Elasticsearch - ELK stack & Postgresql & Logstash, query based CDC 만들기 by docker compose

[ 글의 목적: ELK stack 기반으로 postgresql DBMS와 logstash를 활용해 데이터 동기화, query based CDC를 구성해 보자! logstash "활용"이 가장 큰 주제 ]
🔥 https://github.com/Nuung/elk-psql-cdc-boilerplate 해당 레포에서 전체 완성본 체크 가능합니다.
ELK, postgresql과 logstash
elk stack을 docker compose으로 가볍게 전반적으로 살펴보고, Postgresql과 Logstash 활용을 중점으로 "Query-based CDC" 환경을 만들어보자!
-
사실 Kafka + Debezium의 log-based cdc를 먼저 하려고 했지만, 상대적으로 접근 난이도가 낮은 ELK 활용한 query-based cdc를 먼저 다룬다. 이런 방식을 보통 "PULL 방식" 이라고 한다.
-
CDC는 Change Data Capture의 약자이며 DBMS clustering, sharding 등의 고가용성 목표의 이중화에도 활용되거나 DB data pipe-line 구축을 할 때도 사용된다. 핵심은 "DB 데이터의 변경을 감지해서 event 기반 또는 다양한 형태로 그 내용을 가져온다는 것"이다.
1. ELK stack
1) intro
- ELK는 간단하게
Elasticsearch을 중심으로 하는 "데이터 저장, 수집 및 시각화 통합 stack" 이다.- Elasticsearch: 데이터 저장, 색인 및 검색
- Logstash: 데이터 수집 엔진
- Kibana: 데이터 시각화 및 관리
- 참고로 요즘 es는
beats라는 친구가 있고, simple한 data 수집 파이프라이닝을 구축하는데 널리 사용되고 있으나, 해당 글에서는 등장하지 않는다!
- 각각의 역할이나 정의, 장단점에 대해서는 다루지 않겠다. 기본 설명은 다음 글로 대체한다.
2) goal of the cdc
-
(1) 엔터프라이즈 DBMS 스트레스 및 부하 분산, (2) 장기 보관 데이터 - 한 번 create되면 update될 일이 거의 없는 data 위주, ex) 접속 로그, 매출 데이터, 출생 신고 이력 등의 이관, (3) 다양한 text searching optimization 목표로하는 특수 목적 보관
-
위 3가지 목표를 위해 elk stack을 활용하고, 기존 운영 DBMS 데이터를 이관해 보는 것이 목표이다.
-
log-based CDC 는 DBMS에서 기본적으로 생성하는 "transaction log"를 기반으로 하며, psql의 경우 wal file, mysql binary log 등을 활용해 CDC 환경을 구성하는 것이다. 그에 반해 query-based CDC 는 CDC origin(target) DBMS 대상으로 big-query 또는 특정 주기로 schedule 된 query를 바탕으로 CDC 환경을 구성하는 것이다.
-
query-based CDC 를 구성하는 수 많은 방법이 있겠지만, "여기서는 최대한 단순한 방법을" 살펴보는 것이다!
해당 글에서 소개하는 방법이 당연한 정답이라는 의미가 아니다!
3) docker compose file
-
🔥 스크롤 압박과 환경 변수 사용에 주의 부탁드립니다!!
-
elsatic cluster를 3개의 노드로 구성하고 있는 형태이다. 공식 홈페이지의 elk stack docker compose를 base로 한다. (section 2에서 psql과 logstash를 추가할 것이다.) 참고한 exsample은 아래 두 곳이다!
version: '3'
services:
setup:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- ./certs:/usr/share/elasticsearch/config/certs
user: "0"
command: >
bash -c '
if [ x${ELASTIC_PASSWORD} == x ]; then
echo "Set the ELASTIC_PASSWORD environment variable in the .env file";
exit 1;
elif [ x${KIBANA_PASSWORD} == x ]; then
echo "Set the KIBANA_PASSWORD environment variable in the .env file";
exit 1;
fi;
if [ ! -f config/certs/ca.zip ]; then
echo "Creating CA";
bin/elasticsearch-certutil ca --silent --pem -out config/certs/ca.zip;
unzip config/certs/ca.zip -d config/certs;
fi;
if [ ! -f config/certs/certs.zip ]; then
echo "Creating certs";
echo -ne \
"instances:\n"\
" - name: es01\n"\
" dns:\n"\
" - es01\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es02\n"\
" dns:\n"\
" - es02\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
" - name: es03\n"\
" dns:\n"\
" - es03\n"\
" - localhost\n"\
" ip:\n"\
" - 127.0.0.1\n"\
> config/certs/instances.yml;
bin/elasticsearch-certutil cert --silent --pem -out config/certs/certs.zip --in config/certs/instances.yml --ca-cert config/certs/ca/ca.crt --ca-key config/certs/ca/ca.key;
unzip config/certs/certs.zip -d config/certs;
fi;
echo "Setting file permissions"
chown -R root:root config/certs;
find . -type d -exec chmod 750 \{\} \;;
find . -type f -exec chmod 640 \{\} \;;
echo "Waiting for Elasticsearch availability";
until curl -s --cacert config/certs/ca/ca.crt https://es01:9200 | grep -q "missing authentication credentials"; do sleep 30; done;
echo "Setting kibana_system password";
until curl -s -X POST --cacert config/certs/ca/ca.crt -u "elastic:${ELASTIC_PASSWORD}" -H "Content-Type: application/json" https://es01:9200/_security/user/kibana_system/_password -d "{\"password\":\"${KIBANA_PASSWORD}\"}" | grep -q "^{}"; do sleep 10; done;
echo "All done!";
'
healthcheck:
test: ["CMD-SHELL", "[ -f config/certs/es01/es01.crt ]"]
interval: 1s
timeout: 5s
retries: 120
networks:
- esnet
es01:
depends_on:
setup:
condition: service_healthy
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
container_name: es01
hostname: es01
volumes:
- ./certs:/usr/share/elasticsearch/config/certs
- ./esdata01:/usr/share/elasticsearch/data
ports:
- ${ES_PORT}:9200
environment:
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- node.name=es01
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es02,es03
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es01/es01.key
- xpack.security.http.ssl.certificate=certs/es01/es01.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.http.ssl.verification_mode=certificate
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es01/es01.key
- xpack.security.transport.ssl.certificate=certs/es01/es01.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
networks:
- esnet
es02:
depends_on:
- es01
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
container_name: es02
hostname: es02
volumes:
- ./certs:/usr/share/elasticsearch/config/certs
- ./esdata02:/usr/share/elasticsearch/data
environment:
- node.name=es02
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es03
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es02/es02.key
- xpack.security.http.ssl.certificate=certs/es02/es02.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.http.ssl.verification_mode=certificate
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es02/es02.key
- xpack.security.transport.ssl.certificate=certs/es02/es02.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
networks:
- esnet
es03:
depends_on:
- es02
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
container_name: es03
hostname: es03
volumes:
- ./certs:/usr/share/elasticsearch/config/certs
- ./esdata03:/usr/share/elasticsearch/data
environment:
- node.name=es03
- cluster.name=${CLUSTER_NAME}
- cluster.initial_master_nodes=es01,es02,es03
- discovery.seed_hosts=es01,es02
- bootstrap.memory_lock=true
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=true
- xpack.security.http.ssl.key=certs/es03/es03.key
- xpack.security.http.ssl.certificate=certs/es03/es03.crt
- xpack.security.http.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.http.ssl.verification_mode=certificate
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.key=certs/es03/es03.key
- xpack.security.transport.ssl.certificate=certs/es03/es03.crt
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.license.self_generated.type=${LICENSE}
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test:
[
"CMD-SHELL",
"curl -s --cacert config/certs/ca/ca.crt https://localhost:9200 | grep -q 'missing authentication credentials'",
]
interval: 10s
timeout: 10s
retries: 120
networks:
- esnet
kibana:
depends_on:
es01:
condition: service_healthy
es02:
condition: service_healthy
es03:
condition: service_healthy
image: docker.elastic.co/kibana/kibana:${STACK_VERSION}
container_name: kibana
hostname: kibana
volumes:
- ./certs:/usr/share/kibana/config/certs
- ./kibanadata:/usr/share/kibana/data
ports:
- ${KIBANA_PORT}:5601
environment:
- SERVERNAME=kibana
- ELASTICSEARCH_HOSTS=["https://es01:9200","https://es02:9200","https://es03:9200"]
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_PASSWORD}
- ELASTICSEARCH_SSL_CERTIFICATEAUTHORITIES=config/certs/ca/ca.crt
mem_limit: ${MEM_LIMIT}
healthcheck:
test:
[
"CMD-SHELL",
"curl -s -I http://localhost:5601 | grep -q 'HTTP/1.1 302 Found'",
]
interval: 10s
timeout: 10s
retries: 120
networks:
- esnet
networks:
esnet:
- 필수 설정해야할 환경 변수는 아래와 같다.
docker-compose.yml과 같은 경로에.env로 만들어서 세팅하자!
