
[ 글의 목적: python의 requests 대안 주자인 curl_cffi 의 전신과 히스토리, 사용법 기록 ]
curl_cffi
curl_cffi is a Python binding for curl-impersonate via cffi.
Unlike other pure Python http clients like httpx or requests, curl_cffi can impersonate browsers’ TLS signatures or JA3 fingerprints. If you are blocked by some website for no obvious reason, you can give this package a try.
curl_cffi는 curl-impersonate를 Python에서 사용할 수 있게 해주는 라이브러리입니다. httpx나 requests와 달리 브라우저의 TLS 서명이나 JA3 지문을 모방할 수 있으며, 명백한 이유 없이 일부 웹사이트에서 차단된 경우 이 패키지를 사용해 볼 수 있습니다.
1. curl-impersonate
1) curl 과 관계
-
그래서 이
curl-impersonate란 놈은 무엇인가? 일단 curl 를 알아야 한다. 리눅스 통신 체크 - 서버 네트워크 통신 체크 라는 글에서 가볍게 curl 을 다뤘는데, 한 줄로 "다양한 통신 프로토콜을 이용하여 데이터를 전송하기 위한 command line tool" 이다. -
그
curl을 기반으로 특정 브라우저 행동을 흉내내는! 형태로 통신하게 하는 command line tool 이다. 영어 one line 으로 다음과 같이 소개된다 "curl-impersonate: A special build of curl that can impersonate Chrome & Firefox" -
그리고 다시, 결론으로 잠깐 가면
curl_cffi는curl-impersonate를python runtime에서requests라이브러리 와 비슷한 형태로 사용하게 해주는 것이다!
2) 브라우저 흉내?
- 브라우저 흉내라는 것은 "브라우저의 TLS 서명이나 JA3 지문" 에 대해 알아야 할 필요가 있다. (TLS signatures or JA3 fingerprints) (역시 scraping & crawling 은 창과 방패와 같다. 마치 ML 에서 경찰과 도둑과 닮았다..)
TLS
-
TLS(전송 계층 보안)은SSL(보안 소켓 계층)의 업그레이드된 버전으로, SSL은 이제 TLS로 대체 되었다. -
SSL 의 시대가 변함에 따른 보안 취약점 (RC4, 해시 함수로 SHA-1 등) 으로 SSL 3.1 까지 발전하면서 (사실 SSL 3.1이 TLS 1.0) RSA 대신 Diffie-Hellman 또는 ECDHE (Elliptic Curve Diffie-Hellman Ephemeral) 등의 키 교환 방식을 사용 등의 진화가 이뤄 졌다.
-
더 자세하게는 글의 범위를 벗어나며, https 에 대한 내용은 잘 알수록 좋다! 특히! 얄팍한 코딩 사전의 HTTPS가 뭐고 왜 쓰나요? (Feat. 대칭키 vs. 비대칭키) 를 추천하며 TLS 핸드셰이크의 원리는 무엇일까요? | SSL 핸드셰이크 글을 추천한다.
-
TLS Signature 는 "TLS 핸드셰이크 과정에서 발생하는 고유한 데이터" 를 의미 한다.
JA3 Fingerprint
-
TLS 핸드셰이크 과정에서 클라이언트가 보내는
ClientHello메시지의 내용을 해시하여 고유한 식별자를 만드는 방식을 말한다. JA3 Fingerprint 는 특정 네트워크 클라이언트(브라우저, API 요청, 봇 등)를 구별하는 데 사용되며 서버 측에서는 클라이언트의ClientHello메시지를 해싱한 결과를 비교해 클라이언트를 식별할 수 있다. 더 상세한 내용은 해당 글을 추천한다. -
클라이언트 브라우저 정보를 포함하여 여러 정보를 결합하여 해싱한 값인 이 JA3 Fingerprint 값은 보안과 특히 "봇 탐지" 에 많이 사용된다. 웹 서버는 특정한 JA3 지문을 가진 요청을 차단할 수 있는데, 이 방법은 웹 스크래핑을 방지하기 위한 목적으로 많이 활용된다.
그래서 curl-impersonate 는
- TLS 서명이나 JA3 지문을 모방하여 서버가 실제 브라우저에서 발생한 요청으로 인식하게끔 만들어, 웹 스크래핑 시 발생할 수 있는 차단 문제를 우회할 수 있게 되는 것이다.
2. 다시 curl_cffi & 실습
1) Features
- 공식 Docs 의 피쳐와 비교 그래프를 보면 아래와 같다.
- JA3/TLS and http2 fingerprints 모방(사칭) 지원
- requests/httpx보다 훨씬 빠르며, aiohttp/pycurl과 동등한 수준
- requests API 들을 모방하여(형태를 따라하여) 새롭게 배울 수고가 덜함
- Pre-compiled 된 상태라 컴파일 필요 X
- 각 요청마다 프록시 먹은 상태의 asyncio 를 지원!
