알파고 제로: 인간 데이터를 넘어선 AI 혁신
지난 포스팅에서는 알파고의 기본 원리와 역사적 순간들을 살펴보았습니다. 이번 글에서는 알파고 제로(AlphaGo Zero)의 등장과 함께, 기존 알파고와의 차이점, 기술적 혁신, 그리고 결과 분석을 자세히 알아보겠습니다.
Mastering the game of Go without human knowledge 논문의 6개의 Figure를 맛보기하는 시간이 되시길 바랍니다.
1. 알파고 제로(AlphaGo Zero)의 등장
알파고 제로는 딥마인드가 발표한 혁신적인 사례로, "인간 데이터를 사용하지 않고 스스로 학습하는 AI"라는 새로운 접근 방식을 선보였습니다. 간단히 말해, 바둑판 위의 천재가 혼자 성장한 셈이죠!
1.1 왜 ‘제로(Zero)’인가?
"Starting tabula rasa, our new program AlphaGo Zero achieved superhuman performance, winning 100–0 against the previously published, champion-defeating AlphaGo."
알파고 제로의 가장 큰 특징은 인간 기보(훈련 데이터)를 전혀 사용하지 않고, 오직 자가 학습(Self-play)만으로 탁월한 성능을 달성했다는 점입니다.
기존 알파고 vs. 알파고 제로: 기존 알파고는 인간 전문가의 기보 데이터를 지도학습(Supervised Learning)으로 학습하여 초기 정책 신경망을 구축했습니다. 반면, 알파고 제로는 초기 랜덤 상태에서 시작해 스스로 대국을 반복하며 전략과 기술을 발전시켰습니다.
‘제로’의 의미: 인간 데이터 없이 단순한 규칙만으로 학습을 시작한다는 점에서 새로운 AI 학습 방식의 가능성을 제시합니다.
2. 알파고 제로의 핵심 구조
"This neural network combines the roles of both policy network and value network into a single architecture."
단일 신경망(Combined Policy & Value Network): 알파고 제로는 기존 알파고의 정책 신경망(Policy Network)과 가치 신경망(Value Network)을 하나의 네트워크로 통합했습니다.
2.1 정책 신경망 (Policy Network)
정책 신경망은 바둑판 상태를 입력으로 받아, 가능한 모든 수에 대한 확률 분포를 출력합니다. 이를 통해 몬테카를로 트리 탐색(MCTS)의 탐색 우선순위를 결정합니다.
입력 (Input)
- 현재 바둑판 상태:
- 19x19 바둑판의 상태를 17개의 평면(Feature Planes)으로 표현.
- 각 평면은 흑돌, 백돌, 빈 칸, 이전 수 등의 정보를 포함.
- 크기:
19 × 19 × 17출력 (Output)
- 다음 수의 확률 분포:
- 현재 상태에서 가능한 모든 수(361개의 바둑판 위치)와 패스(pass)에 대한 확률 값.
- 이 확률은 MCTS 탐색에서 수의 우선순위를 결정하는 데 활용됩니다.
- 크기:
19 × 19 + 1(361개 좌표 + 1개의 패스)
2.2 가치 신경망 (Value Network)
가치 신경망은 현재 바둑판 상태를 입력으로 받아, 흑돌의 승리 가능성을 평가합니다. 이를 통해 MCTS 시뮬레이션 결과를 보완하고 효율성을 높입니다.
입력 (Input)
- 현재 바둑판 상태:
- 정책 신경망과 동일한 입력 데이터 사용.
- 크기:
19 × 19 × 17출력 (Output)
- 승리 가능성:
- 현재 상태에서 흑돌이 이길 확률을 나타내는 스칼라 값(0에서 1 사이).
- 1에 가까울수록 흑돌의 승리 가능성이 높음을 의미.
- 크기:
1
2.3 통합 신경망 구조
알파고 제로는 정책 신경망과 가치 신경망을 통합한 단일 신경망을 사용하여 효율성을 극대화합니다.
