
안녕하세요~
지난 포스팅에서는 Dart API를 이용해 최신 공시 보고서를 추출하는 과정을 소개하며, 데이터를 어떻게 가져오는지 알아보았습니다.
이번 2화에서는 1화에서 추출한 정보를 검증한 후, 추가된 기능들과 별도로 진행한 분석 및 검증 작업들을 통해 프로젝트가 어떻게 진화했는지 생생하게 전해드릴게요.
1. 사업보고서 정보 정리
1.1 ChatGPT를 활용한 보고서 분석
-
분석 과정:
추출한 사업보고서와 반기보고서의 XML 파일을 ChatGPT에 입력해, 품질 담당자 관점에서 중요한 항목(고객사, 홈페이지, 매출액, 제품 등)을 분석하도록 했습니다.
"이 정도면 우리 정보는 제대로 짚은 건가?"라는 호기심 어린 질문에, ChatGPT가 깔끔한 요약을 제시해 주었어요. -
분석 결과:
ChatGPT가 뽑아낸 핵심 정보는 최신 데이터와 당사에서 직접 파악한 정보와 대체로 일치했습니다.
덕분에 데이터의 활용 가능성이 높고, 실무에도 무리 없이 적용할 수 있음을 확인할 수 있었어요.

1.2 실제 정보 일치도 확인
-
현장 검증:
당사에서 이미 파악 중인 최신 고객사 정보와 ChatGPT의 요약 결과를 비교해 보니, 거의 흡사한 결과가 나왔습니다.
"이 정도면 믿어도 되겠네!"라는 생각이 절로 들었어요. -
공개할 수는 없지만 아래는 당사에서 파악하고 있는 자료입니다.
1.3 API 적용의 한계와 전략 전환
- 한계점:
보고서 전체를 API로 처리하려 하니, 처리해야 할 토큰 수가 급증하는 문제가 발견되었습니다.
(토큰 수가 늘어나면 비용과 속도 모두 문제가 될 수 있죠…)
ChatGPT API에 과도한 양의 메시지를 전송하여 최대 토큰 제한을 초과하면 다음과 같은 오류 메시지가 발생합니다:
{
"error": {
"message": "This model's maximum context length is 4097 tokens. However, your messages resulted in 4112 tokens. Please reduce the length of the messages.",
"type": "invalid_request_error",
"param": "messages",
"code": "context_length_exceeded"
}
}찾아보니, gpt-3.5-turbo: 최대 4096 토큰, gpt-4: 최대 8192 토큰 이 허용량으로 알려져 있네요.
- 전략 변경:
그래서 OpenAPI를 활용해 필요한 부분만 추출하는 전략으로 전환했습니다.
이렇게 하면 불필요한 부담 없이 핵심 정보만 딱! 뽑아낼 수 있습니다.
2. openAPI로 (고객사) 공시정보 추출
2.1 API 개발 매뉴얼 확보
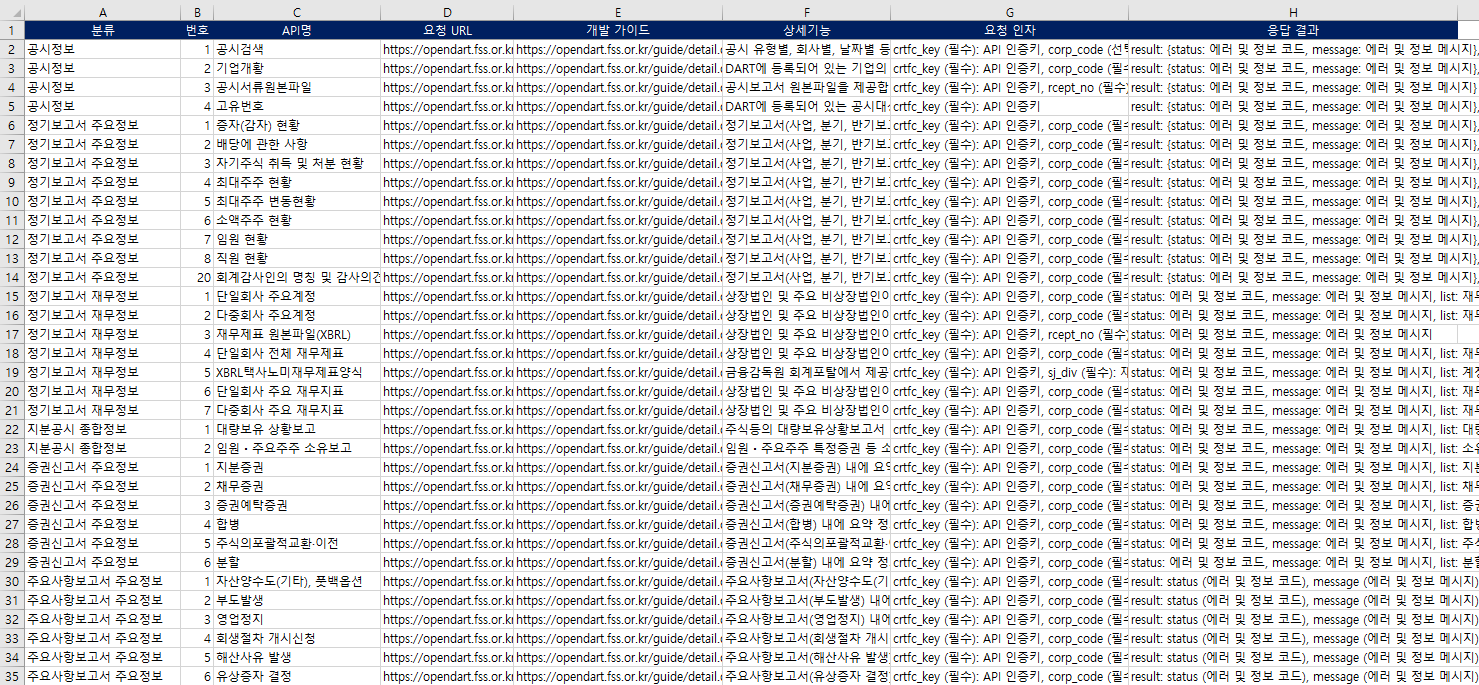
- 매뉴얼 자료:
