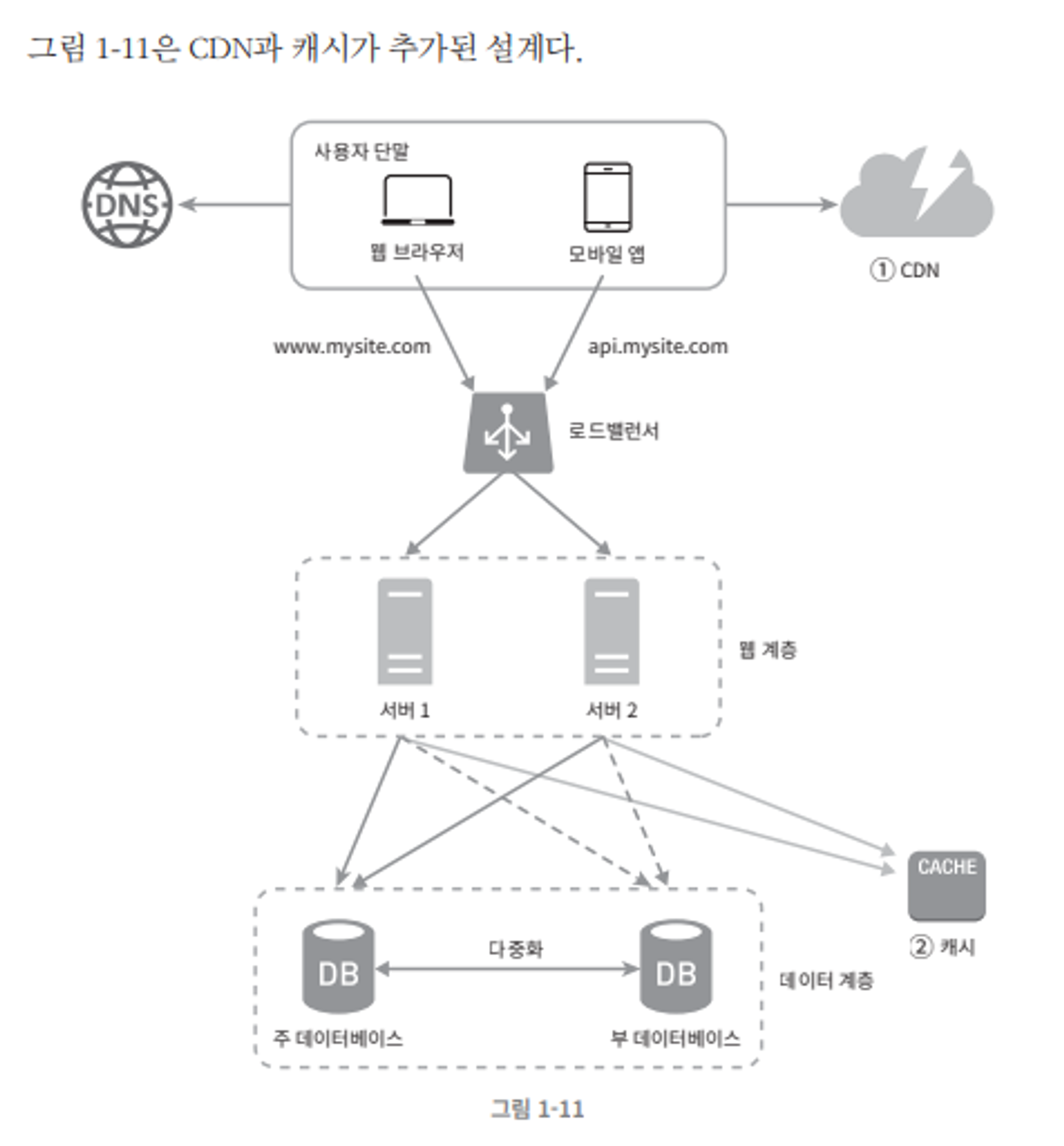
데이터베이스 다중화를 고려한 설계법
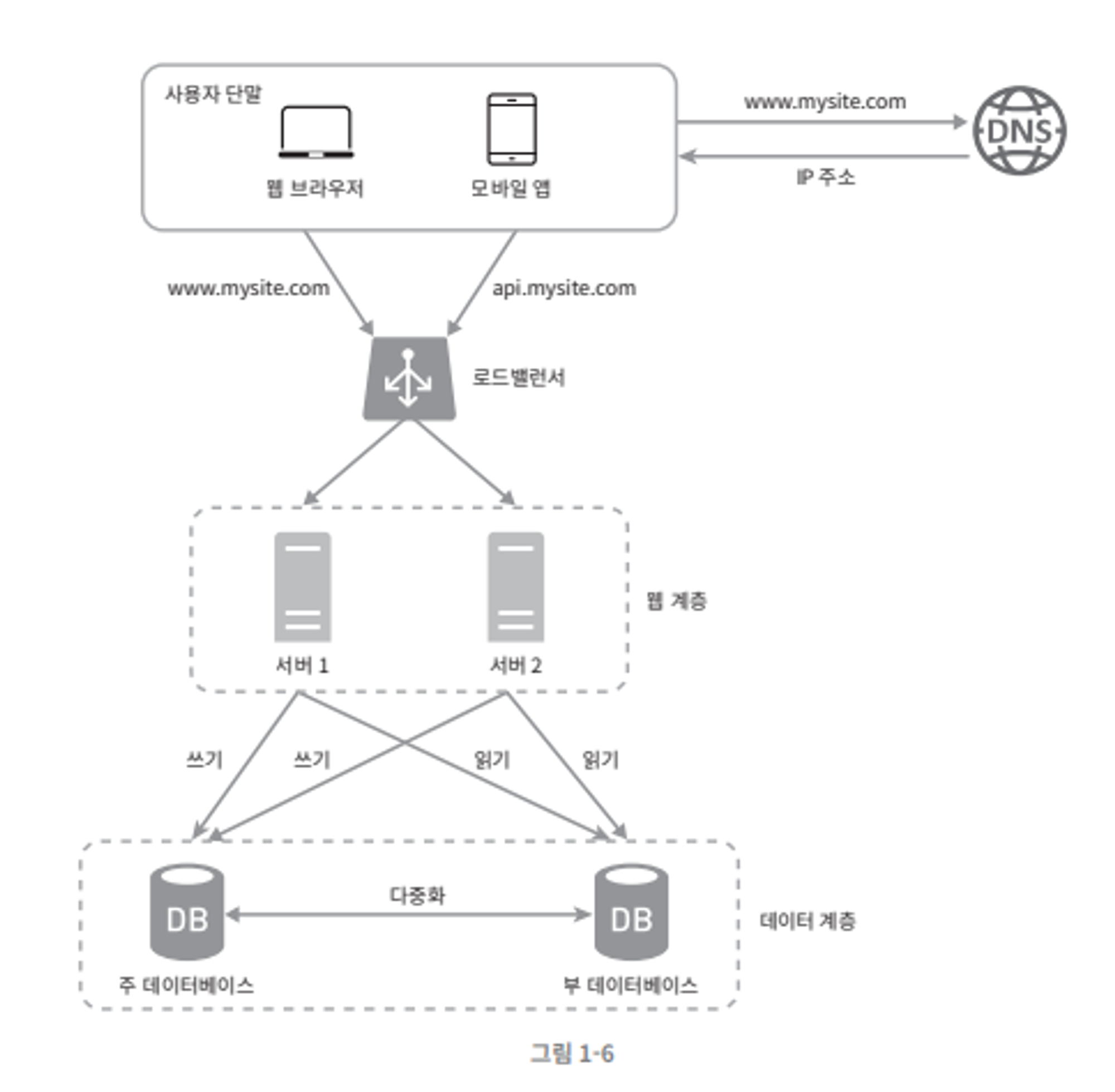
- DNS 로부터 로드밸런서의 공개 IP 를 받아옴
- 사용자는 해당 IP 주소를 통해 로드밸런서 접속
- HTTP 요청은 로드밸런서가 서버 1 혹은 2로 전달
- 읽기 연산은 부 DB, 데이터 변경 연산(쓰기 업데이트, 갱신 등) 은 주 DB로 전달.