입력 (Input)
- 현재 바둑판 상태:
19 × 19 × 17출력 (Output)
- 정책 (Policy):
19 × 19 + 1(다음 수의 확률 분포)- 가치 (Value):
1(승리 가능성)
2.4 요약
신경망 Input (입력) Output (출력) 정책 신경망 19 × 19 × 1719 × 19 + 1: 다음 수의 확률 분포가치 신경망 19 × 19 × 171: 현재 상태에서 흑돌의 승리 가능성 (0~1)통합 신경망 19 × 19 × 17정책: 19 × 19 + 1
가치:1
2. 알파고 제로의 강화 학습
2.1 학습 프로세스
알파고 제로의 학습 과정은 아래와 같이 진행됩니다:
- 초기 무작위 플레이: 랜덤 수를 두며 데이터를 생성.
- MCTS 적용: 각 수의 확률 분포와 승리 확률 평가.
- 자가 대국 데이터 생성: 대국 결과를 학습 데이터로 저장.
- 데이터 버퍼 업데이트: 새로운 데이터로 신경망을 훈련.
- 성능 평가 및 반복 학습: 향상된 네트워크로 새로운 자가 대국 생성.
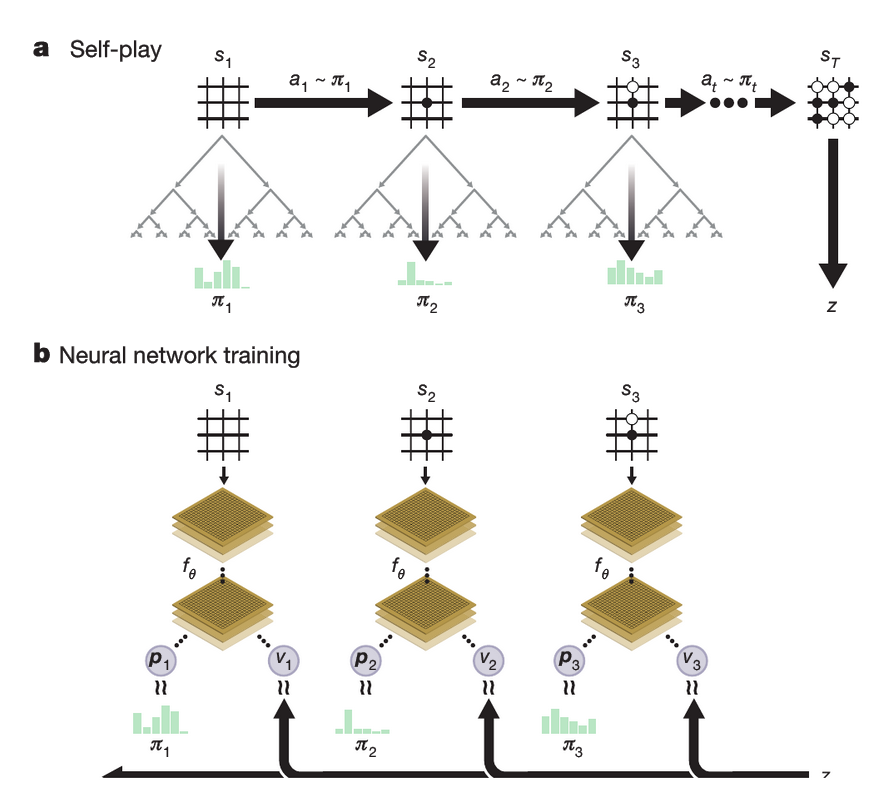
Figure 1: Self-play reinforcement learning in AlphaGo Zero
: 알파고 제로의 자가 학습(Self-play) 과정을 나타낸 다이어그램. 자가 대국과 신경망 훈련의 반복 과정을 시각화
a. 프로그램은 스스로 라는 게임을 진행합니다. 각 위치 에서는 최신 신경망 를 이용해 MCTS 가 실행됩니다 (Fig. 2 참조). MCTS에서 계산된 검색 확률 에 따라 다음 수 가 선택됩니다. 게임의 마지막 위치 는 규칙에 따라 점수를 매기고, 게임의 승자 를 결정합니다.