# Password for the 'elastic' user (at least 6 characters)
ELASTIC_PASSWORD=admin123!
# Password for the 'kibana_system' user (at least 6 characters)
KIBANA_PASSWORD=admin123!
# Version of Elastic products
STACK_VERSION=8.7.0
# Set the cluster name
CLUSTER_NAME=elk-cdc-cluster
# Set to 'basic' or 'trial' to automatically start the 30-day trial
LICENSE=basic
#LICENSE=trial
# Port to expose Elasticsearch HTTP API to the host
ES_PORT=9200
# Port to expose Kibana to the host
KIBANA_PORT=5601
# Increase or decrease based on the available host memory (in bytes)
MEM_LIMIT=1073741824
# Project namespace (defaults to the current folder name if not set)
COMPOSE_PROJECT_NAME=elk-cdc-app-
8.x version 부터는 보안 인증 세팅이 기본으로 되어있다. 그래서 https를 위한 ssl 인증서가 필요하다!
setupservice는 이를 위해 존재하며, 해당 세팅을 한 뒤에 kill된다. 실행하고 나면certs디렉토리가 만들어질텐데 해당 파일이 ssl 인증서다. -
그 디렉토리에 생성된 ssl인증서를 생성한 elastic node가 모두 물고 있어야 한다. 참고로 ssl 인증 받는 ip와 dns는 command를 보면 알수 있듯,
hostname&localhost&127.0.0.1이다. -
그리고 compose를 실행할때 project name을
elk-cdc-app로 준다.docker compose -f ./docker-compose.yml -p elk-cdc-app up -d를 한다는 의미다! -
세팅과 활용이 주된 목표인 만큼, elk 도커 구성에 있어서 하나하나 깊게 다루지 않을 것이다. 자세한 옵션들에 대해서는 elastic official docs 로 대체한다.
8버전오면서 docs가 굉장히 이쁘고 상세해진 것 같다!
4) excute & example data insert
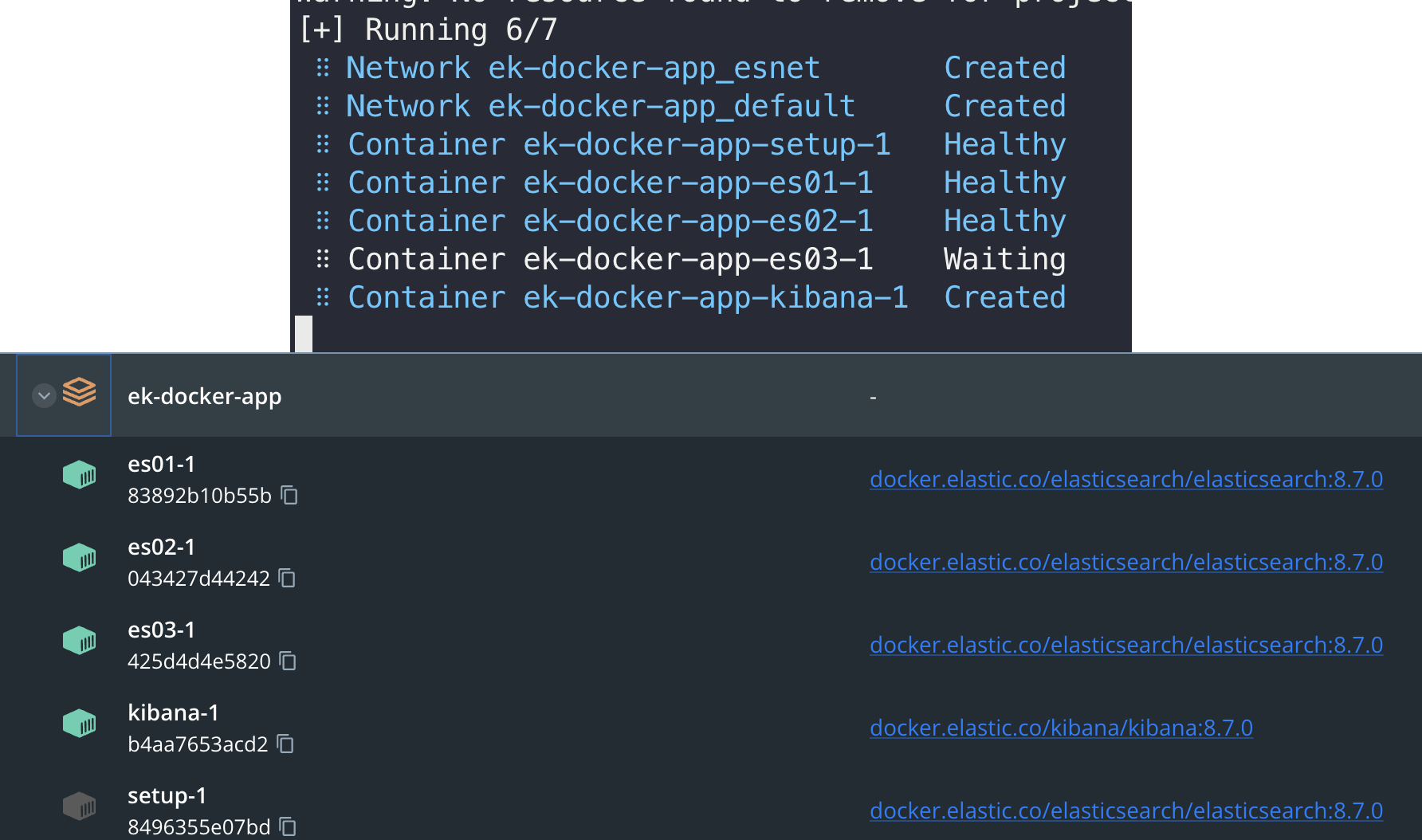
docker compose -f ./docker-compose.yml -p elk-cdc-app up -d로 구성하면 setup이 돌고, ssl를 갱신&생성 이후 es node가 활성화 되며 뒤이어 kibana가 활성화 된다. (아래 사진에서 project name이 다른 것은, 글 쓰다가 2번 날려서.. ㅎ)
- http://localhost:5601 로 접속하면 아래와 같은 kibana login 화면으로 접속 가능하다. 여기서 세팅한 admin 계정으로 로그인하자! 참고로 따로 세팅안하면 admin의 username은 default로
elastic이다.

