Velog Dashboard v2
Velog Dashboard, 신규 feature update 공유!
빨리 접속하기: https://velog-dashboard.kro.kr/
Github repo: https://github.com/check-Data-Out/velog-dashboard-v2
Velog 통계를 한눈에 확인할 수 있는 서비스를 100% 무료로 제공하고 있습니다! Velog 생태계가 살아 있는 한 저희도 함께 성장하며, 오히려 선순환 구조에 기여할 수 있기를 바라고 있습니다. (요즘 광고글 트랜딩에 너무 많아요~~ AI 필터링 도입해주세요~~~ 쩨발,, 과해 ㅠㅠ)
-
저희 팀은 주 1회 이상 정기 회의를 진행하며, 그 과정에서 작지만 잦은 업데이트들이 꾸준히 이루어지고 있습니다!! 현재 코드 커버리지는 90% 이상을 달성했고, 프론트엔드에서는 E2E 테스트까지 도입했습니다!
-
또한 지금까지 총 9대의 서버를 무료로 확보하여 운영해 왔는데, 이를 안정적으로 유지하기 위해 많은 노력을 기울였습니다. 무료 서버를 여기저기 모아 쓰는 게 결코 쉽지 않다는 걸 몸소 체감하고 있습니다. 아래 소개할 인프라 개괄도를 보시면 그 과정이 더 재미있게 다가올지도 모르겠습니다.
-
이번 글은 서비스의 생존 소식을 전하고, 동시에 그간의 업데이트 현황을 공유드려보고자 합니다~~ 🎉🫡
업데이트 요약본
① LLM 기반 주간 메일링 분석(트렌드·작성 글 분석) - 매주 월요일 오전에 발송!
② 리더보드 고도화(기간별 조회/좋아요 증감, 사용자·게시글 단일 클릭 이동)
③ Velog API 의존 최소화(내부 탐색·네비게이션 시 자체 저장 정보 활용)
