[ 해당 글은 "velog-dashboard" 프로젝트를 만들면서 기록한 DevLog 입니다! ]
[서비스 일시 중단 🙆🙇🙆🙇] 12월 중으로 레거시 통계 보기가 안정화 된 상태로 다시 제공" 된다고 하니, 그때 다시 살려보도록 하겠습니다! [🙆🙇🙆🙇]
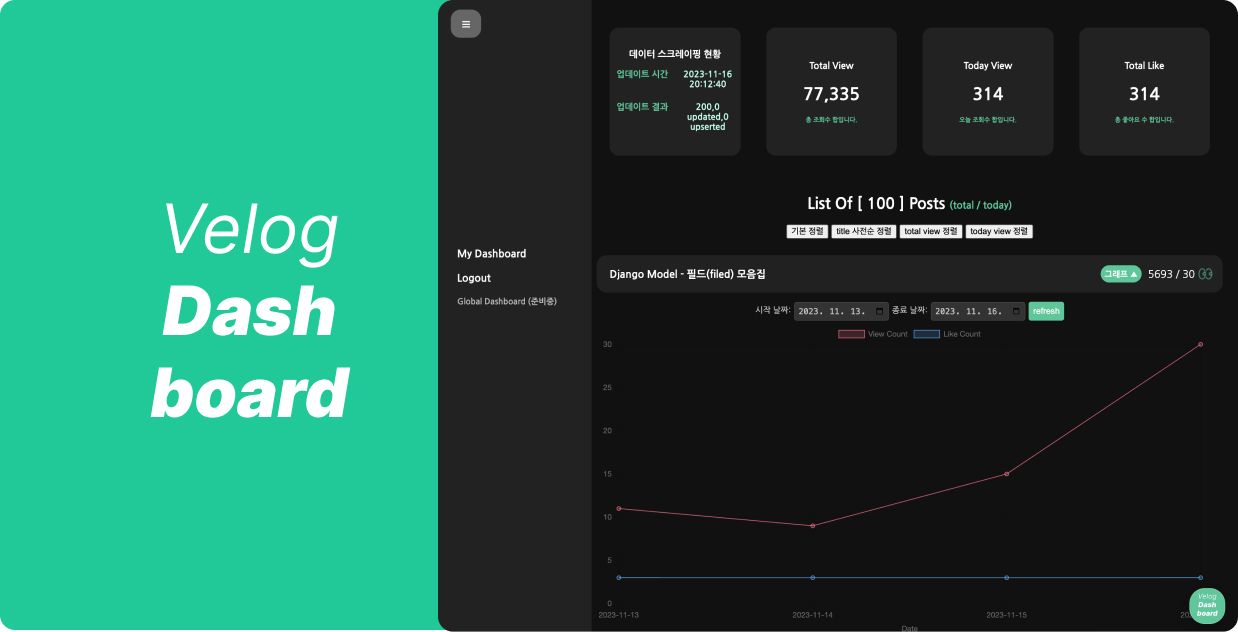
Velog Dashboard
https://velog-dashboard.kro.kr 에
🔥 로그인 없이 둘러보기 🔥가 추가되었습니다!
backend 개발이 가장 익숙해서 자연스럽게 모델링부터 바로 고민하게 된다. 빠른 개발을 위해 NoSQL, mongodb 를 선택하게 되었고, "join없는 최소한의 조회로 가능한 많은 일" 을 하게 하고 싶다. 앞에서 언급한 1) 모델 중심 기능 설계 section에서의 내용을 그대로 model로 풀어내면 될 것 같았다.
1. Backend
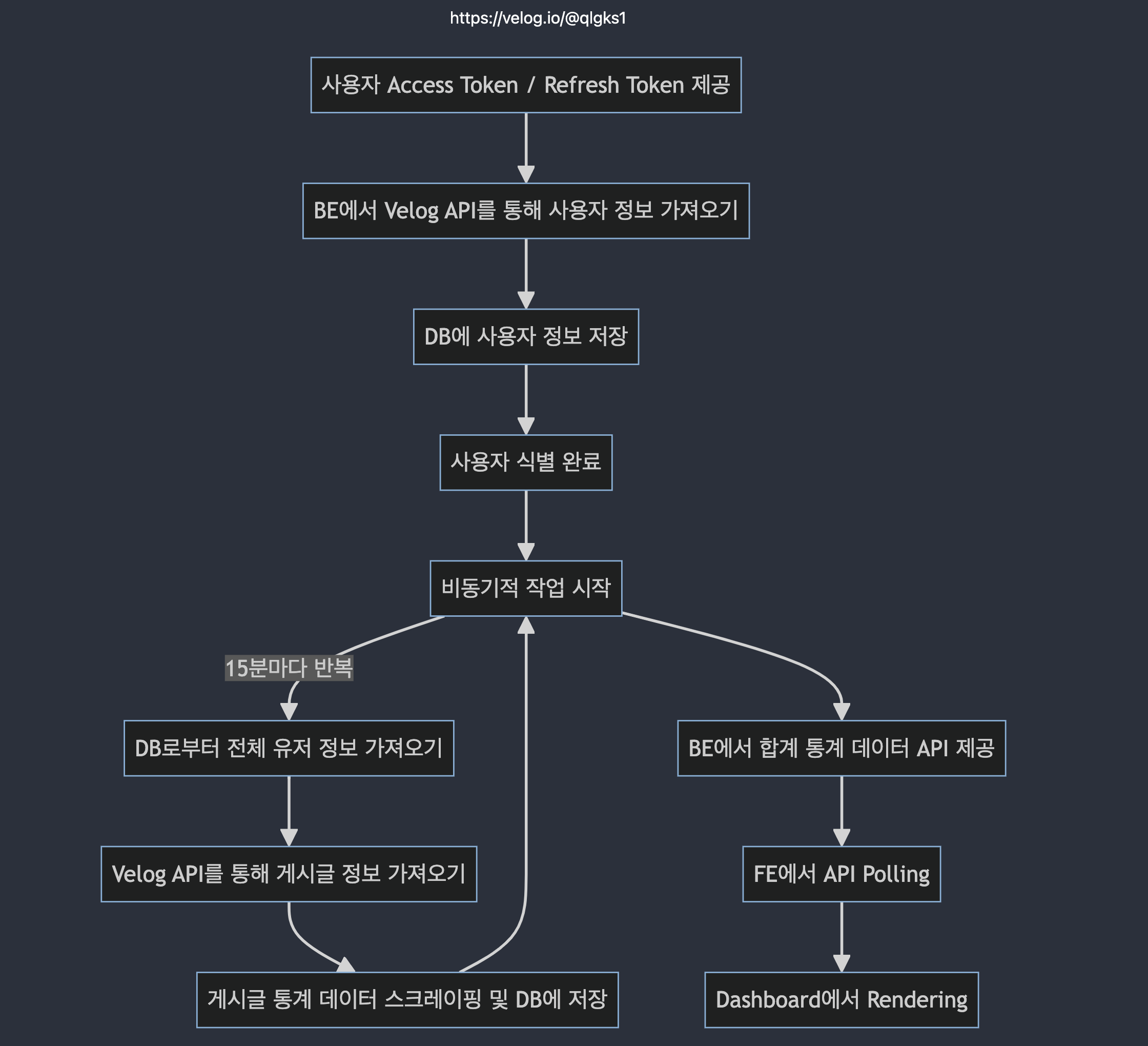
일단 설계 및 구현 방향은 핵심 기능 flow를 BE -> Worker -> FE 까지 한 단계 만들어 놓고 부족한 부분을 계속 쌓아 올리는 형태로 기능 개발을 했다. 아래가 생각한 간략한 flow chart 이다.
-
mermaid live 라는 웹을 통해서
mermaid문법으로 쉽고 빠르게 그릴 수 있다. 더욱 꿀팁은 1, 2, 3... 순서로 chatGPT 한태 넘기면서 mermaid로 만들어 달라고 하면 된다. -
얘를 역할군을 구분해서 표현하면 아래와 같았다.

- 딱히 비즈니스 로직에 우려가 갈만한 예외 상황이 없다고 판단되어서 "우선 happy case 만 생각하고" 바로 작업에 들어갔다!!
1) model schema