데이터 밀어 넣기 tip
import csv
from typing import List, Dict
from elasticsearch import Elasticsearch
def get_csv_dict(file_path: str) -> List[Dict]:
data_dict = []
with open(file_path, "r") as file:
csv_reader = csv.DictReader(file)
for row in csv_reader:
data_dict.append(row)
return data_dict
es = Elasticsearch(
hosts="https://localhost:9200",
ca_certs="../certs/ca/ca.crt",
basic_auth=("elastic", "admin123!"),
)
print(es.info())
for i in range(100):
file_path = f"./example-data-{i}.csv" # 아무렇게나 만든 csv형태 더미 데이터, gpt 같은 친구들이 기가막히게 잘해준다ㅎㅎ.
docs = get_csv_dict(file_path) # 그냥 dict로 바꾸는 것이다.
if i % 5 == 0:
print(i, file_path, "turn..")
for doc in docs:
doc["timestamp"] = datetime.now()
res = es.index(index="여기에 인덱스 이름", document=doc)
-
python의 elasticsearch 모듈로 위와 같이 simple하게 example data를 밀어넣을 수 있다. 더미로 csv file을 마구마구 몇 십만건 만들어서 넣어버리자!
-
kibana에서
Analytics를 가장 많이, 핵심적으로 사용하며, 미리 데이터를 몇 만건 밀어 넣어 둬서 아래와 같이 보인다.
5) Kibana DevTools 활용하기
- kibana navbar menu에서
Management>DevTools에서 바로 console 형태 환경에서 elastic으로 request를 쉽게 던질 수 있다.
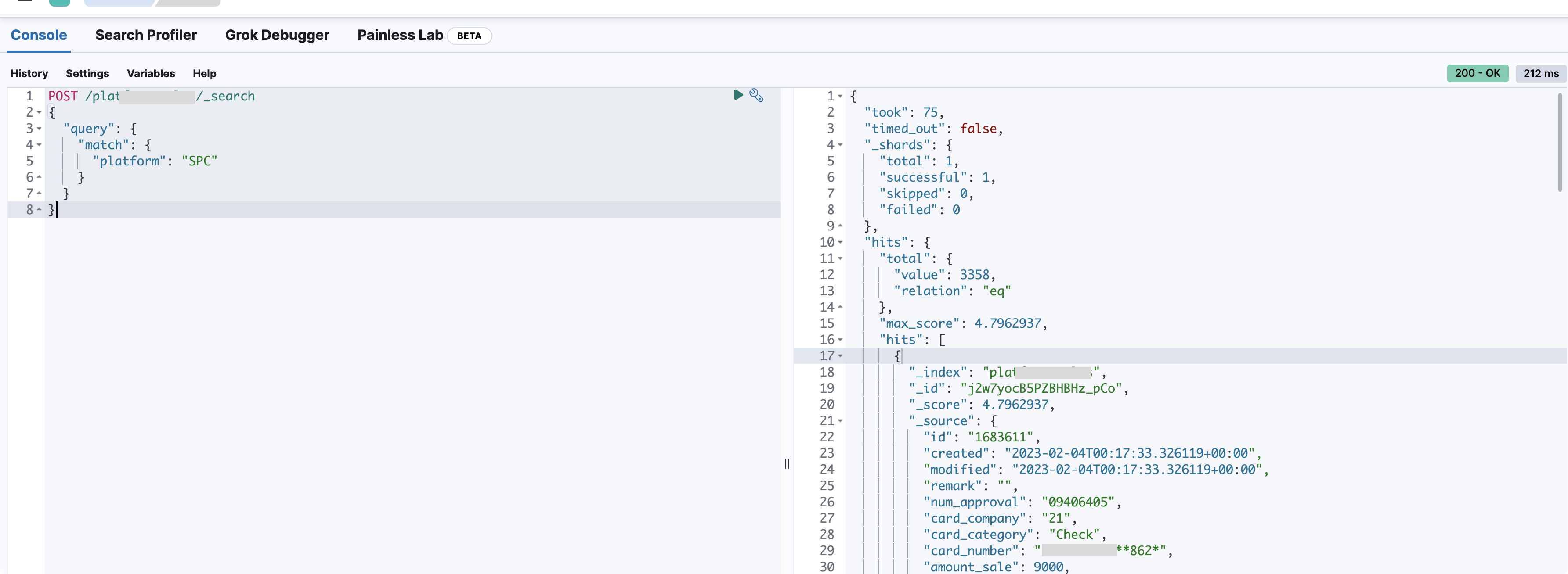
- elastic search의 deep dive와 이런 console 활용은 다른 글에서 더 깊게 다룰 예정이니 이제 진짜 목적인 postgresql & logstash 를 세팅해보자
2. postgresql & logstash
-
이제 위에서 만든 docker compose에 2가지 서비스를 추가한다. 참고로, 나와 같이,, 모든 서비스를 한 번에 돌릴 수 있는 스펙이 안된다면,, postgresql과 logstash만 우선 돌리고, es node는 하나로 줄이자 ㅎ
-
바로 2개다 추가하지 말고 먼저 postgresql 추가하고 기본 세팅하자.
...생략
logstash:
image: docker.elastic.co/logstash/logstash:${STACK_VERSION}
container_name: logstash
hostname: logstash
volumes:
- ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
- ./logstash/inspector-index.dat:/usr/share/logstash/inspector-index.dat
- ./logstash/jar/postgresql-42.6.0.jar:/usr/share/logstash/postgresql.jar
- ./certs:/usr/share/logstash/certs
environment:
- xpack.monitoring.enabled=false
- POSTGRES_HOST=postgres
- POSTGRES_PORT=5432
- POSTGRES_DB=${POSTGRES_DB}
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
ports:
- 5044:5044
command: bash -c "logstash-plugin install logstash-integration-jdbc && logstash -f /usr/share/logstash/pipeline/logstash.conf"
depends_on:
- es01
- es02
- es03
networks:
- esnet
postgres:
image: postgres
container_name: postgres
hostname: postgres
restart: always
environment:
- POSTGRES_DB=${POSTGRES_DB}
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
volumes:
- ./postgresql/data:/var/lib/postgresql/data
ports:
- 5432:5432
networks:
- esnet
...생략-
xpack.monitoring.enabled값은logstash.licensechecker.licensereader의 워닝때문에 추가한 값이다. -
logstash에 세팅된volumes은 차근이 설명할 예정이다..envfile에는 아래와 같이 psql에 관련된 값을 세팅해주자!
...생략
# PSQL CONFIG
POSTGRES_USER=postgres
POSTGRES_PASSWORD=postgres123!
POSTGRES_DB=elkcdc1) postgresql & logstash setting
- cdc target table을 위한 example table과 example data를 아래와 같이 세팅하자!
CREATE TABLE cdc_test (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
dummy VARCHAR(100),
category VARCHAR(1) CHECK (category IN ('A', 'B', 'C', 'D', 'E', 'F'))
);
INSERT INTO cdc_test (dummy, category)
VALUES
('Lorem ipsum dolor sit amet', 'A'),
('Consectetur adipiscing elit', 'B'),
('Sed do eiusmod tempor incididunt', 'C'),
('Ut labore et dolore magna aliqua', 'D'),
('Ut enim ad minim veniam', 'E'),
('Quis nostrud exercitation ullamco', 'F'),
('Laboris nisi ut aliquip ex ea commodo consequat', 'A'),
('Duis aute irure dolor in reprehenderit', 'B'),
('Voluptate velit esse cillum dolore', 'C'),
('Eu fugiat nulla pariatur', 'D');-
여기까지 되었으면 logstash 추가하기 위해 사전에 준비할게 있다.
logstash.conf에 query를 작성하고, query를 excute 할 주체가 필요하며 jdbc 를 사용한다! -
그래서 logstash가 그 jdbc를 활용할 수 있는
logstash-integration-jdbcplugin 이 필요하고, jdbc로 connection 붙을 DBMS의 jdbc driver가 필요하다!!
jdbc driver for postgresql
- 아래 사진과 같이 https://jdbc.postgresql.org/download/ 에 가서
jarfile을 다운로드 받자!
