
[ "길벗 출판사에서 책을 협찬 받아 작성된 서평입니다." ]
객체지향 시스템 디자인 원칙
Maurício Aniche(마우리시오 아니체): 아디옌(Adyen, 네덜란드 기술 기업)에서 테크 리드로 근무(근데 최근 우버로 이직하신 듯), 아디옌의 테크 아카데미를 포함해 엔지니어를 위한 추가 교육과 훈련에 중점을 둔 엔지니어링 지원 이니셔티브 팀을 이끌고 있다. 또한 네덜란드 델프트 공과대학교(Delft University of Technology)에서 소프트웨어 공학 조교수로 재직 중. 2021년 올해의 컴퓨터 과학 교사 상을 받았고, 혁신적인 강사에게 수여되는 명예로운 TU 델프트 교육 펠로우십(Delft Education Fellowship)을 받았다. - 링크드인 & 저자 블로그
요새 저자들 링띤을 어떻게든 찾아내서 책 잘 읽었다고 슬쩍 메시지를 보내본다. 모르는 부분 물어보는 재미가 아주 쏠쏠하다.
🔥 길벗 책 링크 - https://www.gilbut.co.kr/book/view?bookcode=BN004492
🔥 코드 참조 깃허브 레포 - https://github.com/enshahar/SimpleObjectOrientedDesignCode (옮긴이, 오현석님께서 모두 한글로 재구성 해주셨다.)
🔥 그리고 이를 python 으로 직접 포팅한 레포 - https://github.com/Nuung/SimpleObjectOrientedDesignCode
리뷰
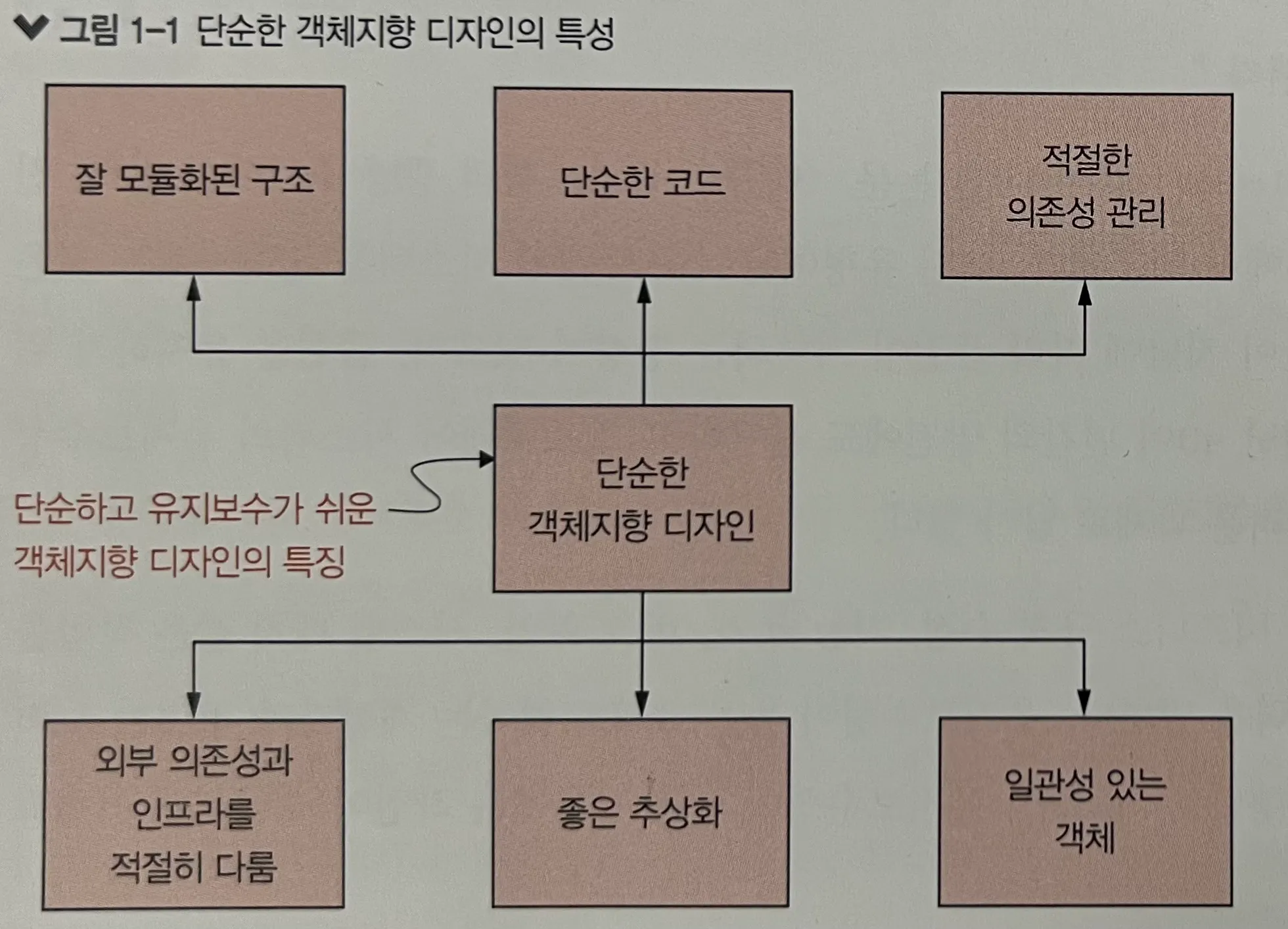
시장에는 객체지향 설계(OOP)와 디자인 패턴 관련 책들이 정말 넘쳐난다. 그럼에도 이 책이 매력적이었던 포인트는, 저자의 머릿말에서부터 “이 정도면 충분한 디자인을 이루는 방법” 에 대해 이야기하고 있기 때문이다. 이 책은 실제로 아래 그림 한 장으로 표현할 수 있다.
이상하게 가장 오래 기억에 남는 문장은 6장에서 나오는 "프레임워크와 싸우지 마라" 이다.
도메인 주도 설계(DDD)에 깊이 몰입하다 보면, ‘프레임워크는 거들 뿐’이라는 말에 너무 진심이 되어버릴 때가 있다. 실제로 나도 과거에 프레임워크 의존성을 싹 걷어낸 뒤, REST API 하나 만들기 위해 어답터 패턴을 굳이 도입하고, 퍼사드를 하나 더 추가하면서 “프레임워크랑 싸운” 경험이 있다. (나름 프레임워크 의존성 없는 독립 모듈에 프레임워크를 얹어 보겠다는 일념으로)
물론 그 시도가 틀렸다고 말할 순 없지만, 책에서 말하듯 어디에서는 프레임워크에 의존하지 말아야 하고, 어디에서는 과감하게 활용해야 하는지의 경계를 짚어주는 부분이 특히 와닿았다. (해당 장에서는 "인프라 계층" 에 대한 것을 다루는데, 아주 좋음!)
이 책은 전체적으로 짧다. 그렇기에 실습 없이 읽으면 아무런 의미가 없다. 꼭 깃허브에 공개된 예제 코드를 따라가는 것을 추천한다.

- 2장부터 5장은 코드작게, 일관성, 의존성, 추상화까지 SOLID 원칙을 하나씩 top-down 하는 흐름이고,
- 6장과 7장이 인프라를 포함한 외부 의존성 (모듈)에 대해 다루며,
- 8장 이상과 현실에 대한 얘기를 하며 끝난다.
솔직히 말하면, 많은 설계/아키텍처 책들은 읽다 보면,, 마치 "성공하는 100가지 법칙!" 같은 책을 읽는 느낌이 든다. 책 내용이 안좋다는게 아니라, 유니콘에 대한 해설책 느낌이랄까.
물론 이 책도 모든 걸 해결해주지는 않지만, 점진적인 고도화 전략과 각 장별로 전달하려는 핵심을 예제 기반으로 잘 녹여낸다는 점에서 실전성 높은 책이라고 생각이 든다. (각 장에서 핵심을 설명하고, “피플그로우!” 라는 실전 예제가 항상 느낌표와 함께 따라온다. 이 반복도 의외로 인상 깊다.)
무엇보다도 좋았던 건, 처음부터 완벽하지 않아도 괜찮다고 말해준다는 점이다. 처음에는 모든 책임을 명확히 구분하거나, 도메인을 제대로 정의하지 못하는 게 당연하며, 그것을 점진적으로 개선해가는 방향이 더 현실적인 접근이라는 메시지가 담겨 있다. "진짜 좋은 디자인은 세 번쯤 다시 작성한 후에야 얻어진다!"
나는 이 책을 처음에는 한숨에 읽고, 그 뒤 코드를 하나하나 Python으로 포팅하면서 다시 읽었는데, 생각보다 시간이 정말 오래 걸렸다. 사실 Python으로 다시 짜는 데 대부분의 시간이 들었다는 건 비밀이다. 디자인 책은 아무리 라이트하다고 해도, 주제 자체가 결코 라이트하지 않다는 점을 다시금 느꼈다.
이 책은 마틴 파울러, DDD, 전통적인 디자인 패턴 등 다양한 고전과 참고 문헌을 바탕으로 하고 있다. 하지만 그 모든 걸 당장 직접 찾아가며 읽을 필요는 없다.
오히려 이 책이 그런 책들에 들어가기 전, 특히 DDD를 공부하기 전에 읽으면 딱 좋은, 전초전 같은 느낌의 책이다. “왜 디자인 패턴?” “왜 객체지향?” “좋은 코드란 대체 뭘까?”라는 질문에 대해 가볍고도 넓게 훑어준다. 이 책을 읽은 다음 ‘클린 아키텍처’와 DDD를 읽으면, 훨씬 더 잘 이해할 수 있을 것이다.
이제 실제 코드 구현은 AI 가 대부분이 한다. 하지만 사견으로 여전히 "적절한 디자인" 은 답답한 구석이 너무나 많다. 그리고 "적절한 디자인" 이라 함은 S/W 구준, 서비스의 현실적인 상황, 팀 내부의 상황 등을 포함해 내&외부에 따라 trade-off 정도가 천차만별이다.
나는 여전히 이 부분에서 필연적으로 AI 를 control 할 인력이 필요하다고 본다. 당장의 cache layer 를 구현하는데, TTL 전략 외 LRU, LFU 까지 강제 구현해버려서 짜증이 났다.
철저하게 TTL 만 사용할꺼고 필요로 하는데, 이 때문에 storage 와 strategy 인터페이스(추상화) 까지 만들어 버렸다. 물론 이게 틀린게 아니라 내가 원한 것 보다 너무 과했기 때문이다. 이걸 다시 리펙토링 하며 가다듬다보면 '이럴꺼면 내가 처음부터 하지',,, 라는 생각도 많이 든다.
이 부분은 더 고도화되겠지만 본질적으로 거시적인 관점에서 trade-off 에 맞는 output 을 평가하는 주체는 아직까지 "인간" 의 영역이고, 이 영역은 더 소중해 질 것으로 보인다. 그렇기 때문에 이런류의 책이 "더 이상 필요 없다 / 이제 AI 가 다 해준다" 라는 평가에는 강력하게 반대한다.
목차별 리뷰
1장 모든 게 복잡도 관리다
이 책은 기존의 객체지향 베스트 프랙티스를 단순히 반복하지 않는다. 원제인 Simple Object Oriented Design 이 암시하듯이, 복잡도를 줄이는 것, 즉 단순한 구조와 유지보수 가능한 시스템을 어떻게 설계할 수 있는가에 초점을 맞춘다.
얘기 시작. 복잡성을 줄이거나 그대로 유지하기 위한 작업을 수행하지 않으면 S/W 시스템은 시간이 지남에 따라 복잡성이 증가한다.
저자는 매니 레만(Lehman)의 논문, "대규모 프로그램의 생명 주기에서 법칙, 진화, 보존에 대한 이해" 라는 논문에서 인용하며 논의를 시작한다. 요지는 단순하다. 복잡성은 줄이거나 유지하지 않으면 반드시 증가한다. 즉, 이를 방치하면 시스템은 유지보수하기 점점 어려워지고, 결과적으로 개발 속도는 느려지고 품질은 낮아진다.