b. AlphaGo Zero의 신경망 학습 과정. 신경망은 바둑판 상태 를 입력으로 받아 여러 합성곱 계층(파라미터 포함)을 거칩니다. 결과적으로 신경망은 두 가지 출력을 만듭니다. 하나는 수에 대한 확률 분포를 나타내는 벡터 , 다른 하나는 현재 플레이어가 위치에서 이길 확률을 나타내는 스칼라 값 입니다. 신경망의 파라미터 는 두 가지 기준으로 업데이트됩니다. 첫째, 정책 벡터 와 검색 확률 간의 유사성을 최대화합니다. 둘째, 예측한 승자 와 실제 게임 결과 간의 오차를 최소화합니다 (식 (1) 참조). 업데이트된 파라미터는 a에서 설명한 방식으로 다음 자가 대국(iteration)에 사용됩니다.
* + +
2.2 알파고 제로의 훈련 과정
- 강화학습 파이프라인을 적용하여 알파고 제로(AlphaGo Zero)를 훈련.
- 훈련은 완전히 무작위 행동에서 시작했으며, 약 3일 동안 인간의 개입 없이 진행
훈련 진행:
- 훈련 과정에서 약 490만 번의 자가 대국(Self-play)이 생성되었습니다.
- 각 MCTS(Monte Carlo Tree Search)는 1,600회의 시뮬레이션을 실행.
- 각 수에 약 0.4초 소모: (3일 X 1600 시뮬레이션) / (490만 자가 대국 X 약 200수/대국)
**파라미터 업데이트:
- 훈련 중 약 70만 개의 미니배치(mini-batch)가 처리
- 각 미니배치에는 2,048개의 바둑판 상태(position)가 포함.
- 신경망은 총 20개의 Residual Block으로 구성
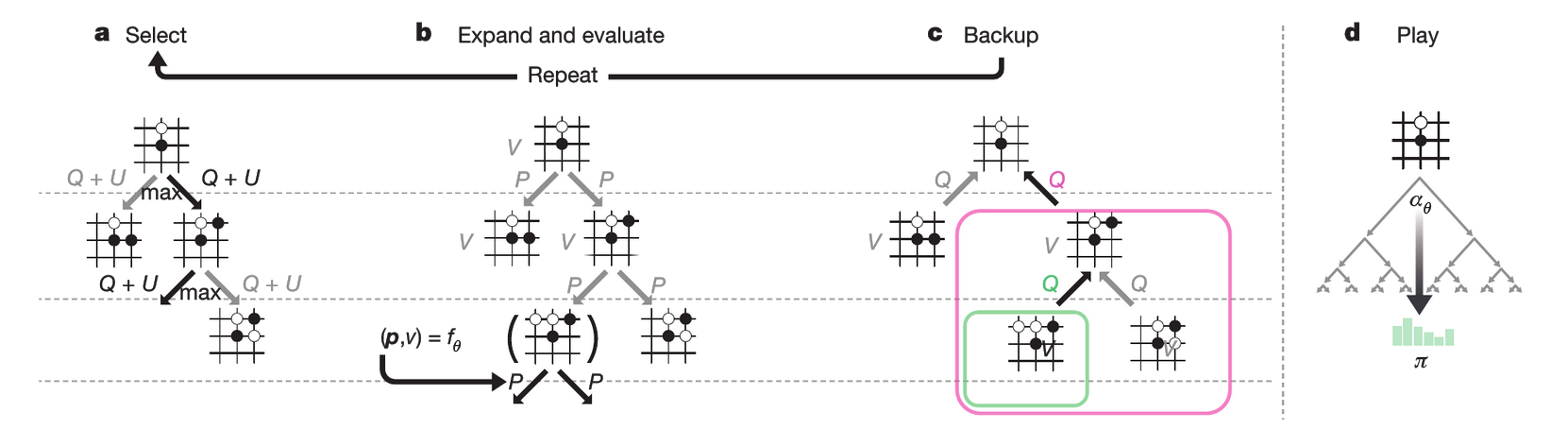
Figure 2: MCTS in AlphaGo Zero
: 알파고 제로에서 몬테카를로 트리 탐색(MCTS)의 구조와 동작 과정을 시각화
a. 각 시뮬레이션은 저장된 사전 확률 와 방문 횟수 에 따라 계산된 상한 신뢰 한계값 를 더한 행동 가치 가 최대인 엣지를 선택하며 트리를 탐색합니다. 엣지를 탐색할 때마다 방문 횟수 이 증가합니다.