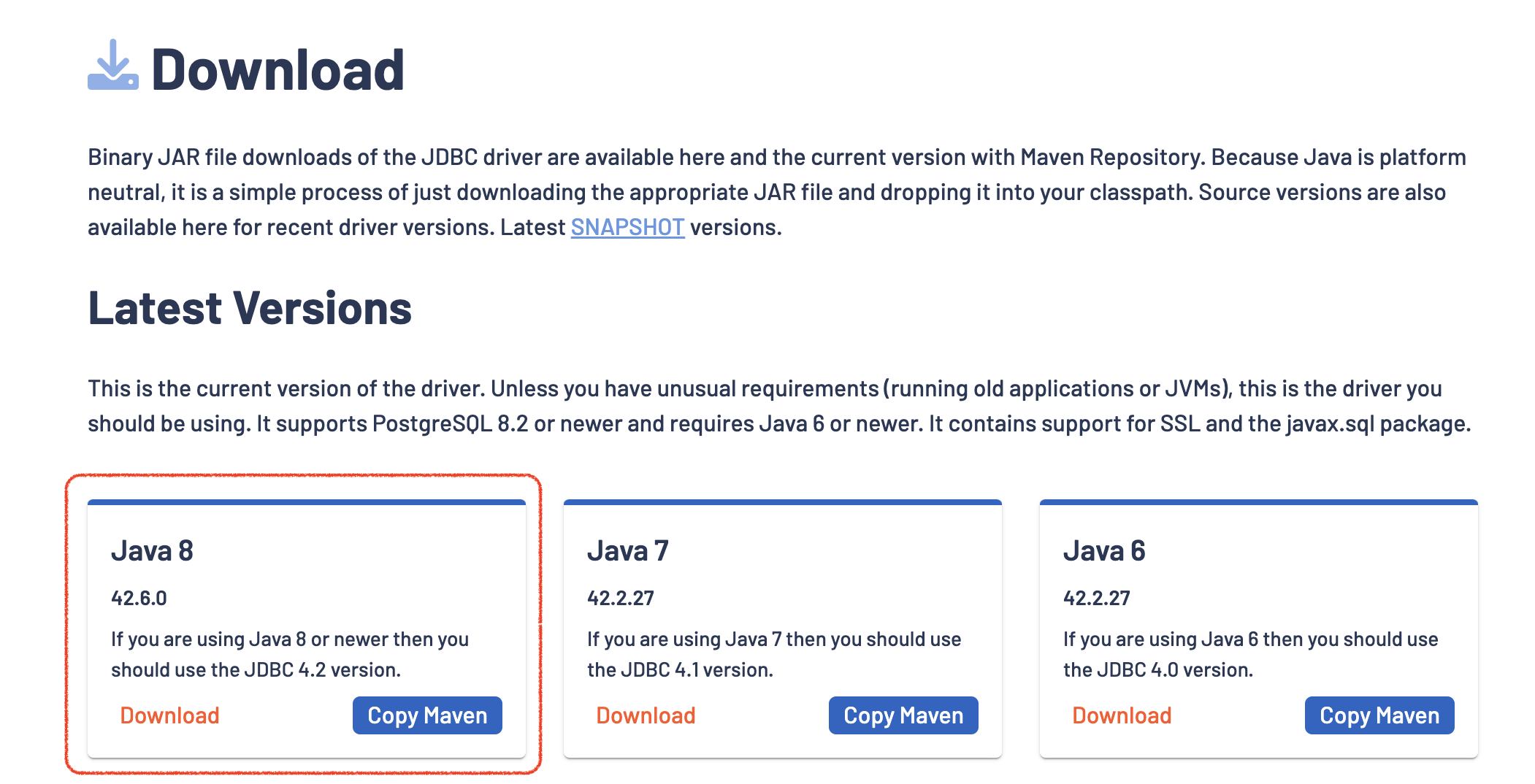
logstash-integration-jdbc
- 플러그인은 위 docker compose file에서 logstash의
command에서 볼 수 있다. 실행할 때 설치하도록 세팅해 두었다.이런 부분은 사실 dockerfile을 구성하는 것이 더 올바른 방향이라고 생각한다..
2) 기본 logstash.conf
- logstash는 기본적으로
input,filter,output설정을 가진다.input: 데이터를 수집하기 위한 설정이다.filter: 수집한 데이터를 전처리, 가공하는 설정이다.output: 전처리 된 데이터의 도착지, 전달되는 곳에 대한 설정이다.
input {
stdin {}
jdbc {}
file {}
}
filter {
mutate {}
date {}
grok {}
}
output {
stdout {}
elasticsearch {}
kafka {}
csv {}
}- 우선 elastic 없이 그냥 logstash로만 postgresql data 읽어오는 방법을 살펴보자!
./logstash/logstash.conf파일을 아래와 같이 세팅하고,docker compose up -d드가자!
input {
jdbc {
# Postgres jdbc connection string to our database, mydb
jdbc_connection_string => "jdbc:postgresql://${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}"
# The user we wish to execute our statement as
jdbc_user => "${POSTGRES_USER}"
jdbc_password => "${POSTGRES_PASSWORD}"
# The path to our downloaded jdbc driver
jdbc_driver_library => "/usr/share/logstash/postgresql.jar"
# The name of the driver class for Postgresql
jdbc_driver_class => "org.postgresql.Driver"
# our query
statement => "SELECT * FROM cdc_test"
schedule => "* * * * *"
}
}
output {
stdout { codec => json_lines }
}- 그리고 docker log를 살펴보면 아래와 같이
cdc_testtable에 밀어넣은 데이터가 1분마다 json 형태로 콘솔에 출력되는 것을 볼 수 있다.
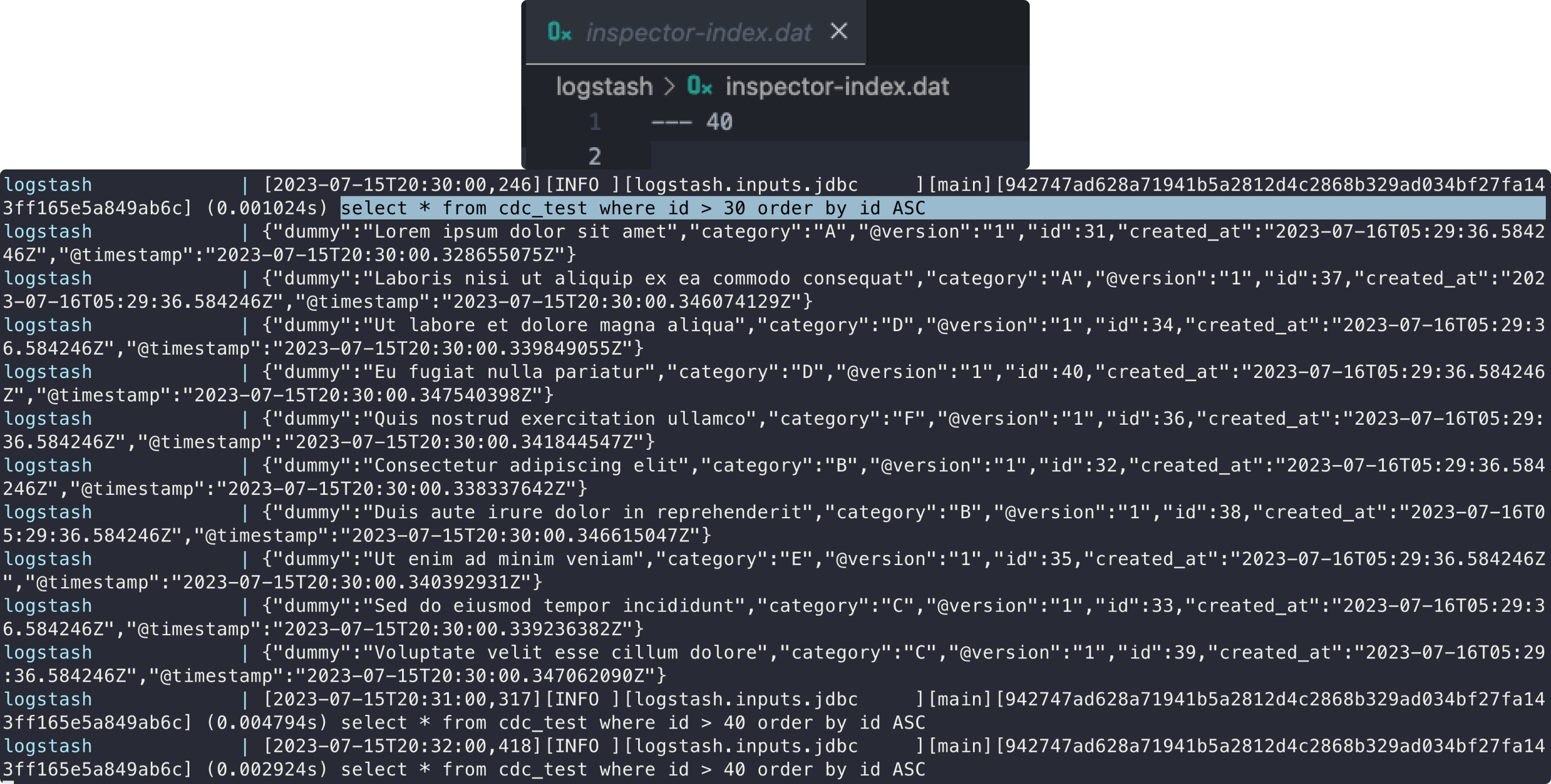
2023-07-02 18:00:00 [2023-07-02T09:00:00,701][INFO ][logstash.inputs.jdbc ][main][6a9a6d43c4988a629c4f0c1134966763a1c7abf3954b988a1bbb9d72d5519f52] (0.018859s) SELECT * FROM cdc_test
2023-07-02 18:00:00 {"dummy":"Sed do eiusmod tempor incididunt","@timestamp":"2023-07-02T09:00:00.721854427Z","category":"C","id":3,"@version":"1","created_at":"2023-07-02T17:12:19.286438Z"}
2023-07-02 18:00:00 {"dummy":"Voluptate velit esse cillum dolore","@timestamp":"2023-07-02T09:00:00.727398197Z","category":"C","id":9,"@version":"1","created_at":"2023-07-02T17:12:19.286438Z"}
2023-07-02 18:00:00 {"dummy":"Ut enim ad minim veniam","@timestamp":"2023-07-02T09:00:00.737814583Z","category":"E","id":15,"@version":"1","created_at":"2023-07-02T17:59:45.011087Z"}
2023-07-02 18:00:00 {"dummy":"Consectetur adipiscing elit","@timestamp":"2023-07-02T09:00:00.720813313Z","category":"B","id":2,"@version":"1","created_at":"2023-07-02T17:12:19.286438Z"}
2023-07-02 18:00:00 {"dummy":"Duis aute irure dolor in reprehenderit","@timestamp":"2023-07-02T09:00:00.725103076Z","category":"B","id":8,"@version":"1","created_at":"2023-07-02T17:12:19.286438Z"}
