
[ 글의 목적: 페이지네이션 기본 개념 정리, drf 에서 기본 제공하는 페이지네이션 class 분석과 정리 ]
DRF Pagination
pagination 을 왜 사용하는가? 특정 데이터 GET ALL 하는 API 는 기본적으로 양이 너무 많다. 네트워크 비용, 퍼포먼스, 최적화 등의 관점에서 pagination 은 특정 상황을 제외하곤 필수다. 몇 천개를 select 하느라 DBMS lock 이 되는 상황을 아무도 원하지 않는다. 이는 server side 뿐 아니라 client side 에서도 rendering 과 직결된다.
1. Pagination
-
앞서 언급한 바와 같이, 네트워크 비용, 퍼포먼스, 최적화 등의 관점에서 pagination 은 특정 상황을 제외하곤 필수다.
-
익히 알듯, 페이지네이션은 "결과를 가져올 때 데이터를 분할하고 번호를 매겨 일부만 가져오는 기법" 이다. 이는
server side뿐 아니라client side에서도 중요하다. -
기본적으로 크게 "2가지 페이지네이션이" 있다. 사실 여기서 다루는 페이지네이션을 더 정확하게 표현하자면 RDBMS 에서 table의 data를 분할해서 가져오는 방법 을 의미한다. (기준은
MySQL&Postgresql)
1) offset
-- 2번째 페이지 (10개 아이템, 10번째부터 시작)
SELECT * FROM table_name
LIMIT 10 OFFSET 10;- (ps.
LIMIT는 가져오는 개수를 제한하는 것) OFFSET은 기본적으로 뛰어넘는 row 개수 를 의미한다.- DBMS 는
OFFSET에 지정된 수만큼의 행을 스캔하고 건너뛰어야 한다.
SELECT * FROM table_name
LIMIT 10 OFFSET 100000000;- 그래서 앞부분의 데이터를 조회할 경우 문제가 되지 않지만 10만 부터 40개씩 등과 같은 방식으로 조회할 경우 느려진다.
- 왜? 데이터 개수는 변경될 수 있기 때문에 매번 데이터를 확인하여 (full-scan) 해당 offset 수 만큼 지나가야 하기 때문이다!
치명적인 문제
| 시간 | 데이터베이스 상태 (데이터 ID) | 페이지 요청 | 반환된 데이터 | 설명 |
|---|---|---|---|---|
| T1 | 1, 2, 3, 4, 5, 6, 7, 8, 9 | Page 1 | 1, 2, 3 | 초기 상태에서 첫 번째 페이지 요청 |
| T2 | 1, 2, 3, 4, 5, 6, 7, 8, 9 | Page 2 | 4, 5, 6 | 두 번째 페이지 요청 |
| T3 | 1, 2, 3, A, B, C, 4, 5, 6, 7, 8, 9 | Page 1 | 1, 2, 3 | 페이지 1 요청, 데이터 3개 추가됨 |
| T4 | 1, 2, 3, A, B, C, 4, 5, 6, 7, 8, 9 | Page 2 | A, B, C | 추가된 데이터 때문에 기존 페이지 2의 데이터가 사라짐 |
| T5 | 1, 2, 3, A, B, C, 4, 5, 6, 7, 8, 9 | Page 3 | 4, 5, 6 | 페이지 3에서 이전 페이지 2의 데이터를 중복 확인 |
- 만약 2번 페이지를 조회 완료 했는데, 1번 페이지에 데이터 3개가 추가 된다면? -> 3번 페이지에서는 2번에서 봤던 데이터 3개가 중복되어서 보여진다. 이는 삭제의 경우도 같다!
장점
- 일반적인 방식으로 쿼리가 복잡하지 않다.
- 다양한 정렬 방식을 쉽게 구현할 수 있다.
- FE 에서
Pagination bar를 쉽고 빠르게 구현할 수 있다.
단점
- 페이지의 뒤로 갈수록 쿼리의 속도가 매우 느려진다.
- 데이터의 잦은 추가와 삭제가 이루어졌을 때 누락과 중복이 발생할 수 있다.
- 실시간으로 빠르게 데이터가 추가 삭제되는 서비스 (ex. SNS 등)에서는 대단히 오류가 많고 속도가 느릴 것이다!
2) cursor (zero offset)
offset을 사용하지 않아서zero offset방식이라고도 한다.
-- 2번째 페이지
SELECT * FROM table_name
WHERE id > 10
LIMIT 10;offset방식과 같은 결과 query 를 커서 방식은 위와 같이 표현할 수 있다. 아래와 같이WHERE조건절에 pk 값 (int, auto_incre 라 가정) 을 위와 같이 세팅해서 가져올 수 있다.