처음 고려한 스키마 형태는 아래와 같았다. (1) token 짝 collection, (2) 해당 짝의 post를 bulk로 stats와 같이, (3) 그리고 워커를 위한 스크레이핑 job & status
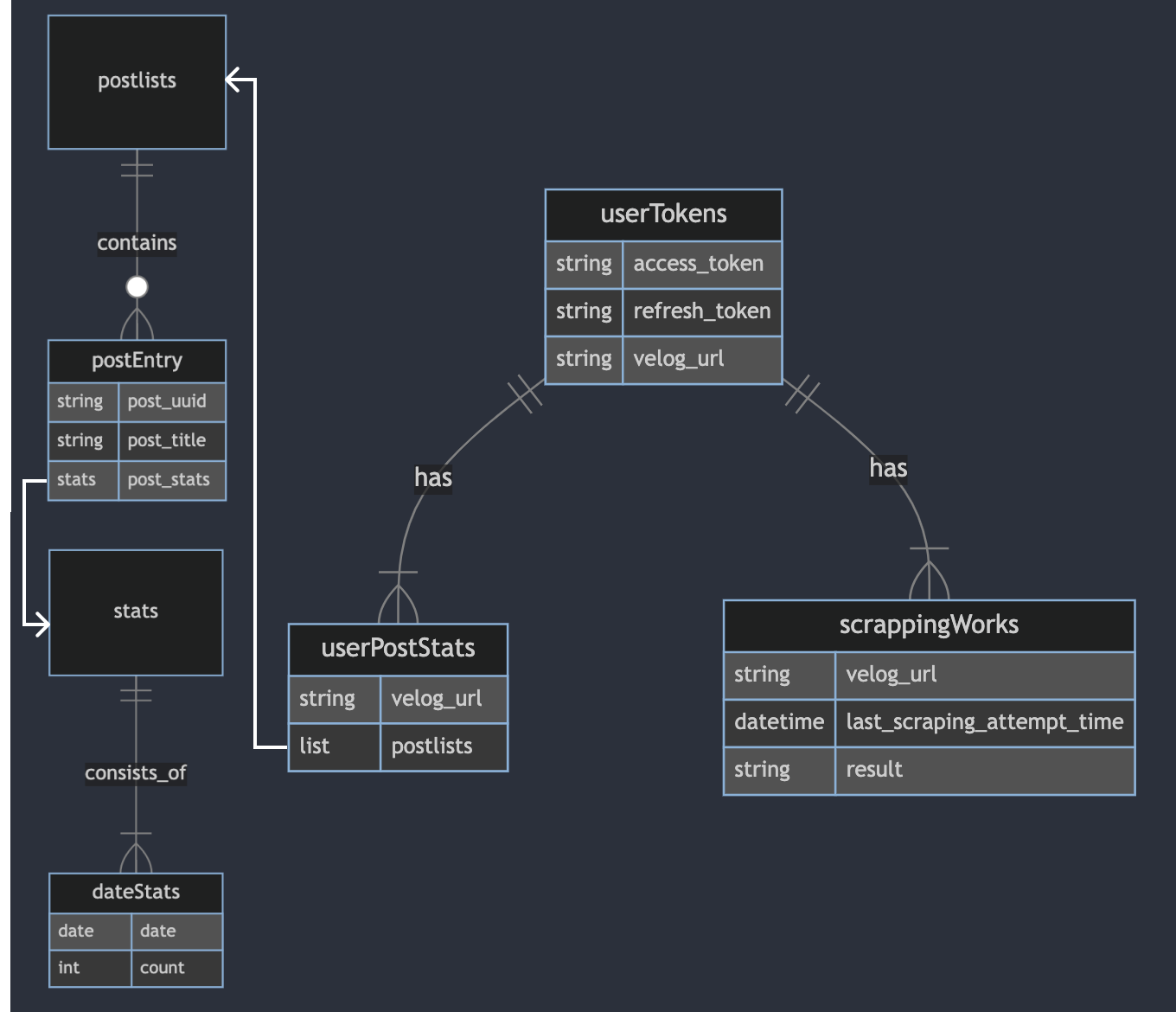
예시 데이터셋은 러프하게 아래와 같았을 것이다.
1. userTokens
- access_token (string)
- refresh_token (string)
- velog_url (string)
2. userPostStats
- velog_url (string)
- postlists ( list[dict] )
- [ {post_uuid: "string", post_title: "string", post_stats: [ {"2023-01-01": 3, "2023-01-02": 5, ... } ] }, {post_uuid: "string", post_title: "string", post_stats: [ {"2023-01-01": 3, "2023-01-02": 5, ... } ] }, {post_uuid: "string", post_title: "string", post_stats: [ {"2023-01-01": 3, "2023-01-02": 5, ... } ] } ... ]
3. scrappingWorks
- velog_url (string)
- Last Scraping Attempt Time
- result물론 이렇게 해서 구현해도 상관없지만, userPostStats collection의 하나의 docs가 쓸데없이 무거웠다. 굳이? 시작부터 너무 자체 역정규화 한거 아닌가 🥹 그리고 너무 velog graphQL 스키마를 그대로 따라간 것 같았다.