④ 30분 캐시 레이어 도입으로 응답 체감 속도 개선
⑤ 샤딩·풀링 아키텍처 재정비
⑥ DevOps 도입
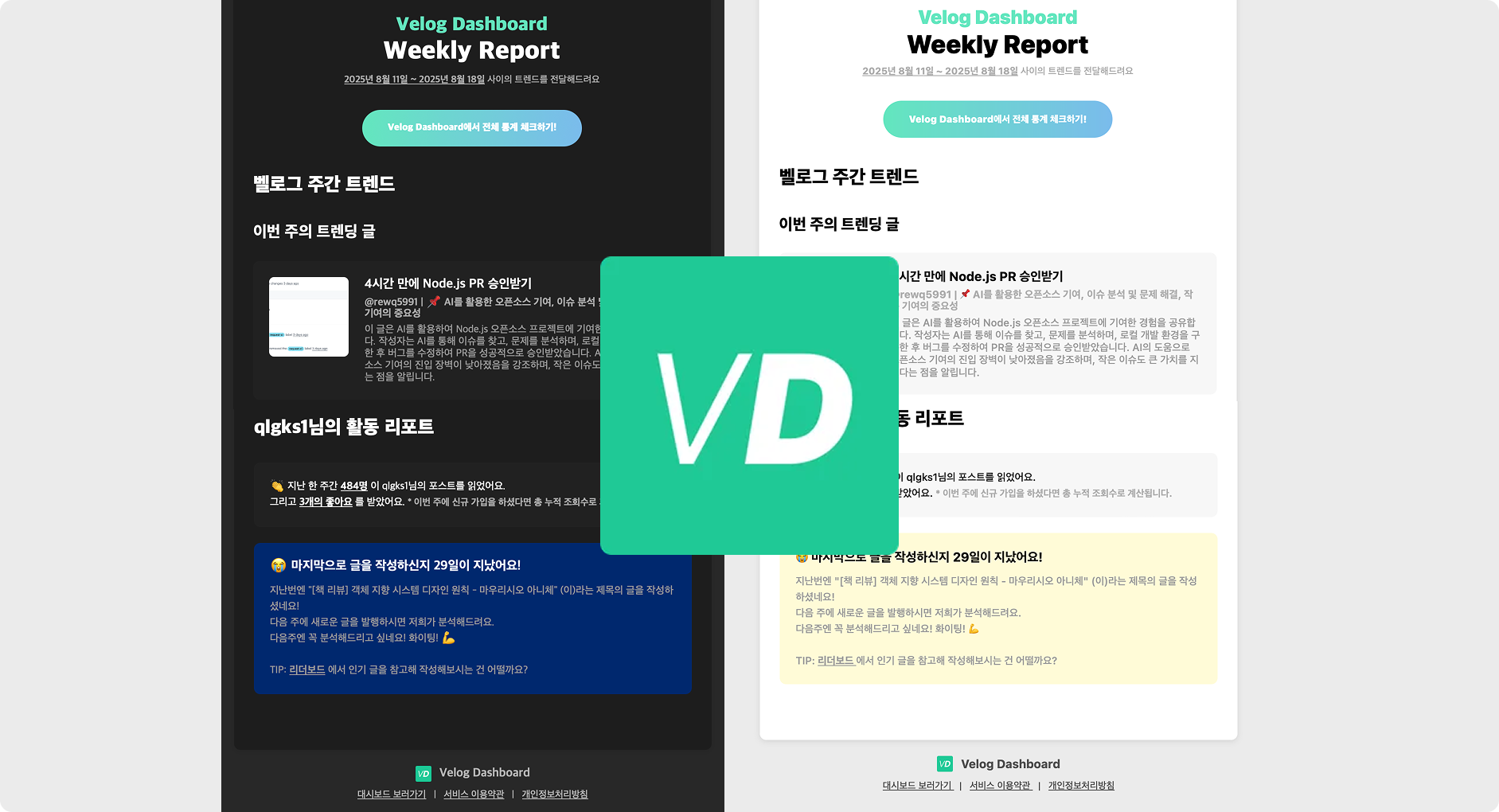
1. 메일링 서비스
Velog 의 주간 트랜드! + 글을 안쓰면 재촉까지!!
그리고 여러분들의 누적 조회 변동량 + 작성한 글에 대한 분석!!
- 글을 쓰면 어떤지 분석을 해드려요, LLM 을 활용한 서비스랍니다 :) 어떤 분석인지 궁금하면 빨리 등록해서 메일을 받아보셔요! >> 빨리 접속하기
세부 구현
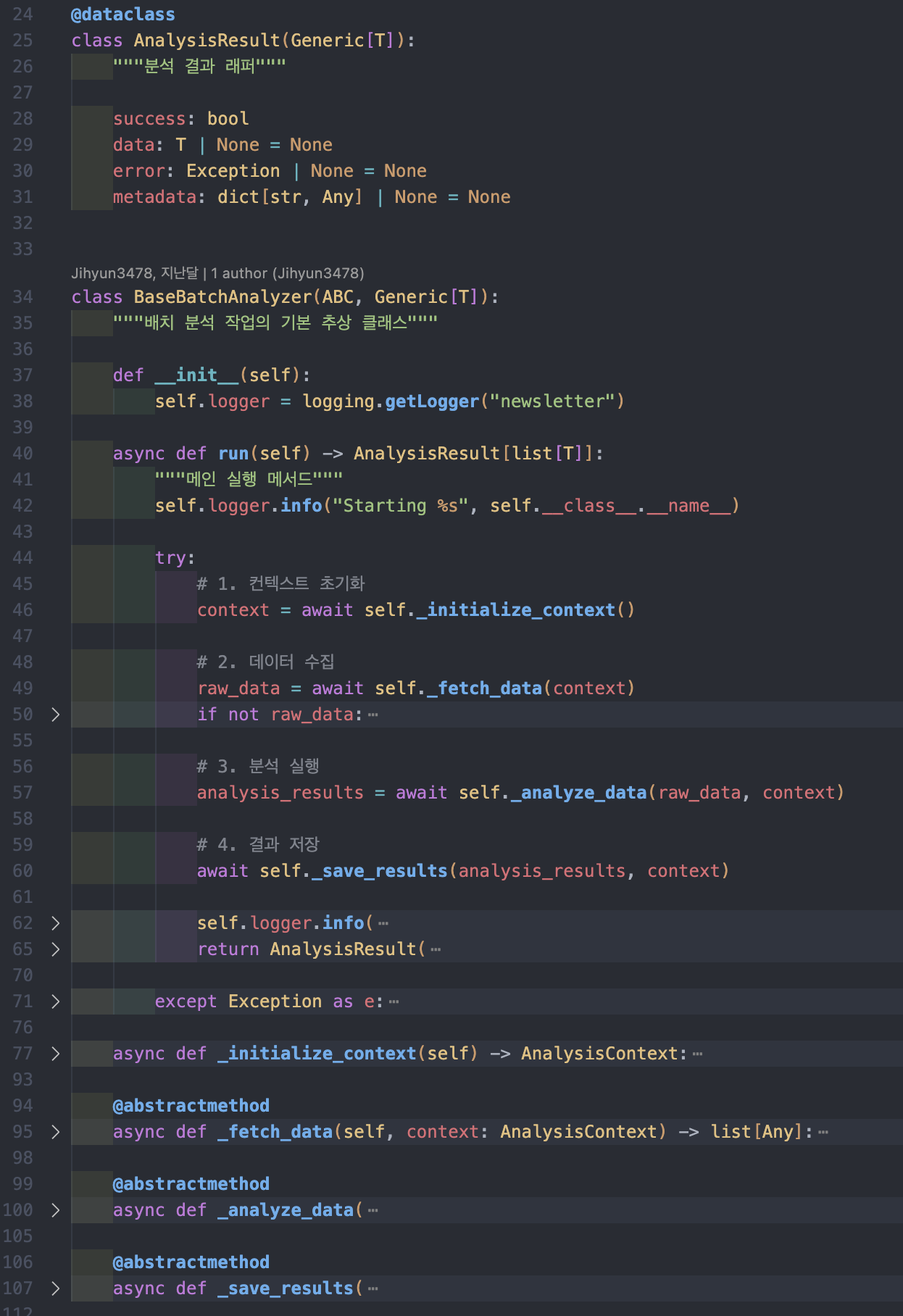
이번에 구현한 “벨로그 글 트렌드 분석” 배치 작업은 추상 클래스 기반 템플릿 메서드 패턴으로 설계했습니다. 내부적으로는 3가지 배치 작업으로 나누어져 있으며, 이를 뒷받침하는 3개의 독립 외부 모듈이 존재합니다.
@dataclass
class AnalysisContext:
"""분석 컨텍스트 정보"""
week_start: datetime
week_end: datetime
velog_client: VelogClient
# ==================================== #
# LLM 호출 부분 ...
# ==================================== #
async def _analyze_data(
self, raw_data: list[TrendingPostData], context: AnalysisContext
) -> list[WeeklyTrendInsight]:
"""LLM을 사용한 트렌드 분석"""
