데이터 센터
지리적 라우딩(GeoDNS-routing)
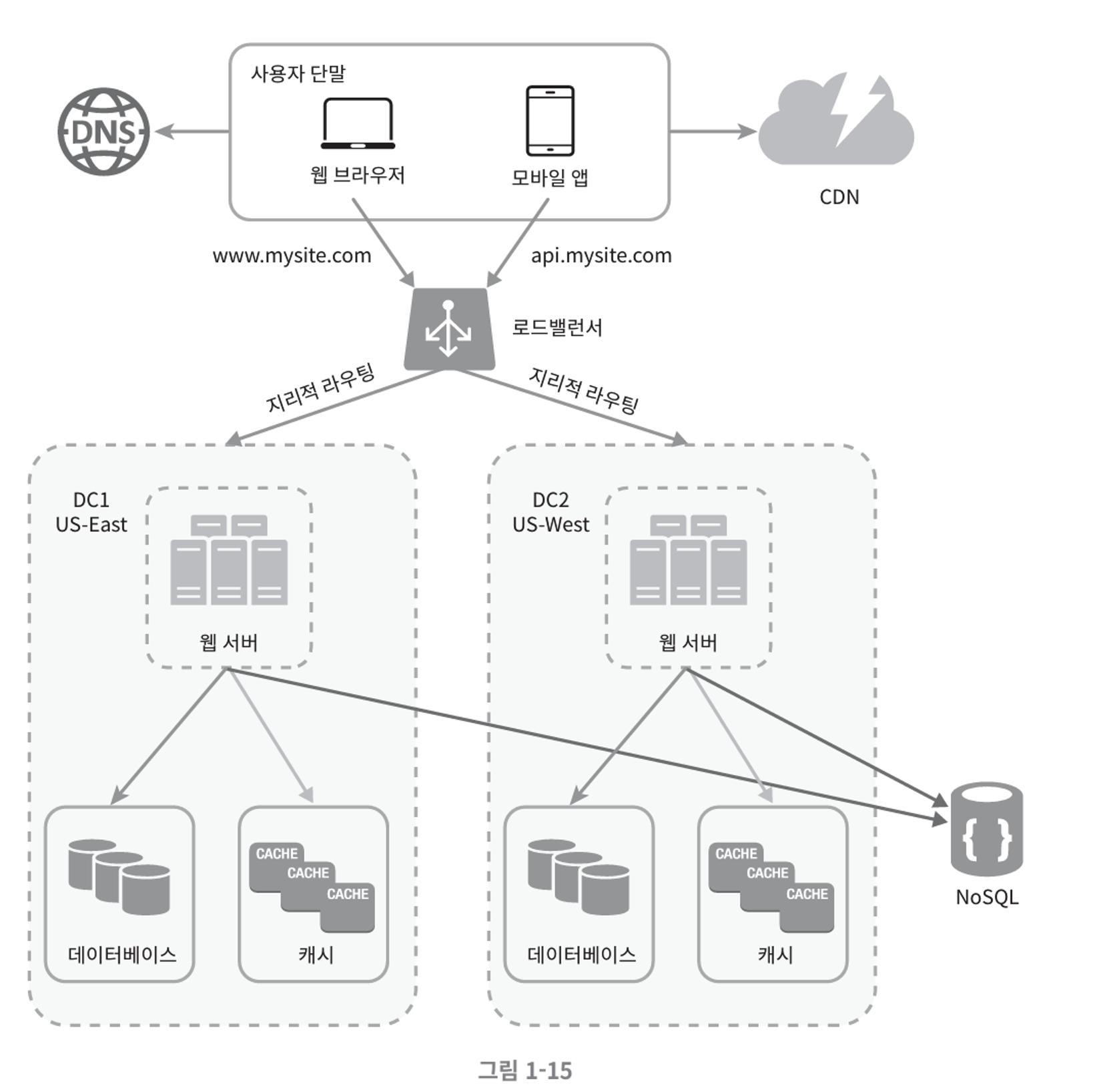
- 사용작 가장 가까운 데이터 센터로 안내된다.
- 책의 예시 상에서는
- x% 의 사용자가 US-East 센터로
- (100 - x%) 의 사용자가 US-West 센터로 안내된다고 한다.