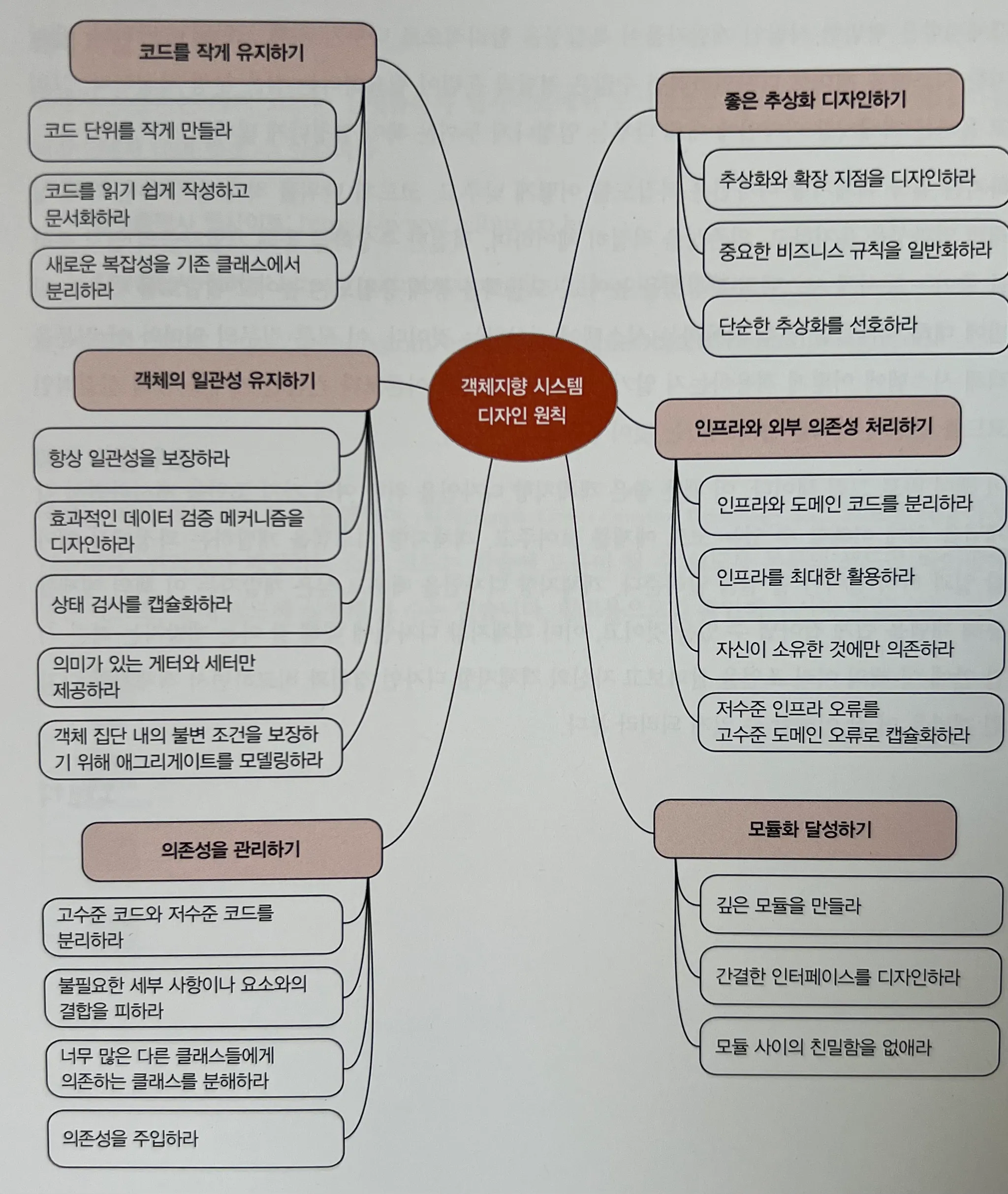
[ 단순한 객체지향 디자인을 위한 여섯 가지 핵심 원칙 ]
책에서는 단순함을 지향하는 객체지향 디자인을 위해 다음 여섯 가지 원칙을 제시한다.
-
단순한 코드
메서드와 클래스는 작고 단순하게 유지해야 한다. 코드의 "크기" 자체가 복잡성을 야기할 수 있다.
→ 즉, 짧고 명료한 함수, 작은 클래스 단위를 유지해야 함. -
일관성 있는 객체
객체는 항상 유효한 상태를 유지해야 한다.
외부에서Basket클래스를 마음대로 수정할 수 있다면 이는 곧 무결성 침해로 이어진다.
이를 위해선 다음 키워드 정도를 떠올릴 수 있다.- 불변성(immutable), 적절한 getter/setter 제공, 접근 제어자 활용 등
-
적절한 의존성 관리
높은 응집도(high cohesion)와 낮은 결합도(low coupling)를 동시에 지향해야 한다.
자식 클래스가 바뀔 때마다 부모 클래스도 바뀐다면, 이는 변경 전파의 악순환이다.
→ 이러한 상황을 방지하기 위한 핵심은 디커플링(decoupling)이다. -
좋은 추상화
추상화는 단순성과 확장성 사이의 균형을 제공한다.
단순함을 추구하다 보면 어느 순간 클래스의 메서드가 지나치게 많아지며 혼란을 유발할 수 있다.
의미 있는 추상화 계층을 도입하는 것이 해결책이다. -
외부 의존성과 인프라를 적절히 다루기
비즈니스 로직과 외부 시스템(DBMS, API 등)과의 의존성은 분리되어야 한다.
예: DB 연결 로직이 여기저기 흩어져 있다면, 추후 캐시 도입이나 DB 교체 시 유지보수 지옥이 펼쳐진다.※ 참고: DDD에서는 이러한 외부 시스템과 자원을 “인프라”로 분류한다.
-
좋은 모듈화
시스템을 작고 명확한 컴포넌트 단위로 나누는 것이 중요하다.
이는 이해하기 쉽고, 변경하기 쉬운 코드를 만드는 데 핵심이다.
[ 일상적인 활동으로서의 단순한 디자인 ]
복잡도를 낮추는 행위는 일회성 이벤트가 아니라, 일상의 루틴처럼 지속적으로 수행되어야 한다.
-
복잡성 줄이기는 개인 위생과 같다
매일 조금씩 관리하지 않으면, 쌓이고 쌓여 나중에는 감당이 안 되는 수준이 된다. -
복잡성이 필요할 수도 있지만 영구적이어서는 안 된다
예외적 상황에서 복잡한 구조가 불가피하더라도, 이를 영구 구조로 유지하면 안 된다. (하지만 소 잡는 칼로 닭 잡지 마라! 점진적 접근!) -
지속적으로 복잡성을 해결하는 것이 비용 효율적이다
미뤄놓으면 나중에 더 큰 비용을 치른다. 리팩터링과 점진적 개선을 게을리하지 말아야 한다. -
고품질 코드는 좋은 실무 프랙티스를 촉진한다
→ 이른바 "깨진 유리창 이론"처럼, 더 나은 코드가 더 좋은 문화를 만든다. -
복잡성을 통제하는 것은 생각보다 어렵지 않다
꾸준한 주의와 실천이 있다면 충분히 관리 가능한 수준이다. -
디자인을 단순하게 유지하는 것은 개발자의 책임이다
아무도 해주지 않는다. 개발자 스스로가 구조를 정리하고 유지할 책임이 있다. -
“이 정도면 충분히 좋은 디자인이다”라는 마음가짐
완벽한 디자인을 고집하기보다, 지금 당장 필요한 수준에서 가장 깔끔한 해법을 추구해야 한다.
『A Philosophy of Software Design』에선, "진짜 좋은 디자인은 세 번쯤 다시 작성한 후에야 얻어진다" 라는 말이 등장한다. 전적으로 동의하는 대목이다.
[ 정보 시스템 아키텍처 구성 요소 ]
이 책에서는 복잡도를 줄이기 위해 객체지향 아키텍처를 어떻게 구성할 것인가에 대해서도 간략히 소개한다:
-
엔터티(Entity)
비즈니스 개념을 표현하는 핵심 객체.
예:Invoice클래스는 청구서라는 개념을 속성과 메서드로 표현한다. -
서비스(Service)
복잡한 비즈니스 로직을 캡슐화.
예:GenerateInvoice는 장바구니의 품목을 종합해 최종 청구서를 생성한다. -
리포지터리(Repository)
데이터 저장 및 조회 로직을 담당.
DB와의 통신은 이 계층에서 처리. -
DTO (Data Transfer Object)
계층 간 정보 전달에 사용되는 단순한 데이터 구조체. -
유틸리티 클래스
언어나 프레임워크가 제공하지 않는 범용 기능을 모은 클래스.
→ 다만 너무 남용하면 도메인 의미를 흐릴 수 있어 주의 필요.
2장 코드를 작게 유지하기
(개인적인 해석으로) 이 장의 핵심 주제는 단 하나다.
“코드를 작게 나누는 것이 복잡도 제어의 출발점이다.”
크고 복잡한 코드일수록 변경에 취약하며, 버그가 발생하기 쉽고, 테스트와 협업이 어렵다.
반대로 작고 응집력 있는 코드 단위는 더 안전하고 유지보수도 용이하다.
클래스와 메서드는 작아야 한다. 긴 메서드는 언제든 버그의 온상이 될 수 있다. 그래서 기본 원칙은 단순하다. “작은 단위는 항상 큰 단위보다 낫다.”
[ 복잡한 메서드를 비공개 메서드로 나눠라 ]
응집력 있는 컴포넌트는 단일한 책임을 가진다. 즉, 한 가지 일만 하는 메서드로 쪼개야 한다. 이를 위한 체크리스트는 다음과 같다:
- 새 메서드의 목적을 설명하는 명확한 이름을 붙일 수 있는가?
- 새 메서드가 응집력 있고, 작으며, 외부 공개 메서드에서 쉽게 호출될 수 있는가?
- 많은 파라미터나 클래스에 의존하지 않고 간결하고 명확한가?
- 정적 메서드로 만들 수 있을 정도로 독립적인가? -> 정적 메서드로 만들 수 있다는 건, 해당 코드가 객체 상태에 의존하지 않는다는 뜻이기도 하다.
[ 복잡한 코드 단위를 다른 클래스로 옮겨라 ]
특정 코드가 현재 클래스의 주요 책임과 관련이 없다면, 그 코드는 다른 클래스로 옮겨야 한다. 아래 질문들을 스스로 던져보자:
- 이 코드는 클래스의 나머지 코드와 다른 작업을 하는가?
- 이 코드에 별도의 이름과 클래스가 필요할 정도로 독립적인 의미가 있는가?
- 독립적인 테스트가 필요한가?
- 클래스 전체가 너무 비대해지고 있진 않은가?
→ 이럴 땐 분리하라.
[ 코드를 작은 단위로 나누지 말아야 할 때 ]
항상 쪼개는 게 답은 아니다. 오히려 쪼개면 복잡해지는 경우도 있다. 아래는 쪼개지 말아야 할 때의 기준이다:
- 퍼즐 조각들이 독립적으로 존재할 수 없을 때 억지로 분리하면 메서드 시그니처가 복잡해짐
- 해당 로직이 교체될 가능성이 낮을 때
- 별도로 테스트할 만한 가치가 없을 때
PS. 여기서 “클래스병” 조심하자 — 존 오스터하우트의 Software Design Philosophy 에서 말하듯, 불필요하게 클래스를 쪼개면 오히려 관리가 더 힘들어진다.
[ 리팩터링하기 전에 전체적으로 살펴보라 ]
무작정 리팩터링하지 말고 먼저 최종 구조를 머릿속에 그려보라. → 미래를 고려한 변화인지 반드시 확인하고 실행할 것.
- 리팩터링 후 모습은 어떤가?
- 그 모습이 지향하는 설계 철학에 부합하는가?
- 지금의 디자인에 문제가 있는 건가?
[ 예제: 직원 데이터 임포트하기 ]
이 책은 "피플그로우!" 프로젝트를 계속 고도화 해간다. 상단 깃허브 레포, https://github.com/Nuung/SimpleObjectOrientedDesignCode 에서 실제 코드를 볼 수 있다. (근데 python 으로 포팅해봄)
여기서 import_employee_service라는 덩치 큰 서비스를 점진적으로 리팩터링하고 쪼개나간다.
└── ch2
├── v1
│ ├── __init__.py
│ ├── csv_parser_library.py
│ ├── employee_repository.py
│ ├── employee.py
│ ├── import_employee_service.py
│ └── import_result.py
└── v2
├── __init__.py
└── import_employee_service.py[ 코드를 읽기 쉽게 만들고 문서화하라 ]
클린코드에선 코드 작성 vs 읽기 시간의 비율은 1:10 이라는 언급이 있었고, 개발자는 전체 시간의 60%를 코드 읽기에 소비한다는 논문도 있다. 이 사실만으로도 “읽기 쉬운 코드”의 중요성은 충분히 강조된다.
1. 좋은 이름을 계속 찾아라
유비쿼터스 언어(Ubiquitous Language, 개발 팀원 모두가 도메인 개념을 이해하고 의사소통하기 위해 사용하는 일관성 있는 공통 언어) 를 기반으로 하라. 팀 전체가 도메인을 공유하는 언어로 일관성 있게 표현해야 한다. → 좋은 네이밍은 단순한 기교가 아니라, 팀 커뮤니케이션의 기반이다.
2. 의사결정을 문서화하라
조건 분기나 로직이 복잡할수록 “왜 이런 결정을 했는가”를 문서화해야 한다. → 조건문은 “결과”이고, 주석(설명, 외부 docs등)은 그 “배경”이다.
3. 코드에 주석을 추가하라
너무 많은 주석은 오히려 혼란을 주지만, 주석이 전혀 없는 코드도 읽기 힘들다. 잘 정제된 핵심 주석은 코드 품질의 일부다.