2023-07-02 18:00:00 {"dummy":"Ut labore et dolore magna aliqua","@timestamp":"2023-07-02T09:00:00.736237676Z","category":"D","id":14,"@version":"1","created_at":"2023-07-02T17:59:45.011087Z"}
...생략3) logstash.conf input 설정 뜯어보기
-
jdbc_driver_library: JDBC 드라이버 JAR 파일의 경로를 설정한다. -
jdbc_connection_string: PostgreSQL 데이터베이스에 연결하기 위한 정보를 설정한다. -
jdbc_user및jdbc_password: PostgreSQL 데이터베이스에 액세스하기 위한 사용자 이름 및 비밀번호를 설정한다. -
jdbc_driver_class: jdbc를 사용하는 만큼 어떤 jdbc module을 핵심적으로 사용할지 세팅하는 부분이다. -
statement: 가져올 데이터를 쿼리로 세팅한다. query based cdc의 가장 핵심적인 부분이 된다. -
schedule: query를 실행할 주기를cron형태로 세팅한다. 안되어 있으면 한 번 input이 일어난 뒤에 service kill 된다. -
jdbc_paging_enabled&jdbc_page_size: 위 설정값엔 없지만, select 등의 결과값을 한 번에 너무많이 가져올 경우 target db가 lock 걸릴 리스크가 있다. 특히 target db가 엔터프라이즈 db의 경우 CDC를 위한 query를 던질 때 마다 api가 timeout이 나는 기적을 경험할 수 있다.- 이를 위해 pagination 기능을 제공하며 size와 offset값을 활용해 세팅한 row값 만큼만 가져오게 세팅할 수 있으며,
jdbc_paging_enabled가true여야jdbc_page_size를 세팅할 수 있다. - 상세한 내용은 es jdbc official docs를 참고하길 바란다.
- 이를 위해 pagination 기능을 제공하며 size와 offset값을 활용해 세팅한 row값 만큼만 가져오게 세팅할 수 있으며,
input {
jdbc {
statement => "SELECT id, mycolumn1, mycolumn2 FROM my_table WHERE id > :sql_last_value LIMIT :size OFFSET :offset",
jdbc_paging_enabled => true,
jdbc_paging_mode => "explicit",
jdbc_page_size => 100000
}
}추가적인 설정하기
-
위에서 부족한 부분이 있다.
schedule마다 실행되는 것은 좋으나, 계속 query의 result를 모두 output으로 준다는 것이다. CDC를 위해서 "마지막으로 읽은 부분을 기억하고 해당 부분 부터 가져와야 한다" 것이 중요하다. -
가장 먼저 봤던
docker-compose.ymlfile에서 logstash의 volumes에 잡혀있던/usr/share/logstash/inspector-index.dat가 "마지막으로 읽은 row, line을 기록하는 file" 이다.fluented, promtail 등이 사용하는 컨셉이 같다! -
그래서 볼륨으로 잡아줄
./logstash/inspector-index.dat파일을 아래와 같이 구성하고,logstash.conf에 설정값을 추가해 주자!
input {
jdbc {
# ...생략
# 추가 및 수정된 설정값
use_column_value => true
tracking_column => id
last_run_metadata_path => "/usr/share/logstash/inspector-index.dat"
statement => "select * from cdc_test where id > :sql_last_value order by id ASC"
}
}-
use_column_value: 해당 값이 true여야 statement에sql_last_value변수를 사용할 수 있으며, file로 저장되는 id 값 metadata를 저장하고 가져올 수 있다. -
tracking_column: 마지막에 읽은 값 기준을 잡아줄 컬럼 명을 설정하는 값이다. 기본적으로 auto incre 세팅이 되어있는 값을 pk로 잡으니, 해당 값을 기준으로 잡으면 좋다. 그리고 값은numeric또는timestamp를 가지며 기본값은numeric이다! -
last_run_metadata_path: 마지막에 읽은 값을 저장할 file path를 세팅한다. 위 compose yaml에서 세팅한 볼륨 경로로 맞춰주면 된다. -
statement값 역시 위 설정에 맞춰서 바뀌었다. 그리고 "마지막에 읽은 값" 이기 때문에 select order by를 꼭 "ASC" 로 해야한다! -
자 이제 다시 실행보자! 그러면,
inspector-index.dat이 업데이트 되면서 매 분 query가 실행될 때 마다 같은 결과 값이 아닌 추가된 값만 출력되는 것을 볼 수 있다!
3. ELK & PSQL CDC 구성 마무리
기본적인 활용은 살펴봤다! 이제 logstash의 output을 elastic search와 이어주면 끝난다!