장애 발생 시 트래픽 전환
- 데이터 센터 중 하나에 심각한 장애가 발생하는 경우 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
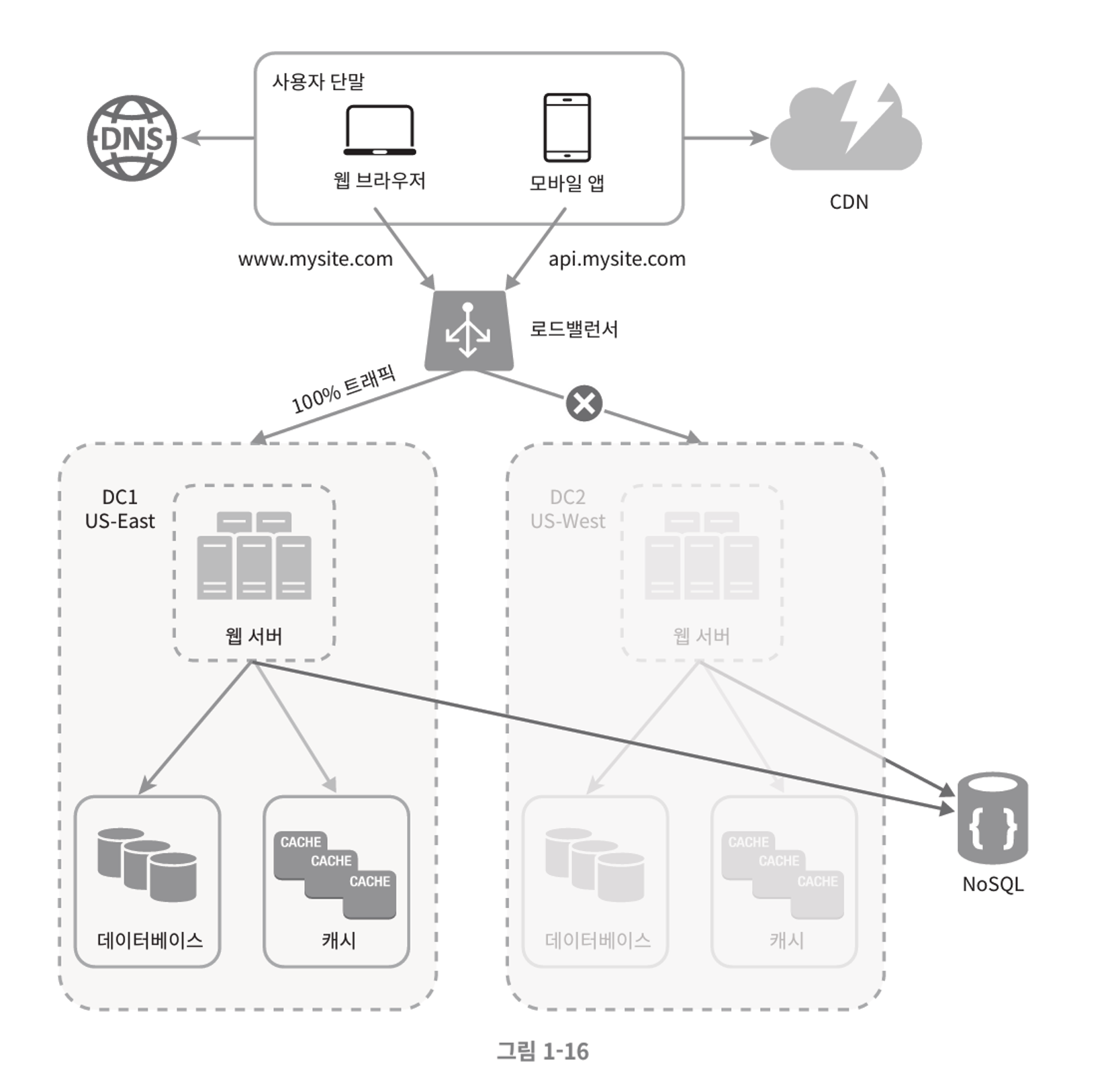
다중 데이터 센터 아키텍처의 기술적인 난제
- 트래픽의 우회
- GeoDNS 를 통해 사용자가 가장 가까운 데이터센터로 트래픽을 보낼 수 있도록 해야한다.