주석에 대한 의견은 다양하지만, 개인적으로 임베디드 시스템이나 byte 한 개에 목숨거는게 아닌 이상, 무슨 TCP 의 14byte 못지키면 죽는게 아닌 이상, 개인적으로 제발 주석을 좀 썻으면 한다. 그리고 책에서는 "왜 했는가?" 도 주석에 남길 필요가 있는 경우가 있다고 언급한다! 매우 동감! 쩨발!
[ 새로운 복잡성을 기존 클래스에서 분리하라 ]
비즈니스 복잡성 증가함에 따라 코드는 성장할 수 밖에 없지만, 성장은 통제돼야 한다. 많은 경우 클래스가 무한정 성장하는 이유는 개발자가 기존 코드를 변경하지 않고 새로운 기능을 추가할 수 있게 해주는 적절한 추상화나 확장 지점이 부족하기 때문. (뼈를 너무 맞아서 좀 아픈 대목)
1. 복잡한 비즈니스 로직을 자체 클래스로 분리하라
새로운 복잡한 로직은 전용 클래스로 독립시켜야 한다. 단, 해당 로직이 작용하는 대상 클래스와 논리적으로 가까운 곳에 위치시키는 것이 좋다.
2. 큰 비즈니스 흐름을 분해하라
여러 단계가 복합적으로 얽힌 비즈니스 흐름은 다음과 같은 방식으로 나눠보자! 핵심은, 하나의 흐름을 여러 개의 작고 응집력 있는 단위로 나누는 것이다.
-
GOF 패턴 예시:
- 책임 연쇄 패턴(Chain of Responsibility)
- 데코레이터 패턴
- 옵저버 패턴
-
더 복잡한 경우:
- 도메인 이벤트 기반 시스템을 고려하자
- 이벤트 기반 아키텍처로 재설계할 수도 있다
SRP(Single Responsibility Principle)는 “하나의 변경 이유만 있어야 한다”는 원칙이다.
이 장에서 강조하는 “작은 단위로 쪼개기” 는 SRP와 결을 같이하지만, SRP가 “책임”에 초점을 둔다면, 이 장은 “크기와 응집력”에 초점을 둔다. 초기 설계 단계에서는 "책임"을 명확히 정의하기 어렵기 때문에, 그보다 더 간단한 접근은 “일단 작게 쪼개기” 라고 한다.
3장 객체의 일관성 유지하기
이 장에서는 객체가 스스로 자신의 상태를 "일관성 있게 유지하도록" 설계하는 것이 얼마나 중요한지를 중심으로 다룬다.
특히 도메인 모델에서의 일관성 유지란 단순히 값 검증을 넘어서, 객체가 책임져야 할 행위와 상태에 대한 깊은 이해를 요구한다.
PS. 일관성(consistency)은 객체가 정확하고 신뢰할 수 있는 정보를 가지고 있음을 나타냄
PS. 반면 DBMS 에서는 무결정(integrity)이 "정보를 정확하게 유지하는 것"을 의미 (일관성은 주로 데이터의 가용성과 관련 있음)
[ 항상 일관성을 유지하라 ]
1. 클래스가 스스로 일관성을 책임지게 하라
데이터의 일관성을 보장하는 책임은 데이터가 속한 클래스 내부에 있어야 한다. 예를 들어, 교육 과정 등록 기능에서 Offering 클래스는 최대 참가자 수를 넘기지 않도록 직접 add_employee() 메서드 내에서 유효성 검사를 수행하고, 등록 시 자동으로 빈 자리를 줄인다. 외부에서 이를 처리하면 중복된 로직이 생기고, 시스템 전반에서 예기치 못한 불일치 상태가 생길 수 있다.
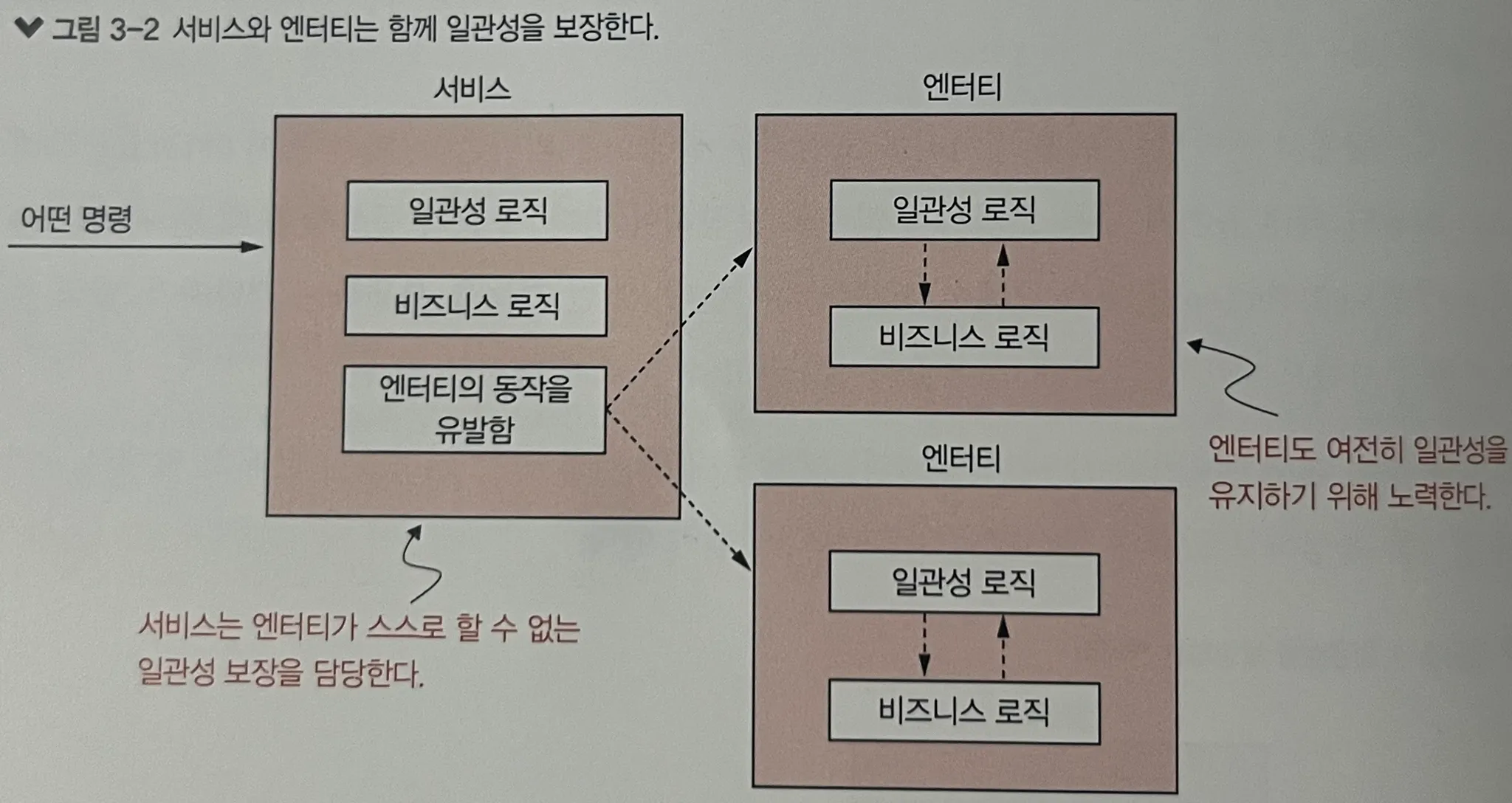
2. 전체 작업과 복잡한 일관성 검사를 캡슐화하라
단일 클래스가 책임지기 어려운 경우, 서비스와 엔티티가 함께 협력하여 일관성을 보장할 수 있도록 설계해야 한다. 서비스는 흐름을 조율하고, 엔티티는 그 안에서 내부 상태를 보장하는 식이다.
3. 예제, Employee 엔터티 업데이트!
클래스 내부 일관성 보장하도록
- 오퍼링 직언 추가 되면 잔여 허용 인원 자동으로 하나 줄이고
- 자리가 꽉 찬 경우라면 새로운 직원이 추가되지 않도록
동시성과 디자인
- 비기능적 요구 사항이 디자인 결정에 영향을 미칠 수 있다. 오퍼링에 직원 추가하는 요청이 동시에 일어난다면, 지금 디자인은 작동하지 않을 수 있음.
class Offering:
"""Training offering with enhanced enrollment management"""
def __init__(self, training: Training, date_: date, maximum_number_of_attendees: int):
self._id: int | None = None
self._training = training
self._date = date_
self._employees: Set[Employee] = set()
self._maximum_number_of_attendees = maximum_number_of_attendees
self._available_spots = maximum_number_of_attendees
@property
def employees(self) -> Set[Employee]:
"""Get immutable copy of enrolled employees"""
return frozenset(self._employees) # Return immutable set
def add_employee(self, employee: Employee) -> None:
"""Add employee to offering with validation and prevent duplicates"""
if self._available_spots == 0:
raise OfferingIsFullException()
if employee in self._employees:
# 이미 등록된 직원이면 spots 차감하지 않고 무시
return
self._employees.add(employee)
self._available_spots -= 1
def has_available_spots(self) -> bool:
"""Check if offering has available spots"""
return self._available_spots > 0
@property
def available_spots(self) -> int:
"""Get number of available spots"""
return self._available_spots
@property
def training(self) -> Training:
"""Get training for this offering"""
return self._training
def is_employee_registered(self, employee: Employee) -> bool:
"""Check if employee is registered for this offering"""
return employee in self._employees[ 효과적인 데이터 유효성 검사 메커니즘을 디자인하라 ]
1. 사전 조건을 명시적으로 정의하라
메서드는 자신이 기대하는 입력 조건을 분명하게 설정해야 한다. 예를 들어, addEmployee(employee) 메서드에 None 값이 들어오면 단순히 무시하는 것이 아니라, 아예 None 이 들어올 수 없음을 전제로 코드 설계를 해보는 것. 그렇게 함으로써, 숨은 오류 발생을 방지할 수 있고 유지보수가 쉬워진다.
근데 모든 경우에 대해 다 처리하면, 내부 개발 코드만 더 늘어난다. 이때 중요한 것이 "존재하지 않는 오류 정의" 하는 것이다.
2. 유효성 검증 컴포넌트를 만들라
비즈니스 룰이 복잡해질수록 검증 로직은 분리되어야 재사용성과 가독성이 높아진다. 이 때 Specification Pattern 과 같은 명세 패턴을 도입해, 특정 조건을 만족하는지를 명확히 정의할 수 있다.
다만 모든 유효성 검사를 엔티티 내부에 구현하는 것은 피하고, 서비스 계층에서 조율하는 방향이 좋다.
3. null은 신중하게 사용하고, 피할 수 있다면 피하라
null은 호출자에게 모든 책임을 전가하기 때문에 위험하다. 가능하면 빈 객체, 옵션 값, 또는 에러 객체로 대체하는 것이 바람직하다.
(특히 파이썬과 같은 언어에서는 None 검사 분산이 코드 복잡도를 높이는 주범이 될 수 있다ㅠㅠ)
근데 빈 값이 가능하다면?
- 값 없음을 나타내는 객체를 만들어 보는 것은 어떨지? (빈 리스트 등)
- 문제 발생시 null 리턴이 아니라, 문제가 무엇인지 설명하는 클래스 리턴은?
4. 예제: 교육 과정에 직원 추가하기
class AddEmployeeToOfferingService:
"""Service for adding an employee to a training offering with validation"""
def __init__(
self,
offerings: OfferingRepository,
employees: EmployeeRepository,
validator: AddEmployeeToOfferingValidator,
):
self._offerings = offerings
self._employees = employees
self._validator = validator
def add_employee(self, offering_id: int, employee_email: str) -> None:
"""Add an employee to an offering after validation"""
offering_opt = self._offerings.find_by_id(offering_id)
employee_opt = self._employees.find_by_email(employee_email)
if not offering_opt or not employee_opt: # 1
raise InvalidRequestException("Offering and employee IDs should be valid")
offering = offering_opt
employee = employee_opt
validation = self._validator.validate(offering, employee) # 2
if validation.has_errors(): # 3
raise ValidationException(validation)
offering.add_employee(employee) # 4
class ValidationResult:
"""Result of a validation check, containing errors if any"""
def __init__(self):
self.errors: List[str] = []
def has_errors(self) -> bool:
"""Check if there are any validation errors"""
return bool(self.errors)
def add_error(self, error: str) -> None:
"""Add a validation error message"""
self.errors.append(error)
class ValidationException(Exception):
"""Exception raised for validation failures"""
def __init__(self, validation_result: ValidationResult):
self.validation_result = validation_result
super().__init__(f"Validation failed with errors: {validation_result.errors}")
class AddEmployeeToOfferingValidator:
"""Validator for adding an employee to a training offering"""
def __init__(self, trainings: TrainingRepository):
self._trainings = trainings
def validate(self, offering: Offering, employee: Employee) -> ValidationResult:
"""Validate if an employee can be added to an offering"""
validation = ValidationResult()
if not offering.has_available_spots(): # 1
validation.add_error("Offering has no available spots.")
times_participant_took_the_training = self._trainings.count_participations(
employee, offering.training
)
if times_participant_took_the_training >= 3: # 2
validation.add_error("Participant can't take the training again.")
if offering.is_employee_registered(employee):
validation.add_error("Participant already in this offering.")
return validationDDD(Domain-Driven Design)와 클린 아키텍처에서는 도메인 서비스와 애플리케이션 서비스를 명확히 구분할 것을 권장한다.
