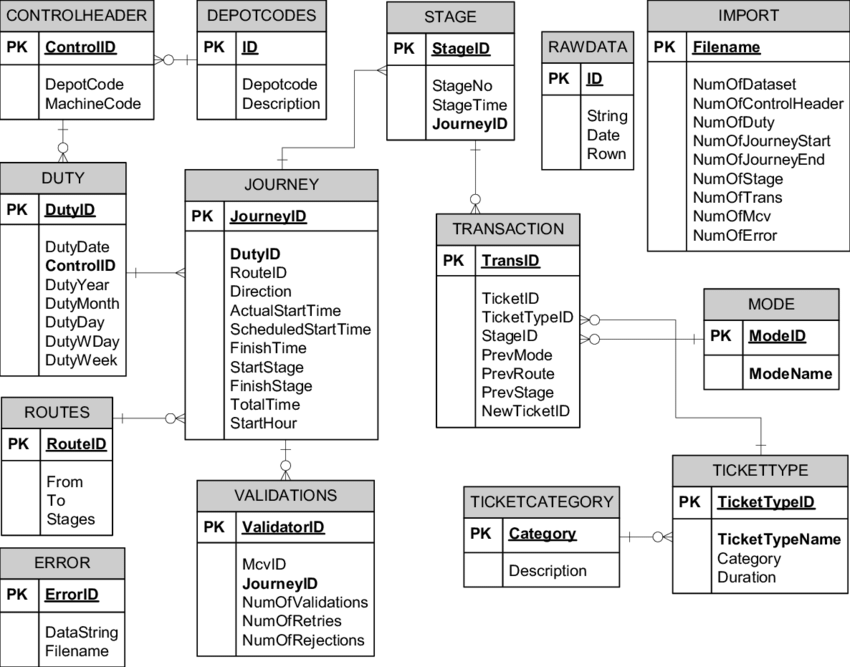
Django Model과 RDB
ORM 컨셉과 RDB에 대해 조금 더 알아보자. 그리고 django model - orm에서 PK, FK, UNIQUE 등의 index처리를 너무 depth있게 살펴보기 보다 전체 그림에서 포인트만 잡아보자!
RDB key - pk, fk,,,
- 고전적인 RDB 관점에서 key는 무엇인가를 유일하게 식별한다는 의미가 있다. 관계 데이터베이스에서 키는 릴레이션에서 특정 투플을 식별할 때 사용하는 속성 혹은 속성의 집합이다. 즉 키가 되는 속성은 반드시 값이 달라서 투플들을 서로 구별할 수 있어야 한다.
PK(Primary Key)키
- 고전적 의미는 후보키 중 하나를 선정하여 대표로 삼는 키를 말한다.
- 후보키는 투플을 유일하게 식별할 수 있는 속성의 최소 집합이다.
- 즉 슈퍼키 중에서 최소의 속성으로 집합된것이 후보키가 된다. (ps, 슈퍼키는 투플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합 -> 여기서 중요한 관점은 '집합도 된다' 라는 것이다.)
FK(Foreign key)키
- 외래키는 다른 릴레이션의 기본키를 참조하는 속성을 말한다. 외래키는 다른 릴레이션의 기본키를 참조하여 관계 데이터 모델의 특징인 릴레이션 간의 관계를 표현한다.
- RDB의 시작이자 끝인 개념.
Django PK, FK, Unique, Index
PK
pk 부여하기
- django ORM에서 속성 옵션 값으로 "primary_key"를 부여할 수 있다. 해당 옵션 값이 True면 해당 컬럼은 PK값이 된다.
- 모든 형태의 데이터 타입이 PK가 될 수 있는 것은 아니다. 자세한 사항은 해당 시리즈의 Field 모음집을 살펴보자.
- Django will automatically add an IntegerField to hold the primary key, so you don’t need to set primary_key=True on any of your fields unless you want to override the default primary-key behavior. For more, see Automatic primary key fields. 공식문서 바로가기
Automatic pk fields
- 위 영어 글에서 볼 수 있듯이 장고는 auto-incrementing primary key 를 pk선언하지 않은 model 대상으로 자동으로 만들어 준다.