try:
# LLM 입력 데이터 준비
llm_input = [post_data.to_llm_format() for post_data in raw_data]
# LLM 분석 실행
llm_result = analyze_trending_posts(
llm_input, settings.OPENAI_API_KEY
)
...
# ==================================== #
# AWS SES 호출 부분 ...
# ==================================== #
class WeeklyNewsletterBatch:
def __init__(
self,
ses_client: SESClient,
...
# 최대 max_retry_count 만큼 메일 발송
while failed_count < self.max_retry_count and not success:
try:
self.ses_client.send_email(newsletter.email_message)
...-
이번 배치는 단순히 “그냥 만들자!” 보다는 “잘 만들어 두자!”에 가까웠습니다.
특히 처음으로 유저에게 직접 발송되는 메일링을 다루다 보니, 유지보수에 열려 있고 변경하기 쉬운 구조가 무엇보다 중요했습니다. -
외부 모듈은 총 3개로,
llm,velog,SES email입니다. (각자 조금씩 다른 디자인 형태로 설계 되었습니다! 실제 코드 보러가기) -
이 모듈들은 퍼사드(Facade) 패턴과 Lazy Init 싱글톤 패턴으로 구현하여, 내부 비즈니스 로직과 철저히 분리해 두었고, 개별 유닛테스트로 동작을 보장하게 되어있습니다.
