-
답변
-
데이터 파티셔닝을 해야할 것 같습니다
- 데이터를 더 작은 청크로 나눠서, 쿼리가 특정 파티션에만 접근하게 함으로 속도를 빠르게 해야한다.
청크?
- 큰 데이터 집합을 더 작고 관리하기 쉬운 부분을 나누는 것을 말합니다.
- 파티셔닝을 통해 쿼리가 특정 파티션에만 접근하도록 하는 것은 DB가 쿼리를 실행 시 필요한 데이터가 포함된 파티션만을 대상으로 검색을 수행하게 함으로써 이루어집니다.
- 이를
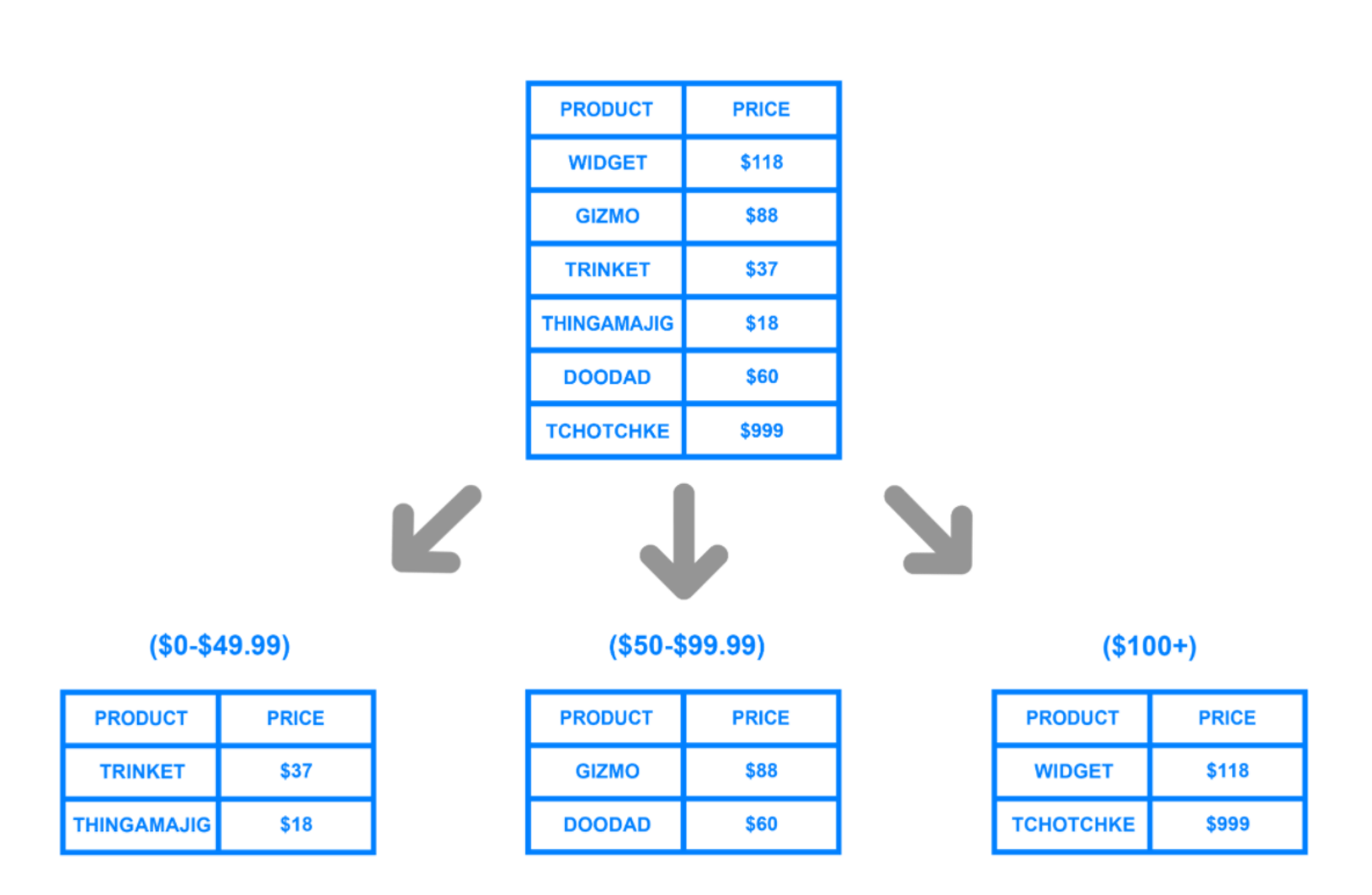
파티션 프루닝(partition pruning)이라고 한다. - 예를 들어
- 시간 기반으로 파티셔닝된 테이블이 있음.