b. 리프 노드(leaf node)가 확장되고, 해당 위치 는 신경망을 통해 평가됩니다. 이를 통해 생성된 사전 확률 벡터 와 평가 값 는 에 의해 계산되며, 에서 나가는 엣지에 값이 저장됩니다.
c. 행동 가치 는 해당 행동 아래의 서브트리에 대한 모든 평가 의 평균값으로 업데이트됩니다.
d. 탐색이 완료되면, 탐색 확률 가 반환됩니다. 이 확률은 루트 상태에서 각 수의 방문 횟수 에 비례하며, 로 계산됩니다. 여기서 는 온도(temperature)를 조절하는 파라미터입니다.
왜 (온도)가 사용되나요?
- 의 역할: 탐색 확률 를 계산할 때 탐색 분포의 집중도를 조정하는 역할
- 값이 높으면 각 수의 확률 분포 가 고르게 분산됩니다. 즉, 여러 선택지를 탐색할 가능성이 높아져 더 넓은 범위를 탐색할 수 있습니다.
- 값이 낮으면 특정 수에 높은 확률이 집중됩니다. 이로 인해 신뢰도 높은 수을 더 자주 선택하게 됩니다.
3. 성능 및 결과 분석
3.1 알파고 Elo 시스템
실력 격차 평가: Elo 차이로 승률 추정:
- 차이 200 → 승률 약 76%
- 차이 400 → 승률 약 91%
3.1.1 승리 확률 계산
두 에이전트 와 가 대결했을 때, 의 승리 확률:
- : 각각 와 의 Elo 레이팅
3.1.2 레이팅 업데이트
경기 결과에 따라 레이팅을 업데이트:
- : 실제 경기 결과 (승리: 1, 패배: 0, 무승부: 0.5)
- : 예상 결과, ,
- : 레이팅 변경 민감도
3.2 알파고 제로: 72시간 만에 알파고 리를 압도
"AlphaGo Zero defeated AlphaGo Lee by 100 games to 0."
알파고 제로는 기존 알파고와 비교했을 때 학습 효율성과 성능에서 큰 차이를 보임.
- 100전 전승: 알파고 제로는 기존 알파고 리(Lee)를 상대로 100전 100승을 기록하며 압도적인 우위를 증명.
- Elo 600 향상: Residual Network와 결합된 네트워크 사용한 결과로 계산 효율성 개선 및 일반화 모델 구현 효과.
특히, 알파고 제로는 단일 머신에서 4개의 TPU를 사용한 반면, 알파고 리는 분산 환경에서 48개의 TPU를 사용했음에도 불구하고 승리했습니다.
Figure 3: Empirical evaluation of AlphaGo Zero
: 알파고 제로의 경험적 평가와 실험 데이터를 요약한 도표. Elo 레이팅 상승과 대국 성능을 중심으로 분석
a. 자가/강화학습의 성능
이 그래프는 알파고 제로의 강화학습 반복 단계 에서 생성된 각 MCTS 플레이어 의 성능을 보여줍니다.
각 플레이어의 Elo 레이팅은 서로 다른 플레이어 간 평가 대국을 통해 계산되었으며, 각 수마다 사고 시간으로 초가 주어졌습니다.
또한, 비교를 위해 KGS 데이터셋을 사용해 인간 데이터를 기반으로 지도학습된 플레이어의 성능도 함께 나타냈습니다.b. 인간 프로 수에 대한 예측 정확도
그래프는 자가 대국 반복 단계 에서 신경망 가 GoKifu 데이터셋의 인간 프로 바둑 수를 얼마나 정확히 예측했는지를 보여줍니다.
정확도는 신경망이 인간의 수에 가장 높은 확률을 할당한 위치의 비율로 측정되었습니다.
지도학습된 신경망의 정확도 역시 비교를 위해 추가로 표시되었습니다.c. 인간 프로 경기 결과에 대한 평균 제곱 오차(MSE)
이 그래프는 자가 대국 반복 단계 에서 신경망 가 GoKifu 데이터셋의 인간 프로 경기 결과를 예측한 평균 제곱 오차(MSE)를 나타냅니다.