-
즉, 내부에서는 해당 모듈의 클라이언트에 접근해 필요한 핵심 비즈니스 로직을 호출하는 것 외에는 어떤 의존성도 가지지 않도록 설계했습니다. 그리고 호출시 주입하도록 했구요!
물론 구현 과정에서 배보다 배꼽이 더 커졌던 것 같긴 하지만요…
- 주간 트렌드 분석
- 주간 사용자 트렌드 분석
- 트렌드 메일 발송
- 배치를 3가지 유형으로 분리한 것도 같은 맥락입니다. 각각의 역할을 명확히 나누어 유연성과 확장성을 확보할 수 있도록 했습니다. 약간의 아쉬움은 존재하지만 과한 집착은 오히려 안티패턴을 만들어~~
2. 리더보드
Velog Dashboard 사용자들은 이제 기간별 조회수 증가량과 좋아요 증가량 리더보드를 더 쉽고 빠르게 확인할 수 있습니다!
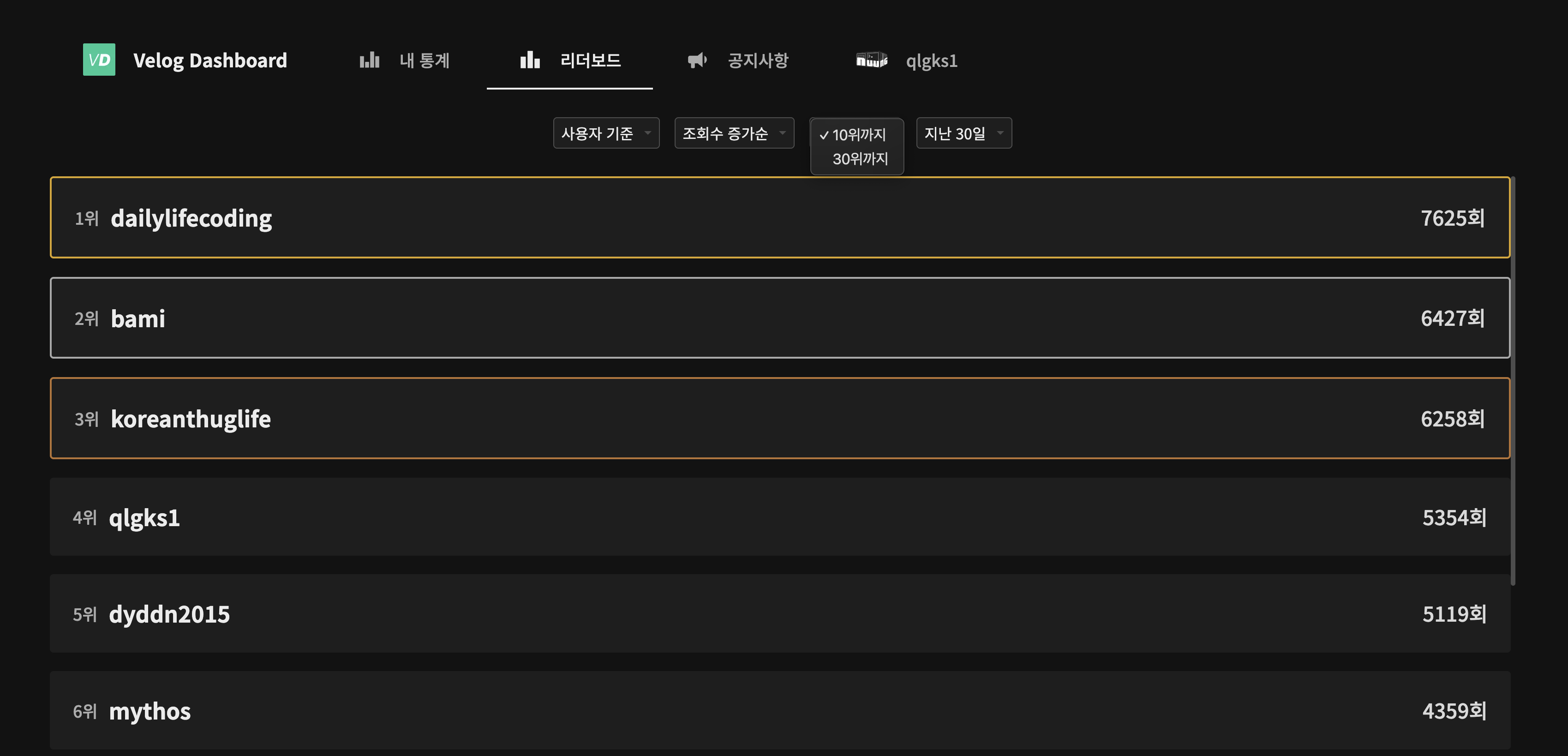
또한 새로운 기능이 추가되었습니다!