- websocket 과 http 2.0 지원!
| Feature | requests | aiohttp | httpx | pycurl | curl_cffi |
|---|---|---|---|---|---|
| http2 | ❌ | ❌ | ✅ | ✅ | ✅ |
| sync | ✅ | ❌ | ✅ | ✅ | ✅ |
| async | ❌ | ✅ | ✅ | ❌ | ✅ |
| websocket | ❌ | ✅ | ❌ | ❌ | ✅ |
| fingerprints | ❌ | ❌ | ❌ | ❌ | ✅ |
| speed | 🐢 | 🐇🐇 | 🐇 | 🐇🐇 | 🐇🐇 |
- 그리고 위 언급한 것에 이어서
curl_cffi는curl-impersonate를 "CFFI(C Foreign Function Interface for Python)" 를 통해 바인딩한 라이브러리다.
2) How 2 Use, simple
- (설치)
pip install curl_cffi, 굉장히 직관적이며, 확실히 기본 익숙한 라이브러리의 사용성과 매우 닮아 있다.
requests 의 대표 get method 와 아주 유사하게 사용할 수 있고, 프록시 세팅도 매우 유사하다.
from curl_cffi import requests
url = "https://tools.scrapfly.io/api/fp/ja3"
# Notice the impersonate parameter
r = requests.get(
"https://tools.scrapfly.io/api/fp/ja3",
impersonate="chrome110",
)
print(r.json())
# ========== proxy ========== #
proxies = {"https": "http://localhost:3128"}
r = requests.get(
"https://tools.scrapfly.io/api/fp/ja3",
impersonate="chrome110",
proxies=proxies,
)Session 객체를 만들어서 사용할 수 도 있다.
from curl_cffi import requests
s = requests.Session()
# httpbin is a http test website
s.get("https://httpbin.org/cookies/set/foo/bar")
print(s.cookies)
# <Cookies[<Cookie foo=bar for httpbin.org />]>
print(s.cookies.get_dict()) # 심지어 이것도 됨
# {'foo': 'bar'}
r = s.get("https://httpbin.org/cookies")
print(r.json())