- 애플리케이션 서비스는 작업을 조정하는 책임만을 가지며, 비즈니스 규칙을 포함하지 않는다. 즉, 외부 요청을 받아 도메인 객체를 호출하고 그 결과를 반환하거나 후속 작업을 조정하는 역할에 집중한다.
- 반면, 도메인 서비스는 도메인 내의 중요한 비즈니스 규칙을 담는 위치다. 특히 도메인 엔티티만으로 표현하기 어렵거나 여러 엔티티가 협력해야만 정의 가능한 로직은 도메인 서비스에 위치시킨다.
이렇게 제어 흐름과 비즈니스 로직을 명확히 분리하면 도메인 모델의 순수성과 코드 유지 보수성이 향상된다.
그러나 필자는 처음부터 이 분리를 강박적으로 지키기보다는, 단순한 서비스 코드 안에 제어와 로직을 함께 담아 빠르게 구현하는 방식을 선택한다.
즉, 처음엔 하나의 서비스가 애플리케이션과 도메인 역할을 모두 수행하게 한 뒤, 코드가 점차 커지고 복잡성이 증가하면 그때서야 역할을 분리하는 점진적 리팩터링을 제안한다. 이는 실용주의적인 접근으로, 지나치게 이른 추상화와 과도한 레이어 분리를 피하고, 현실적인 개발 흐름을 존중한 방식이다.
[ 상태 확인을 캡슐화하라 ]
객체의 상태 확인은 그 자체로도 캡슐화되어야 한다. 단순히 속성 값을 외부로 노출하기보다는, 객체 내부에서 판단 가능한 책임을 맡기고, 클라이언트는 그 판단 결과만 신뢰하도록 해야 한다.
복잡한 구조일수록 상태 확인 로직이 분산되기 쉽고, 이로 인해 "샷건 수술(Shotgun Surgery)" 현상이 발생할 수 있다.
이는 어떤 기능 변경이 시스템 여러 곳의 코드를 동시에 수정하게 만드는 대표적인 안티패턴이다 (Wikipedia - Shotgun Surgery).
1. 명령하라, 질문하지 마라!
OOP의 고전적인 원칙인 Tell, Don’t Ask는 마틴 파울러가 강조한 철학으로, 객체에게 데이터를 꺼내와서 외부에서 판단하게 하지 말고, 객체에게 무엇을 해야 할지를 명령하라는 뜻이다.
즉, if (obj.canDoX()) { obj.doX(); }와 같은 패턴은 obj.tryToDoX()처럼 하나의 메시지로 통합하는 것이 좋다.
이 원칙은 객체의 내부 구현을 숨기고, 역할 중심의 인터페이스를 설계하는 데 핵심이 된다.
[ 필요한 게터와 세터만 제공하라 ]
객체의 캡슐화를 유지하려면, 게터(getter)와 세터(setter)를 남발해서는 안 된다.
게터를 통해 내부 상태를 지나치게 노출하거나, 세터를 통해 객체 외부에서 무분별하게 값을 변경하게 되면 객체가 스스로의 일관성을 책임지기 어려워진다.
(특히나 python 에서도 이걸 좀 잘 생각해야 한다. 중요한 것들을 마냥 attribute 로 접근해서 휘젓고 다니지 못하게 해야 한다!)
1. 상태를 변경하지 않고 클라이언트에 너무 많은 정보를 노출하지 않는 게터
CQS(Command-Query Separation) 원칙에 따르면, 메서드는 명령(command) 또는 조회(query) 중 하나만 수행해야 한다.
- 명령은 상태를 변경하지만 값을 반환하지 않아야 하고,
- 쿼리는 값을 반환하지만 상태를 변경하지 않아야 한다.
이 원칙을 지키면, 예측 가능한 인터페이스 설계가 가능해지고, 사이드 이펙트를 방지할 수 있다.
객체의 상태를 외부에서 해석하게 하지 말고, 그 의미를 추상화한 메서드를 제공하는 것이 바람직하다.
예를 들어 hasAvailableSpots()는 availableSpots > 0이라는 내부 판단을 외부에 감추면서도 의미를 정확히 전달한다.
2. 세터는 객체를 설명하는 속성에만 사용한다
객체의 핵심 상태나 일관성이 중요한 필드에는 세터를 제공해서는 안 된다.
대신, 의미 있는 메서드를 통해 의도를 표현하고, 내부에서 상태 변경과 유효성 검사를 함께 수행하는 방식이 좋다.
예를 들어, setAvailableSpots(int) 같은 메서드보다는 addEmployee(Employee)처럼 도메인 맥락에 맞는 행위 중심 메서드가 더 안전하고 명확하다.
[ 객체 집단의 불변 조건을 보장하도록 애그리게이트를 모델링하라 ]
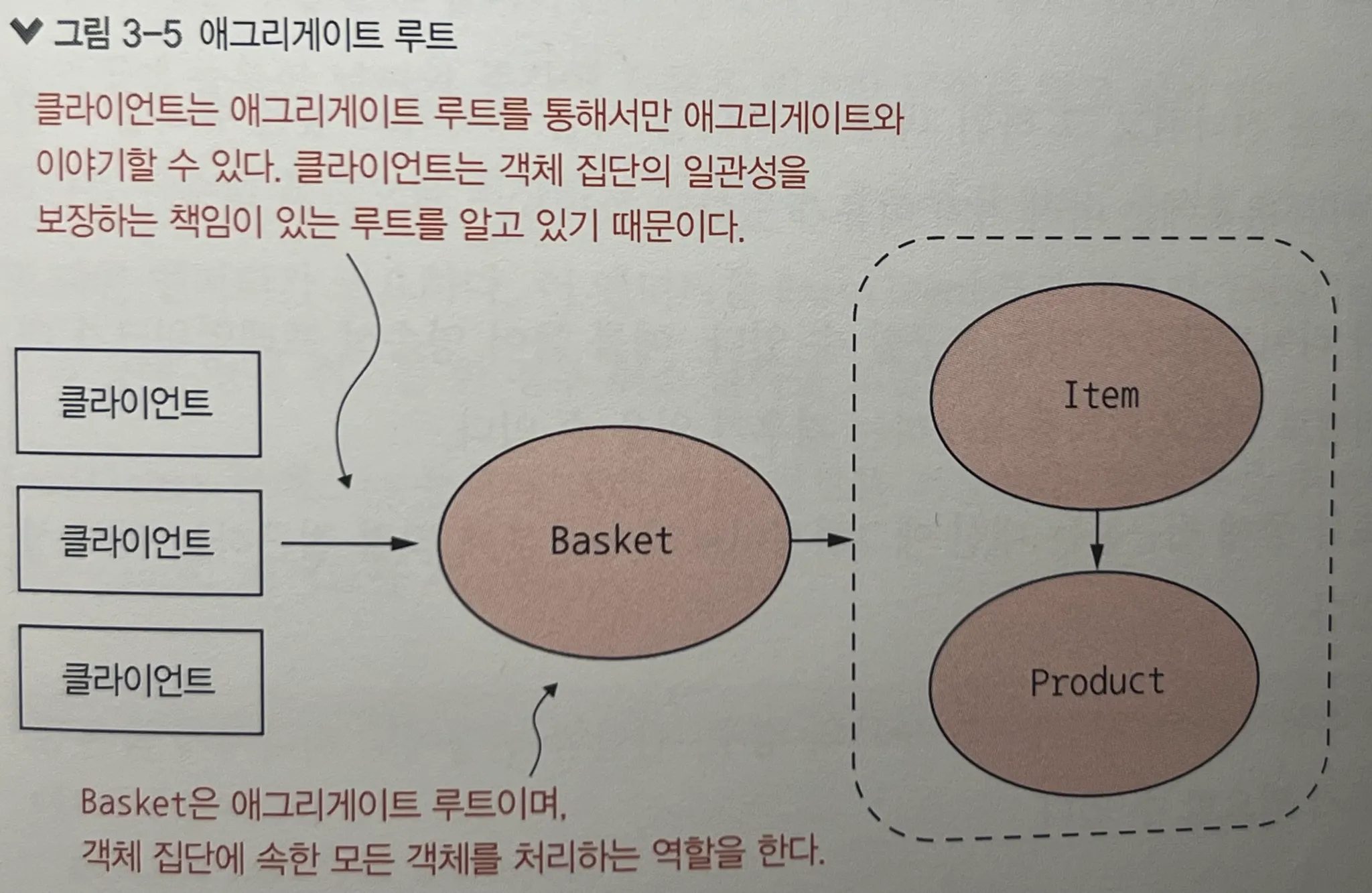
객체 집단의 일관성을 보장하기 위해서는 애그리게이트라는 구조적 단위를 설계해야 한다. DDD에서 애그리게이트는 관련된 객체들을 하나로 묶고, 그 집단의 일관성을 유지하는 단위이며, 이 집단의 대표로서 애그리게이트 루트(aggregate root) 가 존재한다.
애그리게이트 루트는 다음과 같은 역할을 수행한다:
- 클라이언트는 루트에만 접근할 수 있다.
- 루트 객체를 통해서만 내부 객체의 상태가 변경된다.
- 루트의 허가 없이는 하위 객체를 직접 변경할 수 없다.
- 모든 클라이언트는 애그리게이트 루트에 대한 참조만 유지해야 하며, 하위 객체에 대한 참조는 허용되지 않는다.
이것은 단순한 캡슐화(encapsulation) 가 아니라, 도메인 모델에서 일관성(consistency) 을 강제하기 위한 핵심 원칙이다.
또한, 객체를 데이터베이스에 저장할 때도 루트 단위로 저장 및 조회해야 하며, 루트 객체마다 하나의 리포지터리(Repository) 또는 DAO(Data Access Object)가 있어야 한다.
내부 구성 객체가 아니라 루트를 중심으로 트랜잭션과 상태 변경이 관리되는 것이다.
1. 애그리게이트 루트의 규칙을 깨지 마라
실제 개발 과정에서는 하위 객체 중 하나만 빠르게 수정하고 싶어지는 유혹이 발생할 수 있다.
예를 들어:
- 성능상의 이유로 루트를 통하지 않고 하위 객체에 직접 접근하고 싶을 때
- 사용하는 프레임워크나 라이브러리가 내부 객체에 직접 접근하게 만들 때
- 깊은 객체 트리를 구성한 경우, 루트를 통해 접근하면 보일러플레이트 코드가 많아지는 경우 등
이런 경우에도 루트를 우회하지 말고, 설계 규칙을 우선 유지하는 것이 이상적이다. 그러나 저자는 여기서 질문을 던진다:
"이 규칙이 과연 불변의 진리인가?"
상황에 따라서는 성능, 단순성, 유지보수성 등을 이유로 트레이드오프가 필요할 수 있음을 인정하고, 현실적인 타협점을 만드는 유연함도 중요하다고 지적한다.
2. 예제: Offering 애그리게이트
class Offering:
"""Represents a training offering with enrollment management"""
def __init__(
self,
training: Training,
date_: date,
maximum_number_of_attendees: int,
):
self._id: int = None
self._training = training
self._date = date_
self._enrollments: List[Enrollment] = [] # 1
self._maximum_number_of_attendees = maximum_number_of_attendees
self._available_spots = maximum_number_of_attendees
def enroll(self, employee: Employee) -> None: # 2
"""Enroll an employee in the offering"""
if not self.has_available_spots():
raise OfferingIsFullException()
now = date.today()
self._enrollments.append(Enrollment(employee, now))
self._available_spots -= 1
def cancel(self, employee: Employee) -> None: # 3
"""Cancel an employee's enrollment in the offering"""
enrollment_to_cancel = self._find_enrollment_of(employee)
if enrollment_to_cancel is None:
raise EmployeeNotEnrolledException()
now = date.today()
enrollment_to_cancel.cancel(now)
self._available_spots += 1
def _find_enrollment_of(self, employee: Employee) -> Optional[Enrollment]: # 4
"""Find the enrollment for a specific employee"""
for enrollment in self._enrollments:
if enrollment.employee == employee:
return enrollment
return None
def has_available_spots(self) -> bool:
"""Check if there are available spots in the offering"""
return self._available_spots > 0
@property
def training(self) -> Training:
"""Get the training for this offering"""
return self._training
def is_employee_registered(self, employee: Employee) -> bool: # 5
"""Check if an employee is registered for this offering"""
return any(enrollment.employee == employee for enrollment in self._enrollments)이 Offering 클래스는 애그리게이트 루트로서 다음과 같은 역할을 수행하고 있다
- 1)
enroll()과cancel()은 외부에서 호출되는 메서드이며, 내부 상태(_enrollments,_available_spots)를 직접 변경하지 못하게 하고 모든 로직을 루트 내부에서 처리한다. - 2) 내부 데이터 구조(
List[Enrollment])에 직접 접근하지 못하게private속성으로 두고, 검색 및 조회는 루트 메서드를 통해 캡슐화한다.
