
[ "한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다." ]
NLP 와 LLM 실전 가이드
리오르 가지트(Lior Gazit): 금융 분야 머신러닝 그룹의 수석 디렉터이자 신생 스타트업의 수석 머신러닝 자문위원으로서 업계에서 풍부한 지식과 경험을 바탕으로 존경받는 리더이다. 링크드인
메이삼 가파리(Meysam Ghaffari): 현재 MSKCC에서 근무하며 의료 문제를 해결하기 위한 머신러닝과 자연어 처리 모델의 개발과 최적화에 전념하고 있다. 머신러닝 분야에서 9년 이상, 자연어 처리와 딥러닝 분야에서 4년 이상의 실무 경험이 있다. 링크드인
🔥 8 ~ 9 장을 위한 박조은(옮긴이) 님의 youtube 영상
리뷰
진짜 공부하고 싶게 만드는 책이다. 흩어져있는 자연어의 A to Z 를 정석같이 일목요연하게 정리되어 있어서, 모든 챕터 하나 하나가 이정표 역할을 한다. 특히 NLP 입문자에 가까운 나에게 길 잃지말라고 계속 가이드를 준다.
각 챕터가 배경 지식을 하나씩 쌓아가는 형태고, 서술하는 방식이 "장 소개", "목차와 전체 내용" 을 짚고 세부 내용으로 하나씩 진행하는게 "자연어 처리" 라는 분야의 official docs 를 읽는 것 같다.
책은 (주관적으로) 크게 3개 섹터로 이뤄지는 것 같다.
- ML을 위한 기초 지식, ML을 학습하기 위한 기존의 방법들 (자연어 처리 중심)
- 현 시점 SOTA, LLM 에 대한 얘기, 활용과 실습 중심
- 그리고 미래에 대한 전망
초반부에서 다루는 선형대수, 확률, 통계는 실제로 머신러닝 실습을 하는 사람이라면 반드시 알고 있어야 하는 내용들이다. 다만 이 책은 자세한 설명을 일일이 파고드는 스타일이 아니라, 중요한 핵심 개념을 "놓치지 않게" 딱딱 짚어준다. 개인적으로는 이 부분이 정말 좋았다. 너무 깊게 들어가면 NLP 입문자 입장에서 부담스러울 수 있는데, 딱 적절한 수준에서 정리해준다.
CH3부터 CH6까지는 기존 머신러닝 기반 자연어 처리의 전통적인 구조를 설명한다. 전처리, 피처 엔지니어링, 분류, 모델 평가로 이어지는 이 흐름이 아주 교과서적이다.
특히 좋았던 점은 많은 책들이 대충 넘기는 텍스트 전처리를 이 책은 굉장히 다양한 방법론과 함께 자세히 짚고 간다는 것이다. 소문자화, 특수문자 제거, 정규표현식, 불용어 제거, 표제어 추출, 개체명 인식(NER), 품사 태깅(POS tagging) 등이 각각 어떤 맥락에서 중요하고, 어떤 선택지를 고려할 수 있는지 다룬다. 단순한 예제 코드가 아니라 실무적인 감각으로 설명한다.
그리고 CH6부터는 트랜스포머 기반 딥러닝 언어 모델로 넘어가는데, 여기서부터는 NLP 입장에서의 최신 기술 스택에 대한 안내서처럼 구성된다. RNN, CNN을 넘어서 왜 트랜스포머가 등장했는지, BERT와 같은 모델이 어떻게 문맥을 이해하고 분류 성능을 높일 수 있는지 서술한다.
개인적으로는 여기까지 읽고 "실전 가이드 맞네" 라는 생각이 들었다. 설명은 교과서 같지만, 적용은 실전에 가깝게 잘 정돈되어 있다.
CH7부터 CH9까지는 GPT, BERT, LLaMA, PaLM 같은 대규모 언어 모델의 구조와 트렌드, 활용 사례를 다룬다. 특히 OpenAI의 RLHF 접근 방법을 풀어낸 부분은 실전에서 LLM을 접했던 입장에서 더 인상 깊었다. (최근에 읽었던 "GPT API를 활용한 인공지능 앱 개발" 책의 내용을 응축해둔 듯한 느낌)
그리고 10장부터는 자연어 처리와 LLM의 현재와 미래에 대한 이야기다. 이 부분은 책의 인문학적인 성격도 살짝 느껴졌다. 무어의 법칙부터 시작해 GPU, TPU, 양자컴퓨팅, LLMOps, 임베딩 구조, 백터DB, RAG의 중요성까지 기술적인 내용과 산업 트렌드를 폭넓게 다룬다. 여기서 인상 깊었던 건 단순히 기술의 발전만을 다룬 것이 아니라, 아래 흐름으로 으로 알려줘서, 지금 그 흐름 위에 있다는 걸 다시 인지 할 수 있었다.
- 산업 전반에 어떤 변화가 일어났는지
- 왜 CAIO(Chief AI Officer) 같은 포지션이 등장했는지
- 다중 에이전트, AutoGen, LFM(대규모 기초모델) 같은 흐름이 왜 주목받는지
딥러닝 기반 자연어 처리의 전통적인 접근부터 LLM, RAG, 그리고 미래까지 이어지는 흐름 속에서 지금 어디에 서 있는지, 앞으로 뭘 알아야 할지를 알려주는 책이다.
현대는 (어떤 형태의) 비즈니스 이전에 테크가 존재할 수는 없다고 생각하며 기술 그 자체로는 결코 목적이 될 수 없다고 생각한다. 우리는 언제나 '무엇을 이루고자 하는가'라는 목적에서 출발해야 한다. 그리고 그 목적을 이루기 위해 가장 날카롭고 적절한 수단과 도구를 선택하는 것이다. 이 책은 바로 그런 관점에서, 다양한 도구와 방법론들을 마치 잘 정리된 도구 상점처럼 펼쳐 보인다.
목차별 리뷰
모든 목차를 다루기엔 책에서 다루는 범위와 영역이 너무 거대해서 할 수 없다..! 상대적으로 유연한 초반부만 좀 세부적으로 정리하고, 후반부는 철저하게 리뷰 중심이다.
(PS. 참고로 저작권을 위해 모든 내용은 당연히 있으면 안된다.)
CH1. 자연어 처리 개요 살펴보기
이 장에서는 자연어 처리의 역사와 접근 방식을 간결하게 조망한다. 초창기 튜링 테스트를 시작으로, 50~60년대 룰 기반 처리 방식과 조지타운 실험 사례 가 소개된다. 이후 70년대까지는 구조화된 접근과 개념 기반 온톨로지 도입을 통해 시스템이 조금씩 발전했다.
80년대 후반부터는 대규모 말뭉치를 활용한 통계적 접근법이 등장하면서 자연어 처리 분야가 실질적인 전환점을 맞이했다. 이 시기를 기점으로 머신러닝 기반의 자연어 처리가 본격화되고, 21세기 이후 인터넷과 함께 폭발적으로 증가한 데이터는 비지도, 준지도 학습 알고리즘의 발전을 촉진시켰다. 2010년대 이후 신경망 기반 딥러닝 기술의 등장은 자연어 처리의 패러다임을 또 한 번 바꾸었다.
자연어 처리가 단순 규칙 기반의 기술에서 데이터 기반 학습 기술로 진화해왔음을 시대별 사례를 통해 자연스럽게 보여준다. 최신 기술을 이해하는 데 앞서, 지금 우리가 딥러닝을 자연스럽게 사용하는 배경이 어떤 역사와 전환을 거쳤는지 알 수 있는 장이었다.