# {'cookies': {'foo': 'bar'}}- 그 외 기본 사용법은 official docs 에서 확인 가능하다.
3) 그래서 뭐 얼마나 다른데!
JA3/TLS 우회
-
scraping 에 있어서, http 에 기본 인사이트가 있으신 분들은 모두 header & cookie 컨트롤을 잘 하시고, 그에 따라
UA(user-agent)값,referer값 등으로 대부분은 scraping 을 잘 하시리라 생각한다. -
식상하게 js excute 를 위한 셀레니움 방식이나 proxy 사용하세요! 보다 https://www.cloudflare.com/ko-kr/lp/ppc/overview-x/ 를
requests와 같은 방식으로 httpsget요청을 통해htmlfile 자체를 가져오는데 성공해보자! -
(참고로 header 값은 실제 브라우저를 통해 들어갔을때 패킷을 그대로 복&붙)
from requests import get
from bs4 import BeautifulSoup
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "ko,en;q=0.9,ko-KR;q=0.8,en-US;q=0.7",
"cache-control": "max-age=0",
"priority": "u=0, i",
"sec-ch-ua": '"Google Chrome";v="129", "Not=A?Brand";v="8", "Chromium";v="129"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"macOS"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
}
res = get(
"https://www.cloudflare.com/ko-kr/lp/ppc/overview-x/",
headers=headers,
)
html = BeautifulSoup(res.content, "lxml")
with open("cloudflare-requests.html", "w", encoding="utf-8") as file:
file.write(str(html))
print("HTML 파일이 저장되었습니다.")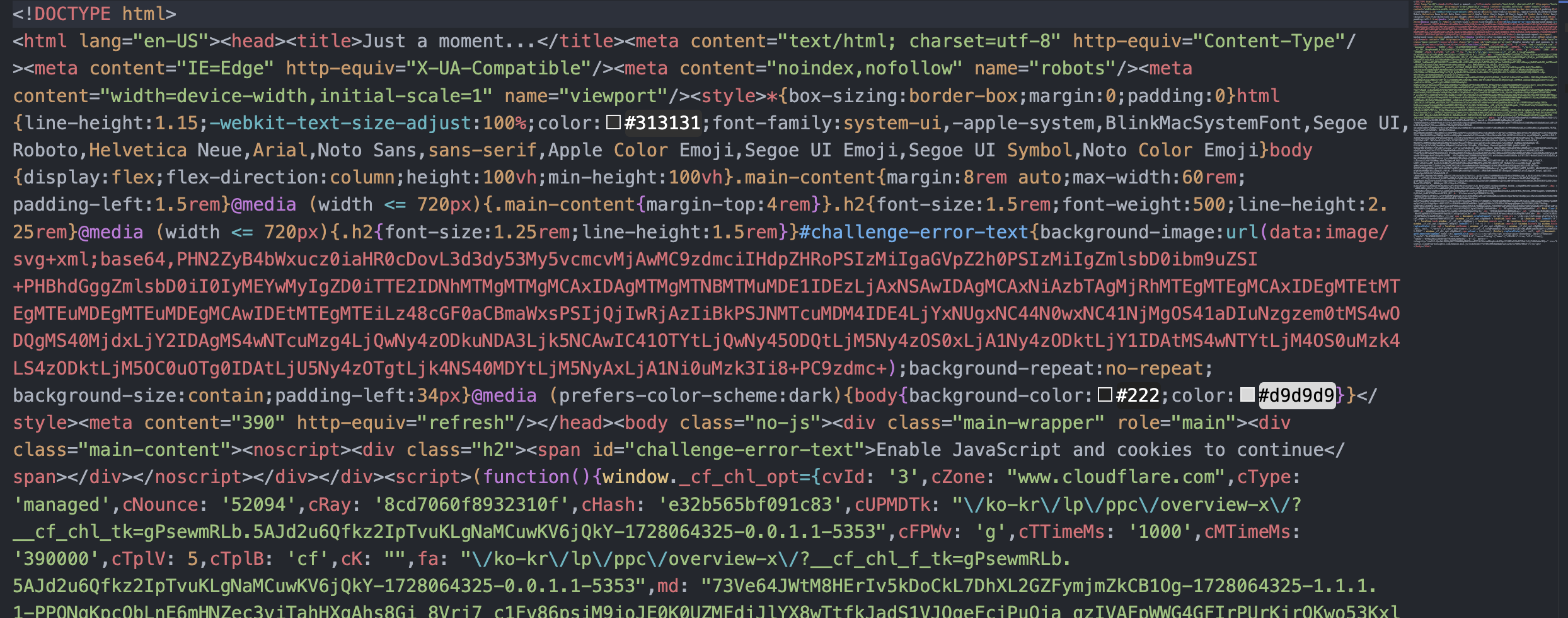
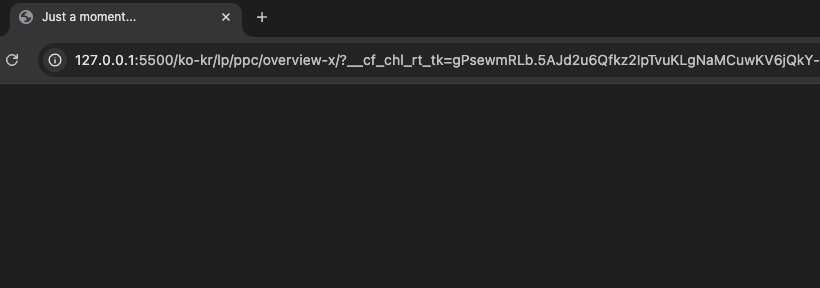
- 우측 상단만 봐도 뭔가 잘 못 됨이 감지된다..! 저장된
html을 실행해 보면 어디론가 나를 급히 데려간다...
- 근데 import 만
from curl_cffi import requests로 바꾸고,get대신requests.get를 사용하면?