이처럼 애그리게이트 루트가 모든 상태 변경의 관문 역할을 하며, 전체 집합의 일관성을 책임진다.
그러나 이 구현 방식은 등록 목록을 순회하여 특정 직원의 등록 정보를 찾는 구조이기 때문에, 참가자 수가 많아질수록 성능 저하의 우려가 있다. (6장에서 다시 다룬다.)
4장 의존성 관리하기
소프트웨어에서 의존성(Dependency) 은 피할 수 없는 개념이다. 예컨대 서비스 클래스는 여러 레포지토리(repository)와 엔터티(entity)에 의존해서 동작한다. 이 말은 곧 다른 클래스와 “결합”된다는 의미다.
우리는 지금까지 설계 상 큰 클래스 대신 작은 클래스를 사용하고, 하나의 클래스가 모든 일을 하지 않도록 신경 써 왔다. 이는 “단일 책임 원칙(SRP)”과도 연결된다. 따라서 어떤 클래스가 다른 클래스에 의존하는 것 자체는 바람직할 수 있다. 실제로 혼자 모든 걸 처리하려 하기보다 역할을 나누고 협력하는 것이 객체지향의 핵심이다.
그러나 문제는 의존이 늘어날수록, 그 중 하나의 문제가 전체로 전파될 가능성도 함께 커진다는 점이다. 그래서 의존을 무분별하게 설정하면 안 된다.
중요한 건, "이 클래스가 어떤 클래스에 의존하는가?", "그 의존이 정말 좋은 의존인가?", 이 두 가지 질문에서 의존성 관리는 출발한다.
[ 고수준 코드와 저수준 코드를 분리하라 ]
의존성 관리에서 가장 먼저 떠올려야 할 개념은 바로 고수준(high-level)과 저수준(low-level)의 구분이다.
- 고수준 코드는 “무엇을 해야 하는가(what)”에 대해 설명한다.
- 저수준 코드는 “어떻게 수행할 것인가(how)”에 대해 설명한다.
- 고수준 코드를 먼저 읽으면 전체 기능이 어떤 역할을 하는지 빠르게 이해할 수 있으며, 저수준의 변경이 고수준에 영향을 주지 않도록 구조화할 수 있다.
- 이는 추상화 수준의 차이로 설명된다. 고수준은 더 추상적이고, 따라서 더 안정적이다. 고수준이 다른 고수준에 의존한다면 변경으로 인한 영향이 적다.
[ 의존성 역전 원칙 (DIP, Dependency Inversion Principle) ]
"세부사항에 의존하지 말고, 추상화에 의존하라." 이 원칙은 단순히 “의존성을 뒤집어라”는 말이 아니다. 진짜 의미는 다음과 같다.
- 고수준 모듈은 저수준 모듈에 의존하지 말고, 공통된 추상화(인터페이스)에 의존하라.
- 저수준 모듈도 동일한 추상화에 의존하게 만들라.
이 원칙은 Robert C. Martin의 SOLID 원칙 중 하나이며, 유지보수성과 확장성을 크게 높여준다.
이 책에서도 강조되지만, 스티브 프리먼과 냇 프라이스의 『테스트 주도 개발로 배우는 객체 지향 설계와 실천』에서는 인터페이스가 구조를 얼마나 유연하게 만들어주는지 아주 명확히 보여준다. 테스트가 용이한 구조로 잘 설계하고 싶다면, DIP와 인터페이스 활용을 잘하면 좋다.
[ 고수준 코드와 저수준 코드를 분리하지 않아도 되는 경우 ]
모든 상황에서 고수준과 저수준을 무조건 분리할 필요는 없다.
예를 들어 고수준의 구현 세부 사항을 비공개 메서드(private method) 로 캡슐화할 수 있다면, 필요할 때 쉽게 내부로 이동 가능하다. 리팩터링의 기회를 엿보면서 점진적으로 개선하면 된다.
근데 절대 섞지 말아야 할 것은 인프라 코드와 비즈니스 코드 이다. 예컨대 SQL 쿼리, HTTP 호출, 메시지 전송과 같은 인프라스트럭처 세부 구현은 비즈니스 코드와 절대 한데 섞이면 안 된다.
비즈니스 로직이 외부 시스템에 직접 의존하게 되면 테스트도 어렵고, 재사용도 어렵고, 변경에도 취약해진다.
[ 예제: 메시지 처리 작업 ]
(나의 깃허브 레포 기준, python/ch4/v1/message_sender.py 위치, MessageSender)
class MessageSender:
"""Service for sending messages"""
def __init__(
self,
bot: Bot,
user_directory: UserDirectory,
repository: MessageRepository,
):
self._bot = bot
self._user_directory = user_directory
self._repository = repository
def send_messages(self) -> None:
"""Send all messages that need to be sent"""
messages_to_be_sent = self._repository.get_messages_to_be_sent()
for message_to_be_sent in messages_to_be_sent: # 1
user_id = self._user_directory.get_account(message_to_be_sent.email) # 2
self._bot.send_private_message(
user_id,
message_to_be_sent.body_in_markdown,
) # 3
message_to_be_sent.mark_as_sent() # 4이 MessageSender 클래스는 충분히 고수준이다.
Bot,UserDirectory,MessageRepository라는 인터페이스에만 의존하고 있다.- 이 인터페이스의 구체 구현체(저수준 클래스) 는 다른 곳에 있다.
- 이 구조 덕분에, 세부 구현이 바뀌더라도
MessageSender의 로직은 그대로 유지될 수 있다. MessageSender는 자신의 “관심사”에 집중할 수 있고, 각 협력자들이 “어떻게” 일하는지는 알 필요조차 없다.
[ 불필요한 세부 사항이나 요소에 의존하는 것을 피하라 ]
복잡한 시스템일수록 정보 은닉(information hiding) 의 중요성이 커진다.
여기서 말하는 정보 은닉이란 단지 “숨기자”는 차원을 넘어, 변화 가능성이 높은 요소와 그렇지 않은 요소를 구분해 의존 구조를 설계하는 것이다. 핵심은 어떤 요소가 바뀌더라도 다른 구성 요소에 파급효과를 일으키지 않도록 만드는 것. 이를 위해선 '의존성을 최소화하고, 꼭 필요한 것에만 의존하도록' 제한하는 설계가 필수적이다.
1. 여러분이 소유한 클래스만 요구하거나 반환하라
-
여기서 ‘여러분이 소유한 클래스’란 도메인 모델에 속하며, 여러분이 직접 통제하고 수정할 수 있는 클래스를 의미한다. 반대로, 외부 라이브러리나 SDK 등은 여러분의 코드 바깥에 있으며, 변경을 예측하기 어렵고 주기적으로 업데이트되는 요소들이다.
-
예를 들어 채팅 도구 SDK를 도입한다고 할 때, 이 SDK가 제공하는 클래스를 그대로 코드 전반에 퍼뜨리면, SDK의 버전이 바뀔 때마다 전방위적으로 코드를 수정해야 할 수도 있다. 즉, SDK에 정의된 클래스를 직접적으로 전달하거나 반환하는 순간, 강결합이 시작되는 것이다.
이러한 강결합을 피하기 위해선 외부 의존성과 도메인 모델 사이에 적절한 추상화 계층을 두는 것이 중요하다.
2. 클라이언트에게 필요한 것 이상을 제공하지 마라
-
하나의 도메인 엔티티를 여러 곳에서 재사용하는 것은 자연스럽고 흔한 일이다. 하지만 문제는 엔티티 전체를 노출할 때 발생한다.
-
예컨대, 어떤 클라이언트는 단지 이름과 이메일만 필요로 하지만, 전체 엔티티를 전달받게 되면, 그 엔티티의 어떤 속성이든 변경될 가능성을 갖는다. 이로 인해 의도치 않은 변경 전파와 데이터 노출 문제가 발생할 수 있다.
-
따라서, 엔티티 전체가 아닌 필요한 정보만 제공하는 것이 중요하며, 이를 실현하기 위한 대표적인 방법이 바로 클라이언트 요청과 엔티티를 분리하고, 정보를 추상화하는 것이다. DTO(Data Transfer Object)나 응답 전용 뷰 모델 같은 것들이 이에 해당한다.
[ 너무 많은 클래스에 의존하는 클래스를 분리하라 ]
예제: MessageSender 서비스 분리하기, (나의 깃허브 레포 기준, python/ch4/v2/message_sender.py 위치, MessageSender)
class MessageSender:
"""Service for sending messages via multiple channels"""
def __init__(
self,
bot: Bot,
user_directory: UserDirectory,
repository: MessageRepository,
email_sender: EmailSender, # 1
user_prefs: UserPreferences, # 1
):
self._bot = bot
self._user_directory = user_directory
self._repository = repository
self._email_sender = email_sender
self._user_prefs = user_prefs
def send_messages(self) -> None:
"""Send all messages that need to be sent"""
messages_to_be_sent = self._repository.get_messages_to_be_sent()
for message_to_be_sent in messages_to_be_sent:
user_id = self._user_directory.get_account(message_to_be_sent.email)
self._bot.send_private_message(user_id, message_to_be_sent.body_in_markdown)
if self._user_prefs.send_via_email(message_to_be_sent.email): # 2
self._email_sender.send_message(message_to_be_sent)
# 메시지를 보낸 것으로 표시한다
message_to_be_sent.mark_as_sent()- 이제 추가로, 이메일을 보내고싶어
EmailSender추가했고, 사용자가 수신 가능한지 체크하기 위해UserPreferences추가했다. - 이메일 발송 관련 로직이나 사용자 선호 설정이 변경되면
MessageSender도 변경해야 하며, 이는 SRP(Single Responsibility Principle)를 위반한 셈이다.
class MessageBot:
"""Handles sending messages through a bot interface"""
def __init__(
self,
bot: Bot,
user_directory: UserDirectory,
):
self._bot = bot
self._user_directory = user_directory
def send(self, msg: Message) -> None: # 2
"""Send a message to a user via the bot"""
user_id = self._user_directory.get_account(msg.email)
self._bot.send_private_message(user_id, msg.body_in_markdown)Bot과UserDirectory를 묶어 새로운 클래스로 만들어서 분리한다면?!- 이렇게 설계를 변경하면,
MessageSender는 더 이상 모든 세부 구현에 직접 관여하지 않고, 간접 결합된 협력자(MessageBot)를 통해 메시지를 발송하게 된다. 최종적으로 리팩터링된MessageSender는 다음과 같다:
class MessageSender:
"""
Service for sending messages via multiple channels, utilizing a MessageBot.
"""
def __init__(
self,
message_bot: MessageBot,
repository: MessageRepository,
email_sender: EmailSender, # 1
user_prefs: UserPreferences, # 1
):
self._message_bot = message_bot
self._repository = repository
self._email_sender = email_sender
self._user_prefs = user_prefs
def send_messages(self) -> None:
"""Send all messages that need to be sent."""
messages_to_be_sent = self._repository.get_messages_to_be_sent()
for message_to_be_sent in messages_to_be_sent:
self._message_bot.send(message_to_be_sent)
if self._user_prefs.send_via_email(message_to_be_sent.email): # 2
self._email_sender.send_message(message_to_be_sent)
# 메시지를 보낸 것으로 표시한다
message_to_be_sent.mark_as_sent()- 의존성이 간결해지고, 각 클래스는 자신의 책임에 충실해진다. 이 구조는 테스트 가능성과 변경 대응력을 높여주는 좋은 예시다.
[ 의존성을 주입하라(의존성 주입을 사용하라) ]
의존성 주입(DI)은 객체가 협력자(다른 객체)를 직접 생성하지 않고, 외부로부터 주입받는 설계 기법이다. 이를 통해 디자인의 유연성과 테스트의 용이성을 동시에 얻을 수 있다.
과거에는 객체 생성 비용이나 성능 문제로 인해 DI를 꺼리는 경우도 있었지만, 이제는 런타임 객체 관리 및 메모리 관리 기술이 발전했기 때문에, 주입 가능한 구조를 채택하는 것이 더 나은 선택이 되었다.
1. 상태를 변경하는 작업에 정적 메서드를 사용하지 마라
- 정적 메서드는 런타임 시점에 대체하거나 모킹(mocking)하기가 어렵기 때문에 테스트가 불가능한 구조가 된다. 상태 변경을 수반하는 로직일수록 정적 메서드를 피하고, 명시적인 객체와 메서드를 통해 의존성을 표현해야 한다.