- 사용자 클릭 시 → 해당 사용자 Velog 페이지로 이동
- 게시글 기준 정렬 시 → 해당 게시글로 바로 이동
-
이를 구현하기 위해 기존에는 저장하지 않던
velog profile관련 정보(username등)를 불가피하게 저장하게 되었습니다. -
그래도 긍정적인 것은 그 결과, 서비스 자체에서는 더 이상 Velog API를 직접 호출하지 않아도 됩니다!! (물론 통계 집계에는 여전히 Velog API를 사용합니다.) -> 간헐적으로 velog api 가 뻗을때 저희도 Timeout 이 되는 이슈가 있었는데 사실 이제 없다는 의미 ㅎㅎ (첫 로그인 외...)
추가로 Cache Layer를 도입했습니다!
- stand-alone 형태로 독립시켜서 가동했고, 여러가지 업데이트가 있을 것 같아 레포를 파서 버저닝을 하게 되었습니다.
- 그래서 리더보드는 30분 단위 캐싱으로 훨씬 쾌적해졌습니다!! 앞으로 이 캐싱의 적용 범위는 계속 늘어날 것 같습니다!
- 현재는 쿼리 최적화도 병행하고 있지만, DBMS 구조적 한계가 있어 우선 캐싱부터 적용했습니다.
3. DBMS 샤딩과 캐시 layer 추가
1) 처음엔 버티컬 샤딩을 하려고 했었다...
초기에는 Supabase 기반으로 운영했습니다! 다만 다음 이슈들이 겹치며 이소 준비를...
- Postgres 17 전환과 TimescaleDB 지원 변경
-
Supabase가 Postgres 17 번들을 예고하면서
timescaledb가 번들에서 제외(Deprecated)되어, 업그레이드 전에 드롭이 필요해졌습니다. -> 시계열 워크로드를 계속 운영하기엔 마이그레이션·대안 검토 비용이 커졌습니다. -
데이터 egress 비용 압박!!, batch 에서 bulk 로 데이터를 많이 밀어넣다보니 egress 가 유독 한계치를 계속 찍었습니다.. 이 탓에 일단 구독을 해버렸었죠.. (월 2.5만) 근데 supabase 를 no-code tool로 사용할 거라면 돈내고도라도 쓰는데, 우리는 이미 가용할 수 있는 무료 서버도 많았죠...
2) PgBouncer로 풀링 + 간이 분산을 시도
설계 초안
- 토폴로지: 1대 Primary, 2대 Replica(Read-only), 앞단에 PgBouncer
- 의도: 커넥션 폭주 완화(풀링) + 간이 라운드로빈
근데 PgBouncer 는 경량 커넥션 풀러입니다. 자체적으로 다중 호스트 라우팅/샤딩을 하지 않았죠...
- 다만 DNS 라운드로빈(또는 host 리스트 뒤 LB) 을 물려두면, PgBouncer의
server_round_robin옵션으로 서버 커넥션 재사용 방식을 라운드로빈에 가깝게 바꿀 수 있었습니다. - 뭐,, 결론적으로 PgBouncer는 샤딩 도구가 아니라 풀러이므로, “읽기/쓰기 분리”나 “키 기반 샤딩 라우팅”은 별도 계층이 필요했죠,, 탈락!
3) 진짜로 원했던 건 ‘유저 그룹’ 기반 수평 샤딩
도메인 특성상 핵심 테이블이 유저 중심이고, 모든 유저가 group 키를 갖도록 최초부터 설계했습니다. 따라서 횡적 분할(샤딩) 을 통해!