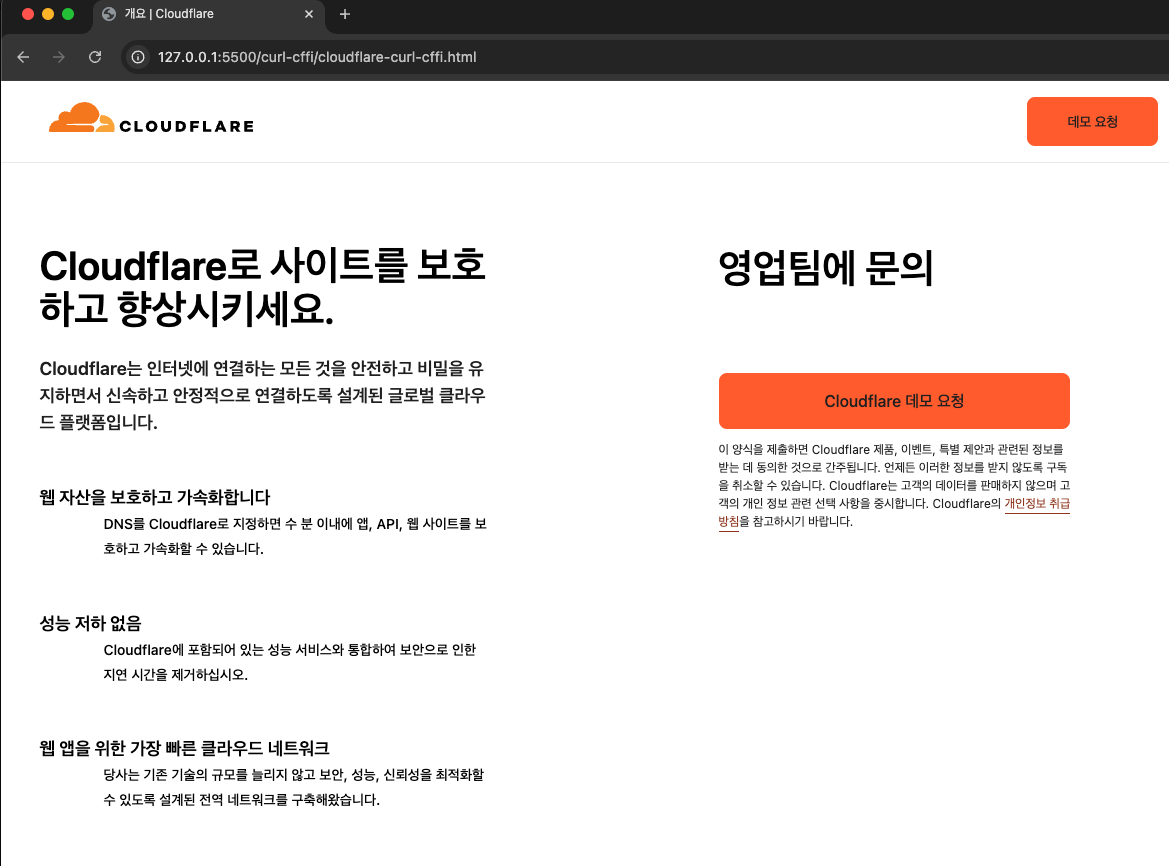
-
여기서
cloudflare와 같은 - https://developers.cloudflare.com/bots/concepts/ja3-ja4-fingerprint/ 친구들에게는 이게 꽤나 지옥일 수 있다. (ps. 근데 이게 절대 모든cloudflare를 우회한다는 뜻이 아닙니다!) -
그리고 requests 를 쓰면서
verify=False이런 값 추가 한 적 다들 있을텐데,, 사실curl_cffi로 브라우저 자체가 하는 JA3 Fingerprint 를 따라하면 거의 대부분의 case 에서 해결 가능해진다.
http version 2 지원 & requests 를 쓰는 것만 같은 비동기
-
이게 불과 몇년 전 만 해도 오지 않을 것 같던 미래지만, 진짜 이제 http2 는 많이 대중화 되고 있다. https://imagekit.io/blog/http2-vs-http1-performance/ (굳이 http1.1 과 http2 를 다루지는 않겠다.)
-
레거시의 단일 외부 http api 호출, 과거의 scraper 들을 보며 이제는 http2 로 async 하게 세팅하는 것을 추천한다.
생각보다 엄청난 광명의 영역
import asyncio
from curl_cffi.requests import AsyncSession
urls = [
"https://google.com/",
"https://facebook.com/",
"https://twitter.com/",
]
async def fetch(url):
async with AsyncSession() as session:
response = await session.get(url)
print(f"{url}: {response.status_code}")
async def main():
tasks = [fetch(url) for url in urls]
await asyncio.gather(*tasks)
asyncio.run(main())- 그리고 (개인적으로) 아주 깔쌈한 비동기 세팅이 가능하다!
꽤 핫하다
-
curl_cffi 깃허브는 꽤 뜨겁다. 지속적으로 업데이트 되는 중이고,
issues역시 실시간으로 처리되는 것도 볼 수 있다. -
stack overlfow 에서도 해당 라이브러리 관련 QnA 가 계속 올라오고 있다!
4) 마무리
-
사실
requests는 충분히 성숙하고, 안정성이 익히 알려져 있고, 적당한 목적 달성을 위해서 여전히 최고의 빠른 선택이다. -
하지만 너무 오래된 라이브러리다. 지속적으로 관리가 되고 있지만, http2 는 지원하지 않는다. (아마 앞으로도, 설계 철학과 단순성, 그리고 http1.1 기준으로 설계 되었기 때문)
-
그래서
requestsvscurl_cffi는 적절하지 못한 비교 대상이고, 차라리httpx와 같은 라이브러리와 비교해야 마땅하다. -
C로 작성된
libcurl를python runtime에서 컴파일된 바이너리 형태로 바로 사용되는 것도 큰 이점을 가진다고 본다. 당장 레거시를 엎는게 아니라, 꼭 한번은 사용해볼 만 한 것 같다!
출처


👍🏻👍🏻