MSE는 실제 경기 결과 와 신경망이 예측한 값 간의 차이를 계산합니다.
이 값은 로 스케일링되어 0에서 1 사이의 범위로 조정되었습니다.
지도학습된 신경망의 MSE 역시 참고를 위해 포함되어 있습니다.
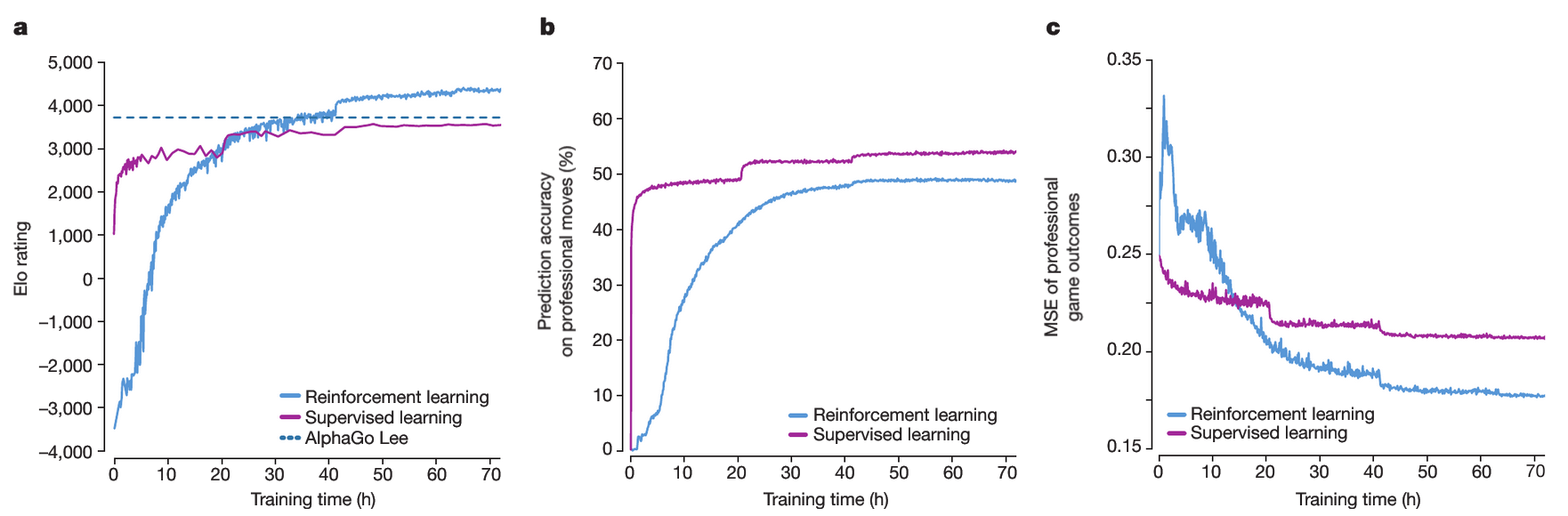
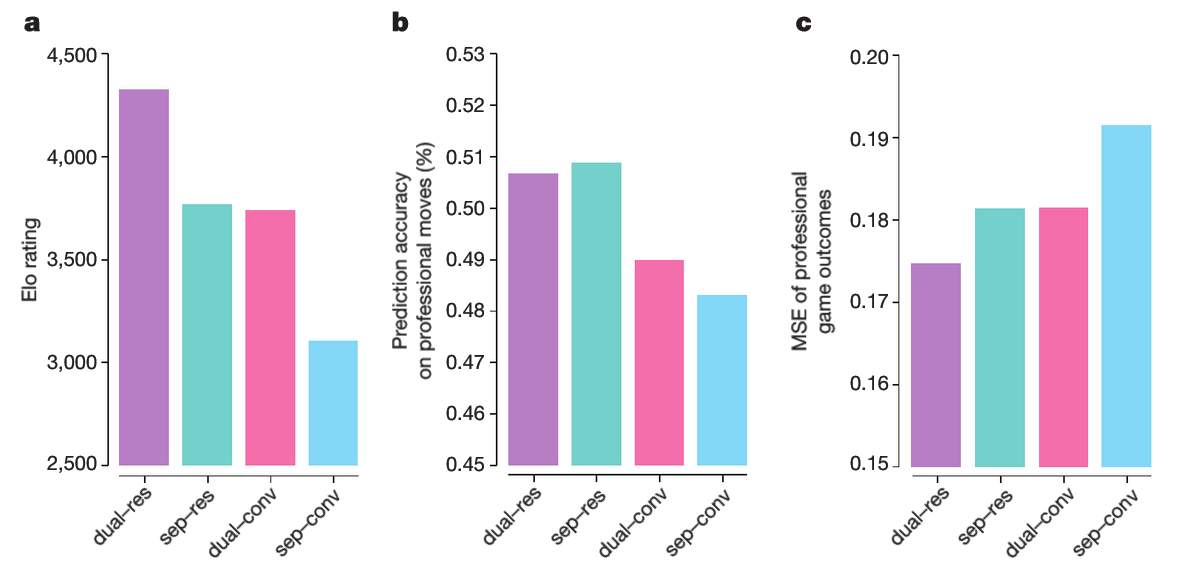
Figure 4: Comparison of neural network architectures in AlphaGo Zero and AlphaGo Lee
: 알파고 제로와 알파고 리의 신경망 구조를 비교한 도식.
다양한 신경망 구조를 비교한 내용으로, 정책 네트워크와 가치 네트워크를 분리(sep)하거나 결합(dual)한 방식과, 합성곱(convolutional, conv) 또는 잔여(residual, res) 네트워크를 사용한 방식을 다룹니다.
'dual–res'는 알파고 제로에서 사용된 신경망 구조를, ‘sep–conv’는 알파고 리에서 사용된 구조를 나타냅니다. 각 신경망은 알파고 제로의 이전 학습 결과에서 생성된 고정된 데이터셋으로 학습되었습니다.a. 각 신경망은 알파고 제로의 탐색 알고리즘과 결합하여 서로 다른 플레이어를 생성했습니다. 각 플레이어의 Elo 레이팅은 이 플레이어들 간의 대국 평가를 통해 계산되었으며, 수당 5초의 사고 시간을 사용했습니다.
b. 각 신경망 구조에서 인간 프로 바둑 기보(GoKifu 데이터셋)에 기반한 수 예측 정확도를 평가했습니다.
c. 각 신경망 구조에서 인간 프로 바둑 경기 결과(GoKifu 데이터셋)에 대한 MSE(평균 제곱 오차)를 측정했습니다.
3.3 알파고 제로의 학습 곡선 및 최종 성능
- 학습 속도 비교: 기존 알파고는 프로 수준에 도달하는 데 수개월이 걸렸지만, 알파고 제로는 단 3일 만에 이를 초월.