관계가 없는 nosql 특성상 한 번에 적절하게 다 들고오면 이득이다. 당연히 (B-tree index 가 잘먹힌) 관계형보다는 대량 select는 느리다. 그래서 "관계가 없는 만큼 join 필요없게 잘 구조화 할" 필요가 있다. 그래서 아래와 같이 바꿨다.
모델 리펙토링
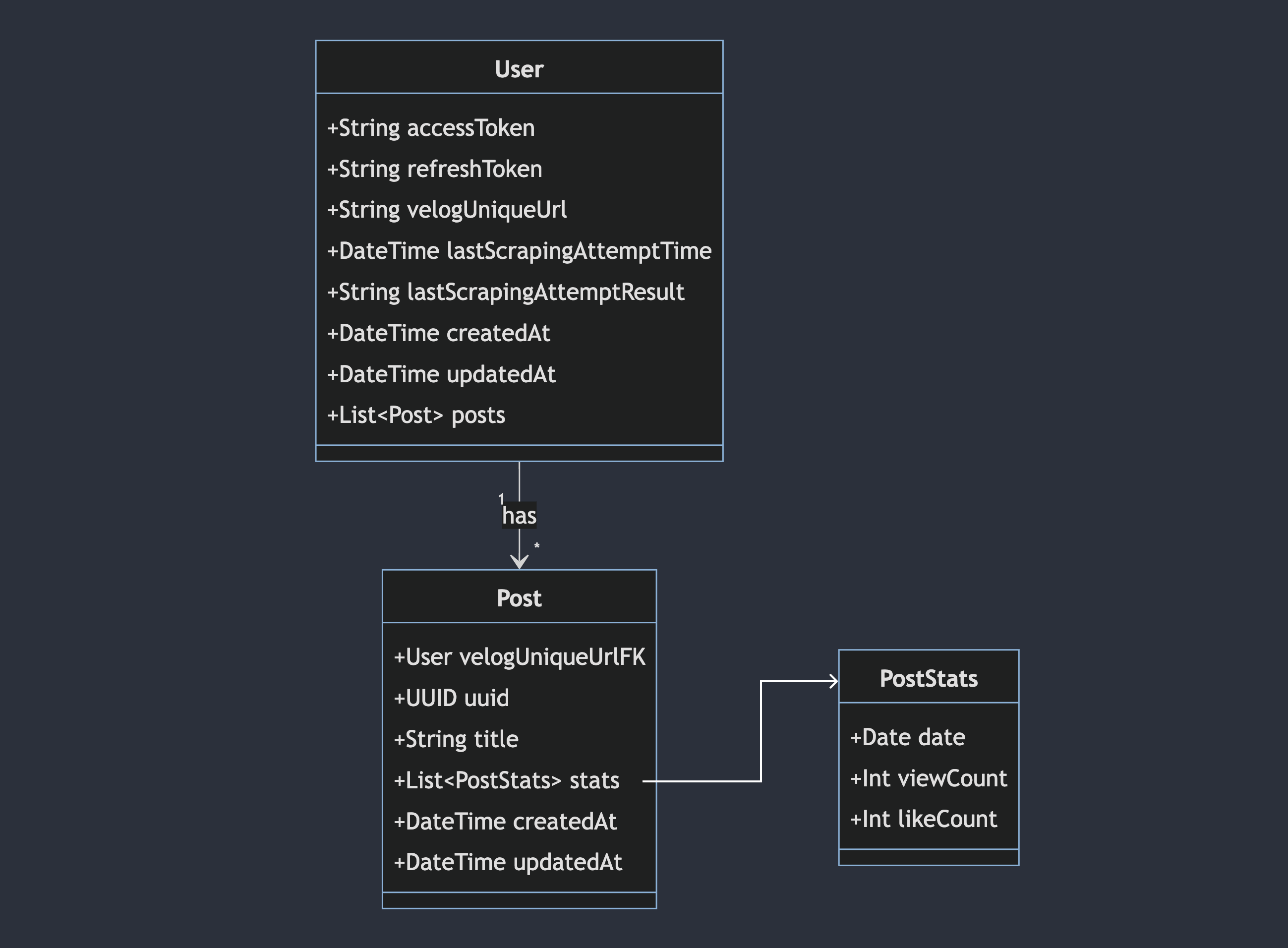
이 2개의 collection으로 모두 해결할 수 있을 것 같다. 일단 이렇게 MVP를 만들고 post 와 postStats 를 분리하던, 아니면 차라리 SQL로 갈아타던 해야겠다.
나중을 생각해 user를 group으로 나누어 worker를 여러개(다중 프로세스) 만들때 구독하는 queue를 분리하듯이 세팅하려고 했으나 나중에 도입해도 충분할 것 같아서 참았다. 너무 먼 미래를 미리 준비하지 말자!! 어짜피 나만 쓸지도 모른다..! 🥹
2) model static method
node 환경의 express + mongoose 조합을 엔터프라이즈에서는 사용해본 경험이 없다. django ORM의 "fat model" 형태에 익숙하기도 하고, ORM에 더 익숙하기도 해서 schema에 "model관련 method를 미리 만들어두고" 사용하기로 했다.
일단 요구 사항을 다시 체크하면서 핵심 필요 method는 아래와 같았다.
- userInfoSchema -
fetchUserInfo: velog api통해 token으로 userinfo 얻기 - userInfoSchema -
createUser: create new user info - userInfoSchema -
findByToken / findByuserId / updateTokenByuserId - userInfoSchema -