자연어 처리 기본 접근 전략
-
불용어 제거
문장의 전반적인 의미에 큰 영향을 주지 않는 단어들을 제거하는 과정이다. 그러나 상황에 따라 불용어도 중요한 의미를 가질 수 있어 무조건 제거하는 것은 위험할 수 있다. 문맥을 고려한 판단이 필요하다는 점이 강조된다. -
어간 추출과 표제어 추출
단어의 시제나 복수형, 파생 접사 등을 제거해 어근 형태로 축소하는 방법이다. 어간 추출은 규칙 기반으로 잘라내는 반면, 표제어 추출은 문맥에 따라 사전 기반으로 판단한다. 두 방식 모두 단어 간 유사성을 높이는 데 쓰이지만, 역시 맥락에 따라 선택이 달라질 수 있다. -
데이터 정규화와 정제
단어 단위의 전처리 외에도 텍스트 전반의 구조를 정리하는 과정이다. 특수문자 제거, 소문자화, 중복 공백 제거 같은 기본적인 작업부터, 실제 적용 시에는 파이프라인 형태로 여러 단계의 처리가 연결된다. -
전처리 파이프라이닝
여러 전처리 단계를 순차적으로 자동 처리할 수 있도록 구성하는 방식이다. 정제, 정규화, 필터링, 토큰화 등을 하나의 흐름으로 묶는 설계 방식으로, 이후 모델 학습에 사용될 데이터를 일관성 있게 다듬을 수 있다. -
사전 학습 모델과 트랜스포머의 등장
BERT, 트랜스포머 같은 모델이 자연어 처리에 끼친 영향이 간단히 소개된다. 기존의 전처리나 피처 엔지니어링에만 의존하던 방식에서 벗어나, 모델 자체가 문맥을 이해하는 구조로 바뀌었음을 시사한다.
CH2. 머신러닝과 자연어 처리를 위한 선형대수, 확률, 통계 마스터하기
거의 7~9년 전 기억이 나서 굉장히 슬펐다(?). 그때 진짜 싫었는데.. 그리고 솔직히 스스로 depth 있게 modeling 을 안하니, 이 개념을 놓치고 살았고, 앞으로도 놓치고 살고 싶다는 생각이 들었다 ㅎㅎ. 만약 이 개념이 생소하면 https://youtu.be/k_yto_vDRF0?si=m2oNb5lfz68rcHcs 과 같은 영상이라도 한 번 보는 것을 추천한다. 엄청 자세하게 정리하려고 하지는 않았는데, 스스로 정리차원에서 하나씩 곱씹어봤다.
ML 을 위한 기본적인 선형대수학
[1] 스칼라, 벡터, 행렬
- 스칼라 (Scalar): 단일 수 (예: 3, -5, 0.2).
- 벡터 (Vector): 숫자의 나열로, 행 벡터와 열 벡터로 구분됨.
- 행렬 (Matrix): 2차원 숫자 배열로, 머신러닝에서 데이터를 표현하는 기본 구조.
- 텐서 (Tensor): 다차원 배열을 의미하며, 벡터와 행렬을 일반화한 개념.
[2] 벡터 연산
- 벡터 덧셈: 동일한 차원의 벡터끼리 요소별 덧셈 수행.
- 벡터 내적 (Dot Product): 두 벡터의 대응 원소 곱의 합.
- 내적 결과는 스칼라 값. 내적은 다른 벡터에 얼마나 투영되는지 측정하는데 사용.
- 내적은 교환법칙 성립, 벡터 순서가 결과에 영향 X
- 내적이 0이면 두 벡터는 서로 직교(orthogonal).
- 내적 공식:
-
벡터 외적 (Cross Product): 3차원 벡터에서 정의되며, 두 벡터에 모두 수직(orthogonal)인 벡터를 생성하며, 방향은 오른손 법칙을 따른다. 외적 결과는 벡터 값.
-
벡터의 노름 (Norm)
- 벡터의 크기를 나타내는 값. 벡터 자신과 내적은 제곱 노름.
- 가장 많이 사용되는 노름: 유클리드 노름 (Euclidean Norm)
- 유클리드 노름 공식:
[3] 행렬 연산
- 행렬 전치 (Transpose): 행과 열을 바꾸는 연산.
- 행 벡터 ↔ 열 벡터 변환.
- 전치 연산 예시:
- 행렬과 벡터의 곱: 결과는 벡터가 됨.
- 행렬의 행렬곱 (Matrix Multiplication):
- 과 가 있을 때, 결과는 행렬.
- 교환법칙 성립하지 않음:
[4] 고윳값과 고유 벡터 (Eigenvalues and Eigenvectors)
- 정의:
- 행렬 에 대해 다음을 만족하는 벡터 와 상수 가 존재할 때:
- 는 고윳값(Eigenvalue), 는 고유 벡터(Eigenvector).
- 고윳값 분해 (Eigendecomposition):
- 대각화 가능한 행렬 는 다음과 같이 표현 가능:
- : 대각행렬 (고윳값이 대각 원소로 위치)
- : 고유 벡터를 열 벡터로 가지는 행렬
- 대각화 가능한 행렬 는 다음과 같이 표현 가능:
- ML에서의 활용:
- 주성분 분석(PCA): 데이터 차원 축소를 위해 고윳값 분해 활용.
- 특잇값 분해(SVD): 비정방 행렬의 차원 축소에 활용.
ML 을 위한 기본적인 확률
[1] 확률 개념
- 시행 (Trial): 한 번의 실험.
- 실험 (Experiment): 확률적 결과를 가지는 과정.
- 표본 공간 (Sample Space): 가능한 모든 결과의 집합.
- 사건 (Event): 표본 공간의 부분집합.
[2] 확률 변수 (Random Variable)
- 이산 확률 변수 (Discrete Random Variable):
- 가능한 값이 유한 개 또는 셀 수 있는 경우.
- 확률 질량 함수(PMF, Probability Mass Function)로 표현.
- 연속 확률 변수 (Continuous Random Variable):
- 값이 연속적인 경우.
- 확률 밀도 함수(PDF, Probability Density Function)로 표현.
[3] 조건부 확률과 독립성
- 조건부 확률 (Conditional Probability):
- 사건 B가 발생한 상태에서 사건 A가 발생할 확률:
- 독립 사건 (Independent Events):
- 사건 A와 B가 서로 독립이면:
[4] 최대 우도 추정법 (Maximum Likelihood Estimation, MLE)
- MLE 개념:
- 확률 분포의 매개변수를 추정하는 방법.
- 가능도 함수 (Likelihood Function)를 최대화하는 매개변수 선택.
- 로그 우도 (Log-Likelihood):
- 곱셈 연산보다 덧셈이 계산적으로 더 유리하여 로그 우도 사용:
- 자연어 처리에서 활용:
- 다음 단어 예측에서 가장 높은 확률을 갖는 단어를 선택하는 방식으로 사용.
- 즉, 주어진 문맥 𝑤 1 , 𝑤 2 , . . . , 𝑤 𝑡 − 1 가 있을 때, 다음 단어 𝑤 𝑡 의 확률을 최대화하는 모델을 찾는 것. 가능도 함수(Likelihood Function) 활용.
[5] 베이지안 추정 (Bayesian Estimation)
- 베이즈 정리 (Bayes' Theorem):
- 사전 확률과 데이터에 기반한 사후 확률 계산:
MLE와 달리 사전 확률을 고려하는 방식.
[6] 추가 개념
- 하우스홀더 반사 행렬 (Householder Reflection Matrix):
- 벡터를 특정 차원에서만 0이 아닌 성분을 갖도록 변환하는 행렬.
- 대각화 가능성 (Diagonalizability):
- 행렬이 대각화 가능하면 계산이 용이함.