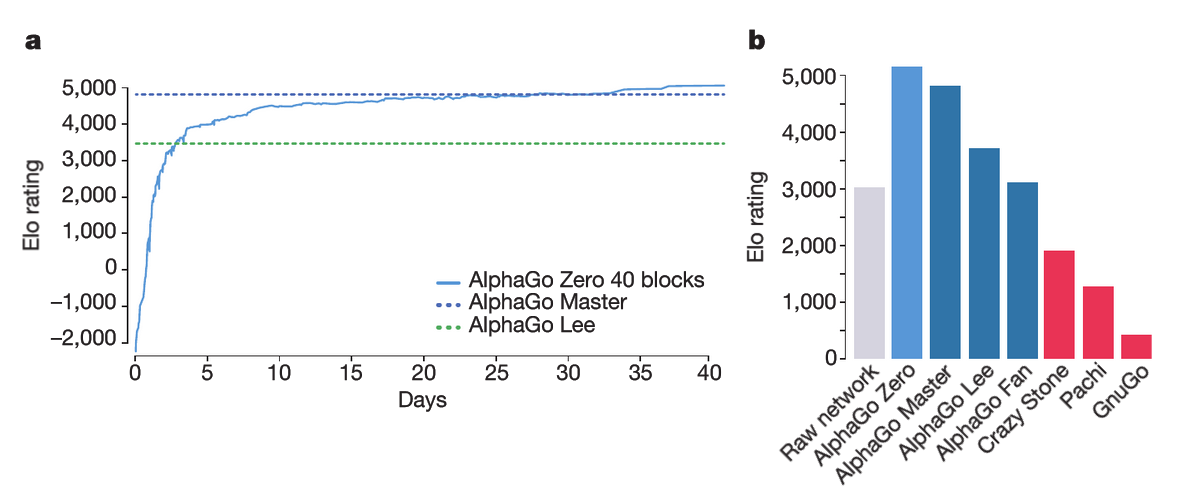
Figure 6: Performance of AlphaGo Zero
: 72시간 내 성능 변화와 최종 결과
a. 40일간의 학습 곡선
40개의 Residual Block으로 구성된 대규모 신경망을 사용해 40일 동안 알파고 제로를 학습시킨 결과를 나타낸 그래프입니다. 그래프는 강화학습 알고리즘의 각 반복 단계 에서 생성된 플레이어 의 성능을 보여줍니다. 각 플레이어의 Elo 레이팅은 서로 다른 플레이어 간 대국 평가를 통해 계산되었으며, 수당 0.4초의 사고 시간이 주어졌습니다.
b. 알파고 제로의 최종 성능
알파고 제로는 40개의 Residual Block을 사용하는 신경망으로 40일간 훈련되었습니다. 아래는 주요 대국 결과를 정리한 내용입니다:
- 대국 조건:
- 각 프로그램은 수 당 5초의 사고 시간이 주어졌습니다.
- AlphaGo Zero와 AlphaGo Master는 Google Cloud의 단일 머신에서 실행되었습니다.
- AlphaGo Fan과 AlphaGo Lee는 다중 머신 환경에서 실행되었습니다.
- 알파고 제로의 원신경망(raw neural network)도 포함되었으며, 이는 MCTS 없이 확률 가 가장 높은 수을 직접 선택했습니다.
- 평가 방법:
- Elo 레이팅을 사용해 성능을 평가했습니다. (Elo 점수 차이가 200점일 경우, 점수가 높은 쪽이 75%의 확률로 승리)
4. 알파고 제로의 학습 과정
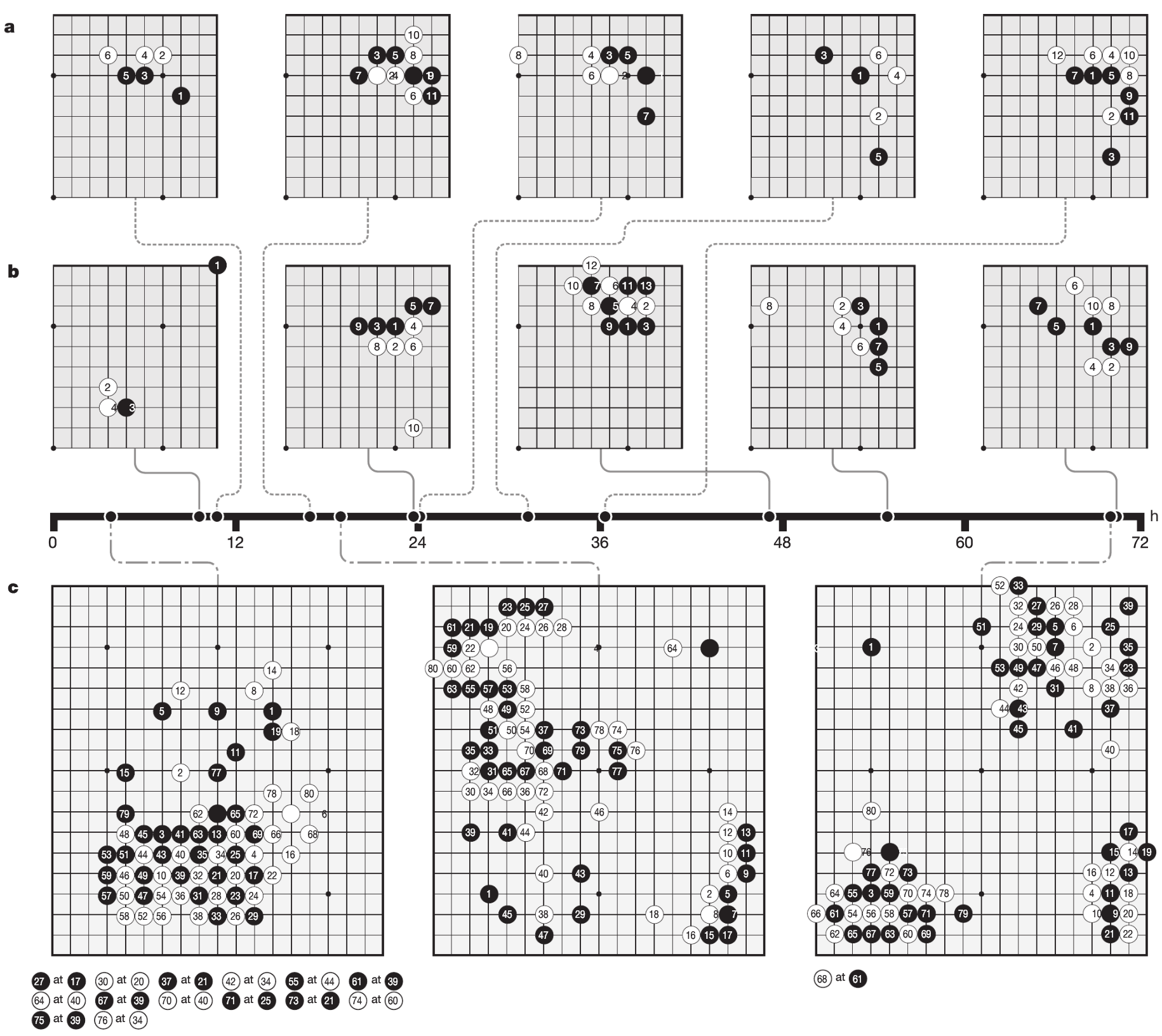