- 데이터 동기화
- 데이터베이스가 여러 데이터 센터에 걸쳐 다중화가 되어야 한다.
- 장애 발생 시 다른 데이터 센터로 트래픽이 우회되더라도 데이터의 손실을 방지하기 위함임.
- 테스트, 배포
- 시스템을 여러 위치에서 테스트하고, 자동화된 배포 도구로 모든 데이터 센터에 동일한 서비스가 설치되도록 해야함.
- 확장성
- 시스템의 컴포넌트를 분리해 각각 독립적으로 확장될 수 있도록 해야 한다.
- 해당 확장성 관련 부분은
- Message Queue 를 사용해 해당 문제를 해결한다.
메시지 큐
- 개요
- 애플리케이션 간의 비동기 통신을 지원하고 메시지의 무손실 특성을 보장하는 컴포넌트이다.
- 서비스나 서버 간의 결합을 느슨하게 하고,
- 규모의 확장성이 필요한 안정적인 애플리케이션 구성에 매우 유용하다.
기본 구조
- 생산자 ( Producer / Publisher )
- 메시지를 생성하고 메시지 큐에 발행하는 입력 서비스
- 메시지 큐
- 메시지를 버퍼링하고 안전하게 저장하는 역할
- 소비자 ( Consumer / Subscriber )
- 메시지를 받아 처리하는 서비스나 서버
메시지 큐는 비동기적으로 메시지를 전송하고,
생산자는 소비자가 다운되어 있어도, 메시지를 발생가능하고,
소비자는 생산자 서비스가 가용하지 않아도, 메시지를 수신할 수 있다.
사용 예
- 사진 보정 어플리케이션
- 이미지 크로핑, 샤프닝, 블러링 등의 작업은 시간이 오래 걸려서 비동기적으로 작업을 처리해야 한다.
- 웹 서버 ; 사진 보정 작업을 MQ 에 넣는다
- 사진 보정 작업 큐 ; 작업을 큐에 넣어 → 보정 작업 프로세스가 꺼내어 처리할 수 있도록 한다.
- 사진 보정 작업 프로세스 ; 큐에서 작업을 꺼내어 비동기적으로 완료를 수행한다.