find all user's posts- 얘는 생각해보니REF를 걸면populate를 통해 join 처럼 사용할 수 있다! - PostStatsSchema -
aggTotalByUserId: get user's total & daily post view (aggregation) - PostStatsSchema -
allPostsAggByUserId: find all user's posts with detail - PostStatsSchema -
aggDailyTotalByUserId: get user's daily total view
이 정도면 일단 MVP를 위한 구현사항은 모두 가능할 것 같고, FE에서 피똥싸면 될 것 같다. 일단 api의 구현 형태는 http request --> api endpoint [router] --> middleware [auth / validation] --> service logic & model method --> response 가 될 것 같다.
3) 전체 디렉토리 구조
.
├── app.js
├── logger.js
├── logs
├── package.json
├── server.js
├── src
│ ├── middlewares
│ │ ├─ 인증...
│ │ └─ 벨리데이션...
│ ├── models
│ │ └─ 언급한 스키마...
│ ├── routes
│ │ └─ 모델 중심, controller 에 가까움...
│ └── services
│ │ └─ 실제 비즈니스 로직...app.js 에서 아래와 같이 라우터를 import 해서 바인딩하고
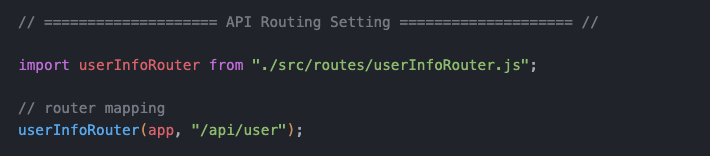
라우터.js 는 아래와 같이 controller 역할을 한다. end point 정의와 벨리데이션, 그 외 미들웨어, 비즈니스로직을 매핑한다.

