리눅스 서버 상태 알아보기
리눅스 서버의 사양(스펙)과 상태가 어떻게 되는지 파악해 보자. 그리고 상태가 어떤 의미를 가지는지, 또 로그에 대해서는 어떻게 접근해야할지 알아보자.
1. 장비 스펙 / 리눅스 서버 사양 제대로 체크해보기
dmidecode
- 컴퓨터의 DMI(Desktop Management Interface) 를 사람이 읽을 수 있게 dumping 하는 명령어이다. 시스템 정보를 자세하게 출력해 주기 때문에 유용한 명령어다!
- 명령어만 그대로 사용하면 너무 많은 정보가 나오기 때문에 파이프(|) 를 통해 다른 명령어를 이용하자. ex) dmisdecode | more
- dmisdecode 더 활용하기
1) 서버 모델 확인
dmidecode | grep Name2) 시리얼번호 확인
dmidecode | grep Serial3) CPU 전체 정보 확인
sudo dmidecode -t processor # CPU H/W 정보 -> root 권한 필요
cat /proc/cpuinfo # cpu 전체 코어 출력, nproc는 코어 수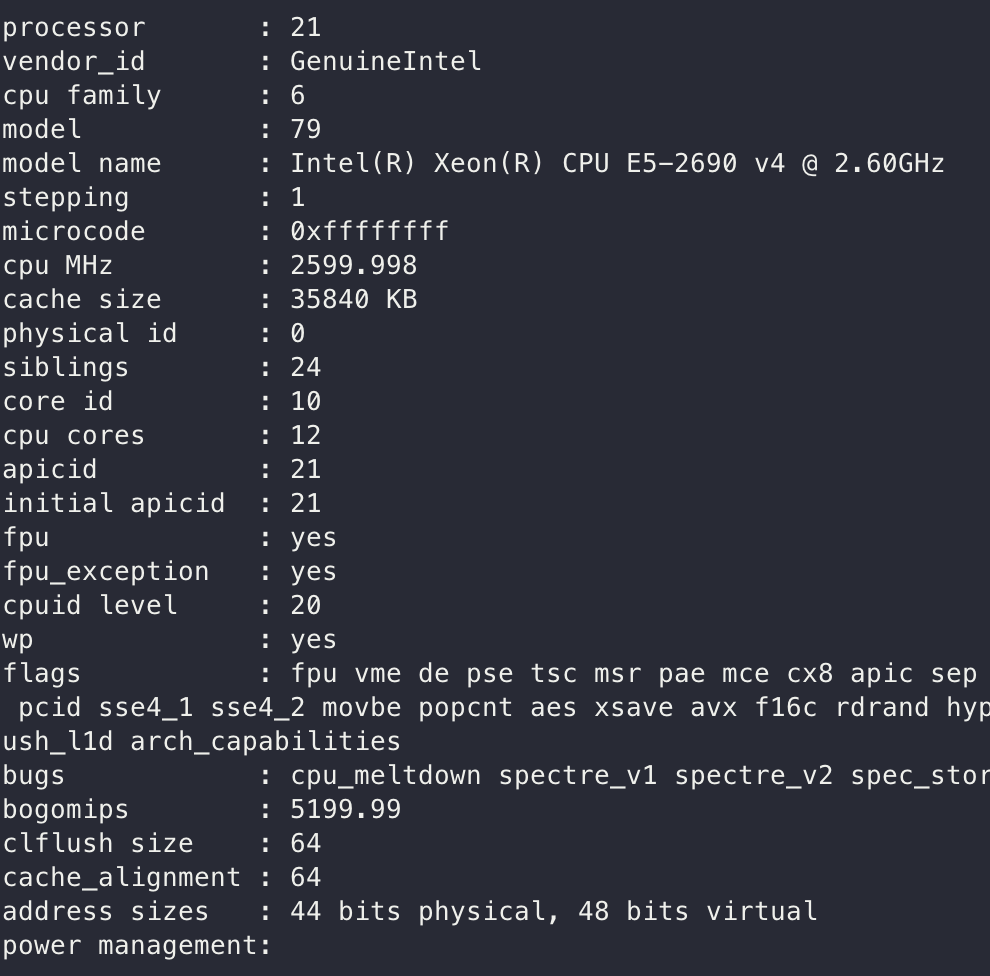
more about cpu info
cat /proc/cpuinfo |grep "physical id" |sort |uniqCPU 칩 (H/W) 개수, 피지컬ID로 구분cat /proc/cpuinfo |grep "cpu cores" |sort |uniqCPU 칩에 할당 된 코어 개수cat /proc/cpuinfo |grep -c "cpu cores"CPU 칩에 할당된 총 코어 개수 -> 가상 코어 포함 => 하이퍼스레딩 때문cat /proc/cpuinfo |grep "sibl" |sort |uniqsiblings 개수가 할당 된 코어 개수 2배라면, 하이퍼스레딩 enable상태
4) 메모리 정보 확인
cat /proc/meminfo # 메모리 전체 인포메이션
free # free 메모리만 체크 5) 리눅스 정보, 하드웨어 장비 확인
cat /etc/sysconfig/hwconf # 전체 하드웨어 장비 확인
# 마우스, GP, NET
cat /etc/sysconfig/hwconf | grep Mouse
cat /etc/sysconfig/hwconf | grep Graphic
cat /etc/sysconfig/hwconf | grep Net
cat /etc/*release # 배포판 무엇인지 확인하기
cat /proc/version # 리눅스 커널 버전
uname -r
6) ubuntu P.S.