2. 항상 협력자를 주입하라: 그 외에는 원하는 대로 하라
- 위 예시에서
MessageSender는Bot,UserDirectory,MessageRepository를 사용한다. 이들을 직접 생성하지 않고 외부에서 주입받으면, 다양한 구현체(Mock, Stub, Spy 등)로 교체가 가능해진다. - 즉, 협력자를 명시적으로 받고, 사용자는 인터페이스나 추상 타입에 의존하도록 설계하라.
3. 클래스와 의존성을 함께 생성하는 전략
- 복잡한 의존 그래프를 가진 시스템에서는 객체 생성 시점에 많은 고민이 필요하다. 이를 효율적으로 처리하기 위해선 DI 컨테이너나 프레임워크(SPRING, Google Guice 등)를 사용하는 것이 유리하다.
- 현대적인 프레임워크는 대부분 DI 설계를 기본 전제로 두고 있기 때문에, 이런 흐름을 따르는 것이 유지보수와 확장성 면에서 안정적인 선택이다.
5장 추상화 잘 디자인하기
에츠허르 데이크스트라 왈, "추상화는 모호하다는 것과 본질적으로 다르다. 추상화의 목적은 모호해지는 것이 아니라, 절대적으로 정확한 새로운 의미 수준을 만드는 것" (The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise)
이 말은 이 장 전체의 핵심을 가장 명확히 설명해준다. 추상화란 복잡한 구현을 감추는 것이 아니라, 의미를 더 정확히 드러내기 위해 불필요한 세부사항을 제거하는 것이다. 즉, 본질에 집중하고, 비본질을 과감히 덜어내는 행위가 추상화의 본질이다.
- 추상화는 개념, 기능, 프로세스를 클라이언트가 내부 메커니즘을 몰라도 이해 가능한 방식으로 설명한다.
- 본질적인 특성에 집중하고, 구현은 신경 쓰지 않으며 신경 쓸 필요도 없다.
[ 추상화와 확장 지점을 디자인하라 ]
추상화는 단순히 복잡성을 숨기는 도구가 아니라, 변화에 유연하게 대응할 수 있도록 구조를 여유 있게 설계하는 기반이 된다. 즉, 새로운 기능을 쉽게 추가하거나 기존 기능을 확장하거나 변경할 수 있도록 만든다.
1. 추상화의 필요성 식별하기
추상화는 멋있어 보인다고 도입해서는 안 된다. 불필요한 추상화는 오히려 복잡도를 증가시킬 뿐이다. 추상화를 적용하기 전에는 반드시 ‘그럴만한 이유’가 있어야 한다.
✔ 대표적 원칙: 추상화는 변화의 방향성이 명확할 때만 도입하라.
참고: Robert C. Martin (Clean Architecture)에서는 “변경의 이유가 둘 이상일 때 분리하라”는 단일 책임 원칙(SRP) 아래, 변경 가능성이 존재하는 지점에 추상화를 도입해야 한다고 강조한다. 이처럼 추상화는 목적 있는 복잡성이다.
2. 확장 지점 디자인하기
확장 지점을 설계할 때는 단순히 인터페이스를 나누는 것 이상을 고려해야 한다.
- 향후 어떤 부분이 가장 자주 변경될 것인가?
- 어떤 방식으로 확장될 가능성이 높은가?
이런 질문에 대한 답을 바탕으로 유연한 구조를 미리 설계해야 한다.
잘 설계된 확장 지점은 이후 변화에 따라 조건문이 아니라 클래스 추가로 대응할 수 있게 만들어준다.
3. 좋은 추상화의 속성
좋은 추상화는 무엇(What)과 어떻게(How)를 분리 한다.
- 클라이언트는 “무엇을 할 수 있는가”만 알면 된다.
- “어떻게 수행되는가”는 감춰져도 무방하다.
4. 추상화에서 배워라
추상화는 한 번에 완벽히 만드는 것이 아니다. 점진적으로 발전시키며 리팩터링을 반복해야 한다. 꾸준함이 결국 좋은 추상화로 이어진다.
5. 추상화에 대해 배워라
추상화를 더 잘 다루고 싶다면, 디자인 패턴은 훌륭한 교과서다.
- GoF 디자인 패턴은 다양한 추상화 사례를 담고 있다.
특히 전략, 상태, 책임 연쇄, 데코레이터, 템플릿 메서드, 커맨드 패턴 등은 행위의 변화와 확장을 위한 추상화 관점에서 매우 유용하다. - 또한, 오픈 소스 프레임워크는 실전에서 적용된 추상화의 정수다. 그 패턴과 모듈화를 분석하며 배우는 것이 가장 효과적이다.
6. 추상화와 결합
추상화와 결합도는 함께 고려되어야 한다.
- 추상화는 결합도를 낮추고 유연성을 높이는 도구이지만, 잘못하면 불필요한 의존성과 인터페이스 남용으로 결합이 오히려 증가할 수도 있다.
- 즉, "적절한 추상화 + 낮은 결합도"가 목표다.
[ 예제: 직원에게 배지 수여하기 ]
(python/ch5/v1/badge_giver.py 의 BadgeGiver)
class BadgeGiver:
"""Assigns badges to employees based on their training history"""
def give(self, employee: Employee) -> None: # 1
"""Give badges to the employee"""
self._per_training(employee)
self._per_quantity(employee)
def _per_training(self, employee: Employee) -> None:
"""Assigns badges based on specific training completions"""
trainings_taken: TrainingsTaken = employee.trainings_taken
# 품질 관련 교육을 받은 경우 배지를 받는다 # 2
if trainings_taken.has("TESTING") and trainings_taken.has("CODE QUALITY"):
self._assign(employee, Badge.QUALITY_HERO)
# 보안 관련 교육을 모두 들으면 배지를 받는다
if trainings_taken.has("SECURITY 101") and trainings_taken.has("SECURITY FOR MOBILE DEVS"):
self._assign(employee, Badge.SECURITY_COP)
# ... 다른 배치 수여 규칙들
def _per_quantity(self, employee: Employee) -> None: # 3
"""Assigns badges based on the quantity of trainings completed"""
trainings_taken: TrainingsTaken = employee.trainings_taken
if trainings_taken.total_trainings() >= 5:
self._assign(employee, Badge.FIVE_TRAININGS)
if trainings_taken.total_trainings() >= 10:
self._assign(employee, Badge.TEN_TRAININGS)
if trainings_taken.trainings_in_past_3_months() >= 3:
self._assign(employee, Badge.ON_FIRE)
def _assign(self, employee: Employee, badge: Badge) -> None:
"""Assign a badge to the employee"""
employee.win_badge(badge)Employee에게 다양한 규칙에 따라 뱃지를 수여하는class- 로직이 명확히 나뉘지 않아 변경에 취약하며, 로직 복잡성이 커지면 메서드 내부가 조건문으로 난잡해질 가능성 존재. 일단 class 단위를 쪼개보자.
(python/ch5/v2/badge_giver.py 파일 내부 class 들)
class BadgeGiver:
"""Assigns badges to employees based on their training history"""
def give(self, employee: Employee) -> None: # 1
"""Give badges to the employee by applying different badge rules"""
BadgesForTraining().give(employee)
BadgesForQuantity().give(employee)
class BadgesForTraining:
"""Applies badge rules related to specific training completions"""
def give(self, employee: Employee) -> None:
"""Assigns badges based on specific training completions"""
trainings_taken: TrainingsTaken = employee.trainings_taken
... 생략 ...
class BadgesForQuantity:
"""Applies badge rules related to the quantity of trainings completed"""
def give(self, employee: Employee) -> None: # 3
... 생략 ...- 로직이 명확하게 나뉘며, 각 책임 클래스에서의 단위 변경이 쉬움
- 하지만 여전히 로직이 많아지고 규칙이 다양해지면 복잡도는 상승
class Badge(Enum):
"""Enum representing different types of badges"""
SECURITY_COP = "SECURITY_COP"
FIVE_TRAININGS = "FIVE_TRAININGS"
TEN_TRAININGS = "TEN_TRAININGS"
ON_FIRE = "ON_FIRE"
QUALITY_HERO = "QUALITY_HERO"
class BadgeRule:
"""Interface for a badge rule"""
def give(self, employee: Employee) -> bool:
"""Determines if the badge should be given to the employee"""
pass
def badge_to_give(self) -> Badge:
"""Returns the badge associated with this rule"""
pass
class QualityHero(BadgeRule):
"""Badge rule for Quality Hero badge"""
def give(self, employee: Employee) -> bool:
trainings_taken: TrainingsTaken = employee.trainings_taken
return trainings_taken.has("TESTING") and trainings_taken.has("CODE QUALITY")
def badge_to_give(self) -> Badge:
return Badge.QUALITY_HERO
class SecurityCop(BadgeRule):
"""Badge rule for Security Cop badge"""
def give(self, employee: Employee) -> bool:
trainings_taken: TrainingsTaken = employee.trainings_taken
return trainings_taken.has("SECURITY 101") and trainings_taken.has("SECURITY FOR MOBILE DEVS")
def badge_to_give(self) -> Badge:
return Badge.SECURITY_COP
class FiveTrainings(BadgeRule):
"""Badge rule for Five Trainings badge"""
def give(self, employee: Employee) -> bool:
trainings_taken: TrainingsTaken = employee.trainings_taken
return trainings_taken.total_trainings() >= 5
def badge_to_give(self) -> Badge:
return Badge.FIVE_TRAININGS
class TenTrainings(BadgeRule):
"""Badge rule for Ten Trainings badge"""
def give(self, employee: Employee) -> bool:
trainings_taken: TrainingsTaken = employee.trainings_taken
return trainings_taken.total_trainings() >= 10
def badge_to_give(self) -> Badge:
return Badge.TEN_TRAININGS
class OnFire(BadgeRule):
"""Badge rule for On Fire badge"""
def give(self, employee: Employee) -> bool:
trainings_taken: TrainingsTaken = employee.trainings_taken
return trainings_taken.trainings_in_past_3_months() >= 3
def badge_to_give(self) -> Badge:
return Badge.ON_FIREBadgeRule을 추상화 해서 (python interface 없기에 ABC 활용)- ENUM 도 활용했고, 결국
BadgeGiver자체는BadgeRule에 따라give가true라면badge_to_give로 수여만 하면 된다.
class BadgeGiver:
"""Assigns badges to employees based on a list of rules"""
def __init__(self, rules: List[BadgeRule]): # 1
self._rules = rules
def give(self, employee: Employee) -> None:
"""Applies each rule to the employee and assigns badges accordingly"""
for rule in self._rules: # 2
if rule.give(employee):
employee.win_badge(rule.badge_to_give())BadgeGiver는 오직 룰을 적용하는 컨트롤러 역할만 수행하며OCP (Open-Closed Principle)를 만족시킴!
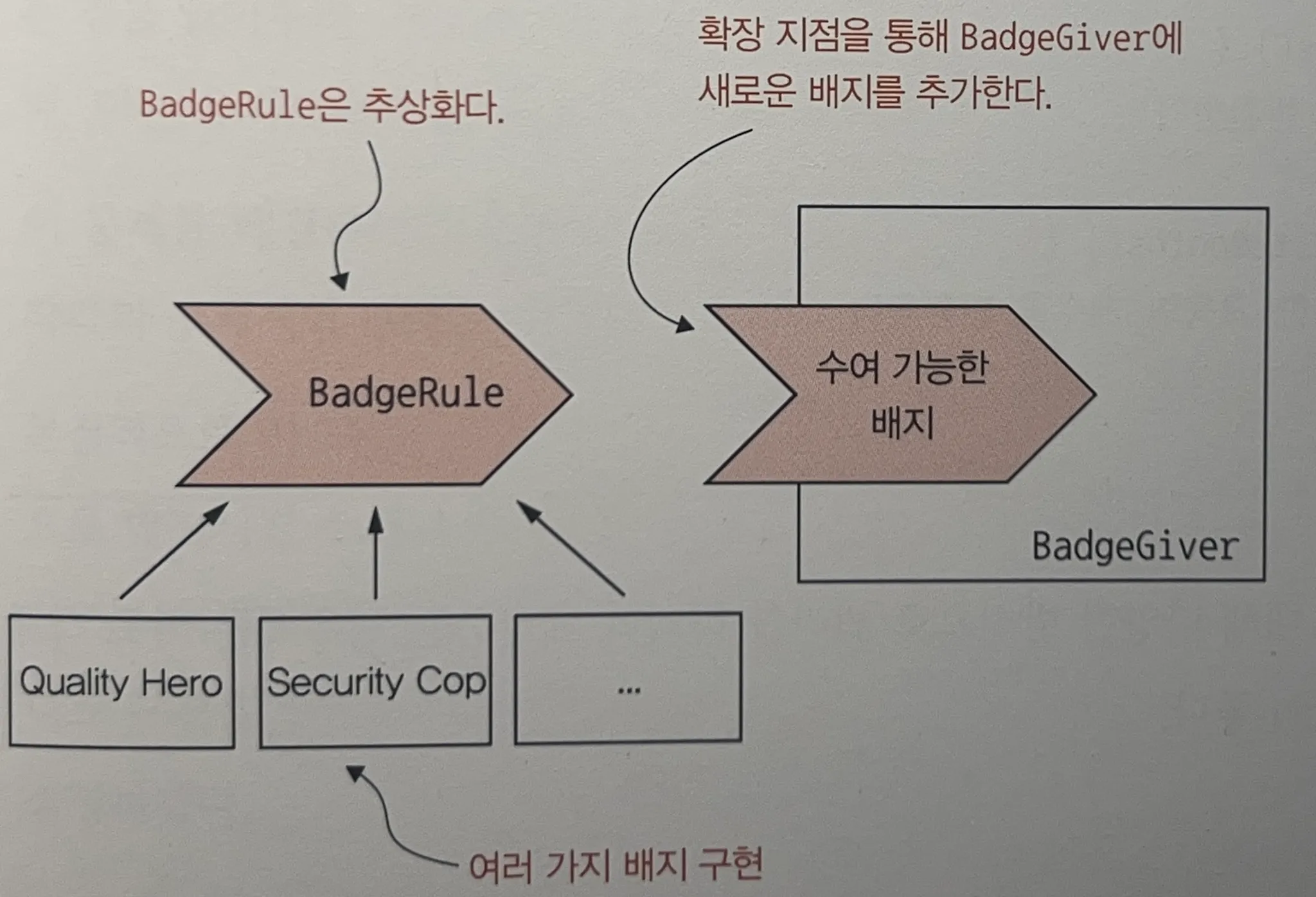
- 이 다음
BadgesForTraining자체를 팩토리 패턴과BadgeRule인터페이스 상속을 구현한 예제가 이어짐. 이는 책에서 확인하는 것을 추천.