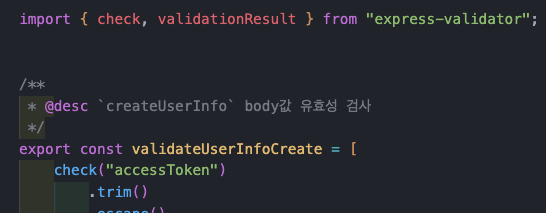
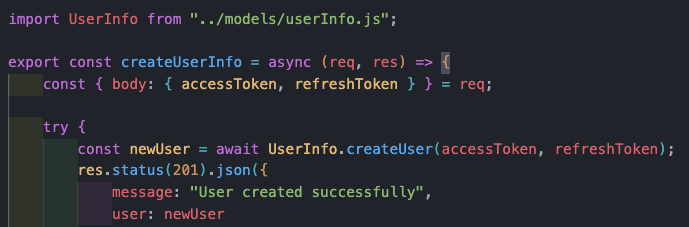
비즈니스로직.js 는 아래와 같이 ODM + 모델에 정의된 method 호출을 한다. 모델에 정의된 method는 2번째 그림과 같은 형태다!

깃허브 레포에는 완성본이 있기에,, 더 편하게 볼 수 있을 겁니다!! -> https://github.com/Check-Data-Out/velog-dashboard
4) 문제 (1) token 만료 이슈
이건 worker에서도 동일하게 issue인데 아차 jwt은 refresh 되어야 하지?! 이다. ㅋㅋㅋ나는 바보야ㅋㅋㅋ망했당ㅎㅎ

일단 로그인 or 회원가입 로직을 아래처럼 개편해야 했다.
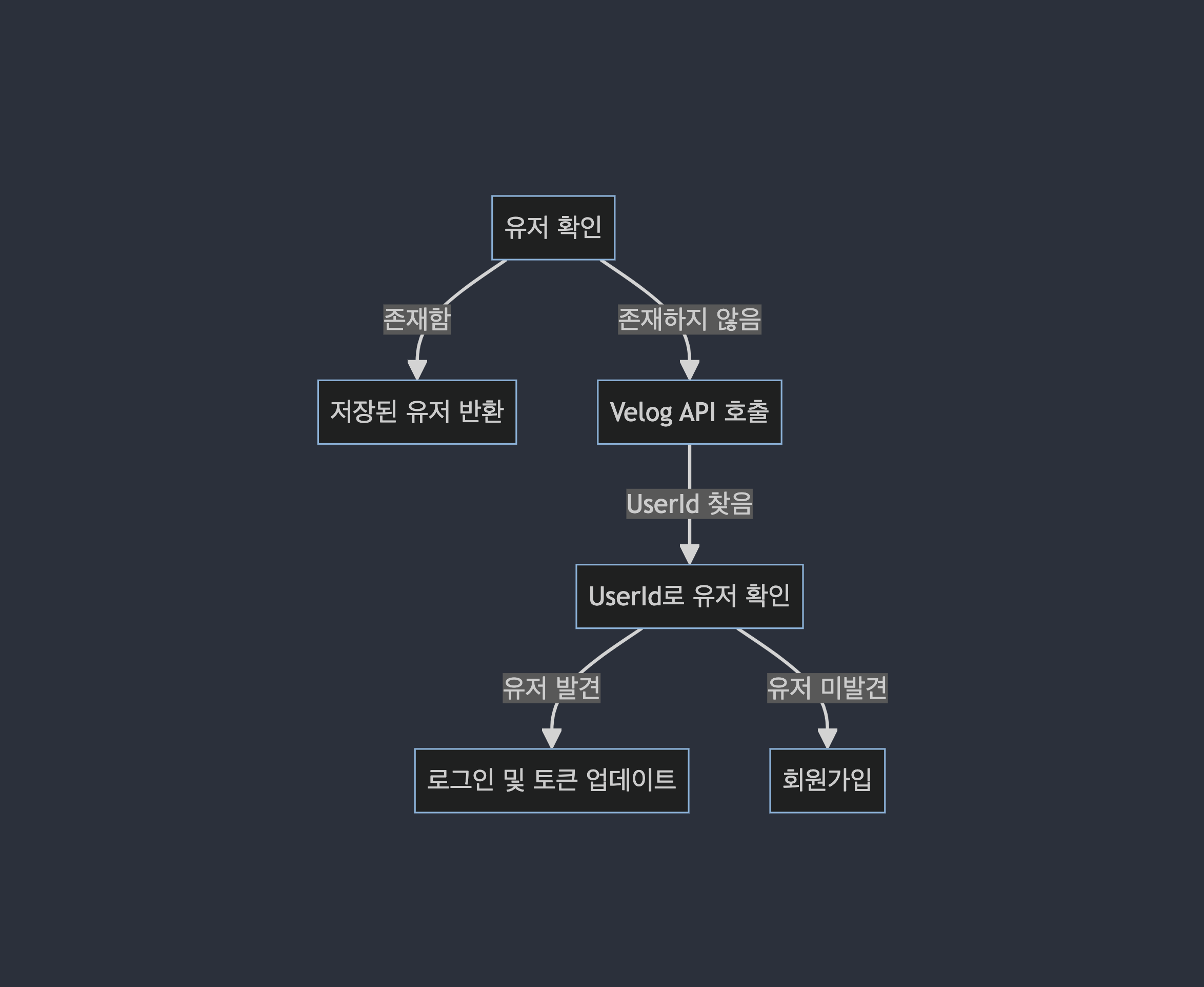
뿐만 아니다,, dashboard에서 polling하는데, worker가 update해주는 data는 token issue로 무한 팬딩이 될 수 있다. 이는 worker에서 다시..