- 단일 노드 I/O 병목을 회피
- 그룹 단위의 데이터 지역성(locality) 확보
- 장애/스케일 전략의 독립성 제고
라는 뻔한(X, 큰꿈) 목표를 노렸고 pgcat 으로 시도 했었죠.. 하지만.. SQL 기반으로 분산 처리 가능하다는데 제대로 작동을 안함
그니까 사실 pgcat 은 sqlparser 기반의 쿼리 파서를 실행해서 SELECT → Replica / 그 외(트랜잭션·DML 포함) → Primary 로 자동 라우팅하는 기능은 명백하게 가지고 있었습니다.. (pgcat github)
근데 더 depth 있게 SQL 의 특정 key 값만 판단해서 라우팅을 하려면 모듈을 오버라이딩 해야 했죠..
-
사실 더 정확하겐
SET SHARDING KEY를 통해 샤드 라우팅을 할 수 있는데, 이는 결국 백오피스든, API에서든, 이를 위한 서드파티 구성이 필요하다는 의미.. -
일단 본능적으로 한 보 후퇴,, 그래서 일단 P.D.D (Primary + 2 Dup) 세팅으로 하되, 다음을 노리는 것으로 방향을 잡았습니다. (근데 사실 아직까지 못끝낸거 실화?...)
4) redis 기반 cache layer, 이를 위한 모듈
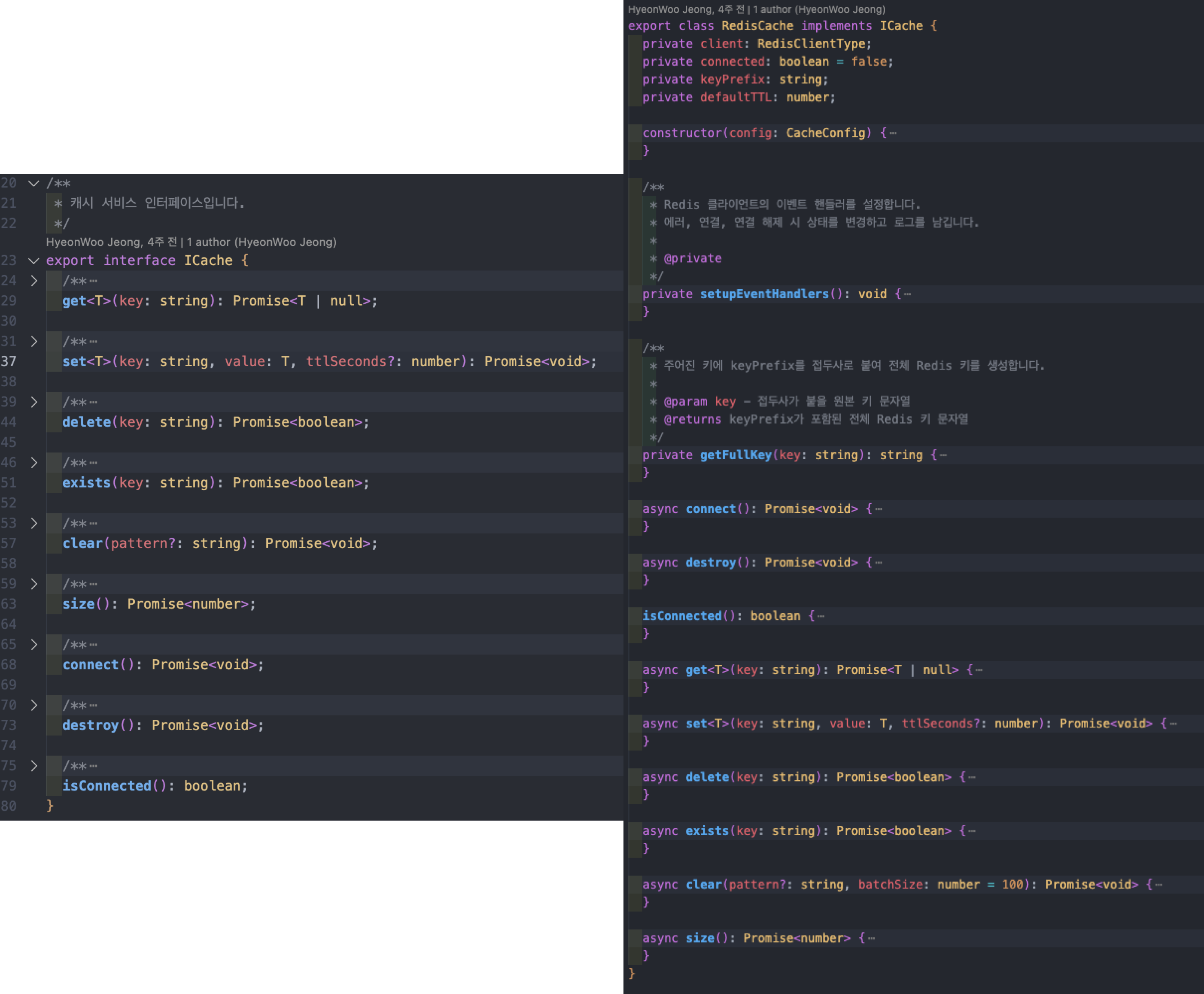
캐시에서 조금 그럴듯 한 얘기를 붙이자면 Interface Segregation Principle 지향했고CacheConfig, Redis 구현체를 위한 ICache "Strategy Pattern" 과 RedisCache 를 하나의 "Adapter" 로 사용하고자 했습니다.