SELECT * FROM product WHERE id > {기준값} LIMIT 40;
SELECT * FROM product WHERE id > 40 LIMIT 40; -- 41~80
SELECT * FROM product WHERE id > 80 LIMIT 40; -- 81~120
SELECT * FROM product WHERE id > 120 LIMIT 40; -- 121~160
SELECT * FROM product WHERE id > 160 LIMIT 40; -- 161~200- 근데 만약 id 값을 내림 차순으로 가져오려면?
- 정렬이 들어가면
cursor는 조금 골치아프다. 내림 차순으로 가져오려면 id 대소값이 "적다" 로 바뀌어야 하는데, 전체 데이터 개수를 모르면? 그 값과 기준을 정하기 어렵다.
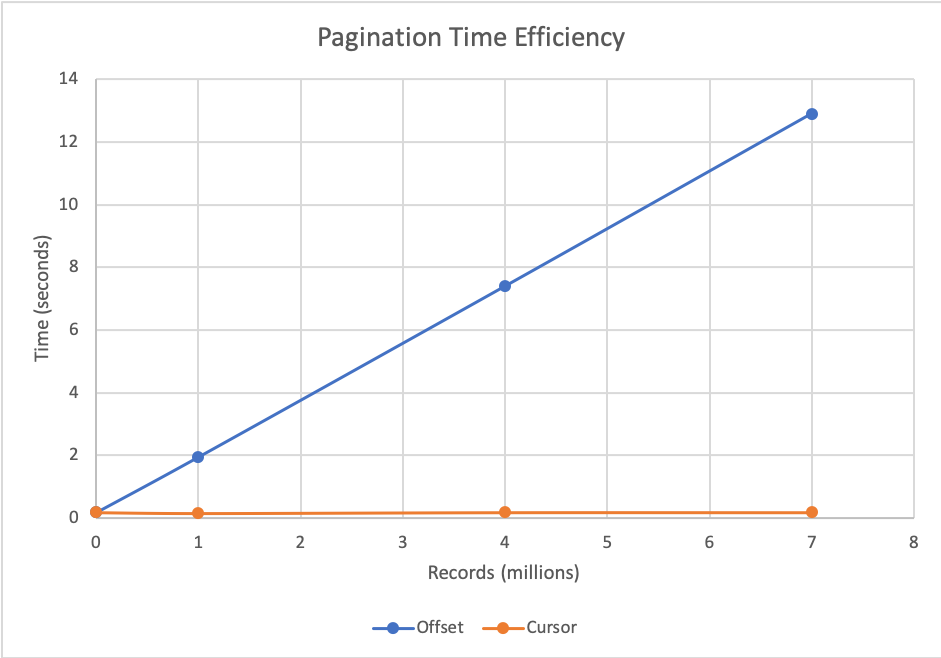
- 둘 다 같은 상황의 index scan 을 한다고 가정하고 (oder by 등 없을때) 단순한 시간 효율성은 커서가 압도한다.
- 하지만
cursor는 제한된 정렬 기능 을 가질 수 밖에 없다. 특정 지점으로 커서를 지정할 수 있어야 하고 (위 경우 id 값), 반드시 정렬 기준이 되는 필드 중 (적어도 하나는) 고유값이어야 한다. - 물론 고유하지 않은 값을 사용할 수 있는데, 그러면 커서 방식을 쓰는게 아무 의미가 없다.
장점
- 같은 조건에서는
offset을 사용하는 것 보다 빠르다. - 페이지 수(데이터 수)에 상관 없이 퍼포먼스를 유지한다.
- 실시간으로 빠르게 데이터가 추가 삭제되는 서비스 (ex. SNS 등)에서 유리하다.
단점
- 상대적인 구현 난이도가
offset보다 높다. (신경쓸게 많다.) - 다양한 정렬을 활용하기 어렵다. (제한된 정렬 기능)
- 커서만을 위한 컬럼을 추가해야할 수 있다. 그에 따라 추가적인 저장 공간이 낭비된다. (필요에 따라 table에 cursor 컬럼 추가하는 경우)
3) DBMS 성능은 복합적이다.