- 물론 꼭 컬럼 이름이 Id 여야 할 필요 없다. 장고는 pk=true 값을 준 컬럼이 있다면, 자동으로 위 내용을 생성하지 않기 때문이다.
FK
- ForeignKey, ManyToManyField, OneToOneField 필드 타입이 존재한다.
Many-to-one(ForeignKey) relationships
-
다대일 관계를 정의하기 위해 django.db.model.ForeignKey를 사용합니다. 여타 다른 Field 타입을 사용하듯이 모델에 클래스 속성을 포함시킴으로서 사용합니다.
-
class:~django.db.models.ForeignKey 는 위치 기반 인자 (인자의 순서가 있는 방식) 로 해당 모델과 관련있는 클래스를 필요로 합니다 (주: 예를 들어 첫번째 인자로 상대 클래스를 명기 해야하는식으로).
-
예를 들어 Car 모델은 한개의 Manufacturer (제조사) 을 가지고 있습니다,즉 Manufacturer 는 여러개의 Car 를 만들 수 있지만 하나의 Car 그 자체로는 하나의 Manufacturer 만을 갖습니다!
from django.db import models
class Manufacturer(models.Model):
# ...
pass
class Car(models.Model):
manufacturer = models.ForeignKey(Manufacturer, on_delete=models.CASCADE)
# ...-
on_delete=models.CASCADE 를 살펴보면 일반적인 관계형 데이터베이스에서 관계를 맺은 데이터가 delete될 때 어떤 규칙을 따르는지 명시한 것 이다.
- CASCADE는 부모가 삭제되면 FK 관계 row값도 삭제되는, 순차적 삭제를 의미한다.
- Model.delete()는 관련 모델에서 호출되지 않지만 삭제된 모든 개체에 대해 pre_delete 및 post_delete 신호가 전송됩니다. (장고 시그널에 대한 얘기)
- PROTECT는 ProtectedError(django.db.IntegrityError 하위 에러)를 발생시켜 참조된 개체를 삭제하지 못하도록 한다.
- RESTRICT는 가이드를 참조해 주세요!
- 그 외 SET_NULL, SET_DEFAULT, DO_NOTHING이 있다.
- SET은 아래 코드와 같이 값 또는 함수(호출)를 넣어 줄 수 있다.
from django.conf import settings from django.contrib.auth import get_user_model from django.db import models def get_sentinel_user(): return get_user_model().objects.get_or_create(username='deleted')[0] class MyModel(models.Model): user = models.ForeignKey( settings.AUTH_USER_MODEL, on_delete=models.SET(get_sentinel_user), ) - CASCADE는 부모가 삭제되면 FK 관계 row값도 삭제되는, 순차적 삭제를 의미한다.
-
FK는 related_name, related_query_name 등을 살펴볼 필요가 있다. 해당 내용은 시리즈의 정참조, 역참조, related_names, select_related, prefetch_related 를 참조하길 바란다.
ManyToManyField relationships
- 다대다 관계, A<->B 모델 서로 서로 여러개 가질 수 있는 형태를 의미한다. Realtion-ship에서 흔히 많이하는 비유로, 피자는 여러 종류의 토핑을 가지고, 토핑은 여러 종류의 피자에 올라 갈 수 있는 것에 비유할 수 있다.
from django.db import models
class Topping(models.Model):
name = models.CharField(max_length=50)
class Pizza(models.Model):
name = models.CharField(max_length=50)
toppings = models.ManyToManyField(Topping)
# 그리고 자기 자신과 여러 관계를 맺을 수 도 있다.
# if I am your friend, then you are my friend.
class Person(models.Model):
friends = models.ManyToManyField("self")
OneToOneField relationships
-
공식 문서에서는 "unique=True를 준 FK와 비슷하지만, 정접근 역접근 모두 같은 하나의 모델을 주는 것" 이라고 설명한다. user <-> profile 관계를 보통 1:1 관계 설정하는 경우가 있다. (물론 FK와 같이 1:N도 충분히 가능하다.)