1) logstash.conf output to elasticsearch
- input은 section 2에서 세팅한 값을 그대로 가져가고, output만 elasticsearch로 가도록 바꿔보자.
output {
elasticsearch {
hosts => ["https://es01:9200", "https://es02:9200", "https://es03:9200"]
user => "elastic"
password => "admin123!"
index => "cdc-test"
document_id => "%{id}"
ssl => true
cacert => "/usr/share/logstash/certs/ca/ca.crt"
}
stdout { codec => json_lines }
}-
3대의 node의 cluster라 hosts에 3대의
hostname:port로 세팅해준다. ps) nat환경이라 3대 노드 모두 9200번 포트 개방할 필요 없다. -
중요한점은 3대 모두 기본 보안세팅으로 자체 ssl인증서 기반 https만 허락하는 상태라
ssl값과cacert값을 꼭 세팅해 줘야 한다. 그렇기 때문에 위의 docker compose file volume에 cert를 잡은 것이다. -
document_id: 각 이벤트에 대해 고유한 문서 식별자를 세팅한다. es에서 색인된 문서의_id값으로 사용된다! -
그리고 multi output을 지원하기 때문에 "stdout" 도 디버깅을 위해 세팅을 같이 했다. 이제 기본적인 모든 준비가 끝났다, set-up, elastic node 3대, kibana, logstash, postgresql 7개의 컨테이너 컴포즈 모두 합쳐서 실행해 보자!
docker compose -f ./docker-compose.yml -p elk-cdc-app up -d
index 세팅 팁
-
이전 글 Elasticsearch - 루씬 기본 개념과 ES 시스템 및 데이터 구조(Node, Index, Shard) 이해하기 에서 alias 를 봤다면, 위에서 세팅한 logstash output의 index 부분에 alias 값을 세팅하면 좋겠다는 것을 catch할 수 있다.
-
즉 "하나의 alias에 복수개의 index를 연결" 이 가능하고, 1:1 일때는 insert & delete도 가능하기 때문에 1개는 나머지 인덱스 조회 전용으로, 1개는 가장 최근의 index로 1:1 세팅해서 cdc로 계속 이어가면 되는 것이다.
2) kibana로 CDC testing
- 왼쪽
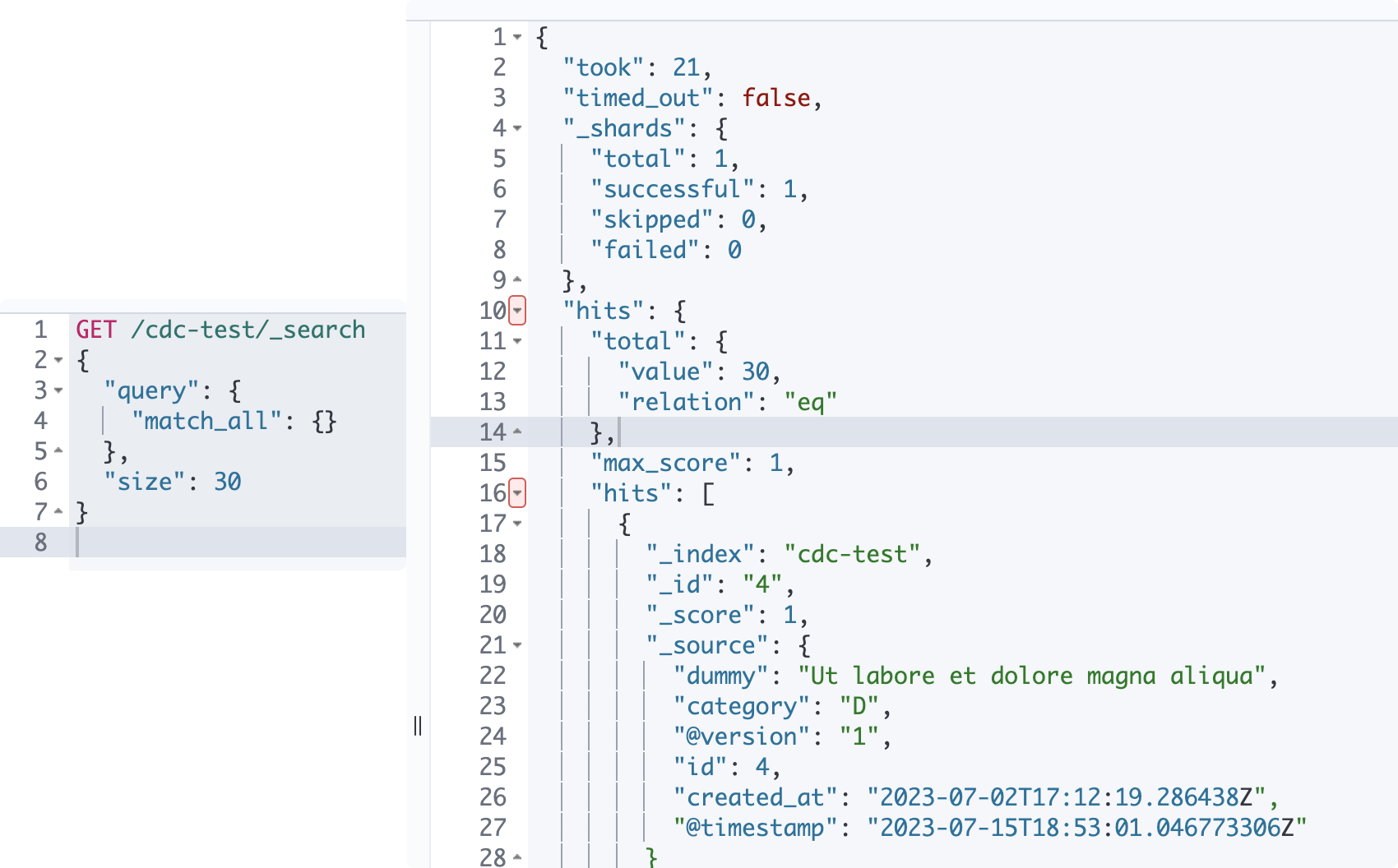
nav bar>Management>Dev Tools에서 테스팅해보자! get all을 위해 아래 search query를 때려보면, 다음 사진과 같은 결과값을 얻을 수 있다. 참고로 es는 기본적으로 10개를 response로 주기 때문에size세팅이 필요하다.
GET /cdc-test/_search
{
"query": {
"match_all": {}
},
"size": 30
}
- 위에서 사용한 insert into를 통해 10개 더 넣어보면, 아래와 같다!