- 가역 행렬 (Invertible Matrix):
- 역행렬이 존재하는 행렬.
- 가우스 소거법 (Gaussian Elimination):
- 연립 방정식 풀이를 위한 행렬 변형 기법.
- 행렬의 대각합 (Trace of a Matrix):
- 대각 원소의 합.
- 선형 변환의 고윳값 합과 동일.
CH3. 자연어 처리에서 머신러닝 잠재력 발휘하기
데이터 탐색
자연어 처리 모델의 성능은 입력 데이터 품질에 크게 좌우된다. 이 장에서는 데이터를 탐색하고 정제하는 과정에서 고려해야 할 핵심 요소들을 설명한다. 먼저 결측치는 전체 분석의 왜곡을 야기할 수 있으므로 반드시 처리해야 하며, 중복 데이터 역시 불필요한 중복 학습을 유발할 수 있으므로 제거 대상이다.
데이터 표준화에서는 각 특성(feature)의 평균을 0, 표준편차를 1로 맞추는 Z-score 정규화가 자주 사용된다. 반면 최소-최대 스케일링은 데이터를 0과 1 사이로 정규화하는 방법으로, 각 값의 상대적인 크기를 유지하며 모델이 특정 특성에 과도하게 민감하지 않게 도와준다.
- Z-score 정규화 (Standardization)
- μ는 특성의 평균 (mean)
- Min-Max 정규화 (Min-Max Scaling)
이상치 처리는 모델 안정성에 중요하다. 윈저화는 일정 범위 밖의 값들을 경계 값으로 조정해 이상치의 영향을 줄이는 기법이다. 또는 강건한 통계 기법을 활용해 이상치를 억제할 수도 있다. 중요한 건 이상치를 제거하는 것이 아니라, 그것이 분석 결과에 어떤 영향을 미치는지 파악하고 도메인 지식과 함께 판단해야 한다는 점이다.
데이터 오류 수정은 통계적 이상 탐지나 수동 검사 외에도 머신러닝 기반 접근법이 가능하다. 도메인 지식이 병행되면 신뢰도는 더욱 높아진다. 이후 가장 중요한 과정 중 하나는 특성 선택(feature selection) 이다. 정보량 기반 방법, 카이제곱 검정, 상관계수 분석, 라쏘 회귀(L1 패널티) 등을 통해 유의미한 특성을 골라야 한다. 또한, 고차원 데이터에서는 차원 축소 기법인 PCA(주성분 분석), LDA(선형 판별 분석)도 유효하다.
일반적인 머신러닝 모델 인프런, 파이썬 머신러닝 완벽 가이드 (추천...)
- 선형 회귀는 연속적인 수치 예측에 적합하고,
- 로지스틱 회귀는 이진 분류에 활용된다.
- 결정 트리는 해석이 쉬운 구조로 분류와 회귀 모두 가능하지만 과적합되기 쉬우며,
- 랜덤 포레스트는 여러 결정 트리를 앙상블하여 안정성과 성능을 향상시킨다.
- SVM(서포트 벡터 머신) 은 고차원에서의 마진 최대화를 통해 분류 문제에 강력하며,
- 인공 신경망은 복잡한 비선형 관계를 학습할 수 있어 텍스트, 음성, 이미지 등 다양한 도메인에서 활용된다.
특히, 트랜스포머는 자연어 처리에서 혁신적 성능을 보여준 구조로, 셀프 어텐션을 기반으로 문맥을 효과적으로 반영하는 구조다. 이는 후속 챕터에서 더 깊이 다루어진다.
모델 과소적합과 과대적합
모델이 너무 단순해서 학습 데이터조차 설명하지 못하는 경우는 과소적합(underfitting), 반대로 지나치게 복잡해 학습 데이터에만 특화된 경우는 과대적합(overfitting)이다. 이 둘의 균형을 맞추는 것이 편향-분산 트레이드오프이다.
이를 해결하기 위한 전략으로는
- 정규화 기법(L1 라쏘, L2 릿지, 또는 두 방법을 혼합한 엘라스틱넷),
- 교차 검증,
- 조기 종료(validation loss가 더 이상 줄어들지 않을 때 학습 중단),
- 드롭아웃(신경망 일부 노드를 임의로 비활성화),
- 데이터 증강,
- 앙상블 등이 있다.
데이터 분할
모델 학습 과정에서 데이터를 훈련(train), 검증(validation), 테스트(test) 세트로 나누는 것은 일반적인 접근이다. 기본적으로 8:2로 훈련-테스트를 나누거나, 더 정교하게는 K-폴드 교차 검증으로 평가의 일관성을 확보한다. 계층화 K-폴드는 클래스 불균형을 다루는 데 유용하며, 시계열 데이터의 경우 시간 순서를 고려하여 분할해야 한다.
하이퍼파라미터 튜닝
모델 학습 전에 설정하는 값들인 하이퍼파라미터(hyperparameter)는 모델 성능에 큰 영향을 미친다. 예를 들어, 학습률, 정규화 강도, 은닉층 수 등이다.
이를 튜닝하기 위한 방법에는
- 그리드 탐색(grid search): 조합을 전수조사
- 랜덤 탐색(random search): 무작위 조합을 샘플링
- 베이지안 최적화: 이전 결과 기반으로 다음 탐색 지점 예측
특히 SMBO(Sequential Model-Based Optimization)는 성능 예측 모델을 통해 탐색 효율을 높인다. 하이퍼파라미터 튜닝은 탐색 공간이 크고 평가 비용이 높기 때문에 샘플링 전략과 병렬화 등이 고려되어야 한다.
앙상블 모델
앙상블 학습은 여러 모델의 예측을 결합하여 전체 성능을 향상시키는 방법이다.
- 배깅(Bagging - Bootstrap Aggregating)
- 작동 원리: 원본 데이터셋에서 부트스트랩 샘플링(복원 추출)을 통해 여러 서브셋을 생성하고, 각 서브셋에서 동일한 유형의 모델을 학습시킨 후 결과를 통합한다.
- 통합 방식: 분류 문제에서는 투표(voting), 회귀 문제에서는 평균(averaging)을 사용한다.
- 장점: 분산(variance)을 감소시켜 과적합을 줄이고 모델의 안정성을 높인다.
- 주요 알고리즘:
- 랜덤 포레스트: 부트스트랩 샘플링으로 얻은 각기 다른 훈련 데이터를 사용하고, 특성 또한 매번 랜덤하게 선택하여 다양성을 높이는 방법이다.
- 배깅 결정 트리: 동일한 알고리즘을 사용하지만 다른 훈련 데이터로 여러 모델을 훈련시키는 방법이다.
- 부스팅(Boosting)
- 작동 원리: 약한 학습기(weak learner)를 순차적으로 학습시키며, 이전 모델이 잘못 예측한 샘플에 더 높은 가중치를 부여한다.
- 특징: 이전 모델의 오류에 집중하여 점진적으로 예측 성능을 향상시킵니다.
- 주요 알고리즘:
- AdaBoost(Adaptive Boosting): 오분류된 샘플에 더 높은 가중치를 할당하며, 각 모델의 정확도에 따라 최종 예측에 다른 가중치를 부여한다.
- Gradient Boosting: 이전 모델의 잔차(residual)나 오차에 대해 다음 모델을 학습시킵니다. 이 방식은 손실 함수의 기울기(gradient)를 최소화하는 방향으로 진행된다.
- XGBoost, LightGBM, CatBoost: Gradient Boosting의 최적화된 구현으로, 속도와 성능 측면에서 개선되었다.