[ 단순한 추상화를 선호하라 ]
1. 경험적 규칙
- 추상화가 꼭 필요한가? → 단순한 것이 항상 낫다.
- 추상화의 필요성이 명백하게 드러나는가? → 이쯤 되면 고려해야 한다.
- 좋은 추상화가 필요하게 되리라는 걸 안다면? → 처음부터 추상화를 두려워 말라.
2. 단순한 것이 항상 더 낫다
- 추상화는 도구이지 목표가 아니다.
- 단순함을 추구하다 보면 불필요한 추상화를 피하고, 꼭 필요한 순간에만 의미 있는 추상화를 만들 수 있다.
- if 구문으로 가득찬 코드, 클리스 등. 더욱이 "잘못된 추상화 보다 중복이 더 저렴하다" 라고 말한 사람도 있다(루비 개발자, 샌디 메츠). 하지만 중복은 잘된 추상화 보다 비용이 더 많이 든다는 점도 아주 중요한 시사점이다.
3. 이쯤 되면 추상화를 고려해야 한다
- 같은 클래스를 계속 반복적으로 수정하는가?
- 클래스가 계속 커지는 가?
- 변화를 구현하기 위해 if 조건문이 추가 되는가?
- 기존 비즈니스 규칙을 시스템의 다른 부분에 결합시키는 과정이 어거지로 이어붙이는 것 같은가?
4. 처음부터 추상화를 모델링하는 것을 두려워하지 마라
- 추상화를 사후에 도입하려 하면 더 큰 비용이 든다. 처음부터 확장성을 고려한 모델링은 오히려 단순함을 보장해준다.
- 단, 미리 설계하되, 지금 필요한 만큼만 구현하라. 추상화를 위한 추상화는 독이다.
6장 외부 의존성과 인프라 다루기
[ 도메인 코드와 인프라를 분리하라 ]
인프라와 도메인 코드를 분리하는 이유는 단순히 아키텍처적 우아함을 위한 것이 아니다. 실제로 외부의 세부 사항이 시스템 전반에 영향을 미치지 않도록 하기 위해, 그리고 테스트 가능성을 높이고 유지보수성을 확보하기 위해 반드시 필요하다.
-
외부 세부 사항은 테스트를 어렵게 한다.
예컨대 AWS SDK, 타사 데이터베이스 클라이언트처럼 외부와 직접 통신하는 코드가 프로젝트 곳곳에 퍼져 있다면, 테스트 시에는 이를 일일이 mocking 해야 하며, 환경이 조금만 바뀌어도 문제가 생길 수 있다. -
캡슐화 없이는 외부 라이브러리의 변경에도 영향을 받는다.
외부 API는 버전이 올라가며 추상화가 바뀌고, 리턴 구조가 달라질 수 있다. 이 변화가 전파되지 않도록 하려면 중간에 캡슐화 계층이 필요하다. -
인프라 코드는 저수준이다.
DB, 메시지 큐, 외부 API 등은 시스템 아키텍처의 하부를 구성하며, 이들이 변경되었을 때 영향도를 최소화하려면 추상화와 분리가 선행되어야 한다.
잘 된 추상화는 인프라 세부 사항을 감추고, 시스템의 다른 부분이 변경 없이 그대로 동작할 수 있도록 해준다. 그러나 DBMS → SQS 로 바뀌는 수준의 변화까지 무리 없이 감추기란 어렵다.
결국 어느 수준까지 분리할 것인가, 어떤 방식으로 분리할 것인가에 따라 트레이드오프가 필연적으로 존재한다.
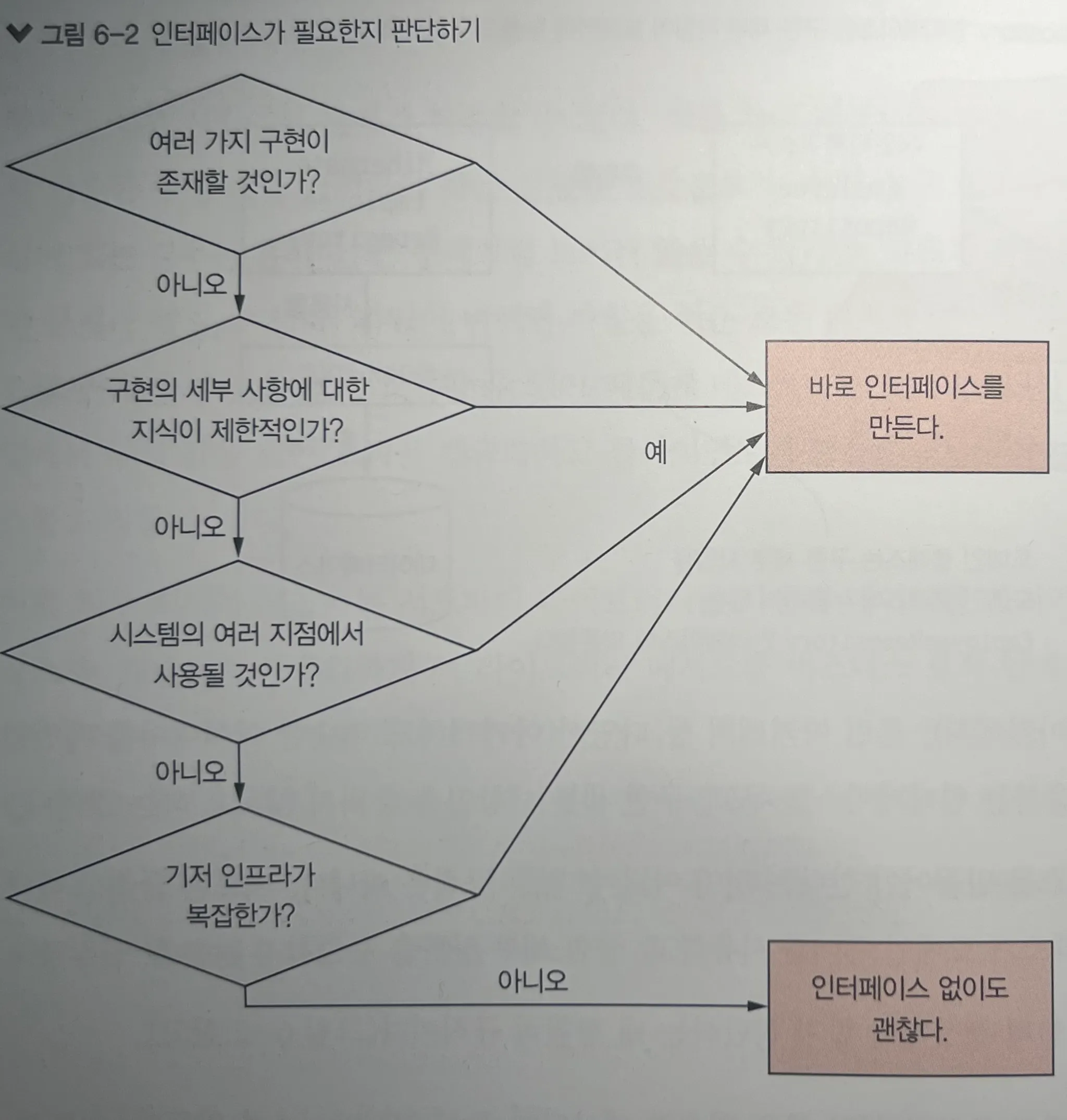
1. 인터페이스가 필요한가?
다음 조건 중 하나라도 해당된다면 인터페이스를 도입하자!
-
동일 인프라에 대해 여러 구현이 예상될 경우
예:EmployeeRepository를 RDB, NoSQL, Mock 등 다양한 방식으로 구현 -
인프라 구조에 대한 지식이 아직 부족할 경우
추상적인 인터페이스를 만들고 구체 구현은 나중에 교체 가능 -
여러 군데에서 동일 인프라를 사용하는데, 공통화되지 않은 경우
인터페이스를 도입하면 무거운 클래스 대신 가벼운 추상 계층으로 관리 가능
하지만 주의할 점은, 기저 인프라가 복잡할수록 세부사항이 누출되기 쉽고, 이를 막는 것도 쉽지 않다는 점이다.
2. 코드에서는 세부 사항을 숨기고, 개발자에게는 숨기지 마라
외부에 공개되는 코드 수준에서는 인프라의 디테일을 철저히 숨겨야 한다. 하지만 팀 내부나 문서에서는 그 디테일을 명확히 공유하고, 숨기지 않아야 한다. 그래야 변경 시 충돌과 오해가 줄어든다.
즉 개발자에게 까지 제발 숨기지 말라는 것이다. 이게 문서화를 통해서든, 가이드를 통해서든 말이다.
3. 인프라 변경하기: 괜한 걱정일까, 실제로 일어날까?
아주 솔직하게 DBMS 종류가 바뀌는 사건들은 마냥 흔한 일은 아니다. 하지만 인프라 변경은 현실이다. 단일 서버에서 RDS로, MySQL에서 Postgres로, 자체 이메일 시스템에서 SES로… 등의 변화는 "생각 보다 매우 빈번" 하다.
더욱이 서비스가 성장한다면 말이다. "변경은 없을 것이다"는 단순한 낙관주의다. 따라서 변경 가능성을 가정하고 구조를 짜야 한다.