-
아래 예시 코드와 같이 User모델을 스스로 1:1로 주어서 슈퍼바이저 관계를 가질 수 있다.
from django.conf import settings
from django.db import models
class MySpecialUser(models.Model):
user = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
)
supervisor = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
related_name='supervisor_of',
)Unique
-
각 필드의 값이, 테이블 내에서 "유일한 값"을 가지는 필드로 만든다. 즉 모든 레코드가 서로 다른 값을 가져야만 할 때 사용한다.
-
모델을 정의할 때
Field(unique=True)로 유니크 값을 설정할 수 있다. 보통 타임스탬프 값이 유니크값이 될 수 있다. 하지만 충분히 중복 가능성은 있기 때문에, 타임스탬프에 시퀀스 값을 붙이는 경우도 있다. -
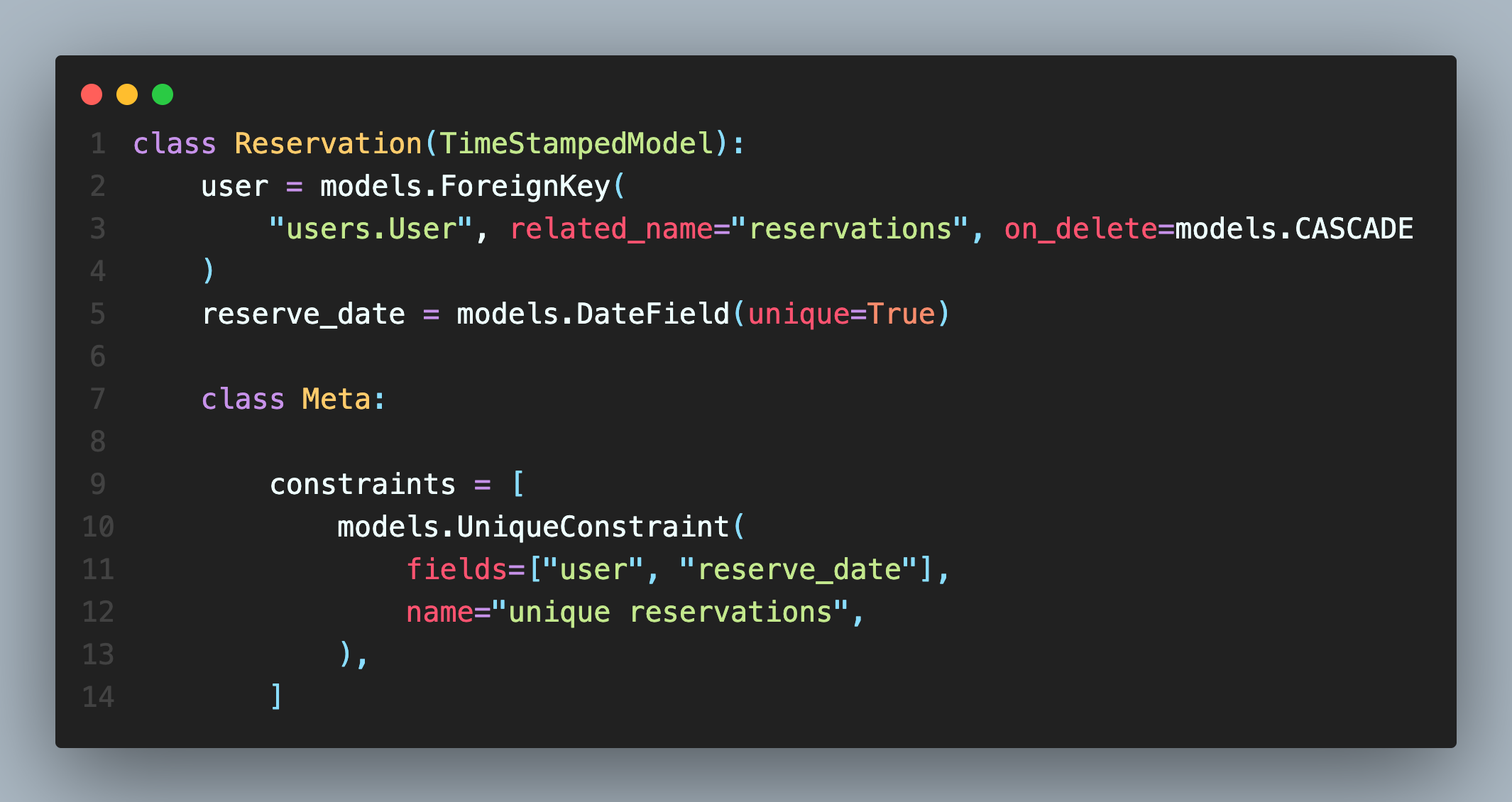
사실 더 핵심 사용은 "여러개 필드를 묶어서 Unique를 만들기" 다. 일반적으로 SQL을 사용할 때, 복수의 컬럼(키) 값을 묶어 Unique 집합으로 사용하는 것 과 같다. 예를 들면, title과 date를 묶어 유니크 하게 하면 같은 날짜에 같은 title을 가지는 레코드(row)는 존재할 수 없게 할 수 있다.