결
- 생산자와 소비자 구조로서 각기 독립적인 확장이 가능함.
- 큐의 크기가 커지면 더 많은 작업 프로세스를 추가하여 처리 시간을 줄일 수 있음.
데이터베이스의 규모 확장
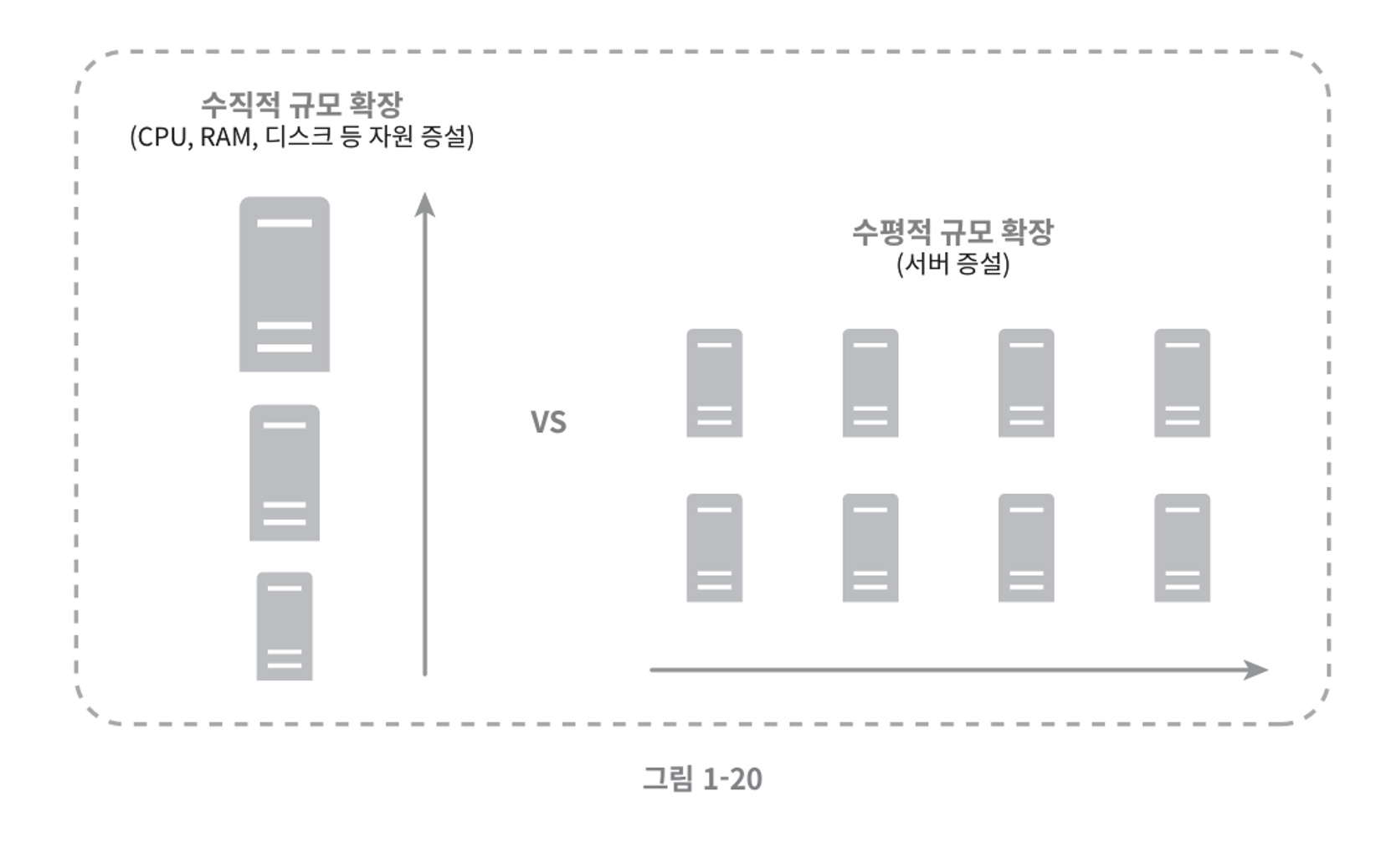
수직적 확장 ( Scale Up )
- 기존 서버에 더 많은 자원(CPU , RAM , 디스크 등)을 추가하는 방식임
장점
-
관리가 비교적 단순
-
고성능 자원을 통해 성능의 큰 향상이 가능하다
단점
-
하드웨어 한계가 있어서 무한 증대는 불가능하다
-
단일 장애 지점(SPOF) 으로 가용성에 문제가 있다
-
비용이 많이 든다 ( 고 성능 서버일수록 비싸다 )
-
수평적 확장( Scale Out - 샤딩)
- 여러 대의 저사양 서버를 네트워크로 연결하여 하나의 DB 시스템처럼 운영하는 방식이다.
- 데이터를 여러 서버에 분산저장하고 처리하여, 대규모 데이터 처리 요구에 대응가능하다.
-
이를
샤딩(Sharding) 이라고하며 데이터를 작은 단위(샤드) 로 분할하여 각 샤드에 분산 저장하는 것을 말한다.장점
-
확장성
- 필요에 따라 서버를 추가하여 쉽게 확장이 가능하다.
-
비용 효율성
- 고성능의 비싼 서버 대신 여러 대의 저사양 서버를 활용가능하다.
-
고가용성
1. 여러 서버 중 하나에 문제가 발생해도 다른 서버가 계속 운영되므로, 서비스 중단의 위험이 줄어든다.단점
-
복잡성
- 서버 간 데이터 일관성을 유지하기 위해 추가적인 관리와 설정이 필요
-
네트워크 부하문제
- 서버 간 통신으로 인해 네트워크 부하가 증가할 수 있음.
-
복잡한 장애 처리
- 장애 발생시 원인 파악하고 복구 과정이 복잡해진다.
-
샤딩의 구현과 고려사항
-
샤딩 키
-
데이터 분산을 결정하는 키이다.