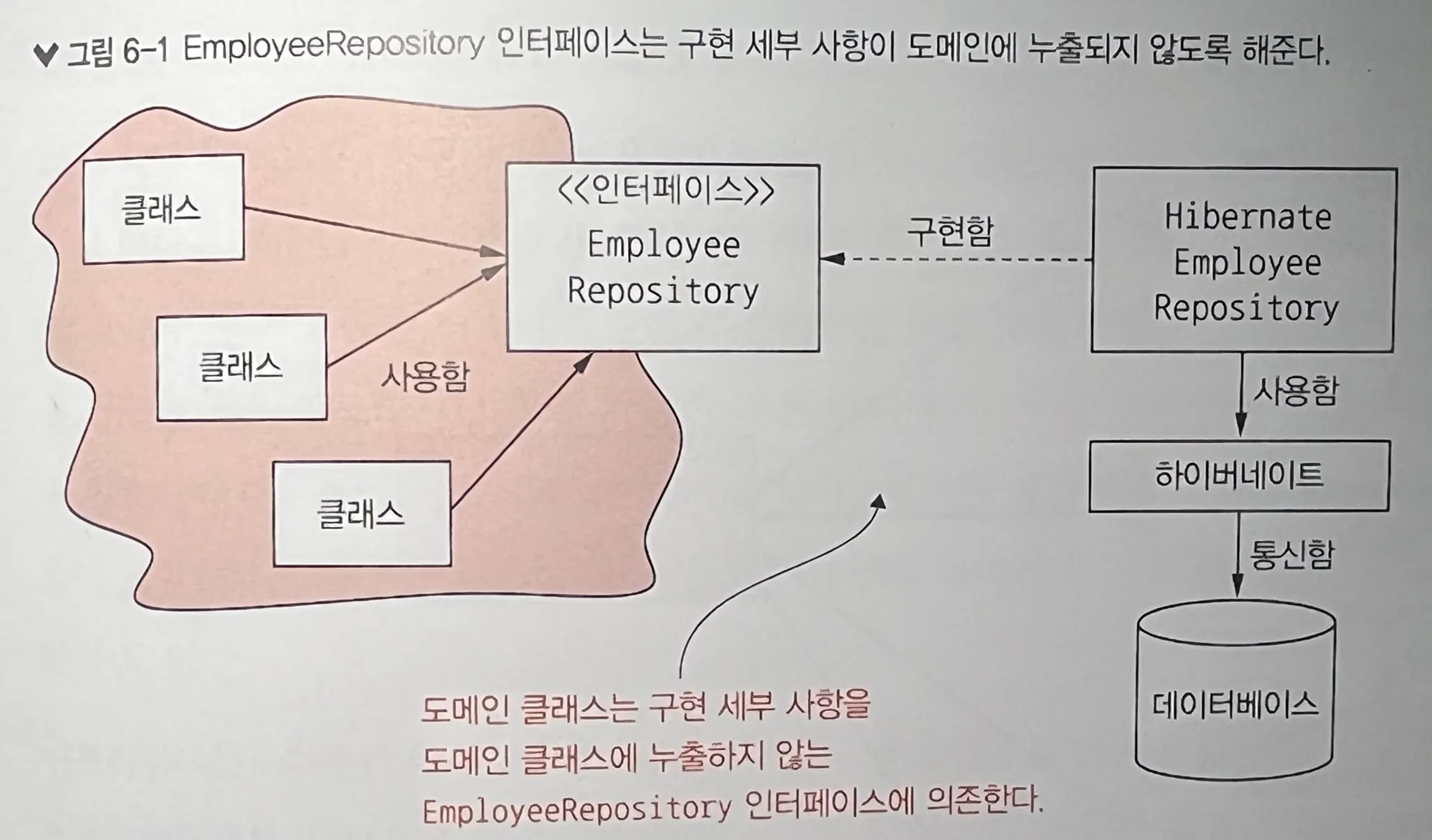
4. 예제: 데이터베이스 접근과 메시지 봇
class EmployeeRepository(ABC):
"""Abstract repository interface for Employee operations"""
@abstractmethod
def find_by_email(self, email: str) -> Optional[Employee]:
"""Find employee by email address"""
pass
@abstractmethod
def save(self, employee: Employee) -> None:
"""Save employee to repository"""
pass
@abstractmethod
def update(self, employee: Employee) -> None:
"""Update existing employee in repository"""
pass
class HibernateEmployeeRepository(EmployeeRepository):
"""Employee repository implementation simulating Hibernate interaction"""
def __init__(self, session: MockSession):
self._cache: Cache[Employee, str] = Cache()
self._session = session
def find_by_id(self, id_: int) -> Optional[Employee]:
"""Find an employee by their ID"""
return self._session.find(Employee, id_)
def find_by_last_name(self, last_name: str) -> Set[Employee]: # 2
"""Find employees by their last name, using cache"""
if not self._cache.contains(last_name):
# Simulate database query
result_list = self._session.create_query(
"from Employee e where e.lastName = :lastName", Employee
).set_parameter(":lastName", last_name).get_result_list()
self._cache.add_all(last_name, set(result_list))
return self._cache.get(last_name)
def find_by_email(self, email: str) -> Optional[Employee]:
"""Find an employee by their email address"""
return self._session.create_query(
"from Employee e where e.email = :email", Employee
).set_parameter(":email", email).get_single_result_or_null()
def save(self, employee: Employee) -> None:
"""Save a new employee"""
self._session.persist(employee)
def update(self, employee: Employee) -> None:
"""Update an existing employee"""
self._session.merge(employee)- 이 예제는
EmployeeRepository라는 추상 계층을 통해 도메인과 인프라를 분리하고 있다. - 특정 로직에만
cache를 추가하고 싶은 경우,HibernateEmployeeRepository내에서_cache필드만 추가(활용)하면 된다. - 사실 요즘 완벽한 도메인 분리는 못해도 무조건
layered pattern까지는 지키려고 노력하는데, 이도 비슷한 궤
[ 인프라를 최대한 활용하라 ]
요즘 당연하게 데이터 영속성을 위해 DBMS 를 사용하고, API를 효율적으로 만들기 위해 웹F/W 에 의존한다.
그리고 최근 몇십 년 동안 폭발적으로 발전해왔다. 근데 class 디자인에 맞지 않는다는 이유로 기능 무시하는 것은 아까운 일 이다.
1. 디자인을 망가뜨리지 않도록 최선을 다하라
-
디자인에서 모든 선택에 트레이드오프 관계가 있다. 해당 예제 등록 취소하기는 에그리게이트를 우회하려는 것에 대해 다룬다.
-
특히
cancel이라는 method 는 오퍼링 내의 모든 등록 내용 확인하는 로직이 있었기 때문
순회를 하지말고, 여기서 DBMS 를 활용해 직접 등록 정보를 다 가져와서 cancel 처리하게 하면 됨. (이를 리펙토링 하는 과정을 직접 책 보면서 따라가는 것 추천.)
[ 자신이 소유한 것에만 의존하라 ]
외부 라이브러리, SDK 등을 직접 사용하는 대신, 반드시 내부 래퍼 또는 어댑터를 두자. 이를 통해 다음과 같은 장점이 생긴다.
- 외부 변경에 대한 완충 작용
- 도메인 코드에서 의미 있는 인터페이스 제공
- 테스트 용이성
결과적으로 서드파티 의존성이 코드 전반에 퍼지는 것을 방지 한다. 통제하기 어려운 것이 내 손안에 들어온다!
1. 프레임워크와 싸우지 마라
(개인적으로 매우 와닿았음 ㅋㅋ)
- 모든 의존성과 완전한 분리는 실현 불가능한 목표 이다. 오히려 완전한 분리가 코드 복잡도의 폭발적 증가 를 낳을 수 있다.
- 즉, 프레임워크를 무시하거나 거스르는 것이 곧 좋은 아키텍처는 아니다.
- 도메인과 프레임워크는 분리하되, 프레임워크의 강점을 적절히 활용하는 타협이 필요하다.
2. 간접 누출에 주의하라
- ORM 생각해보자. 다들 object & orm method 의 모든 부분이 raw query 로 어떻게 사용되는지 완벽하게 파악하고 사용하는가?
- 하지만 ORM의 기능을 무비판적으로 사용하면 성능이나 트랜잭션 이슈가 발생할 수 있다.
- 추상화의 깊이를 항상 점검하고, 불필요한 간접 누출을 경계하자.
[ 저수준 인프라 오류를 고수준 도메인 오류로 캡슐화하라 ]
저수준 인프라 라이브러리는 다음과 같은 문제를 가진다.
- 고유한 error code 체계
- raw exception 노출
- 메시지 구조가 도메인에 맞지 않음
따라서 다음과 같이 바꿔야 한다
- 외부 오류 → 의미 있는 도메인 오류 (
EmailAlreadyRegisteredError,DataConsistencyError등) - 이 과정에서 도메인 계층은 외부 시스템의 오류를 전혀 알 필요가 없어진다.
애플리케이션은 이를 기반으로 UX 수준에서 적절한 피드백을 구성 가능해진다!
7장 모듈화 달성하기
6장까지 다뤘던 단순성, 일관성 유지, 좋은 추상화, 확장 지점, 인프라 세부 사항의 캡슐화와 격리 는 사실상 모두 모듈화라는 큰 주제 아래 자연스럽게 수렴된다. 이 장은 그러한 원칙들을 모듈 수준에서 구현하고 지켜내는 방법에 대한 이야기다.
-
캡슐화의 확장
우리가 데이터를 클래스 내부에 감추는 것처럼, 모듈 또한 연관된 기능들을 내부에 감추고 외부에는 필요한 것만 드러내야 한다. 이 때의 '모듈'은 단순한 코드 묶음이 아니라, 구조적 경계이자, 소프트웨어의 관리 단위다. -
복잡한 기능 위에 단순한 인터페이스 제공
좋은 모듈은 클라이언트 입장에서 쓰기 쉬워야 한다. 복잡한 로직은 내부에 숨기고, 이를 감싸는 단순하고 명확한 API만 노출해야 한다. 이는 단순한 함수 수준이 아니라, 모듈 전체 수준에서도 동일하게 적용된다. -
내부 변경이 외부에 영향을 주지 않도록
좋은 모듈은 내부 세부 사항이 변경되더라도, 이를 사용하는 클라이언트 코드가 변경되지 않아도 되도록 설계되어야 한다. 즉, 모듈은 클라이언트를 보호하는 방패가 되어야 한다. -
안정적이고 하위 호환 가능한 인터페이스
모듈의 가장 핵심은 일관된 인터페이스 설계다. 이 인터페이스가 깨질 경우, 모듈을 사용하는 수많은 클라이언트가 일제히 영향을 받는다. 따라서 명확하고 지속 가능한 통신 방식이 필수적이다. -
확장 지점의 설계
시스템이 커질수록 기능 추가와 변형이 요구된다. 이때 모듈은 유연한 확장을 허용하되, 그 방식은 일관되고 예측 가능해야 한다. 즉, 확장 지점은 있어야 하지만, 아무나 아무 데나 꽂을 수 있게 해서는 안 된다. -
모듈 간 세부 사항 비공개화
모듈은 자신의 내부를 감추고, 다른 모듈의 내부를 알지 않아야 한다. 그래야만 모듈 간 결합도를 줄일 수 있으며, 독립적으로 변경과 진화를 꾀할 수 있다. -
클라이언트는 누출된 세부 사항에 의존하지 않도록 주의
만약 어떤 모듈이 내부 구현을 의도치 않게 노출한다면, 이를 사용하는 측에서 그 부분에 의존하게 될 수 있다. 이 의존성은 이후 변경 시 ‘모듈의 구현 변경이 전파되는 리스크’를 낳는다. -
모듈의 명확한 소유권과 규칙
여러 팀이 함께 시스템을 만들 때, 모듈이 분리되어 있지 않으면 갈등이 생기기 쉽다. 어떤 코드에 누가 책임을 질지 모호해지기 때문이다. 명확한 소유권과 규칙이 있는 모듈은 조직적 커뮤니케이션 비용까지 줄여준다.
사견을 덧붙이자면, 모듈화는 어떤 기법이라기보다는 앞선 장들의 내용을 충분히 소화한 결과물에 가깝다. 단순히 "모듈을 설계하자"는 의도를 넘어서, 좋은 코드와 아키텍처를 고민하다 보면 결과적으로 자연스럽게 형성되는 단위가 모듈이라는 생각이다.
또한, 나의 경우 모듈화를 할 때 마치 내가 오픈소스를 만들고 있다는 상상을 해보는 것도 꽤 도움이 되었다. 일종의 라이브러리나 SDK를 만든다고 생각하고, 사용자 입장에서 인터페이스를 설계하다 보면 오히려 더 집중하게 되고, 실용적인 결과물을 만들 수 있게 된다.
8장 실용적인 접근법
✔ 실용적으로 접근하되, 딱 필요한 만큼만
완벽한 설계보다는 지금 필요한 만큼의 단순한 해결책이 우선이다. 미래를 대비한 과도한 설계는 실제로 쓰이지도 않을 가능성이 높고, 오히려 현재를 더 복잡하게 만들 수 있다. 실용성은 포기하지 않는 선에서 절제된 추상화와 설계가 요구된다.
✔ 과감하게 리팩터링하되, 단 작은 단위로 나눠서
리팩터링은 주저해서는 안 되는 작업이지만, 동시에 무작정 갈아엎는 식이어서는 안 된다. 이 장에서는 리팩터링을 '과감하게' 하되, 안전하게 작은 단위로 쪼개서 실행할 것을 강조한다. 시스템 전체를 한 번에 뒤엎는 방식이 아니라, 변화 가능성을 감지하고 작은 확신들로부터 개선을 시작하는 태도가 중요하다.
✔ 코드가 완벽하지 않다는 사실을 받아들여라
모든 코드가 완벽할 수는 없으며, 완벽을 추구하다가 실제 문제 해결이 늦어지는 일은 피해야 한다. 때로는 어설픈 코드라도 현재 문제를 해결하는 것이 더 가치 있을 수 있다. 물론 그 임시방편이 '영원한 기술 부채'가 되지 않도록, 지속적으로 개선할 수 있는 여지를 남겨두는 태도가 필요하다.
✔ 재디자인을 고려하라
지속적인 기능 추가와 요구사항 변화 속에서, 기존 구조가 더 이상 적절하지 않게 되는 시점이 온다. 그럴 때는 과감하게 재디자인을 검토해야 한다. 이는 리팩터링보다 큰 결정이지만, 때로는 시스템의 생명력을 연장시키는 유일한 선택이 되기도 한다. 단, 재디자인은 개인의 열정이 아니라, 정량적이고 조직적인 판단에 기반해야 한다.
✔ 여러분은 주니어 개발자들에 대한 책임이 있다
시스템의 구조와 코드는 단지 기계가 해석할 수 있도록 짜는 것이 아니라, 함께 일하는 사람들—특히 주니어 개발자—가 이해할 수 있도록 짜야 한다. 좋은 설계는 곧 좋은 학습 자료이자 멘토링 수단이 된다. 코드가 혼란스럽고 복잡할수록, 팀 전체의 성장 가능성은 낮아진다. 경험 많은 개발자일수록, 이 책임을 자각해야 한다.