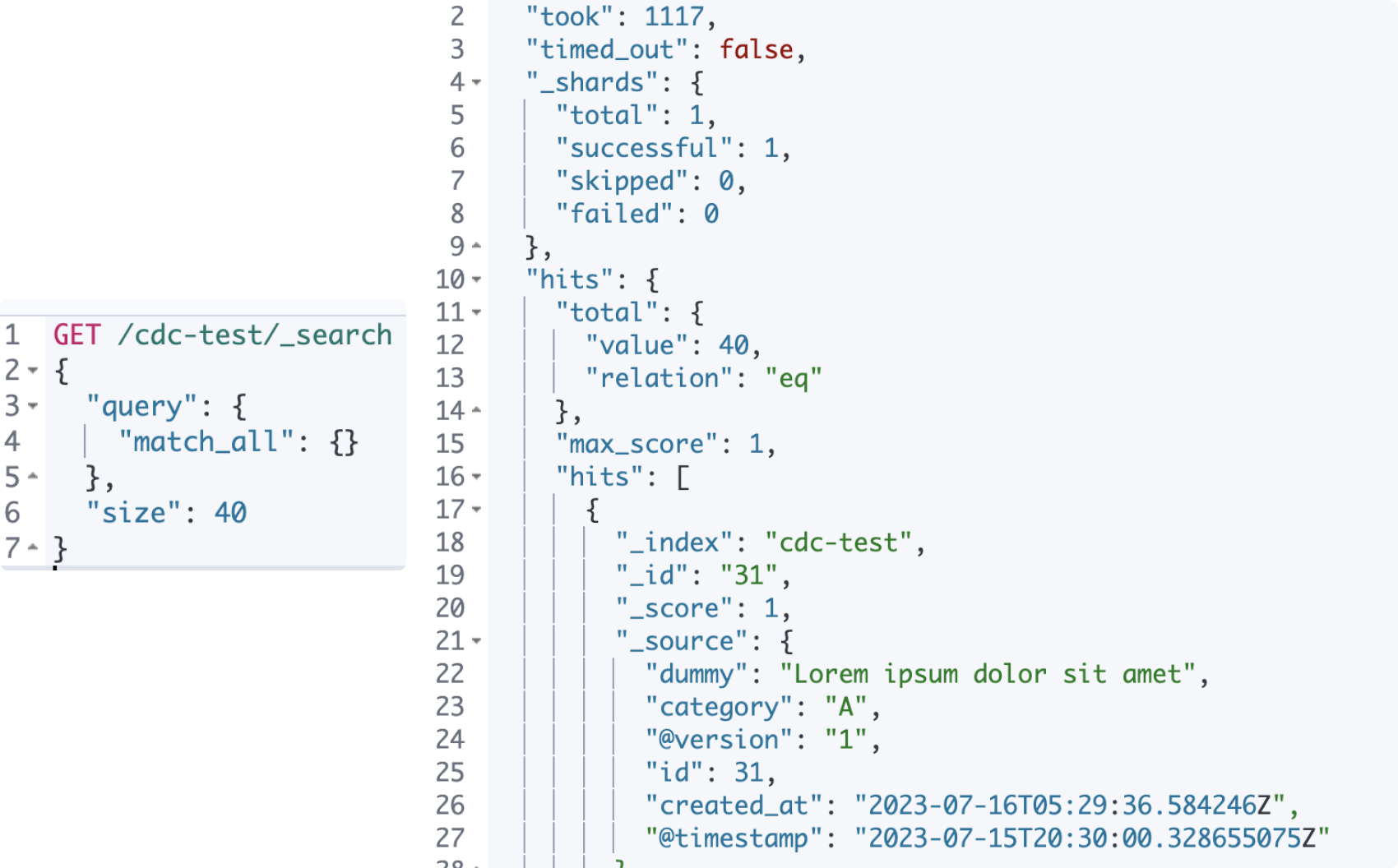
- 어떤 노드에 얼마나, 어떻게 저장되어 있을까?
GET /_cat/shards/cdc-test?v명령어로cdc-testindex 저장되어 있는 샤드들을 보여준다. 아래 사진을 보면 "primary로 es02에 저장" 되어 있고 "es03에 duplication" 되어 있는 것을 볼 수 있다.

GET /_cat/indices/cdc-test?v명령어를 통해서는 인덱스 수준에서 (인덱스 관점 및 중심) 결과를 보여준다. 아래와 같다.

primary, es02를 죽이고 search를 때리면 어떻게 될까?
- es02를 강제로 죽이고 다시
GET /_cat/shards/cdc-test?v를 때려보면 아래와 같이 es03이 primary를 차지하고, es02는UNASSIGNED상태가 된 것을 확인할 수 있다.GET /cdc-test/_searchquery 때려면 아주 응답도 잘 준다! (index 이름이 다른 이유는 다음 step을 보면 알 수 있다 ㅎ)

3) alias & operation tip
alias
- 앞서 언급한 index 세팅 팁에서 alias 세팅을 해보자!
cdc-testindex를 묶음 read 전용으로, logstash 가 데이터를 밀어 넣을 땐YYYY-MM-DDiso format 형태의 날짜를 달아주자!
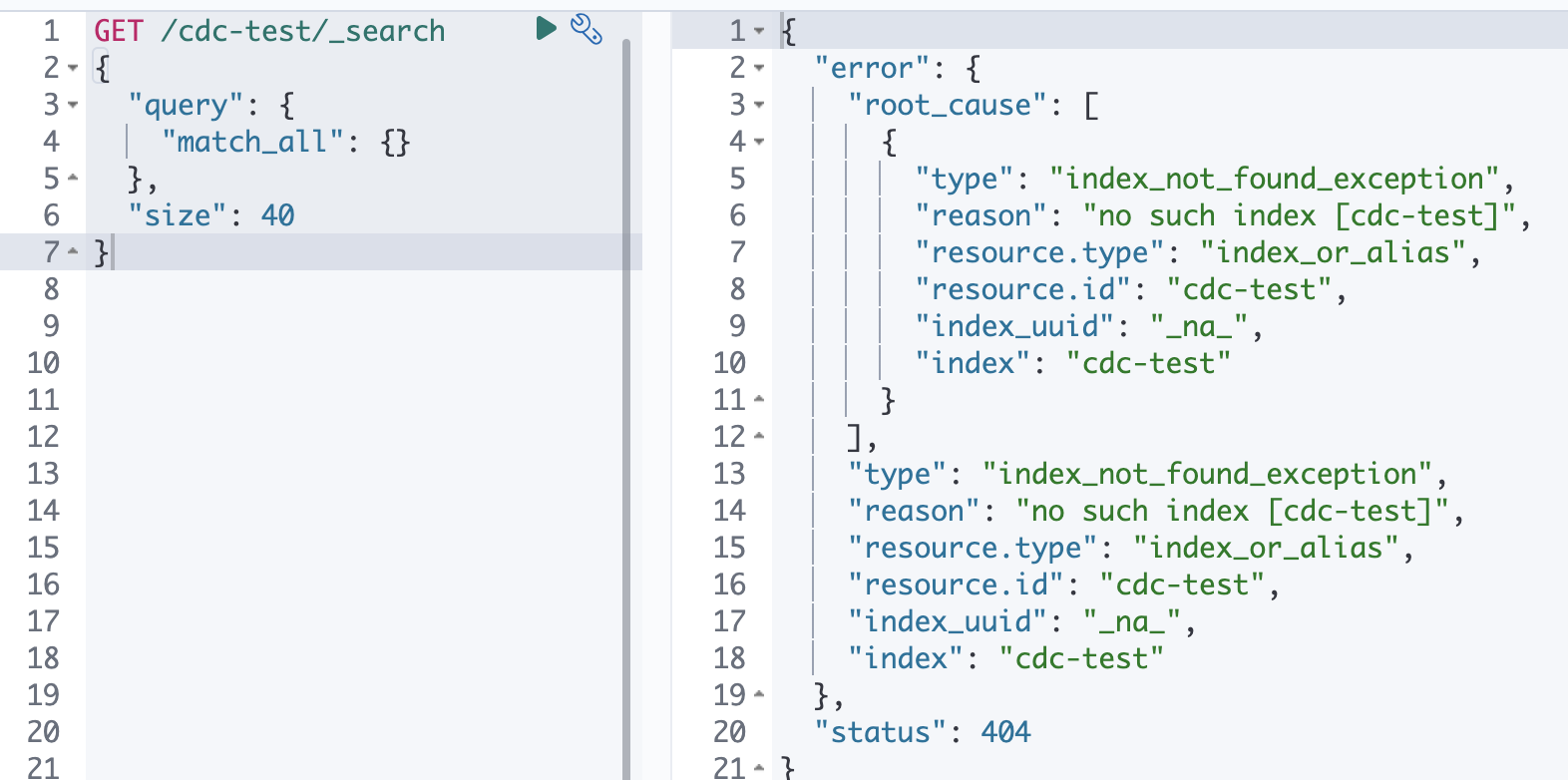
1. 이전에 세팅한 데이터와 index 값을 깔끔하게 삭제하자
# 인덱스의 모든 문서를 삭제한다! 대량의 문서를 처리시 실행 시간이 오래 걸릴 수 있다!
POST /cdc-test/_delete_by_query
{
"query": {
"match_all": {}
}
}
# 이제 인덱스도 삭제한다!
DELETE /cdc-test- 이렇게 삭제하고 cdc-test index query 때려보면 아래와 같이 나와야 한다.
- 추가로 데이터를 id 0부터 새로 밀어넣으려면, last index를 기억하는
inspector-index.dat값도 0으로 세팅해줘야 한다.