-
예를들어 회원정보를 DB에 담는다고 하고 DB 샤드를 4분류로 나누는 경우,
user_id % 4를 통해 데이터가 어느 샤드에 저장될지 결정함.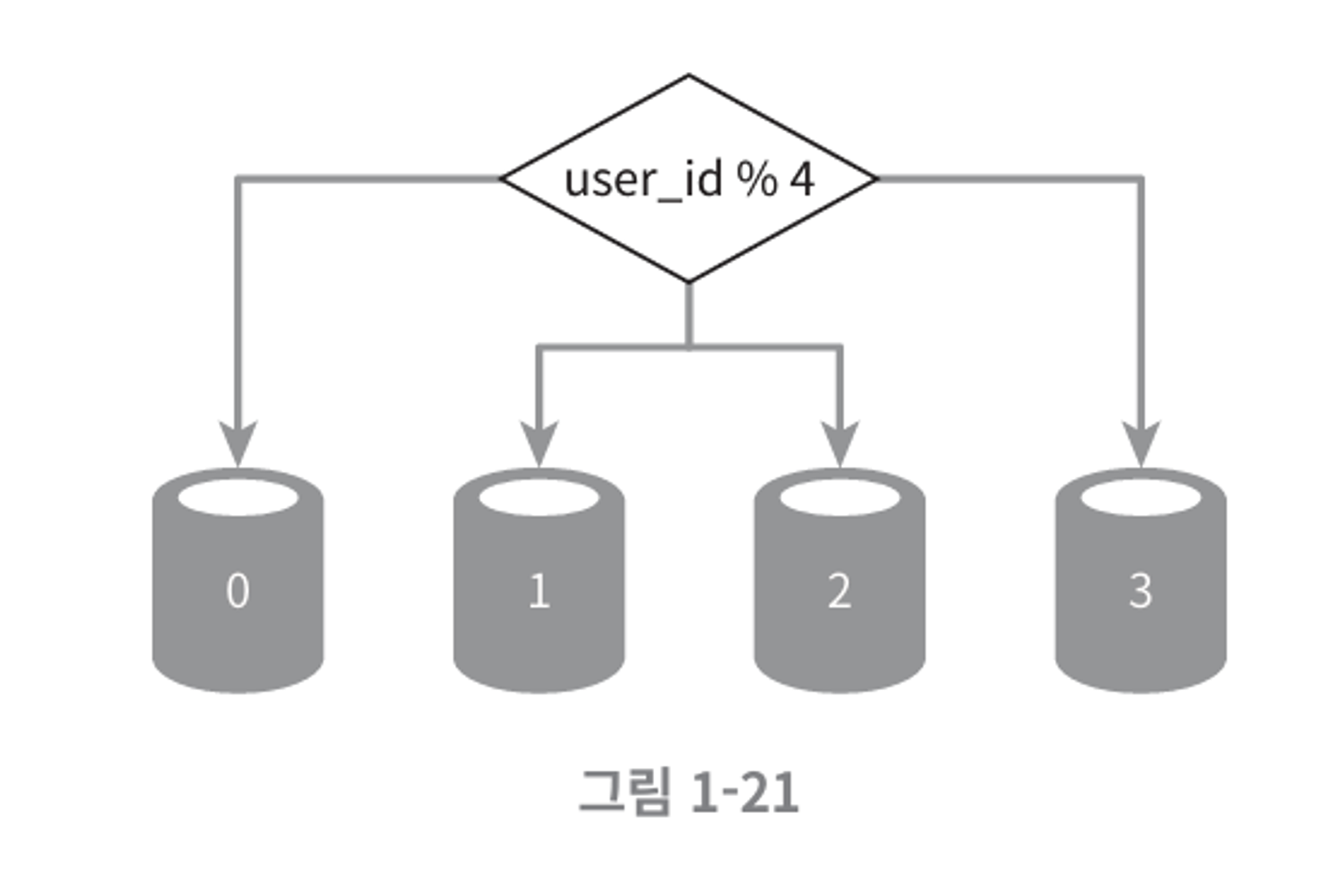
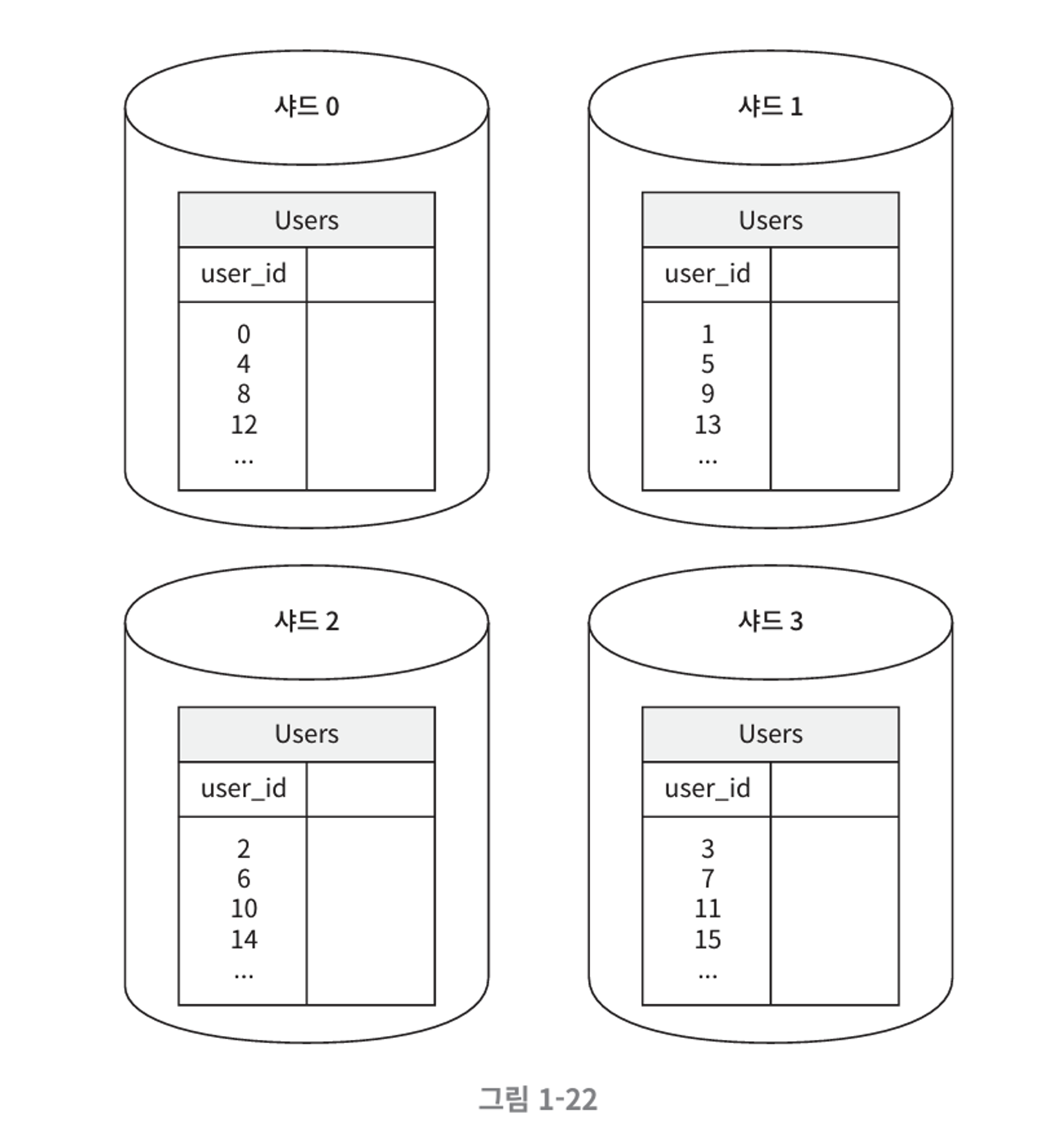
-
-
재 샤딩(
resharping)- 데이터가 너무 많아지거나 샤드 간 데이터 분포가 불균형해진다면 재 샤딩이 필요하다.
-
유명인사 문제
- 특정 샤드에 질의가 집중되는 문제가 발생할 수 있다.
- 유명인의 데이터가 특정 샤드에 몰리면 발생할 수 있음.
- 별도로 더 잘게 샤딩을 하던가, 아니면 유명인사들은 샤드마다 적절하게 재배치되도록 설정해야 할 수 있다.
-
조인과 비정규화
- 여러 샤드에 걸친 데이터를 조인하기가 어렵기에, DB를 비정규화해서 해결한다고 한다.