5) 문제 (2) mongodb의 timezone
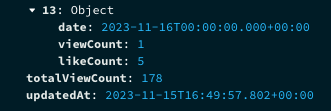
뭐? 방금 스크레이핑한 11월 16일 통계가 업데이트 되었는데,
updateAt은 왜저뤱?
일단 결론부터 보자면 updateAt 은 정상이다. 예상치 못한 대환장파티였다.. mongodb 는 기본적으로 date를 UTC에 맞춰서 저장한다. 즉 내가 한국시간대로 만든 date object를 저장할때 자동으로 UTC casting이 들어간다는 점이다.
이게 node - mongoose 라이브러리 사용해서 저장할때는 자동 casting에 문제가 없었지만, worker에서 motor 로 string으로 된, velog stats 그대로 가져와서 date를 그대로 저장하다보니 자연스럽게 UTC 인 것 처럼 저장되고, 저장된 값을 mongoose 에서 query할때는 시간대가 꼬이는 것... 이다!!
// 오늘 날짜 설정
// UTC 기준으로 오늘 날짜 설정
const KST_OFFSET = 9 * 60 * 60 * 1000; // 한국 시간대는 UTC+9
const now = new Date();
let today = new Date(now.getTime() + KST_OFFSET); // UTC 시간에 한국 시간대를 적용
// 다시 문자열로 년월일 문자열로 바꾸고, 다시 문자열을 date object로 바꾸고
// 시 분 초 0으로, UTC 시간대로 만들기
const dateString = today.toISOString().split("T")[0];
today = new Date(dateString);
console.log(today);눈물의 casting 쑈를 했다. 아니 js timezone을 직접 세팅할일이 없다보니 몰랐는데, python보다 시간대 세팅이 더 헬이다 무쳤다!!
now에 offset값 더하고, slice하고, 다시 만드니까 UTC인 것 처럼 솎더라.. 이 Date object로 query를 해서 해결했다.. 근데 새로운 issue, velog에서도 자정 넘어서 바로 업데이트가 되는 것이 아니라는 점이다..! 자정 넘어서 추가되는게 아니라, 그 날의 최초 조회수가 있어야만 만들어 진다는 점!
2. Worker
worker는 python asyncio & aiohttp 조합으로 비동기 및 코루틴으로 velog graphQL을 통해 user의 token을 빌려 post의 stats를 계속 갱신해야 한다. 그리고 1) model schema 에서 언급한 poststats collection을 계속 Update 해야한다.
1) 프로젝트 세팅 & 초기 설계
-
일단 최근에
poetry에 맛들려서poetry로 세팅했고, 버전은python 3.10+에 맞추려고 한다. 그리고black&flake8과 같은 린팅은 미리 세팅해서 가져가려고 했다! -
단일 프로세스 하나로 멀프 대신 (무료 cloud는 후져서,, CPU 점유를 낮추고) 코루틴을 적극적으로 활용하려고 한다. 그래서 단일 진입점에 비동기 task를 열심히 구성해서
while True형태로 가져가야 한다. -
함수형(함수형이라 하기엔 부끄럽고, 함수 위주로 구현된)으로 일단 러프하게 작성하고 리펙토링하는게 MVP 구현의 목적이다! 프로젝트의 전체 패키징은 아래와 같다.