2. logstash.conf output 에서 index 부분을 아래와 같이 바꾸자! Logstash는 따로 세팅을 안하면 날짜는 무조건 UTC 기준이다!
output {
elasticsearch {
# ...생략
index => "cdc-test-%{+YYYY-MM-dd}"
# ...생략
}
# 나는 죽어도 UTC가 싫다라면 아래와 같이 filter 세팅에 timezone을 추가해주자
filter {
date {
match => ["timestamp_field", "ISO8601"]
target => "timestamp_field"
timezone => "Asia/Seoul"
}
}- 이제 logstash container만 재시작하면 새로 데이터를 밀어넣을 것이다.
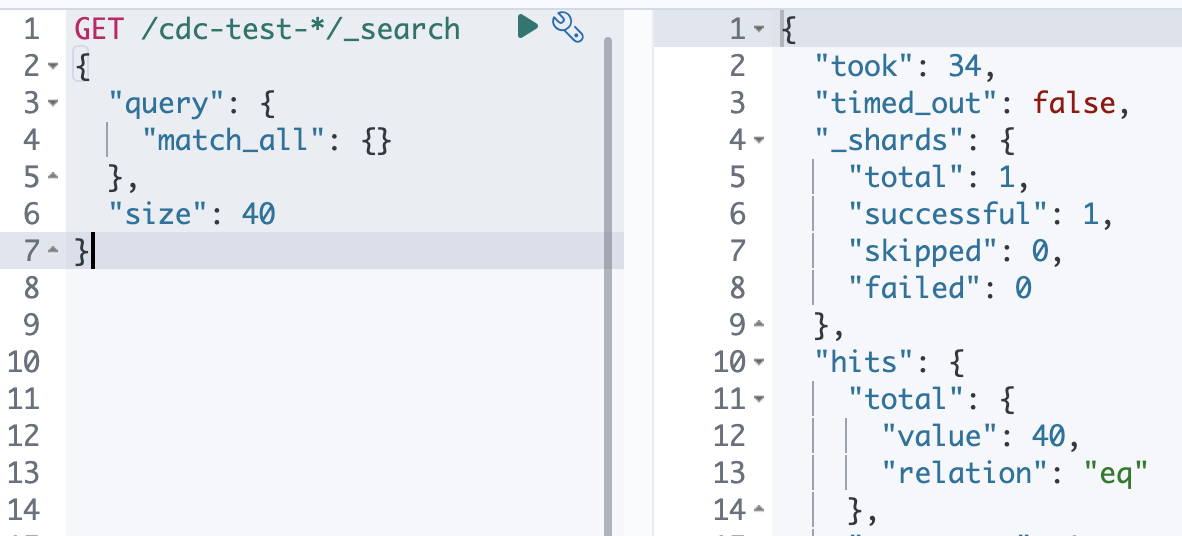
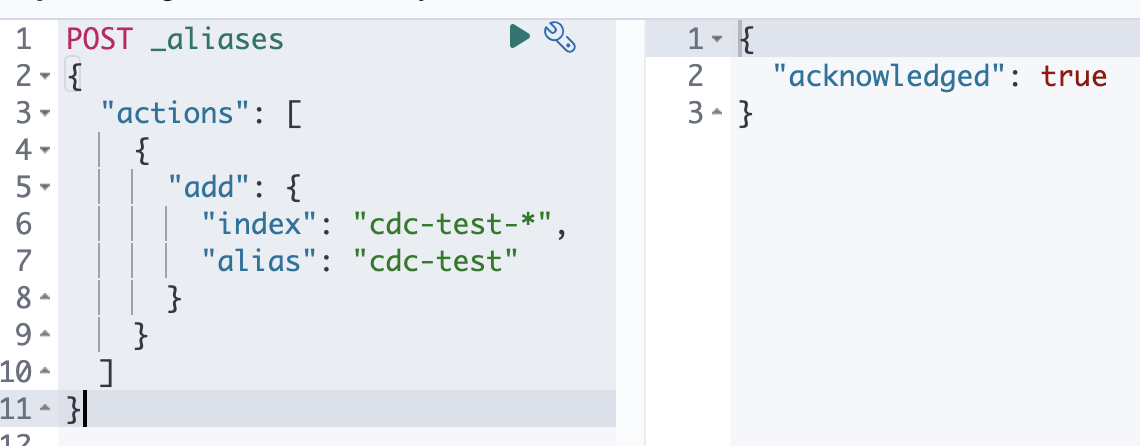
- 이게 핵심이다. 이제
cdc-test라는 alias를 세팅하는데 대상 index는cdc-test-*라는 것이다. 그러면 이제 index search 때릴 때cdc-test만 써도 되는 것이다.

3. 근데 써드 파티에서 신규 데이터 insert를 해야하고, 오래된 데이터는 remove 해야한다.
-
cdc-test는 1:N 이라 read only이다. 하지만 특정 인덱스로 임의 데이터 밀어넣기 또는 써드 파티를 사용할 때는? 1:1로 세팅된 alias가 필요하다는 것이다. -
즉,
cdc-test-2023-07-16라는 data insert 전용 alias를w-cdc-test로 세팅하고,cdc-test-2023-04-16라는 3개월이 이상 지난 index는 remove 전용 alias를 세팅해야 하는 것이다.
POST _aliases
{
"actions": [
{
"add": {
"index": "cdc-test-2023-07-16",
"alias": "w-cdc-test"
},
"remove": {
"index": "cdc-test-2023-04-16",
"alias": "w-cdc-test"
}
}
]
}- 이제 그냥
w-cdc-test에 alias로 mapping된 index만 바꿔주면 된다! PUT 할 때 역시w-cdc-test를 쓰면 되고, DELETE를 하면cdc-test-2023-04-16가 지워질 것이다.
4. 전체 데이터 동기화 잘 된것을 어떻게 보장하나?
-
여기서는 또 역시 다양한 테크닉이 들어갈 수 있다. 하지만 가장 쉽고 빠른 길은 "캐시 서버" 를 활용하는 것이다. 위와 같이 alias 세팅을 했으면 오늘 날짜에 해당하는 index가 있고, 다음날이 되기 전 총 동기화된 데이터를 확인할 수 있다.
-
target db에서 생성되는 cdc target data를 cache server에서 총 insert되는 개수를 하루 TTL로 기억하고 있으면 된다. 하루 TTL이 조금 그렇다면, cache key를 date를 포함한 값으로 세팅해 약 30시간 TTL로 세팅하고, 전 일자 index
ex) cdc-test-2023-07-16의 documents 수와 cache가 기억하는 수를 기억하면 운영 DB 스트레스 없이 체크도 가능하다.
5. 추가 고려 사항
-
query based cdc는 데이터를 운영 DB에 스트레스를 줄 수 있다는 점, query fail 또는 last index file issue로 중복 값과 last index 유실이라는 리스크도 분명 존재한다. 하지만 여기서 다룬 세팅만 제대로 해도 해당 상황은 바로 대응 할 수 있을 것이다.
-
추가로 고민해야할 점은, 여기서는 사실 단일 target DB로 다루었지만, source DBMS가 clustering된, sharding된 DBMS라면?, 각 샤드마다 CDC agent를 둔다고 가정하자, 그러면 그 CDC agent가 각 shard에 저장되는 data를 모두 "올바른 순서, pk 증가 순서" 로 가져올 수 있는가? 사실 이러한 ordering 문제는 CDC를 구축하면서 해결해야할 과제이기도 한 것 같다.
-
🔥 https://github.com/Nuung/elk-psql-cdc-boilerplate 해당 레포에서 전체 완성본 체크 가능합니다.
출처
- https://esbook.kimjmin.net/
- https://www.guru99.com/elk-stack-tutorial.html
- https://www.elastic.co/kr/blog/getting-started-with-the-elastic-stack-and-docker-compose
- https://github.com/deviantony/docker-elk/blob/main/docker-compose.yml
- https://debezium.io/blog/2018/07/19/advantages-of-log-based-change-data-capture/
- https://www.elastic.co/guide/en/logstash/current/advanced-pipeline.html
- https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