- 스태킹(Stacking)
- 작동 원리: 여러 기본 모델(base model)의 예측 결과를 새로운 특성으로 사용하여 메타 모델(meta-model)을 학습시킨다.
- 구현 방식: 다양한 알고리즘으로 여러 기본 모델을 학습시킵니다 (예: 결정 트리, SVM, 로지스틱 회귀 등).
- 각 기본 모델의 예측값을 새로운 특성으로 변환한다.
- 이 새로운 특성들을 입력으로 사용하는 메타 모델을 훈련시킨다.
- 장점: 각 모델의 강점을 활용하고 약점을 상쇄하여 전체적인 예측 성능을 향상시킨다.
- 구현 시 고려사항: 기본 모델 결과의 과적합을 방지하기 위해 교차 검증을 통한 예측값 생성이 중요하다.
CH4. 자연어 처리 성능을 위한 텍스트 전처리 과정 최적화
전처리는 중요한 초기 단계이다. "원시 상태" 의 자연어를 "머신러닝 알고리즘이 쉽게 이해할 수 있는 형식" 으로 변환하는 과정 포함한다.
자연어 처리에서의 소문자 변환, 특수 문자와 구두점 제거, 불용어 제거, 개체명 인식 (NER), 품사 태깅(POS 태깅), 전처리 파이프라인 을 다룬다. NLTK, spaCy, 사이킷런 라이브러리 활용한다. (with 쥬피터노트북)
1. 자연어 처리에서의 소문자 변환
-
소문자 변환은 텍스트 전처리에서 가장 먼저 수행되는 작업 중 하나로, 전체 어휘 집합의 복잡도를 줄이고 통일성을 확보하는 데 도움이 된다. 예를 들어 "Apple"과 "apple"을 동일하게 처리함으로써 분류기나 모델이 더 안정적으로 학습할 수 있다.
-
하지만 모든 상황에서 유용한 것은 아니다. 특히 개체명 인식(NER)에서는 대문자 정보가 중요한 신호가 되기 때문에, 무작정 소문자로 바꾸는 것이 오히려 성능 저하로 이어질 수 있다.
-
책에서 소개된 정규 표현식 예시인
re.sub(r'[^A-Za-z0-9]+', '', text)는 공백까지 제거하는 잘못된 패턴으로 보인다.re.sub(r'[^A-Za-z0-9\s]+', '', text)처럼 공백은 살리고 특수 문자만 제거하는 패턴을 말하고자 한 것 같다.
2. 특문과 구두점 제거
- 텍스트에서 특수 문자나 구두점은 대부분 의미가 약하거나 노이즈로 작용하는 경우가 많다. 따라서 이들을 제거함으로써 모델의 학습을 보다 효과적으로 만들 수 있다. 그러나, 예외적인 경우(예: 감정 분석에서 느낌표)에는 정보 손실로 이어질 수 있어 주의가 필요하다.
3. 불용어 제거
- 불용어(stopwords)는 텍스트 의미에 큰 영향을 주지 않는 단어들로, 예: a, an, the, and, in, at 등이 있다. 불용어 제거를 통해 어휘 크기와 특성 공간의 차원을 줄여 효율성을 높일 수 있다.
- 한글 불용어 제거
4. 맞춤법 검사와 교정
- 텍스트 내 오타나 철자 오류는 전처리 단계에서 수정해야 한다. 사소한 오탈자 하나가 모델의 처리 단위를 바꿔 성능을 저하시킬 수 있기 때문이다.
5. 표제어 추출
- 단어를 기본 형태 또는 사전 형태인 표제어로 단순화하는 텍스트 정규화 방법이다.
- 예: "cats" → "cat", "mice" → "mouse". 단어의 품사 정보까지 고려하므로 정교한 처리가 가능하다.
6. 어간 추출
- 단어를 기본적이거나 뿌리 형태로 축소하는 과정이다. 이때 뿌리를 어간(stem) 이라 한다.
- 품사나 문맥은 고려하지 않기 때문에 다소 과도한 변형이 발생할 수 있음을 유의해야 한다.
- KoNLPy 의 okt 형태소 분석기가 어간 추출 기능 제공한다.
개체명 인식
- NER은 텍스트 내에서 사람, 조직, 장소와 같은 고유명사를 탐지하고 분류하는 작업이다.
- 주로 조건부 무작위장(CRF), 순환 신경망(RNN) 기반 모델이 사용된다.
- 트랜스포머 기반의 BERT 역시 최근 NER 성능을 크게 향상시킨 대표적 모델이다.
- 이 챕터에서는 관련 구현 예제를 깃허브 코드로 제공한다.
품사 태깅
- 단어에 명사, 동사, 형용사 등의 품사 태그를 부여하는 과정으로, 다음 세 가지 접근이 있다.
-
규칙 기반 방법
예: 단어가 -ing로 끝나면 동명사일 가능성, 앞에 관사가 있으면 명사일 가능성 -
통계 기반 방법
은닉 마르코프 모델(HMM), 조건부 랜덤 필드(CRF)를 활용한 확률적 추론 기반
문맥에 따라 가장 가능성 높은 품사를 선택한다. -
딥러닝 기반 방법
RNN, 특히 LSTM 셀을 사용한 시퀀스 모델 기반의 접근
입력 레이어에 워드 임베딩을 넣고, LSTM 레이어를 통해 문맥 정보를 처리한 뒤, 출력 레이어에서 품사 태그를 예측한다.
최근에는 BERT 같은 트랜스포머 기반 모델이 더 높은 정확도로 POS 태깅을 수행한다.
관련 코드도 깃허브 레포에 포함되어 있다.
정규 표현식
- regex, regexp, 쉽고 빠른 유효성 검증 가능한 접근 법이다.
- 검색 및 교체, 특정 패턴에 따른 데이터 추출에 유리하다!
토큰화
- tokenization, 텍스트를 토큰 단위로 분리하는 과정이다.
- 단어 토큰화: 공백이나 구두점을 기준으로 분리
- 문장 토큰화: 마침표, 느낌표 등을 기준으로 분리
- 서브워드 토큰화: WordPiece(BERT), Byte Pair Encoding(BPE) 등을 활용해 희귀어(OOV)를 처리
- BERT에서는 WordPiece 방식이 사용되며, 드물거나 긴 단어도 부분적으로 분할해 처리할 수 있는 장점이 있다.
전처리 파이프라인 예시와 개체명 인식 및 품사 태깅은 깃허브 레포 코드로 상세하게 볼 수 있다.
CHAPTER 5 텍스트 분류 강화: 전통적인 머신러닝 기법 활용하기
텍스트 분류의 유형
텍스트 분류는 말 그대로 텍스트 데이터를 어떤 카테고리에 속하는지 판단하는 작업이다. 이때 사용할 수 있는 학습 방식은 크게 지도 학습, 비지도 학습, 준지도 학습으로 나뉜다.
-
지도 학습은 레이블이 부여된 데이터를 통해 학습하고, 이후에는 새로운 텍스트에 대해 자동으로 레이블을 예측할 수 있다. 주요 알고리즘으로는 나이브 베이즈, 로지스틱 회귀, 서포트 벡터 머신(SVM)이 있다. 특히 SVM은 초평면을 이용한 분류로 유명하다.
-
비지도 학습은 레이블 없이 데이터 내 숨겨진 구조나 패턴을 발견하는 접근이다. 군집화(Clustering), LDA(Latent Dirichlet Allocation, 잠재 디리클레 할당), Word2Vec, GloVe와 같은 임베딩 기반 학습 등이 대표적이다. 특히 Word2Vec과 GloVe는 단어를 밀집 벡터로 표현하여 의미론적 유사성을 잘 반영할 수 있도록 한다.