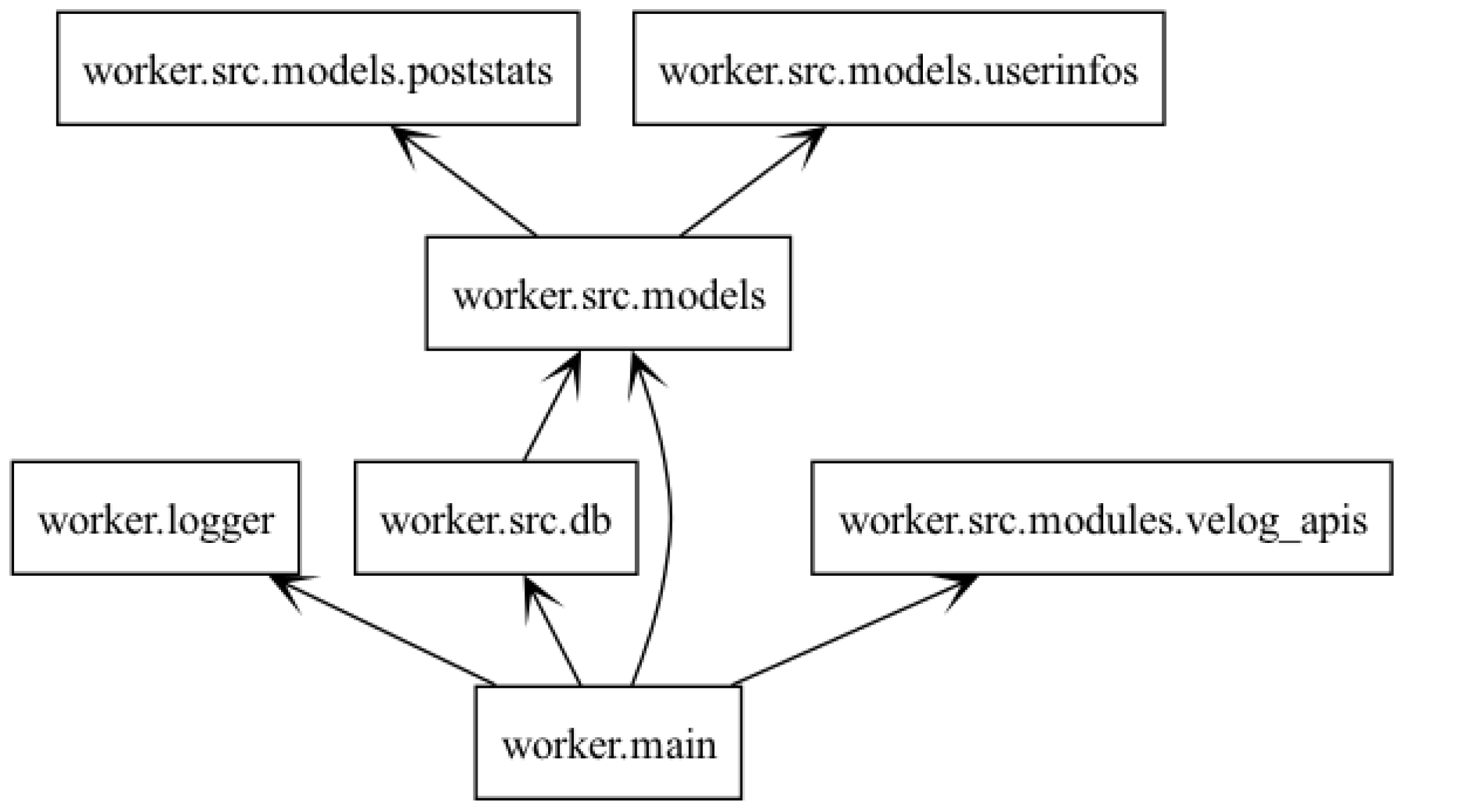
db: db는Repositoryclass로 싱글톤 형태로 사용하기로 했다.logger: code level로 세팅한 로깅 모듈이다. python logging 해부!velog_apis: https://github.com/inyutin/aiohttp_retry 를 통해 retry 정책이 가미된aiohttp기반으로 실제 velog api를 호출하는 함수들이다.models:pydantic으로 mongodb에 정의된 datamodel & 스크래이핑한 datamodel 을 정의했다.- 이제 main에서 전체 데이터 스크레이핑을 아래와 같은 root code로 러닝한다.
async def run_periodically():
while True:
await main() # 메인 함수를 실행
await asyncio.sleep(600) # 10분(600초) 동안 대기
# 이벤트 루프를 사용하여 run_periodically 함수 실행
asyncio.run(run_periodically())- 참고로 github action으로 러닝할때는
asyncio.run(main())만 호출한다!
2) worker job (task) 비즈니스 로직
userinfoscollection 에서 스크레이핑 주기 (업데이트 주기) 가 도달한 docs를 모두find all해서 가져온다.- 가져온 docs 기반으로 먼저 velog graphQL
get all posts (Posts)를 때려서 post list를 다 가져온다. - 다 가져온 post list 별로 velog graphQL
get a post's stats (GetStats)를 때려서 해당하는 post의 통계 시계열 데이터를 가져온다. poststatscollection 에서 해당하는 post의 uuid로 찾아statsfield를 업데이트 시켜준다.userinfos의lastScrapingAttemptTime과lastScrapingAttemptResult를 업데이트 친다.

러프하게 위와 같다. 물론 디테일한 사항이 있다. (예를 들어 업데이트 주기는 얼마인가? 실패 결과는? 리트라이 정책은? 등) 해당 사항은 "코드의 구현 레벨" 에서 계속 살펴봐야할 것 같다.
3) 전체 디렉토리 구조
.
├── logger.py
├── logs
│ └── velog-dashboard-worker.log
├── main.py
├── poetry.lock
├── pyproject.toml
└── src
├── __init__.py
├── db.py
├── models
│ ├── __init__.py
│ ├── poststats.py
│ └── userinfos.py
└── modules
├── __init__.py
└── velog_apis.py1) 프로젝트 세팅 & 초기 설계 에서 세팅한것과 크게 차이 없이 프로젝트 디렉토리를 구성했다. 깃허브 레포에는 완성본이 있기에,, 더 편하게 볼 수 있을 겁니다!! -> https://github.com/Check-Data-Out/velog-dashboard
4) 문제 (1) 스크레이핑 해온 데이터가 다를때 만 업데이트
"스크레이핑 해온 데이터가 다를때 만 업데이트" 해야 한다. 통계 API가 생각보다 실패율이 굉장히 높다. 특히 오래된 post의 전체 통계를 가져올때 말이다.