-
좋은 예시가 있어서 링크와 사진을 가져왔다! 출처
Index
사실 인덱스는 개념부터 좀 제대로 잡고 살펴보는 것이 좋다. 느린 RDBMS에서 어떻게 서치(SELECT)를 최적화 할까? 에 초점이 맞춰진 개념이다.
-
indexing 기술은 RDBMS에서 검색 속도를 높이기 위해서 사용되는 기술 이다. Table의 컬럼을 따로 파일로 저장하여서, 검색시 해당 Table의 레코드를 full scan하는 것이 아니라, 저장한 Index 파일을 검색하여서 검색 속도를 빠르게한다.
-
Array의 index를 알 때, O(1) 의 시간복잡도로 접근할 수 있는 개념과 비슷하다. 인덱스는 DBMS 내부적으로 처리되는 알고리즘을 사용한다. 대표적으로 B-Tree, Hash, Fractal-Tree 등이 있다. [Real MySQL] B-Tree 인덱스 글을 읽어보는 것을 추천한다.
-
데이터의 종류가 적을 수록 Index의 효율이 떨어진다. 반대로 서로 다른 값으로 여러 종류의 데이터가 존재하면 효율은 좋아진다.
-
이렇게 index가 db에 제대로 반영 되는지 확인하기 위해서는 EXPLAIN 문을 이용해서 알 수 있다. SELECT 문 앞에 'EXPLAIN'을 붙여주고, possible_keys와 key 컬럼을 통해 알 수 있다.
class Post(models.Model):
title = models.CharField(db_index=True, max_length=100) # title
contents = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
# ...생략...
# author로 User를 FK로 가진다고 생각하자-
CharField인 title에 옵션 db_index=True를 주어서 인덱싱을 했다.
-
django 문서 상에서는 filter, exclude, order_by가 자주 사용되는 컬럼에 db_index를 사용하는 것을 추천한다. -> 장고 쿼리 튜닝에 좋은 초점이 된다.
-
Django 에서는 Queryset에 explain method가 존재하는데, 이것을 통해 index 사용 여부를 알 수있다.
test = Post.objects.filter(user_id=1)
print(test.explain)
#결과 값
'0 0 0 SEARCH TABLE posts_post USING INDEX posts_post_user_id_id_8907527a (user_id_id=?)'- FK값은 PK와 연결되고, 그 PK는 자동으로 인덱싱되어서 위와 같은 결과를 볼 수 있다.
index의 기본적인 조건
-
카디널리티 (Cardinality) 높을수록 / 한 컬럼이 갖고 있는 값의 중복 정도가 낮을 수록 좋다.
a. 상대적인 개념이다. 다른 컬럼에 비해 카디널리티가 높고 낮음을 결정 -
선택도 (Selectivity) 가 낮을 수록 인덱스 설정에 좋은 컬럼이다.
a. 5~10% 정도가 적당
b. 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 100
c. 컬럼의 값들의 평균 row 수 / 테이블의 총 row 수 100 -
활용도 높을 수록 인덱스 설정에 좋은 컬럼
a. 실제 작업(query에서 얼마나 활용되는지에 대한 값, SELECT 되는 컬럼, WHERE 절에 자주 활용되는 컬럼 -
중복도
a. 중복도가 없을 수록 인덱스 설정에 좋은 컬럼이다. 카디널리티와 중복도는 상대적이고 절대적인 개념에서 엄연히 다르다.