-
준지도 학습은 지도와 비지도의 중간 형태로, 레이블이 일부만 부여된 상황에서 지도학습과 비지도학습을 혼합하여 모델을 훈련시킨다. 대표적인 방법으로 레이블 전파(Label Propagation), 공동 훈련(Co-training) 등이 있다.
TF-IDF를 활용한 텍스트 분류
가장 전통적인 텍스트 분류 접근은 원-핫 인코딩(One-hot Encoding)이나 단어의 등장 빈도를 바탕으로 특징을 추출하는 방법이다. 흔히 사용하는 방법이 단어의 출현 빈도를 기준으로 문서를 벡터화하는 단어 가방(Bag of Words, BoW) 모델이다.
BoW의 단점은 문서마다 단어의 중요도를 반영하지 못하는 것인데, 이를 보완하기 위해 등장한 것이 TF-IDF(Term Frequency - Inverse Document Frequency)이다.
TF는 특정 문서에서의 단어 빈도IDF는 그 단어가 다른 문서에서 얼마나 드물게 나타나는지를 수치화
이를 곱한 TF-IDF 값이 클수록 특정 문서에서 해당 단어가 중요하다고 판단한다.
TF-IDF 는 단어의 중요도를 반영한 특징 벡터를 만들어 SVM, 로지스틱 회귀 등의 분류기에 적용할 수 있으며, 실무에서도 여전히 많이 사용되는 전통적인 접근이다.
Word2Vec을 활용한 텍스트 분류
Word2Vec 은 단어를 저차원의 실수 벡터로 임베딩하는 모델이다. 두 가지 주요 학습 방법이 존재한다.
CBOW(Continuous Bag of Words): 주변 단어들을 보고 중심 단어를 예측Skip-gram: 중심 단어를 보고 주변 단어들을 예측
Word2Vec은 학습 과정에서 확률적 경사 하강법(SGD)과 역전파(backpropagation)를 사용하여 모델 파라미터를 최적화한다. 결과적으로 학습된 임베딩은 유사한 의미를 가진 단어들이 벡터 공간에서 가까운 위치를 갖도록 표현된다.
Word2Vec을 활용하면 문서 전체를 단어 임베딩의 평균이나 합으로 표현하여 분류 문제에 활용할 수 있다.
토픽 모델링: 비지도 텍스트 분류의 특정 사례
토픽 모델링은 비지도 학습의 대표적인 사례로, 문서가 어떤 주제를 다루는지 자동으로 파악하는 방법이다. 가장 대표적인 알고리즘은 LDA(Latent Dirichlet Allocation)이다.
LDA는 각 문서가 여러 토픽의 혼합으로 구성되었고, 각 토픽은 단어들의 확률분포로 표현된다고 가정한다. 이를 통해 문서에 숨겨진 주제 분포를 추정한다.
LDA는 클러스터링이나 추천 시스템 등 다양한 NLP 태스크에 활용되며, 레이블이 없는 상황에서 유용하게 쓰인다.
머신러닝 시스템 설계
실제 분류 모델을 만들기 위해서는 학습 데이터를 분할하고(훈련/검증/테스트), 모델을 훈련한 후 적절한 평가 지표로 성능을 검증해야 한다. 또한 하이퍼파라미터 튜닝은 반드시 필요한 과정이다.
- 하이퍼파라미터는 학습 전에 설정하는 파라미터로, 학습 중에는 변경되지 않는다. 예를 들어 나이브 베이즈의 알파값, SVM의 C 값, 로지스틱 회귀의 정규화 계수 등이 이에 해당한다.
하이퍼파라미터는 모델의 성능에 큰 영향을 미치기 때문에 그리드 서치나 랜덤 서치 같은 방법으로 적절히 탐색해야 한다.
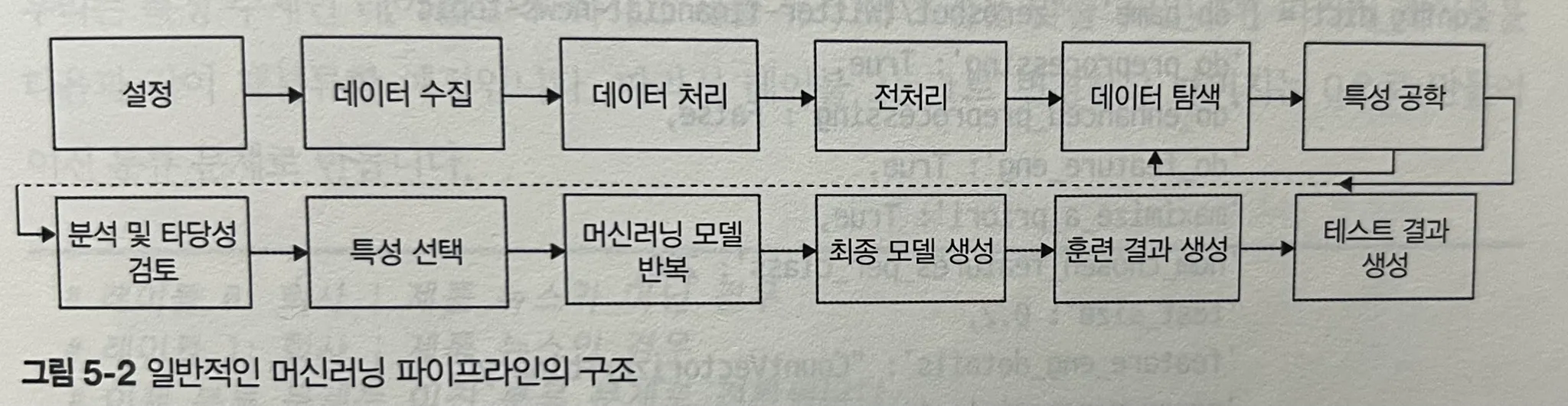
CH6. 텍스트 분류의 재해석: 딥러닝 언어 모델 깊게 탐구하기
딥러닝은 텍스트 데이터를 다루는 데 있어 기존의 RNN, CNN을 넘어서는 혁신적인 전환점을 마련해왔다. 이 장에서는 딥러닝과 자연어 처리(NLP)의 결합을 어떻게 실현할 수 있는지, 그리고 최근 가장 각광받는 트랜스포머 기반 언어 모델들이 어떤 구조와 원리로 작동하는지를 다루고 있다.