// cache.config.ts
const cacheInstance: ICache = new RedisCache(cacheConfig);
export const cache = cacheInstance; // 전역에서 하나의 인스턴스 사용- 위와 같이
Singleton으로 사용했고, 필요할때만 전역에서 불러와 사용합니다. ICache덕에 test code 에서 주입하기도 좋습니다!- 캐싱 전략은 우선적으로 TTL 밖에 없습니다!
5) 그래서 현 최종 인프라 개괄도
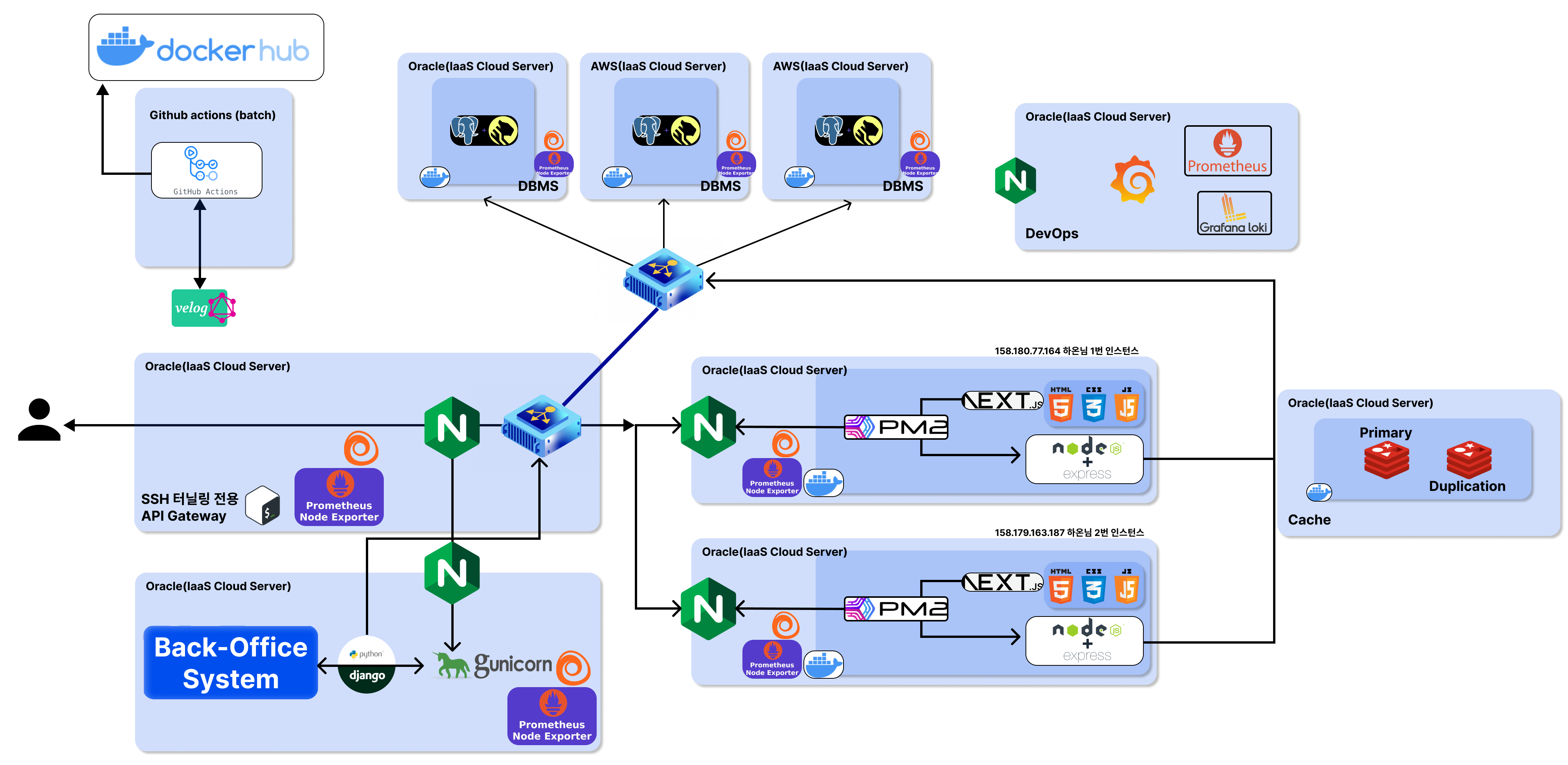
개발새발인 것 같지만 이게 최대치
4. DevOps
Prometheus + PLG stack 을 기본 베이스로 깔고, (Prometheus)node-exporter 들로 서버 자체 매트릭을 가져오는 정도를 목표로 세팅했습니다. (사실 아직 완료는 못했고 중에 있습니다.)
- 근데 웬걸, alloy 라는 걸로 바뀌어 버렸네?
- 굳이 왜..? 를 좀 더 찾아보니 "Grafana는 Prometheus, Promtail, Grafana Agent 등 서로 다른 수집 도구들을 하나로 통합" 하고 싶었다고 하네요.. -
https://grafana.com/blog/2024/04/09/grafana-agent-to-grafana-alloy-opentelemetry-collector-faq/?utm_source=chatgpt.com근데 사실 오히려 좋아
| 단계 | 일정 (2025년 기준) | 주요 내용 |