최종 샤딩된 아키텍처 구조
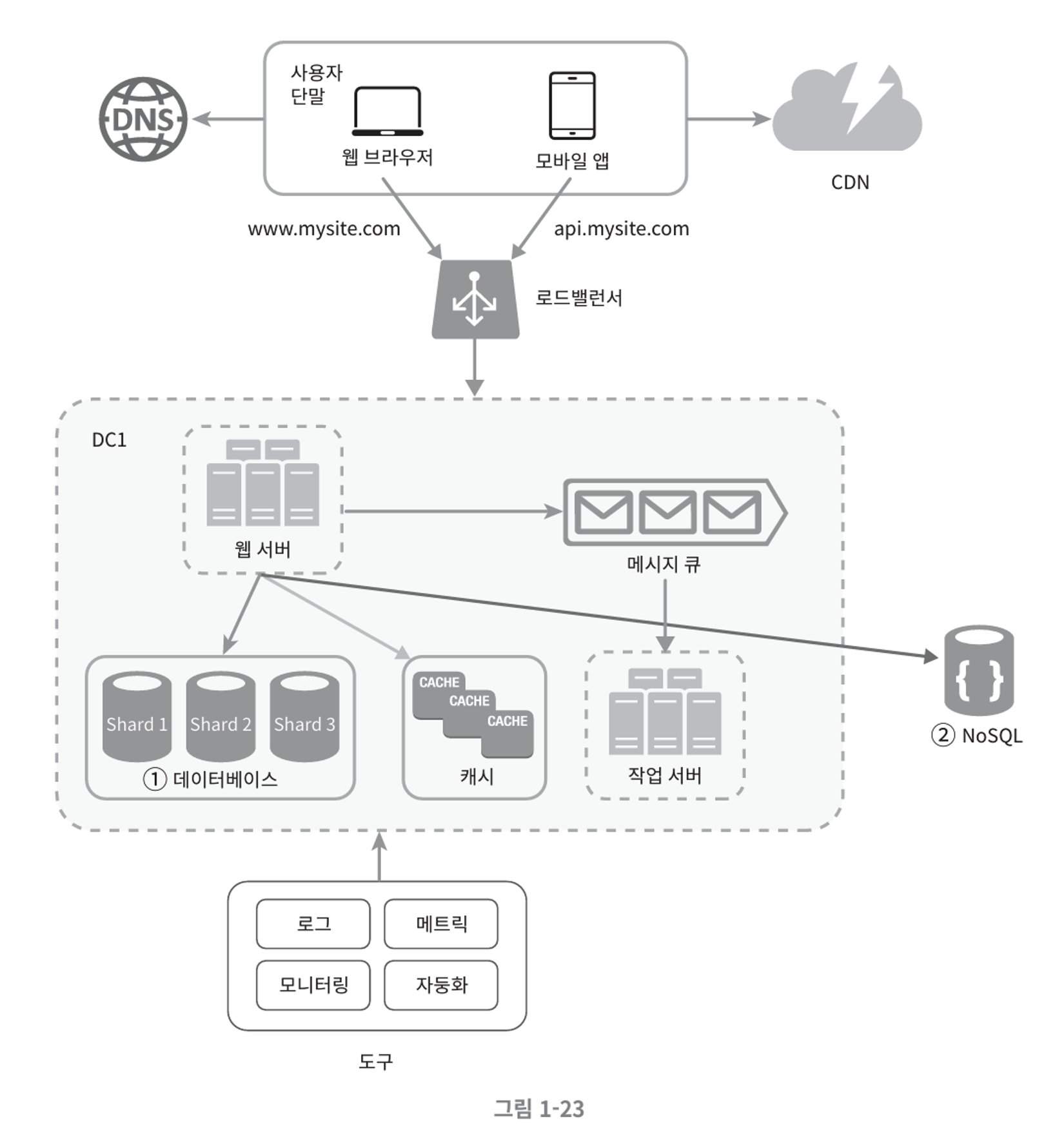
결
- DB 규모 확장의 경우 2가지가 있고,
- 특히 NoSQL 같은 DB는 수평적 확장에 용이 하고 대규모 데이터를 효율적으로 관리할 수 있다.

이전 블로그 : https://oth3410.tistory.com/