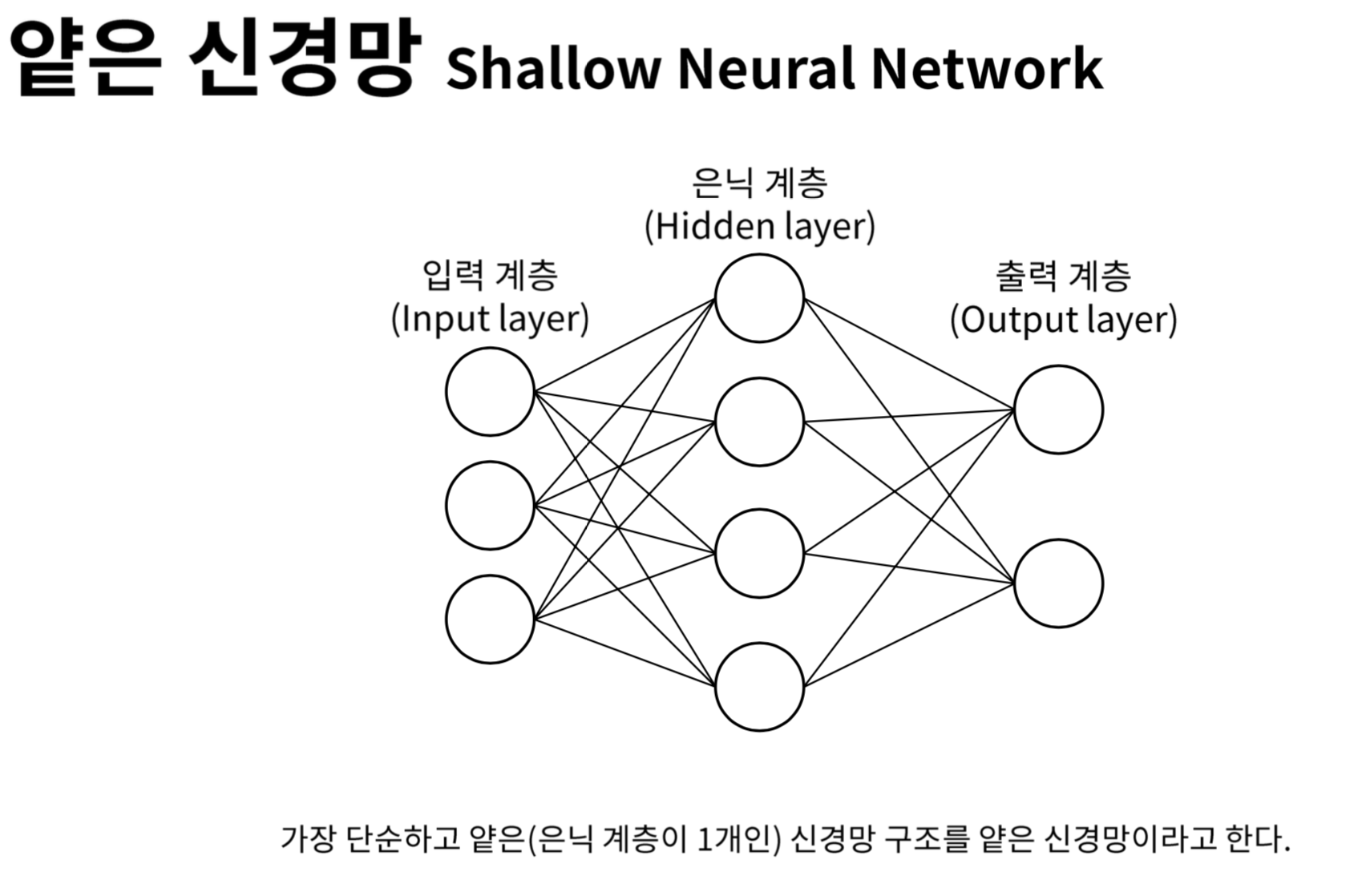
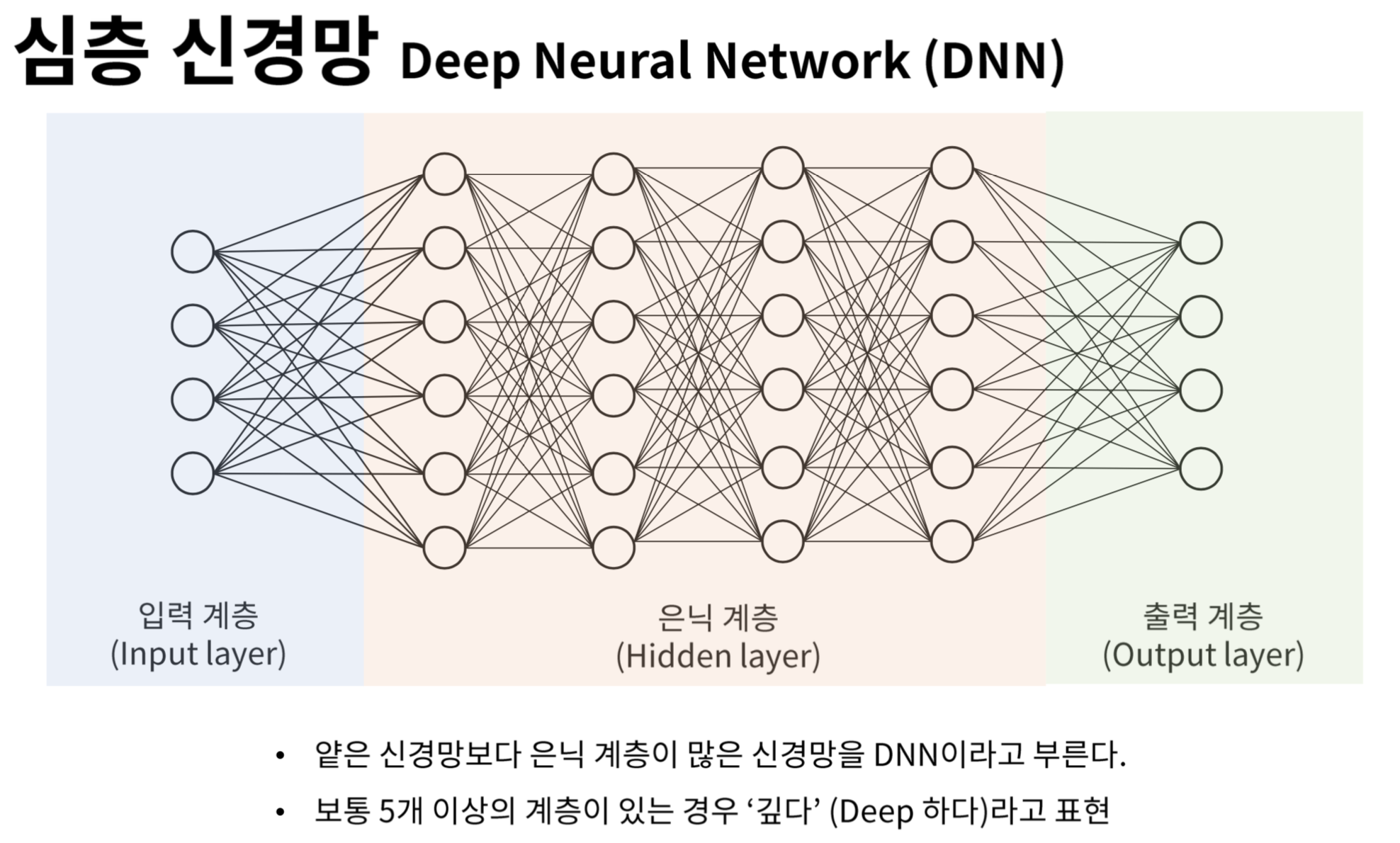
(이미지 출처: https://heung-bae-lee.github.io/2019/12/08/deep_learning_03/)
신경망의 기본 구성은 입력층, 은닉층, 출력층으로 나뉜다. 특히 은닉층은 입력과 출력 사이에서 정보를 가공하며, 가중치의 곱과 편향을 합산한 뒤 활성화 함수를 통해 비선형성을 도입한다. 주요 활성화 함수로는 Sigmoid, Tanh, ReLU, ELU 등이 있으며, 각각의 특성에 따라 네트워크의 성능이나 수렴 속도에 영향을 준다.
또한 학습의 반복을 나타내는 Epoch, 한 번의 학습에서 사용하는 데이터 크기를 의미하는 배치 크기(Batch size) 등의 하이퍼파라미터는 과대적합과 과소적합을 피하면서 최적 성능을 달성하는 데 매우 중요하다.