-
사실 현업에서 DBMS 의 조회 성능은 [
offset은 느리다.cursor는 빠르다. ] 와 같은 단순 이분법으로 절대 나뉘지 않는다. -
아주 아주 많은 경우에서 우리의
select가 느린 이유는offset&cursor보다 본질적으로 우리가 "어떻게 정렬" 하고 있는지, "어떤 컬럼에 조건을 거는지" 가 훨씬 더 지대한 영향을 미친다. -
그리고 DBMS 종류마다 달라질 수 도 있다. mysql & psql 의 경우
streaming방식과buffering방식이 있는데, 전자는 바로 return, 후자는 결과를 메모리에 다 쌓아두고 return 하는 방식이다. -
mysql & psql 에서는 정렬이나 그룹이 들어가면
buffering방식이 되고, 대부분의 페이징은 정렬을 무조건 사용한다.더 깊이들어가면 해당 글의 본질이 바뀔 것 같아 다음번에..
2. DRF 에서 제공하는 Pagination
1) BasePagination
- 아래 소개될 drf 의 3가지 페이지네이션 기법은 모두 해당 class 를 상속받고 있다.
class BasePagination:
display_page_controls = False
def paginate_queryset(self, queryset, request, view=None): # pragma: no cover
raise NotImplementedError('paginate_queryset() must be implemented.')
def get_paginated_response(self, data): # pragma: no cover
raise NotImplementedError('get_paginated_response() must be implemented.')
def get_paginated_response_schema(self, schema):
return schema
def to_html(self): # pragma: no cover
raise NotImplementedError('to_html() must be implemented to display page controls.')
def get_results(self, data):
return data['results']
def get_schema_fields(self, view):
assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`'
if coreapi is not None:
warnings.warn('CoreAPI compatibility is deprecated and will be removed in DRF 3.17', RemovedInDRF317Warning)
return []
def get_schema_operation_parameters(self, view):
return []- 하나 하나 다 뜯어보면 이야기가 산으로 가니 다른 sub class 를 보면서 더 살펴보자!
2) PageNumberPagination & LimitOffsetPagination
- drf 의 아주 default 페이징 기법이다.
국밥 페이징
class PageNumberPagination(BasePagination):
... # 생략
page_size = api_settings.PAGE_SIZE
django_paginator_class = DjangoPaginator
page_query_param = 'page'
... # 생략
def paginate_queryset(self, queryset, request, view=None):
... # 생략
self.request = request
page_size = self.get_page_size(request)
if not page_size:
return None
paginator = self.django_paginator_class(queryset, page_size)
page_number = self.get_page_number(request, paginator)
try:
self.page = paginator.page(page_number)
except InvalidPage as exc:
msg = self.invalid_page_message.format(
page_number=page_number, message=str(exc)
)
raise NotFound(msg)
if paginator.num_pages > 1 and self.template is not None:
# The browsable API should display pagination controls.
self.display_page_controls = True
return list(self.page)-
django_paginator_class를 보면 알 수 있듯, 기본적으로 django core 의Paginatorclass 를 활용해 페이징 처리를 한다. -
기본적으로 "pk" 값을 활용해 페이징 처리를 한다. 하지만 위 mehtod 에 전달하는 "queryset" 의
order_by값을 건들면, 해당 값 기준으로 페이징 처리가 된다. -
(단순 결과물만 봤을때)
http://api.example.org/accounts/?page=3&page_size=20로 요청이 온다면, 아래 SQL 이 실행된다.
SELECT * FROM accounts ORDER BY id ASC LIMIT 20 OFFSET 40;-
그리고 사실
LimitOffsetPagination도 동작은 같다고 보면 된다. 하지만django_paginator_class를 사용하지 않는다. -
좀 더 고전적인
offset & limit방식이라고 보면 된다. cursor 대신 특정 섹션(구간)에 통으로 모든 데이터를 가져올 때 좀 더 유리하다.
3) CursorPagination
- 사람들이 은근 안쓴다. 왜 안쓰는지 모르겠다. (물론 굳이 커서까지 필요할 경우가 꽤 드물긴 하다. 복합적 ordering 과 잘 짜여진 index 를 더 선호해서 그런가?)
def decode_cursor(self, request):
encoded = request.query_params.get(self.cursor_query_param)
if encoded is None:
return None
try:
querystring = b64decode(encoded.encode('ascii')).decode('ascii')
tokens = parse.parse_qs(querystring, keep_blank_values=True)
offset = tokens.get('o', ['0'])[0]
offset = _positive_int(offset, cutoff=self.offset_cutoff)
reverse = tokens.get('r', ['0'])[0]
reverse = bool(int(reverse))
position = tokens.get('p', [None])[0]
except (TypeError, ValueError):
raise NotFound(self.invalid_cursor_message)- 위
decode_cursormethod 를 통해 가장 먼저cursor에 필요한 값들을 request 로 부터 받아온다.