|---|---|---|
| Promtail LTS 시작 | 2025-02-13 | 기능 업데이트 종료, 보안·버그 수정만 지원 (Grafana Labs, Grafana Labs) |
| Alloy 기능 통합 | Loki 3.4 이후 | Promtail 기능 및 구성 변환 도구 Alloy에 통합 (Grafana Labs, Grafana Labs) |
| Promtail EOL | 2026-03-02 | 공식 지원 및 업데이트 완전 종료 (Grafana Labs, Grafana Labs) |
- 메트릭, 로그, 트레이스 통합 수집 → Alloy,
- 시각화/알람 → Grafana,
- 스토리지 → Loki/Prometheus
이 3강 체제로 "Observability" 를 끌어올리려고 합니다!
마무리와 TOBE
-
(혹시나 궁금하신 분들 위해..) DAU 는 약 50+- a 선으로 나오고 있습니다. 꾸준히 보는 사람만 보는? 그런 좀비 서비스랄까요ㅎㅎ 일단 제가 가장 열심히 DAU에 일조하고 있는 듯
-
통계 데이터는 약 300만개에 달하게 되었습니다. P.D.D 세팅이 시급합니다.. 어서 제발 끝내자..
이제 다음 feature 는 진짜 다른 플랫폼 통계 데이터 aggregation 으로의 확장일 것 같습니다. 아마 미디엄이나 티스토리 둘 중 하나가 될 것 같네요!
여기까지가 Velog Dashboard v2의 생존기(?)와 업데이트 소식입니다!
매번 글을 너무 과하게 쓰는 것 같아서 많이 줄였습니다 ㅋㅎㅋㅎ



매일 잘 사용하고 있어요! 감사합니다!