응답시간 개선관련
- 응답 시간은 보통
-
캐시
-
CDN
방식을 주로 사용한다.
-
캐시
- 왜 사용하나?
- 디비를 자주 호출하는 경우 시스템의 성능이 저하될 수 있음.
- 캐시를 통해 디스크영역과 소통하는것이 아니라, 메모리 영역과 소통하여 서버의 자원을 적게 사용하도록 해야함
캐시 계층(Cache Tier)
-
캐시 계층의 특징
- DB보다 훨씬 빠르게 데이터에 접근하고
- DB의 부하를 줄이고, 독립적으로 확장이 가능.
-
작동 원리
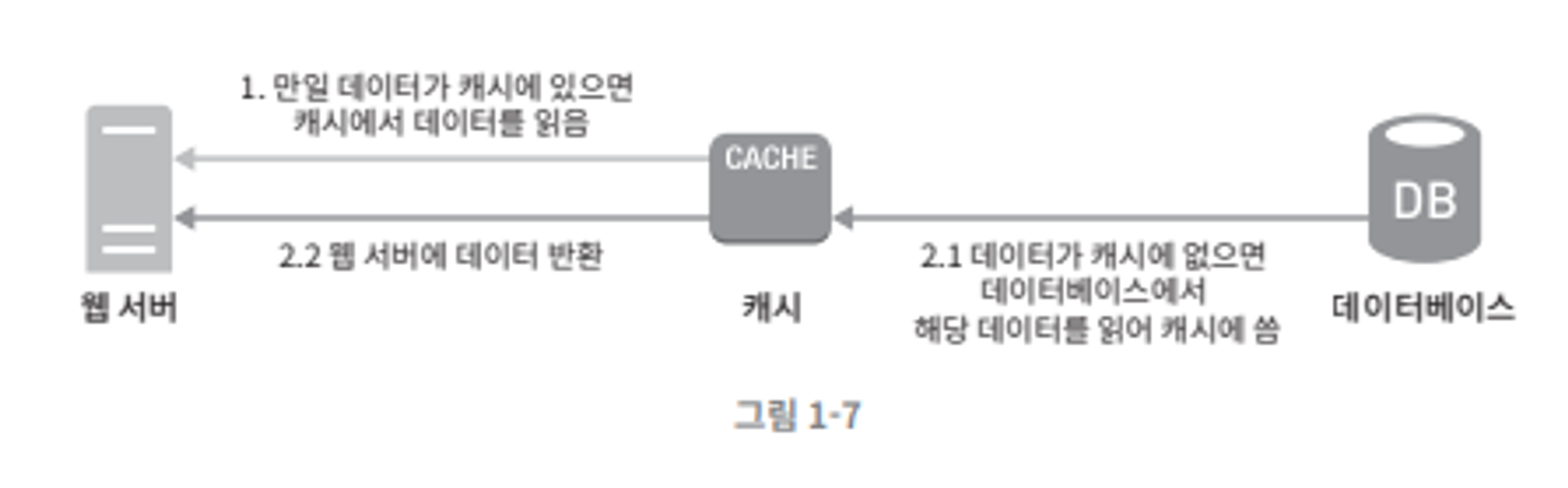
- 서버에서 원하는 데이터가 캐시에 있는지 확인 → 캐시에서 데이터를 읽는다.
- 정상적으로 조회시 서버에 해당 데이터 반환
- 데이터가 캐시에 없는 경우
- DB에서 해당 데이터를 읽어서 캐시에 쓴다.
- 캐시에서 웹 서버에 데이터를 반환함.
- 서버에서 원하는 데이터가 캐시에 있는지 확인 → 캐시에서 데이터를 읽는다.
캐시 전략
- 읽기 주도형 캐시 전략(read-through caching strategy)
- 위의 캐시의 작동 원리가 해당 전략의 청사진이다.