offset: 현재 페이지에서 데이터를 건너뛰는 개수reverse: 데이터를 역순으로 가져올지 여부position: 현재 커서 위치를 나타내는 고유 값
-
재미있는 부분이
tokens = parse.parse_qs(querystring, keep_blank_values=True)이 부분이다. cursor 의 핵심은 "페이징 위치를 파악하는 것" 인데, drf 에서는parse_qs를 활용하고 있다. -
그런 다음 중요한 "정렬 순서" 를 가져온다.
def get_ordering(self, request, queryset, view):
# 기본 정렬 기준 설정
ordering = self.ordering
ordering_filters = [
filter_cls for filter_cls in getattr(view, 'filter_backends', [])
if hasattr(filter_cls, 'get_ordering')
]
if ordering_filters:
# 뷰에 정렬 필터가 있는 경우 이를 사용합니다.
filter_cls = ordering_filters[0]
filter_instance = filter_cls()
ordering_from_filter = filter_instance.get_ordering(request, queryset, view)
if ordering_from_filter:
ordering = ordering_from_filter
# ... 생략 ...
# 정렬 기준을 튜플로 반환합니다.
if isinstance(ordering, str):
return (ordering,)
return tuple(ordering)-
"ordering" 은 정렬 기준인데, 여기서 꼭
index의 중요성을 놓치면 안된다. 정렬 순서에 카디널리티가 높은 것들 순서대로, 가능하면 첫 order 는 unique 값을 세팅해야 한다. (그래야 커서의 퍼포먼스가 의미 있다!!) -
그런 다음
paginate_querysetmethod 로 넘어가서 쿼리셋을 구성하게 된다.ordering='-created'를 기준으로 정렬한다고 하면, 아래와 같은 sql 을 만들 것이다!
SELECT * FROM myapp_mymodel
WHERE created < '2024-08-04 12:00:00'
ORDER BY created DESC
LIMIT 11;- 그리고 실제 "next" 와 "previous" 는 아래와 같이 만들어 진다. 저 cursor 값이 포지션이 되는데, 여기서
decode_cursormethod 의cursor값을 잘 해석해서 슈킹할 수 있다면,, 순차 포지션 접근 말고 중간 커서 포지션으로 딱! 접근할 수 있을 것이다.. (근데 아시다시피 이럴꺼면 cursor 안쓰는게..)

4) 오버라이딩 하기
- 개별
view단위로는 아래와 같이 사용하면 된다.
class FooPagination(PageNumberPagination):
page_size = 3
class FooViewSet(viewsets.ModelViewSet):
queryset = Foo.objects.all()
serializer_class = FooSerializer
pagination_class = FooPagination- 대게 단일화된 API response format 을 위해 위와 같은 방식은 지양하는게 좋다. (물론 통계 api 등에서는 얘기가 달라질 수 있다.)
- 보통 전역적으로 사용할 기본 페이지네이션 class 를 만들고,
settings에서 세팅해 둔다.
# settings.py
REST_FRAMEWORK = {
# ... 생략 ...
"PAGE_SIZE": DEFAULT_PAGE_SIZE,
"DEFAULT_PAGINATION_CLASS": "config.base_paginations.CustomPagination",
}
class CustomPagination(PageNumberPagination):
page_size = 10
page_size_query_param = "page_size"
max_page_size = 100
def get_paginated_response(self, data):
return Response(
{
"links": {
"next": self.get_next_link(),
"previous": self.get_previous_link(),
},
"total": self.page.paginator.count,
"page_size": int(self.request.GET.get("page_size", self.page_size)),
"current_page": self.page.number,
"total_pages": self.page.paginator.num_pages,
"results": data,
}
)커서 방식은 조금 더 신경 써야 한다.
- 아래와 같이 "페이지 사이즈", "정렬 순서", "커서파라미터" 정도만 세팅해도 되고
class MyCursorPagination(CursorPagination):
page_size = 10
ordering = 'created'
cursor_query_param = 'cursor'ordering값을 정해진 것 중 하나만 선택해서 사용하게 할 수 있다.
class CustomCursorPagination(CursorPagination):
page_size = 10
ordering = '-created'
cursor_query_param = 'cursor'
page_size_query_param = 'page_size'
max_page_size = 100
def get_ordering(self, request, queryset, view):
ordering = request.query_params.get('ordering', self.ordering)
return (ordering,)-
그래서 필자는 "단일화된 API response format" 위해
CustomPagination과CustomCursorPagination를 모듈화 해두고 전역적으로 default 는CustomPagination를 사용하게 한다. -
그리고 때에 따라서 view class 에서
pagination_class = CustomCursorPagination를 사용한다.
출처