다양한 신경망 아키텍처
- FNN (Feedforward Neural Network): 기본적인 전방향 신경망
- MLP (Multilayer Perceptron): 은닉층이 1개 이상인 구조
- CNN (Convolutional Neural Network): 이미지 처리에 적합한 구조로, NLP에서도 특징 추출 목적으로 사용됨
- RNN (Recurrent Neural Network): 시퀀스 데이터를 다룰 수 있는 구조로, 이전 상태의 정보를 메모리 셀에 저장
- AE (Autoencoder): 입력을 압축하고 다시 복원하는 방식의 비지도 학습 모델
- GAN (Generative Adversarial Network): 생성자와 판별자가 경쟁하는 구조
트랜스포머 이해하기
트랜스포머는 논문 Attention is All You Need에서 처음 소개된 모델로, 순차적 연산이 필요했던 RNN과 달리 병렬 처리가 가능하다는 점에서 큰 혁신을 일으켰다. 핵심은 Self-Attention 메커니즘이다.
Self-Attention (셀프 어텐션)은 입력 시퀀스 내에서 각 단어가 다른 단어들과 얼마나 연관이 있는지를 파악하고, 그에 따라 가중치를 부여하는 방식이다. 이를 위해 각 단어 임베딩은 선형 변환을 거쳐 쿼리(Q), 키(K), 값(V)로 변환된다. 그 후, 다음 수식을 통해 어텐션 점수가 계산된다:
이 점곱 어텐션은 Scaled Dot-Product Attention이라 불리며, 계산된 값이 너무 크거나 작아지는 것을 방지하기 위해 로 나눈다.
한편, 트랜스포머는 순차 정보를 고려하지 않기 때문에 입력 임베딩에 위치 인코딩을 더해 각 단어의 순서를 보완한다. 위치 인코딩은 사인/코사인 함수를 활용하여 각 차원별로 주기적인 위치 정보를 부여한다.
가장 좋았던 부분은 "BERT를 텍스트 분류에 미세 조정을 하는 방법" 이 있다는 것이다. 물론 이론적인 부분이 과반이지만 앞서 설명한 얘기를 기반으로 진행하기 때문에 설명이 친절한 편이라고 생각된다. 실제로 해당 장의 마지막엔 실습이 코드와 함께 있음 (물론 실제 하려면 사전 세팅이나 준비 사항이 꽤 많이 필요함)
CH7. 대규모 언어 모델 이해하기
이번 장에서는 대규모 언어 모델(LLM, Large Language Model)의 탄생 배경과 발전 과정을 중심으로 설명하고 있다. 본격적으로 LLM이 주목받기 시작한 2018~2019년부터, 2023년에 이르기까지 NLP 분야에서 일어난 변화들을 연대기적으로 서술한다.
OpenAI가 ChatGPT로 널리 알린 RLHF는 LLM 발전의 가장 중요한 전환점 중 하나였다.
기존의 언어 모델은 단순히 대량의 데이터를 이용한 사전 학습(Pretraining)과, 정답이 있는 문제에 대한 지도 학습(Supervised Fine-Tuning)만으로는 사용자의 기대에 부합하는 응답을 생성하기 어려웠다. 이를 해결하기 위해 도입된 것이 RLHF다.
기본적인 흐름은 다음과 같다.
-
Supervised Fine-Tuning (SFT)
우선 사람이 직접 작성한 고품질 응답 데이터를 바탕으로 언어 모델을 지도 학습한다. -
Reward Model (RM) 학습
사람이 두 응답 중 더 좋은 것을 선택하여 쌍 비교 데이터(pairwise preference)를 제공하면, 이를 통해 모델이 무엇이 더 좋은 응답인지를 학습하는 보상 모델(Reward Model)을 구축한다. -
PPO (Proximal Policy Optimization)
이후 모델의 출력을 RM을 통해 평가하면서 강화학습을 진행한다. PPO는 강화학습에서 흔히 사용되는 기법으로, 모델의 정책이 너무 급격하게 변화하지 않도록 안정성을 확보하는 목적을 가진다. 이 과정을 통해 모델은 사람의 피드백을 반영한 보다 유용하고 안전한 응답을 생성할 수 있게 된다.
실제로 OpenAI는 RLHF를 통해 GPT-3를 ChatGPT로 발전시켰고, Google은 PaLM을, Meta는 LLaMA 시리즈를, Anthropic은 Constitutional AI를 적용한 Claude를 발표했다. 특히 RLHF 기반 모델은 사용자의 피드백을 받아 들이며, 이전보다 훨씬 정교한 대화와 문장 생성을 보여주었다.
CH8. 대규모 언어 모델의 잠재력을 끌어내는 RAG 활용 방법
이 장에서는 최근 LLM 응용에서 핵심 키워드가 된 RAG (Retrieval-Augmented Generation)의 개념과 활용법, 그리고 이를 실제로 구현하기 위한 기술 스택으로 LangChain을 소개한다. 또한, OpenAI API 기반 접근법과 로컬에서 LLaMA, GPT-J 같은 오픈소스 모델을 세팅하는 실전적인 예제도 포함되어 있다.
LangChain 파이프라인
RAG를 제대로 활용하기 위해서는 LLM 단독으로는 부족하고, 외부에서 정보를 검색하고, 이를 활용하여 답변을 생성하는 파이프라인이 필요하다. 이를 위해 LangChain 프레임워크가 소개된다.
LangChain은 다양한 LLM과 데이터 소스를 연결하고, 체계적으로 응답을 생성할 수 있게 도와주는 파이썬 기반 오픈소스 라이브러리이다.
- Component (컴포넌트): LangChain의 최소 단위로, 프롬프트 템플릿, LLM, 메모리, 툴 등 다양한 유형이 존재
- Chain (체인): 여러 컴포넌트를 순차적으로 연결하여 하나의 일관된 흐름을 만드는 구조
- Agent (에이전트): 체인과 달리, 스스로 의사결정을 하고, 필요한 툴을 골라 사용하며 상황에 맞게 동작을 수행
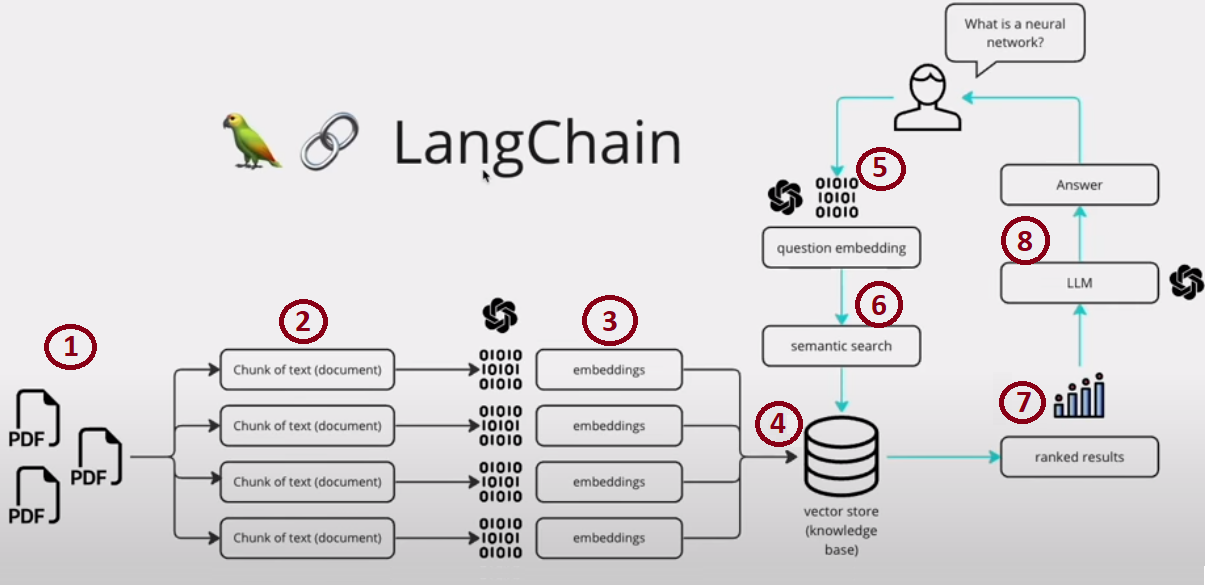
RAG 뿐만 아니라, LangChain에서는 메모리라는 개념도 중요한데, 이는 이전 대화나 정보를 저장하여 이후 대화에 활용하는 기능이다. 메모리를 활용하면 대화형 에이전트가 앞선 대화 내용을 기억하고 이를 기반으로 더 자연스럽고 일관성 있는 대화를 이어갈 수 있다. 특히 LLM이 가진 한계 중 하나인 컨텍스트 윈도우 문제를 보완할 수 있는 중요한 장치이다.