Figure 5: Go knowledge learned by AlphaGo Zero
: 알파고 제로의 자가 학습에서 발견된 정석과 게임 분석
a. 자가 학습에서 발견된 5개의 정석
알파고 제로의 학습 과정에서 발견된 5개의 정석입니다.b. 학습 단계별로 선호된 정석
자가 학습의 다양한 단계에서 선호된 5개의 정석이 있습니다.
각 단계에서 나타난 수순 중 가장 빈도가 높은 정석이 기록되었으며, 타임라인에 해당 시점이 표시되어 있습니다.
- 학습 10시간 시점에서는 별로인 수순이 선호되었습니다.
- 학습 47시간 시점에서는 3–3 침입이 가장 많이 사용되었습니다. 이 정석은 인간 프로 바둑에서도 흔히 사용되지만, 알파고 제로는 이후 이를 변형한 수순을 선호하고 있습니다.
c. 자가 학습 단계별 초기 게임 80수 분석
알파고 제로가 학습의 서로 다른 시점에서 진행한 3개의 자가 대국에서 초기 80수를 분석한 결과는 다음과 같습니다.
- 3시간 시점: 게임은 초보자처럼 단순히 돌을 많이 따내는 데 집중했습니다.
- 19시간 시점: 생사 문제, 세력, 집과 같은 바둑의 기본 개념이 드러나기 시작했습니다.
- 70시간 시점: 대국이 놀랍도록 균형을 이루며, 여러 번의 전투와 복잡한 팻감 싸움이 포함되었습니다. 결국 흰돌이 반집 차이로 승리했습니다.
5. 마무리
알파고 제로는 기존 알파고의 한계를 넘어, 인간 데이터를 사용하지 않는 학습 방식으로 새로운 가능성을 열었습니다.
힌편. 본 포스팅이 논문의 모든 정보를 담고 있진 않습니다. 자세한 설명이나 Extra 자료는 논문을 통해 직접 확인해보시기 바랍니다.
다음에도 새로운 소식으로 찾아뵙겠습니다! 😊