- 2020년 데이터
- 2021년 데이터
- 시간 기반으로 파티셔닝된 테이블이 있음.
- 이를
- 파티셔닝을 통해 쿼리가 특정 파티션에만 접근하도록 하는 것은 DB가 쿼리를 실행 시 필요한 데이터가 포함된 파티션만을 대상으로 검색을 수행하게 함으로써 이루어집니다.
등으로 파티션이 나뉘어져 있는데, - 사용자가 2021년 데이터만을 요청하는 쿼리를 실행하는 경우, 데이터베이스는 자동으로 2021년 파티션만을 검색하고, 나머지 파티션을 무시하게 된다. - ❗검색의 범위가 줄어들고, 결과적으로 쿼리의 성능이 향상된다고 한다. - 큰 데이터 집합을 더 작고 관리하기 쉬운 부분을 나누는 것을 말합니다.
- 데이터를 더 작은 청크로 나눠서, 쿼리가 특정 파티션에만 접근하게 함으로 속도를 빠르게 해야한다.
-
샤딩도 있습니다.
-
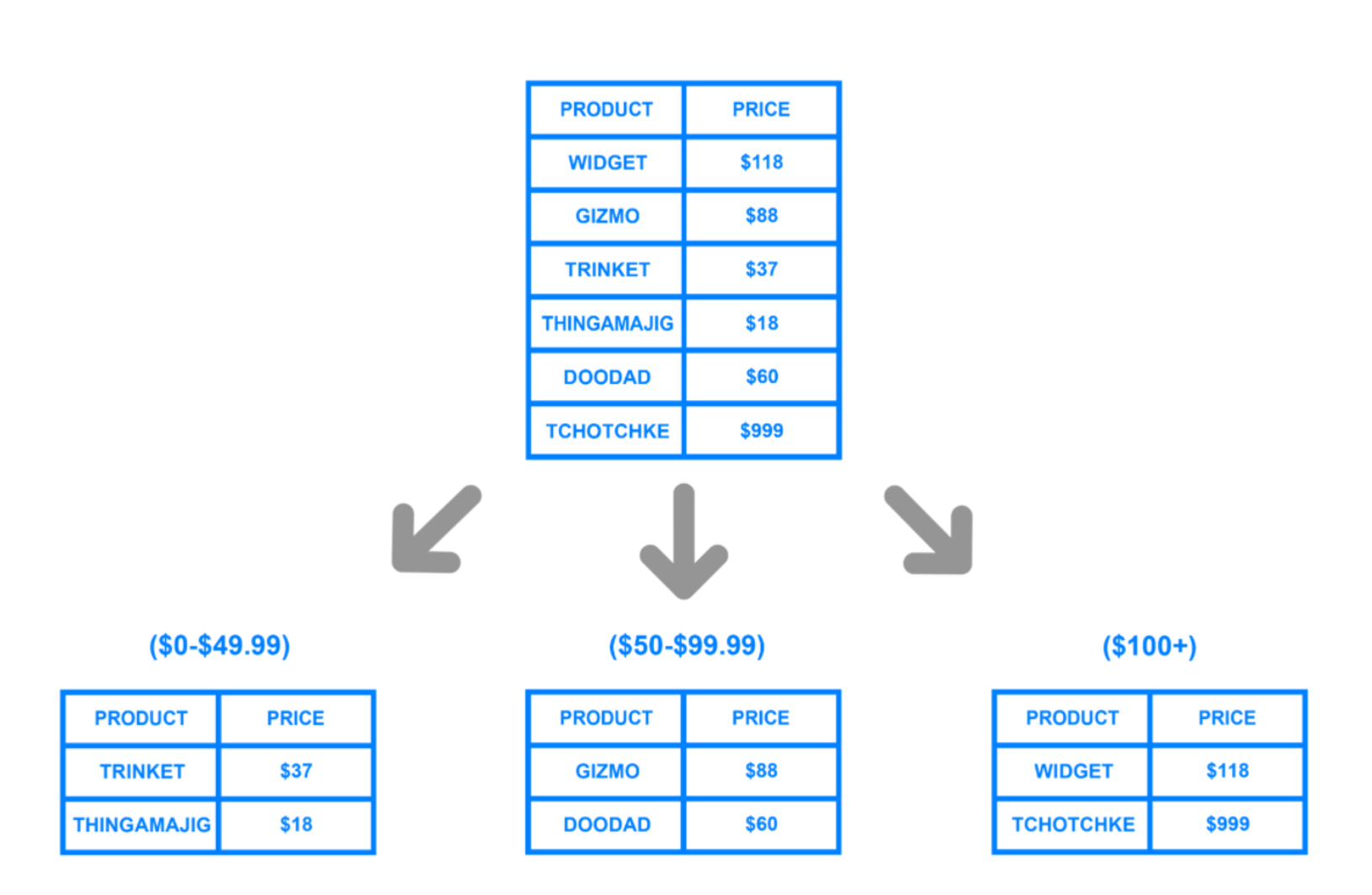
샤딩은 DB를 수평적으로 분할하는 방법입니다.
-
큰 데이터베이스를 작은
샤드라고 불리는 여러 개의 데이터베이스로 나누는 것을 의미합니다. -
각 샤드의 경우 데이터베이스의 독립적인 부분으로 작동, 전체 DB의 부하를 분산시키는 역할을 한다고 합니다.
샤딩의 종류
-
수평, 수직 샤딩
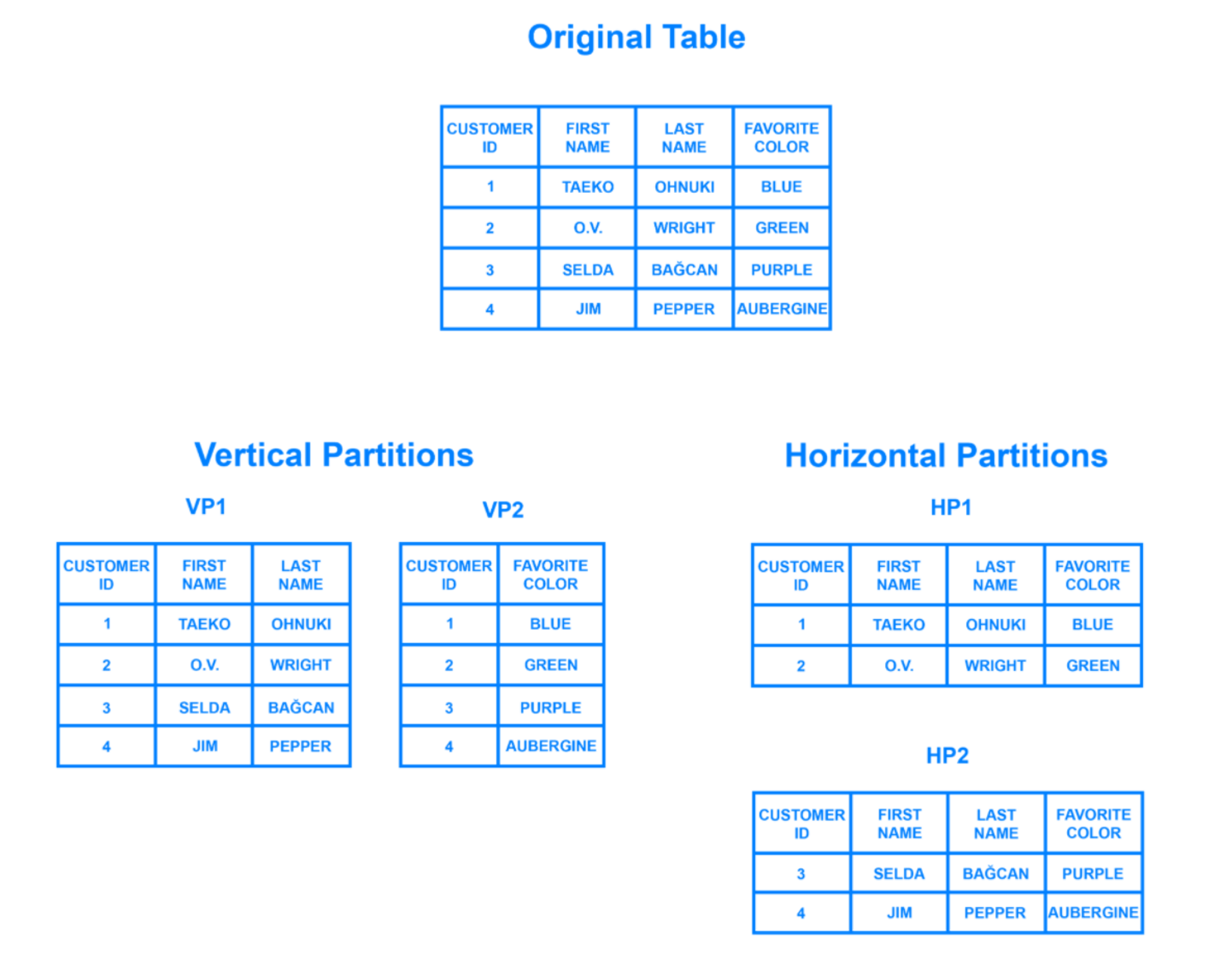
- 수평 샤딩
- 데이터를 행을 기준으로 분할하는 방식입니다.
- 각 샤드는 테이블의 특정 범위의 행을 가지고
