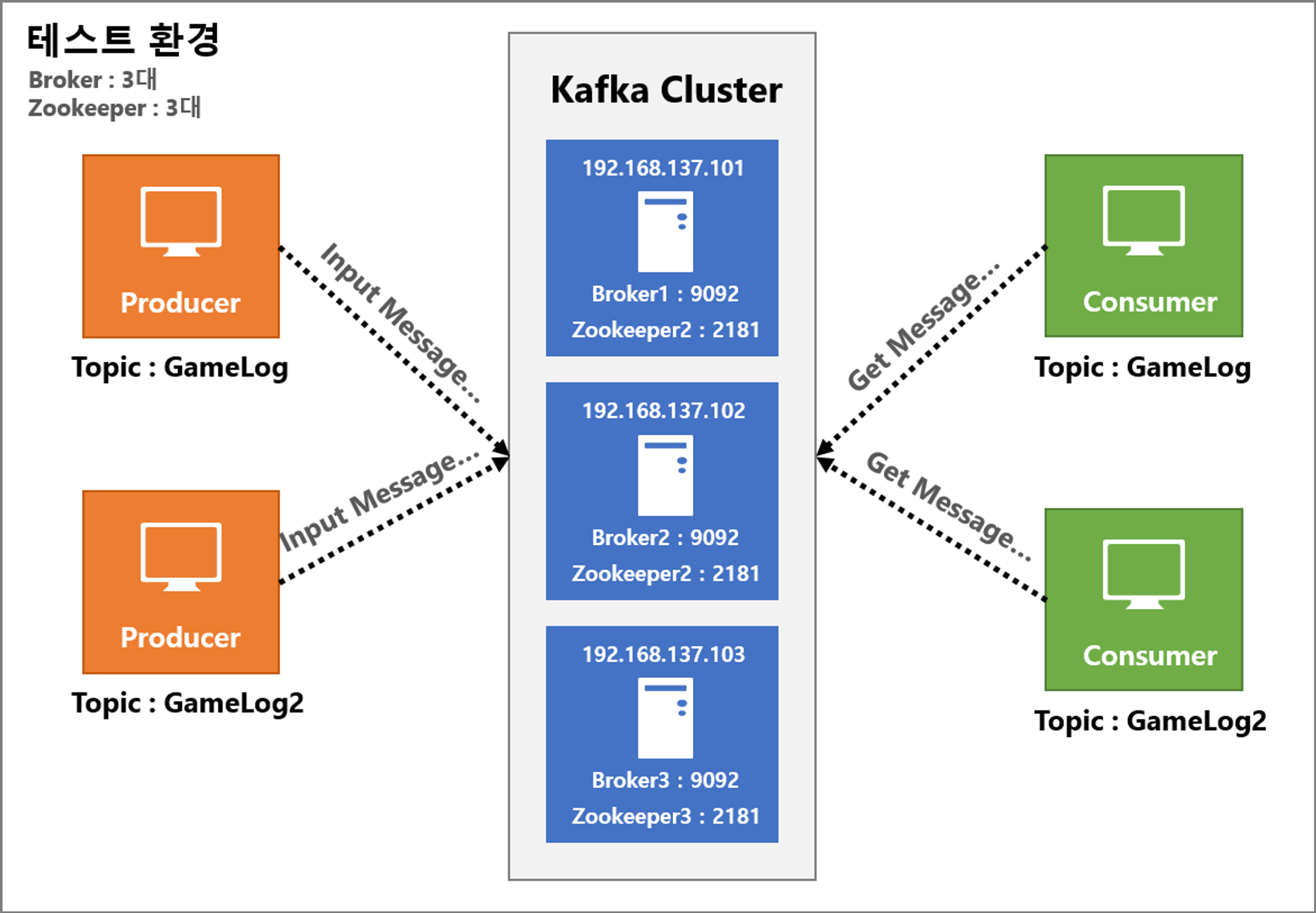
카프카 브로커·클러스터·주키퍼
카프카 브로커
- 정의
- 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체
- 데이터를 분산 저장하여 장애가 발생해도 안전하게 사용할 수 있음
- 실행 단위
- 하나의 서버에는 한개의 카프카 브로커 프로세스가 실행된다
- 기능
- 단일 브로커로도 구성이 가능하지만,
- 보통 REDIS Sentienl 같이 데이터의 안전한 보관과 처리를 위해 여러 대의 브로커 서버를 클러스터로 묶어 운영하는 것이 일반적이다.
카프카 클러스터
- 정의
- 3대 이상의 브로커 서버로 구성된 클러스터를 통해 데이터를 안전한 분산 저장과 복제를 수행함
- 역할
- 프로듀서로부터 받은 데이터 안전하게 분산 저장
- 컨슈머가 데이터를 요청하는 경우 해당 데이터 전달
주키퍼 앙상블
카프카 클러스터의 메타데이터 관리, 클러스터 내 브로커들의 상태 관리, 리더 선출 등의 역할을 수행
왜 카프카를 사용해야하는가? (성능 관점)
-
고처리량
- 카프카는 분산 시스템으로 기본적으로 설계되어있다.
- 수 천 개의 노드로 확장이 가능하다.
- 원하면 노드를 늘려서 엄청난 량의 데이터를 병렬적으로 처리할 수 있다.
-
빠른 데이터
- 실시간성을 유지하면서, 데이터를 배치로 처리하여 네트워크 요청의 오버헤드를 줄이고 ,데이터의 전송 속도를 높을 수 있다.
어떤 식으로 배치 처리를 하는 걸까?
- 카프카의 프로듀서가 메시지를 생성 & 카프카 브로커에 전송하는 역할
- 프로듀서는 메시지를 바로 전송하는 대신, 메모리 버퍼에 일정량의 메시지를 모은다.
- 해당 버퍼가 설정된 크기에 도달하거나, 설정된 시간이 경과하는 경우. 프로듀서는 이 메시지들을 하나의 큰 배치로 묶어 카프카 브로커에 전송한다.
- 브로커는 배치를 받아 디스크에 저장, 컨슈머(Consumer) 가 데이터를 요청할 때 이를 전달한다.
- 컨슈머 역시 배치로 데이터를 받아 처리함
-
실시간 스트리밍
- 실시간 데이터 스트리밍을 지원한다, 데이터가 생성되는 즉시 처리할 수 있음.
-
다중 컨슈머
- 여러 컨슈머가 동일한 데이터 스트림을 동시에 읽을 수 있도록 지원한다.
- 이는 데이터를 다양한 시스템과 어플리케이션에서 활용할 수 있도록 해준다.
왜 다중 컨슈머를 구성하는거임?
- 부하 분산
- 다중 컨슈머를 통해 메시지 처리 부하를 균등하게 분산시킨다.
- 각 컨슈머가 최적의 성능으로 작동하게 하는데, 전체 시스템의 부하를 관리하는 데 도움이 된다.
- 메시지 처리 속도 증대
- 동시에 여러 메시징 처리가 가능하기에 전체적인 메시지 처리 속도가 향상됨.
- 유연성
- 다양한 컨슈머 그룹을 설정, 각 컨슈머 그룹이 다른 목적으로 메시지를 처리하도록 할 수 있음.
- 하나는 실시간 모니터링
- 하나는 데이터 분석 ..등
- 다양한 컨슈머 그룹을 설정, 각 컨슈머 그룹이 다른 목적으로 메시지를 처리하도록 할 수 있음.

이전 블로그 : https://oth3410.tistory.com/