그도 그럴것이 velog에서 pagination없이 전체 stats를 response로 주고 있기 대문이다. 그러다 보니 과정에서 velog쪽 issue도 발견했다..!
select count(id) as count, date_trunc('day'::text, timezone('KST'::text, created_at)) as day from (\n select * from post_reads \n where fk_post_id = $1\n ) as t\n group by day\n order by day desc",
'parameters': ['150791f6-009c-408f-b739-4c3bda2e22ba'],
'driverError': {'length': 104, 'name': 'error', 'severity': 'ERROR', 'code': '57014', 'file': 'postgres.c', 'line': '3124', 'routine': 'ProcessInterrupts'},
'length': 104, 'severity': 'ERROR', 'code': '57014', 'file': 'postgres.c', 'line': '3124', 'routine': 'ProcessInterrupts'psql의 57014 error는 주로 "쿼리 취소 또는 타임아웃을" 말한다. 역시 너무 많은 데이터를 한 번에 요청을 했기 때문에 타임아웃 한계를 초과하거나, 인터럽트에 의해 서버 프로세스가 종료될 때 발생 했다. 사실 velog issue 라기 보다는 한번에 허용된 트랜잭션의 양을 넘은 것 같다.
그래서 스크레이핑을 성공한 result만 업데이트해야 한다! 이 실패케이스를 다루는게 굉장히 난해했다. 이유는 내가 python의 비동기에 능숙하지 않기도 하고, 비동기의 결과값을 모아 DBMS 부하 저하를 위해 bulk 로 묶어서 하는 과정에서 해당 조건을 처리 하는게 바로 떠오르지 않았다.
결국 전체 묶어서 bulk는 버리고, (1) find_one 하나씩 일단 다 때리고, (2) 가져온 데이터와 저장된 데이터가 다른 것만, (3) 그리고 가져오기를 실패하지 않은 것만 Update query 만들어서 bulk 때는 방향으로 바꿧다.
5) 문제 (2) 대망의 token update
일단 velog를 까봐(?)야 제대로 알 수 있을 것 같다. https://github.com/velopert/velog-server/blob/master/src/lib/token.ts#L131 코드를 보면 life < 30mins 일때 refresh 함수 호출하고 -> refreshUserToken -> setTokenCookie 흐름으로 흘러 간다. 기본적으로 미들웨어에서 만료 30분 미만일때 바로 refresh 해준다는 것이다.
token의 지속적인 refreshing을 위해 API 리스트를 아는 것이 좋다. https://github.com/velopert/velog-server/blob/master/src/graphql 에서 러프하게 살펴볼 수 있다.
일단 가장 확실한 API는 아이러니하게 "통계API" 이다. 중요한건 이제 전략이다. 데이터 스크레이핑은 무조건 따른 프로세스로 (worker) 러닝하니, token_refersh 전용 batch가 있어야 할 것 같다.
main worker 와 별개로 동작하는 token_refersh worker 가 필요하다. token_refersh worker 는 (1) user 를 모두 불러와서 단일 게시글의 통계 API request 를 통해 받는 response의 cookie를 추출해서, (2)DB에 저장된 token을 update 해야 한다.
여기서 또 한 번 발목이 잡히는 부분은 이제 기 유저가 velog-dashboard 에 user login 할 때 넣어야할 token이 이미 DB에서는 refresh 되었을 때라면..? 의 경우가 문제다..!
6) 문제 (3) Token을 refresh하니 user가 로그인을 할 때 4XX or 5XX 가능성이 있다!
jwt 는 3가지 색션으로 이뤄져 있다. 같은 유저라면, velog 자체가 jwt 관련 통 update를 갑자기 하지 않는 이상은, header 와 payload 값이 같을 것 이다.

이를 login에 녹였다. token으로 login할때 "러프하게 login이 가능하게끔" 만들어 두었다.

이에 따르는 또 다른 이슈는 다시 다뤄보려고 한다 :')
3. 회고
-
js,python왓다 갔다 하면서mongoose schema&python pydantic모델까지 중복해서 사용하다보니까 syntax 도 혼동이 가끔 오고, 3개 밖에 안되는 데이터 모델들 사용하는게 너무 번거로웠다. worker stack을 차라리 node 환경으로 돌아가게 js 기반으로 만들껄... 아니면 node 대신 fastAPI 쓸껄... "결국 애매한 데이터 시리얼라이징이 되어 버린 느낌(이럴꺼면 시리얼라이징 왜함?!)" -
확실히 logging 처리나 error handling에 있어서
python숙련도가node에 비해서 높은게 느껴졌다. 다행히? 구현 난이도나 중요도가 api 보다 worker가 훨씬 높았다. 그러다보니 진짜 worker code가 너무 날먹이 되었다...리펙토링 열심히 해야겠다..

- 세부 데이터 분석 및 접근을 위해서는
최초 데이터 insert 할 때와기존 데이터 update 할 때가 생각보다 로직 처리가 너무 달라야 했다. 특히 "like" history 추적을 위해서 말이다. velog api는 언제 like가 올라갔는지는 주지 않기 때문에..


1편부터 재밌게 보고 있습니다 다음 시리즈도 기대됩니다!