API 개발에 필요한 모든 가이드라인은Manual_DartAPI.xlsx파일에 정리해 두었으며, 이 문서를 바탕으로 각 API 엔드포인트의 사용법과 특징을 꼼꼼하게 파악할 수 있었습니다.
2.2 비동기 API 호출을 통한 정보 추출
- 개발 내용:
신규 소스에서는build_api_calls함수를 활용해 다양한 Dart API 엔드포인트를 하나의 리스트로 구성한 후, 비동기로 호출합니다.- 재무정보, 재무지표, 영업정지, 부도발생, 소송제기 등 여러 정보를 동시에 추출할 수 있게 되었어요.
- 모든 결과는 하나의 DataFrame으로 통합되어 CSV 파일로 저장되므로, 후속 데이터 분석이나 시각화 작업에 아주 유용합니다.
async def update_all_company_data(
company_name: str,
company_code: str,
start_date: str,
end_date: str,
bsns_year: str = "",
report_code: str = "",
debug: bool = False
):
report_dir = f"dart_data/{company_code}"
os.makedirs(report_dir, exist_ok=True)
# API 호출 구성 함수 호출
api_calls = build_api_calls(company_code, start_date, end_date, bsns_year, report_code)
tasks = []
labels = []
for call in api_calls:
if call["flag"]:
# API 함수 호출 (주석: 해당 API 사용)
tasks.append(call["func"](*call["args"]))
labels.append(call["label"])
results = await asyncio.gather(*tasks)
# 각 결과의 레코드 수 출력 (검증용)
for label, df in zip(labels, results):
print(f"{label}: {len(df)} 레코드")
# 데이터 저장 함수 호출
save_dataframes(report_dir, company_name, labels, results, debug)def _call_api(endpoint_key: str, params: dict, list_key: str = "list", xml: bool = False) -> pd.DataFrame:
endpoint = ENDPOINTS.get(endpoint_key)
if not endpoint:
raise ValueError(f"Unknown endpoint key: {endpoint_key}")
url = endpoint["url"]
params["crtfc_key"] = API_KEY
resp = requests.get(url, params=params)
if xml:
if resp.status_code == 200:
df = pd.DataFrame([{ "rcept_no": params.get("rcept_no"), "document": resp.text }])
else:
df = pd.DataFrame()
else:
try:
data = resp.json()
except Exception:
data = {}
if data.get("status") == "000":
items = data.get(list_key) if list_key is not None else data
df = pd.json_normalize(items) if items else pd.DataFrame()
else:
df = pd.DataFrame()
print(f"{endpoint_key}: fetched {len(df)} records")
return df# 데이터 프레임 저장을 모듈화한 함수
def save_dataframes(report_dir, company_name, labels, results, debug):
combined = pd.concat(results, ignore_index=True)
combined_file = os.path.join(report_dir, f"{company_name}_merged.csv")
combined.to_csv(combined_file, index=False, encoding="utf-8-sig")
print(f"모든 데이터가 합쳐져 {combined_file} 에 저장됨")
if debug:
# 개별 데이터 프레임 저장 (디버그 모드)
for label, df in zip(labels, results):
debug_file = os.path.join(report_dir, f"{company_name}_{label}.csv")
df.to_csv(debug_file, index=False, encoding="utf-8-sig")
print("디버그 모드: 개별 파일 저장됨")
else:
print("live 모드: 개발 중")2.3 추출된 결과
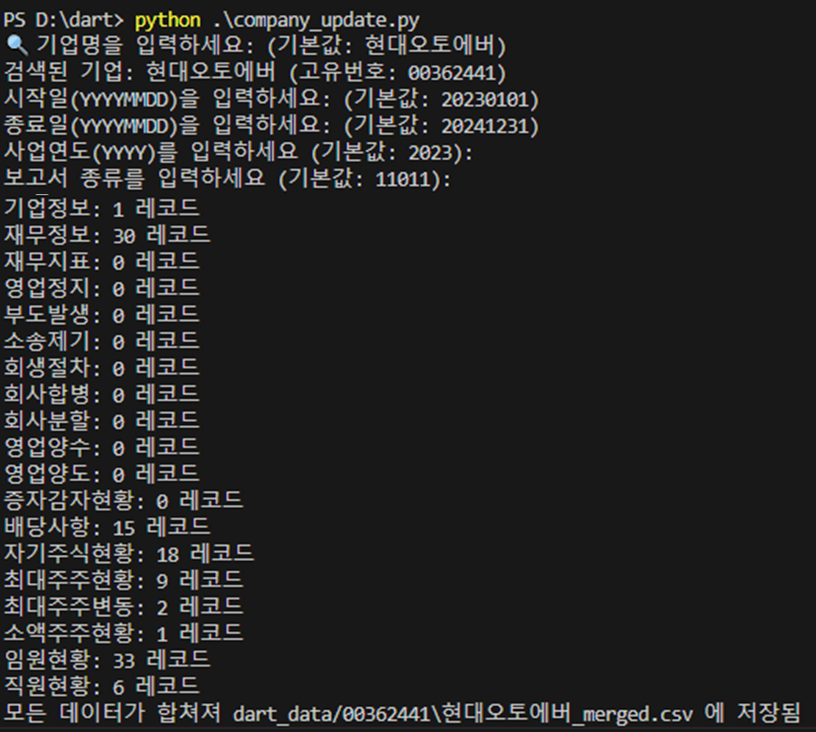
- 데모 시연:
실제 API 호출과 데이터 통합 과정을 시연한 화면 캡처 및 동영상 자료를 준비 중입니다.
여러분도 이 모습을 통해 실시간 데이터 추출의 놀라운 속도를 체감해 보실 수 있을 거예요!

3. 다음 예고
-
정보 파싱하기:
- ChatGPT를 활용한 보고서 파싱과 직접 XML 파싱 방식 두 가지 버전을 비교 분석할 예정입니다.
- 각 방식의 장단점을 꼼꼼하게 다뤄, 최적의 파싱 방법을 찾아볼 계획이에요.
-
고객사 정보 관리 컨버팅:
- 당사에서 고객사 정보를 어떻게 관리하고 있는지, 그리고 이를 데이터베이스(RDBMS) 연동을 통해 체계적으로 관리하는 방법을 소개할 예정입니다.
감사합니다!