예시
- Memcached API
SECONDS = 1
cache.set('myKey', 'hi there', 3600 * SECONDS)
cache.get('myKey')
myKey 라는 키로 특정값은 1시간 동안 저장하고, ㅐ당 키로 데이터를 조회하는 예제- 키 밸류 형식의 캐싱구조이다.
캐시를 사용하는 경우의 유의점
- 캐시가 바람직한 상황
- 데이터의 갱신은 자주 일어나지 않지만, 참조가 빈번한 경우
- 보통 메인페이지의 데이터 중에 바뀌지 않는 데이터의 경우 캐싱을 수행한다.
- 캐시에 저장할 데이터
- 휘발성 메모리에 저장된다.
- 영속적으로 보관할 데이터는 캐시에 두지 않는 것이 좋다.
- 캐시 서버가 재시작되는 경우 캐시 내의 모든 데이터가 사라진다.
- 물론 레디스같은 경우 AOF 같은 기술이 있지만, 이마저도 레디스의 성능을 떨어뜨리는 원인이 되기도 하여, 기록할 수 있는 용량이 있기에, 휘발성에 대한 위험에서 벗어나기가 어렵다.
- 데이터 만료
- 캐싱된 데이터는 만료일에 대해 적절하게 설정해야한다.
- 너무 만료일이 짧은 경우 너무 자주 호출될 것이고,
- 너무 만료일이 긴 경우 실제 DB 상의 데이터와 이격이 생긴다.
- 캐싱된 데이터는 만료일에 대해 적절하게 설정해야한다.
- 일관성 문제
- 캐시 저장소와 원본 데이터 저장소간의 이격이 생길 수 있다.
- 일관성을 어떻게 유지할지 고민해봐야한다
- 장애 대처
- 캐시 서버를 하나만 두는 경우
- 단일 장애 지점(Single Point of Failure, SPOF) 가 되어버릴 수 있다.
- 캐시 서버 하나의 구멍으로 전체 시스템에 문제가 생길 수 있다.
- 이는 쿠팡에서 레디스 사용시 발생했던 문제를 예시를 들 수 있음.
- 쿠팡에서는 장애 발생시 레디스 int 에서 최대로 설정할 수 있는 값을 넘어버려서 overflow 가 발생했었다고 한다.
- 이런 에러가 발생한 경우 slave db 에서도 같은 문제가 발생했을 것이고,
- DB에서 모든 요청을 처리했다면 DB 서버도 부하로 죽어버렸을 것이다.
- 필수불가결하지만, 설정에 유의하지 않으면 매우 위험한 편이다.
- 캐시 서버를 하나만 두는 경우
- 캐시 메모리 설정관련
- 메모리가 너무 작으면 데이터가 캐시에서 자주 밀려서 (evitction) 캐시의 성능이 떨어지게 된다.
- 이를 위해 캐시 메모리를 과할당하는 정책을 결정한다고 한다
- 이는
overprovision이라고 한다,
- 메모리가 너무 작으면 데이터가 캐시에서 자주 밀려서 (evitction) 캐시의 성능이 떨어지게 된다.
- 데이터 방출(eviction) 정책
- LRU(Least Recently used - 마지막으로 사용된 시점이 가장 오래된 데이터를 내보내는 정책)
- LFU, FIFO 등이 있음.
콘텐츠 전송 네트워크(CDN)
-
개요
- 정적 콘텐츠를 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크임.
- 이미지, 비디오, CSS, Javascript 파일 등을 캐시할 수 있다.