모든 샤드가 동일한 스키마를 가짐
- 수직 샤딩
- 테이블을 열기준으로 분할하는 방식
- 각 샤드는 테이블의 특정 열 또는 열 그룹을 포함
- 특정 기능이나 서비스에 더 중점을 주는 경우 선택한다.
- 수평 샤딩
-
해시 기반 샤딩 ( Hash-Based Sharding )
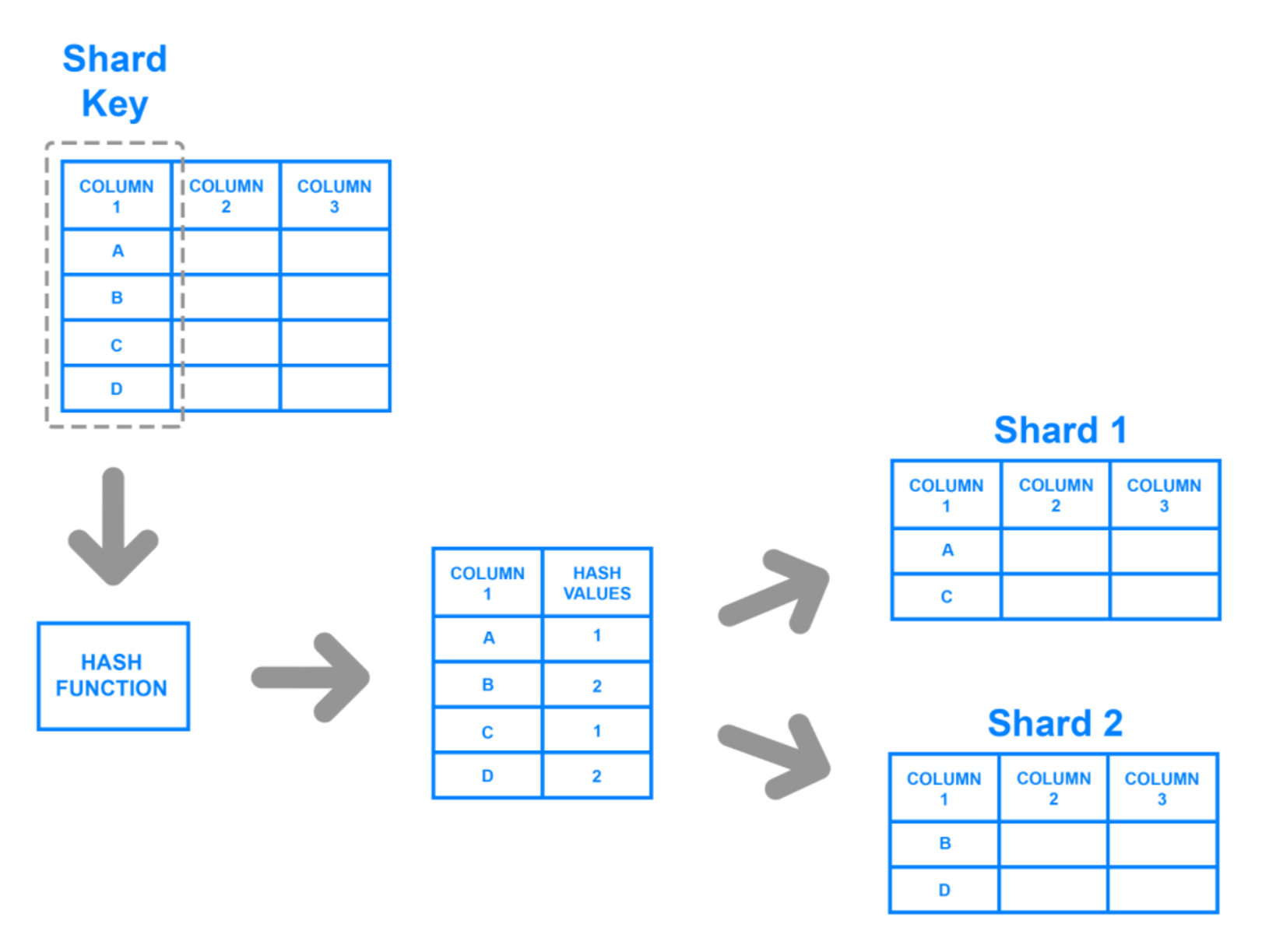
- 샤드를 결정하기 위해 해시 함수를 사용
- 데이터의 키를 해시 함수에 입력하면, 결과 해시 값이 어느 샤드에 데이터를 저장할지 결정하는 데 사용
-
범위 기반 샤딩 ( Range-Based Sharding )
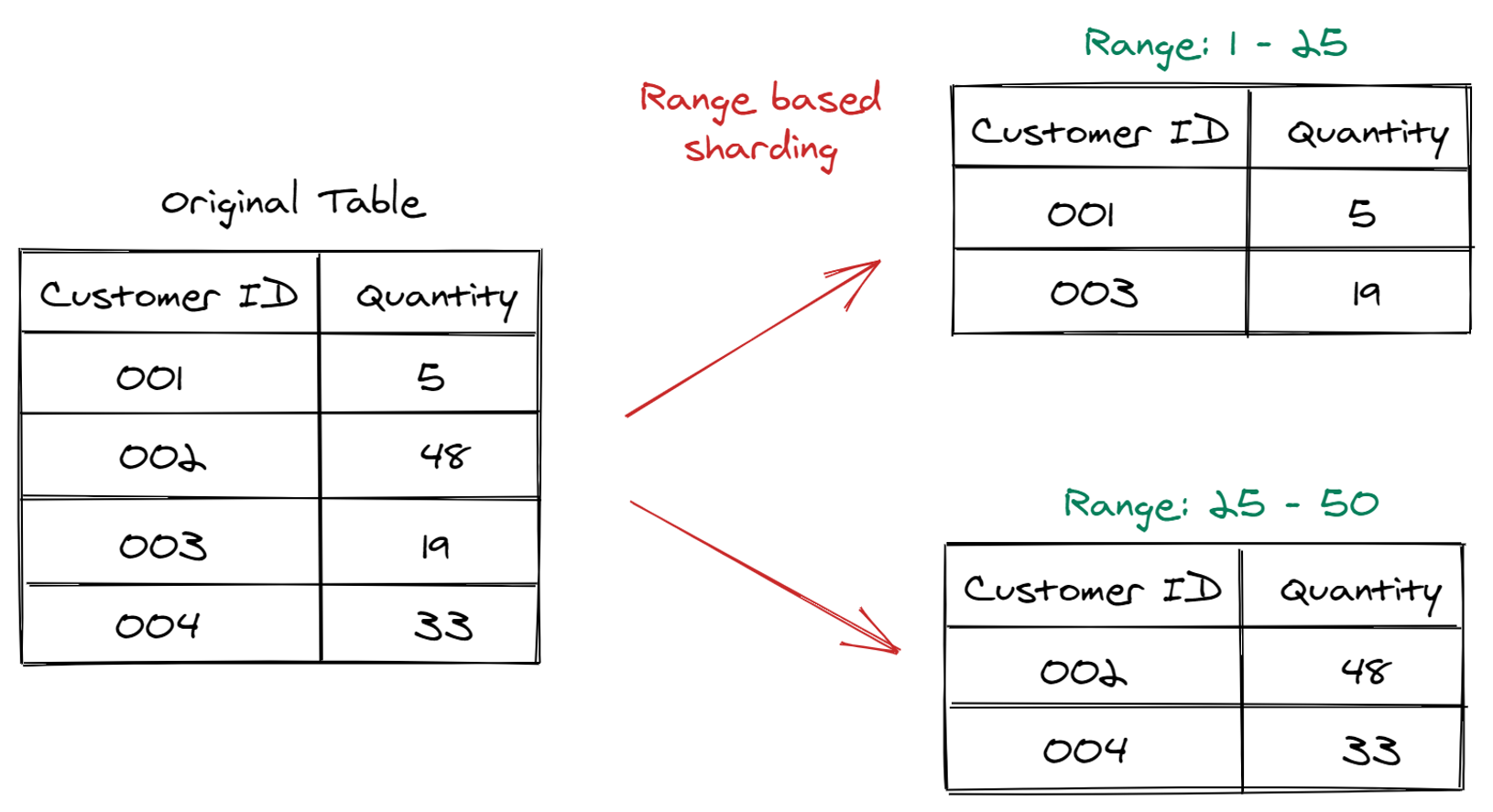