CH9. 대규모 언어 모델이 주도하는 고급 응용 프로그램 및 혁신의 최전선
이번 장에서는 대규모 언어 모델(LLM)을 활용한 고급 시스템 설계와 최근 주목받고 있는 다양한 응용 기술들을 실습 중심으로 소개한다. 특히 LangChain을 활용한 고급 RAG, 프롬프트 최적화, 다중 에이전트 구성까지 이어지는 내용이 흥미롭다.
Retriever, Memory, Chain, Agent를 단순히 나열하는 수준이 아니라, 여러 개의 컴포넌트를 유기적으로 연결하여 더욱 정교한 시스템을 구축한다.
예를 들어, 사용자의 질문이 들어왔을 때 적절한 Retriever를 조건부로 선택하거나, 검색된 여러 정보를 우선순위로 정렬한 후 LLM에 전달하는 등 보다 실용적인 로직을 실습 형태로 설명하고 있다.
프롬프트 압축 (LLM Lingua)
LLM을 사용할 때 가장 큰 문제 중 하나는 프롬프트 토큰의 한계와 비용이다. 특히 RAG 구조에서는 외부 검색 결과를 LLM 입력으로 넣을 때, 프롬프트가 지나치게 커질 수 있다.
이를 해결하기 위한 방법으로 LLMLingua가 소개된다. LLMLingua는 대규모 언어 모델이 처리할 프롬프트를 축약(compression)하는 도구로, 입력 문서에서 의미를 최대한 유지하면서도 토큰 수를 줄여준다.
책에서는 실제로 LLMLingua를 활용하여 동일한 정보를 담고 있지만 압축된 프롬프트를 LLM에 넣고, 성능 및 비용을 개선하는 방법을 코드로 보여준다.
AutoGen (Microsoft)
Microsoft가 개발한 AutoGen은 다중 에이전트 프레임워크의 대표적인 사례로, LangChain과는 다른 접근 방식을 제공한다.
AutoGen의 핵심은 에이전트가 사전에 정해진 프로세스를 따르는 것이 아니라, 대화를 통해 문제를 협의하고 해결할 수 있도록 설계된 점이다. 에이전트들은 스스로 토론하며 어떤 에이전트가 어떤 작업을 수행할지 결정하고, 순차적 또는 병렬적으로 문제를 해결한다.
책에서는 간단한 AutoGen 사용법과 함께, AutoGen이 어떻게 에이전트 간의 자연스러운 협업을 지원하는지를 설명하고, 이를 활용한 RAG + Multi-Agent 시스템의 예시도 소개한다.
CH10. 대규모 언어 모델과 인공지능이 주도하는 과거, 현재, 미래 트렌드 분석 & CH11. 세계적 전문가들이 바라본 산업의 현재와 미래
대규모 언어 모델의 발전을 논할 때 컴퓨팅 파워는 빠질 수 없는 이야기이다. 기존에는 무어의 법칙(2년마다 트랜지스터 수가 2배 증가)을 바탕으로 꾸준한 하드웨어 성능 향상을 기대했지만, 2020년대를 지나며 물리적 한계와 비용 문제로 의문이 제기되었다. 그럼에도 무어의 법칙은 여전히 산업계에서 중요한 기준점으로 작용하고 있다.
이와 동시에 Tensor Processing Unit(TPU), GPU의 발전, 그리고 딥러닝 특화 하드웨어의 등장으로 LLM 훈련과 추론 환경은 크게 개선되었다. 특히 TPU와 GPU 클러스터를 활용한 클라우드 컴퓨팅의 확산으로, 개인이나 중소기업도 대규모 언어 모델을 실험하고 서비스할 수 있는 환경이 마련되었다.
프롬프트 엔지니어링과 RAG의 재조명
프롬프트 엔지니어링은 LLM을 활용한 애플리케이션 개발의 첫 번째 단계로 자리 잡았다. 그 뒤를 이어 RAG (Retrieval-Augmented Generation)이 재조명되고 있는데, 이는 검색된 정보와 언어 모델을 결합하여 보다 정확하고 신뢰성 있는 결과를 제공하기 위함이다.
RAG의 성능은 단순히 모델의 크기나 파라미터 수에 의존하는 것이 아니라,
- 검색된 데이터의 구조 설계
- Vector DBMS의 선택
- 임베딩 품질
등에 의해 크게 좌우된다.
여기서 임베딩은 텍스트 데이터를 벡터로 변환하는 과정으로, 손실 압축 메커니즘이기 때문에 어느 정도 정보 손실이 발생한다. 따라서, 효율적인 임베딩 설계가 RAG의 성능을 좌우한다.
LLM을 활용한 응용은 다음과 같은 복잡도 단계를 가진다.
- 프롬프트 엔지니어링
- RAG
- 미세 조정(Fine-Tuning)
- 모델 재학습
- 사전학습(Pretraining)
각 단계로 갈수록 비용과 기술적 복잡성은 급격히 증가하지만, 그만큼 얻을 수 있는 커스터마이징의 폭도 커진다.
최근에는 이러한 워크플로우를 체계화한 LLMOps가 등장했다. LLMOps는 LLM의 개발, 배포, 모니터링, 버전 관리, 평가를 포함하는 LLM 기반 MLOps의 확장된 개념이다.
책의 마지막은 글로벌 기업의 AI 담당자들과의 인터뷰로 구성되어 있다. 그 중에서도 인상 깊었던 것은 이베이의 CAIO 니잔 메켈-보브로브 박사의 발언이었다.
니잔 박사는 앞으로의 트렌드로 대규모 기초 모델 (LFM, Large Foundation Model) 로의 전환을 강조했다. 이는 특정 용도에만 국한된 모델이 아니라, 다수의 태스크를 포괄할 수 있는 범용적인 모델의 필요성을 뜻한다. 실제로 OpenAI, Google, Meta 역시 모두 LFM 중심으로 연구를 이어가고 있으며, 다중 언어 지원, 복합적인 reasoning, 멀티모달 학습 등으로 확장되고 있다.
팔란티어 CTO는 K-LLMs 즉, 특정 도메인 또는 조직에 맞게 커스텀된 LLM들의 활용 가능성을 강조했다. 앞으로는 단일 대규모 모델보다는 다양한 크기의 특화된 LLM들을 유기적으로 조합하는 전략이 중요해질 것으로 보인다.

오 읽어봐야겠어요 좋은 정리 감사합니다.
학부 때 배운 수학 진짜 거의 다 잊어버렸지만 이런 책 읽을 때 확실히 도움은 되는 것 같아요.
먼가 아 맞아 이런 개념이었지 하고 콜드 스토리지에서 열심히 찾아 불러오는 느낌 ㅋㅋㅋ