-
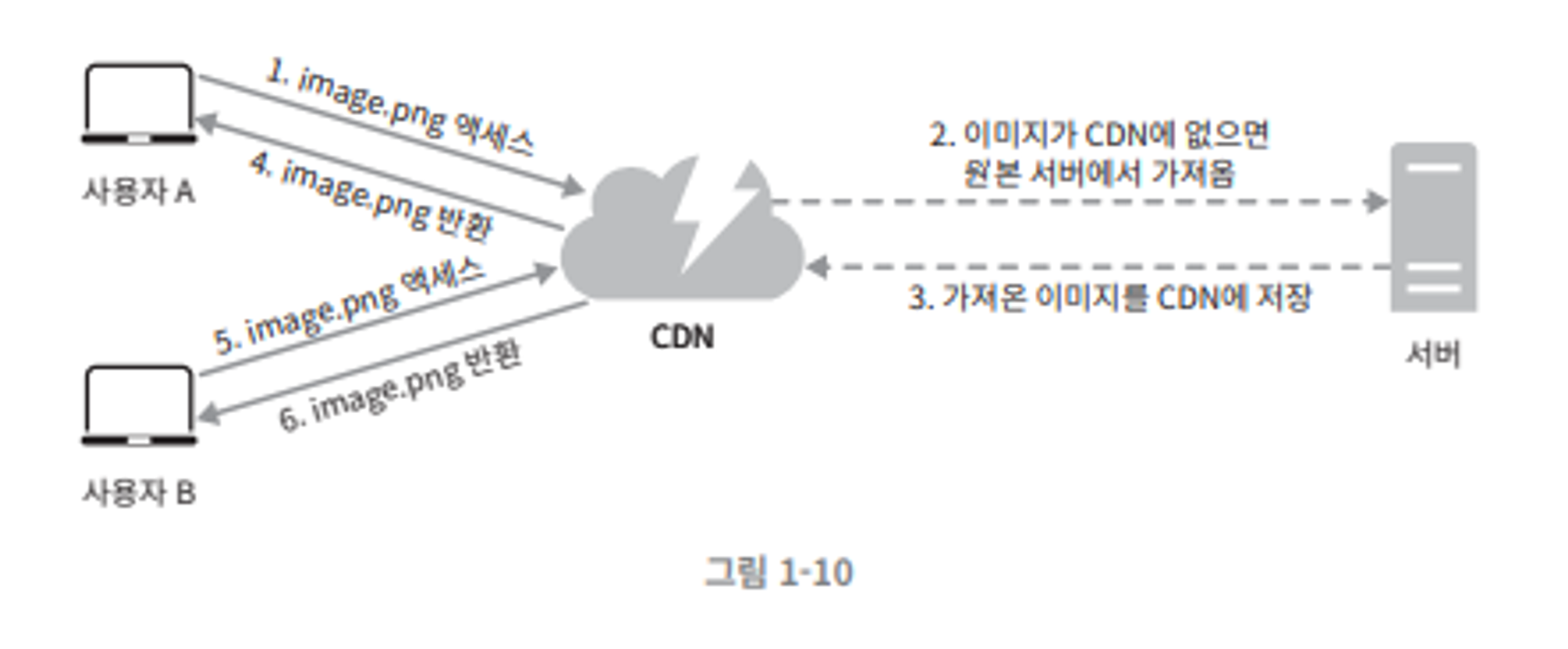
CDN 동작 방식
-
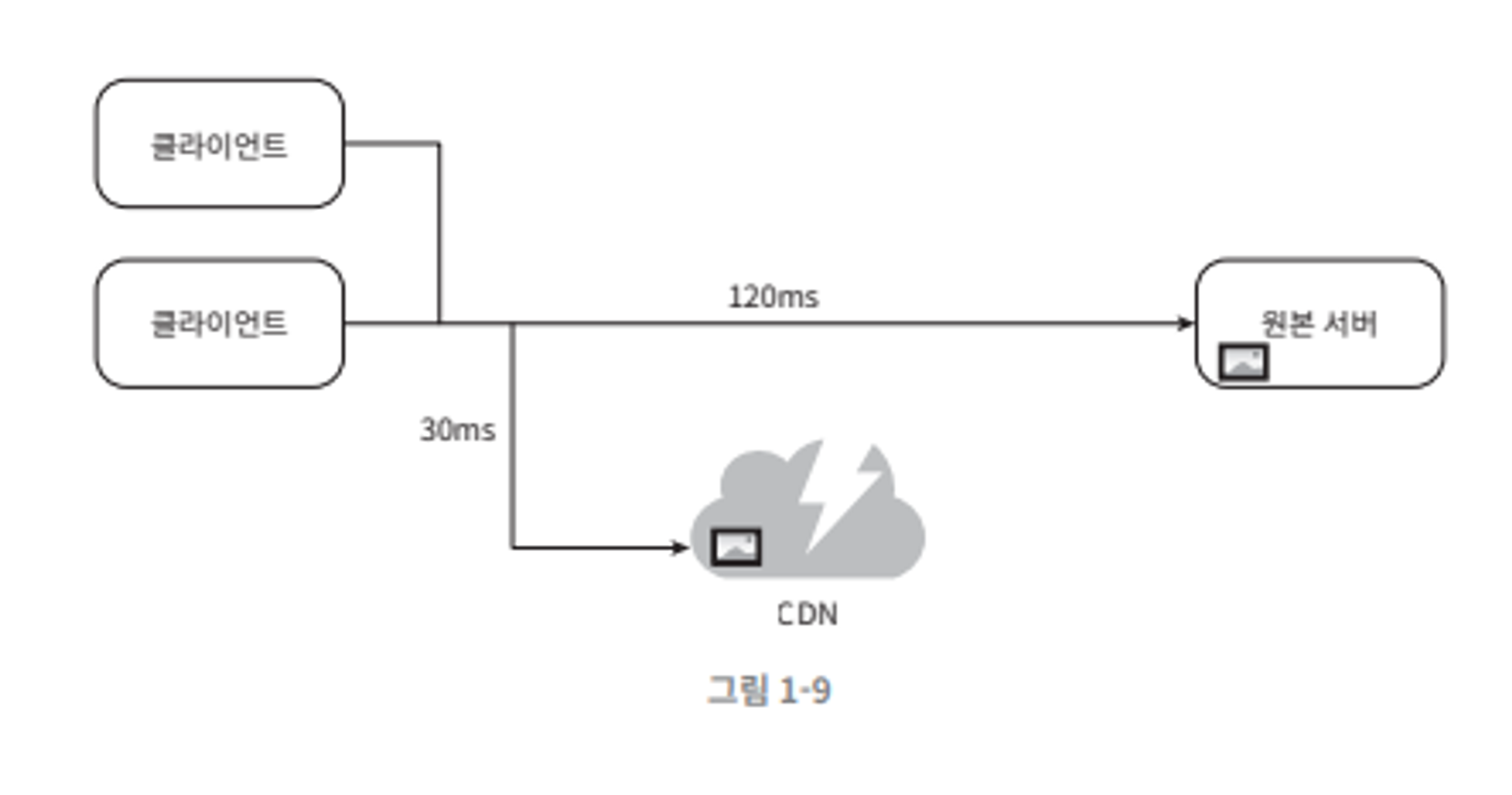
사용자가 웹 사이트 방문.
-
가장 가까운 CDN 서버가 정적 컨텐츠를 전달.
-
사용자와 CDN 서버가 멀면 웹사이트는 천천히 로드된다.
-
CDN 사용시 고려사항
- 비용 문제
- CDN 은 보통 데이터 전송 양에 따라 요금을 냄.
- 만료 시한 문제
- 만료 시한이 너무 길면 → 신선도 하락
- 만료 시한이 너무 짧으면 → 원본 서버에 빈번하게 접속하여 성능 저하
- CDN 장애
- 2024 05 02일에 발생한 jsDeliver 등에 대한 CDN 서버의 SSL 만료로 인하여 아시아에서 문제가 발생했던 적이 있다.
- SSL 만료로 해당 라이브러리를 불러오지 못하는 경우, 사이트에 엄청난 문제가 발생하기에,
- 자체적인 CDN 서버를 구축하는 등의 대안을 마련해야한다.
- 혹은 원본 서버에서 그냥 불러오도록 우회코드를 짜는 방법도 있다.
- 콘텐츠 무효화(invalidation)
- CDN 사업자가 제공하는 무효화 API 로 신선도 있는 컨텐츠 제공
- 오브젝트 버저닝
- image.png?v=2 같은 식으로 컨텐츠를 버저닝함으로 최신화 가능

이전 블로그 : https://oth3410.tistory.com/
유익한 내용 공유해주셔서 고맙습니다 :)