- 범위 샤딩은 데이터를 특정 범위에 따라 분할한다.
날짜 범위나숫자 범위를 기준으로 데이터를 샤드에 할당한다.- 예를 들어
-
사용자 ID가 1부터 1000까지인 데이터를
- 샤드 A
-
사용자 ID 가 1001부터 2000까지인 데이터를
- 샤드 B에 저장하는 식이다.
-
-
-
-
인메모리 DB에 대해서 고려
- 자주 접근하는 데이터를 메모리에 캐싱하여 DB의 부하를 줄이고 응답 시간을 개선할 수 있습니다.
- Redis 같은 인메모리 데이터 스토어를 사용할 수 있습니다.
- 자주 접근하는 데이터를 메모리에 캐싱하여 DB의 부하를 줄이고 응답 시간을 개선할 수 있습니다.
-
읽기 전용 복제본(Replica)을 사용
- 읽기 전용 복제본(Replica) 를 활용하여 읽기 요청이 많은 경우 주 데이터베이스(Main DB) 의 부하를 줄일 수 있다고 한다.
- 데이터를 조회하는 읽기 작업만 수행하는 경우 주 DB에서 처리할 필요는 없고, 복제본에서 읽기 작업을 처리하면 주 DB의 부하를 줄일 수 있을 것이다.
- 쇼핑몰에서 상품 정보를 조회하는 경우, 수 많은 읽기 요청이 발생하는데, 이걸 모두 주 DB에서 처리하면 DB에 부하가 발생함.
- 상품 조회는 복제본에서 처리하는 거임.
- 그렇게하면,
- 읽기 부하는 복제본이 감당
- 주 DB는 쓰기에만 집중이 가능함.
-

이전 블로그 : https://oth3410.tistory.com/