df -h # 논리 디스크 파티션, df는 진짜 많이 사용한다! du 또한 비슷하게 사용
fdisk -l # 물리 디스크
# CPU, 메모리, 메인보드, 바이오스 등등 정보를 lshw 통해 체크 + -html로 output을 만들어서 확인가능
lshw -html > Hardware.html
# 캐릭터 디바이스, 블록디바이스 확인가능
cat /proc/devices- 사실 위와 같은 사항을 아주 한 방에 쉽게 보여주는 패키지도 존재한다. 하지만, 우리가 오픈소스인 '리눅스' 자체를 이해할 때에는 라이브러리(패키지)에 의존하는 방법은 좋지 않다고 생각한다.
- 조금 아이러니 하지만 위 와 다른 맥락으로는, 유용한 유틸 패키지들은 배포판에 포함되기도 한다 ^^,,
2. 서버 상태 체크하기
1) 무엇을 확인해야 하나?
- 이 부분은 지극히 주관의 시작이다. 왜냐면 리눅스 서버에서 무엇을 서비스하냐, 무엇이 있냐에 따라 굉장히 많은 부분이 달라지기 때문이다. 즉, "무엇이 문제냐?" 를 빠르게 파악하는 스탠스가 훨씬 유리할 것 같다.
- 그리고 기업에서 사용하는 솔루션의 경우에는 모니터링 페이지도 포함되는 경우가 많아 직접 서버 자체 상태를 살펴볼때가 그렇게 많지도 않을 수 있다.
2) top 활용하기
- top은 일단 급하게 어떤 상황이 일어나는지 빠르게 파악이 가능하다.
- CPU, Memory, Process, Loadave- 등을 한 번에 볼 수 있기 때문이다.
- 참고 자료
- top 으로 알아보는 리눅스 프로세스!
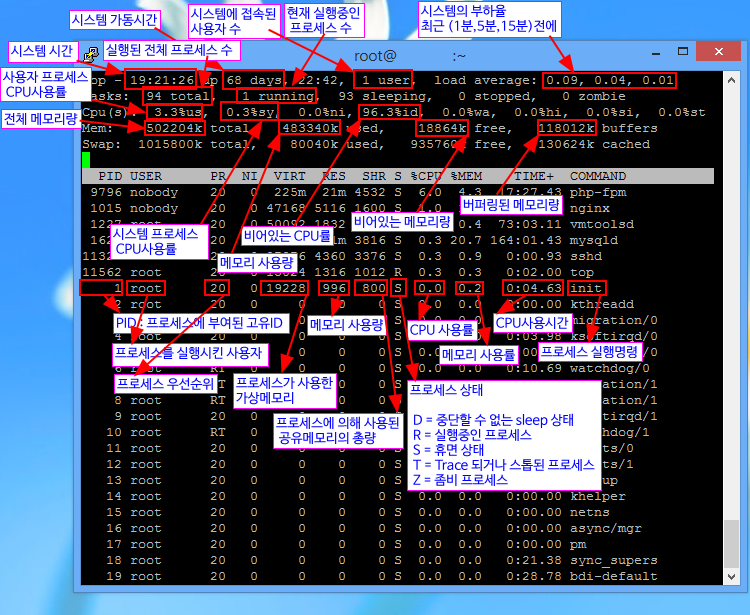
- load average : 현재 시스템이 얼마나 일을 하는지를 나타냄. 3개의 숫자는 1분, 5분, 15분 간의 평균 실행/대기 중인 프로세스의 수. CPU 코어수 보다 적으면 문제 없음(하단에 세부 설명)
- Tasks : 프로세스 개수
- KiB Mem, Swap : 각 메모리의 사용량
- PR : 실행 우선순위
- VIRT, RES, SHR : 메모리 사용량 => 누수 check 가능
- 프로세스 상태 체크(작업중, I/O 대기, 유휴 상태 등)
S – 슬립
D – I/O 대기
R – CPU 대기/실행 중
T – 정지 중
Z – 종료 중
W – 모두 SWAP되어 있다.
< - 우선도가 높다.
N – 우선도가 낮다.
L – 특별한 프로세스 (전혀 SWAP되지 않은 메모리가 할당되어 있다.) - STAT가 항상 R(CPU를 필요로 하고 있는 상태), CPU 이용률이 계속 99%가 되거나 메모리 이용률이 비 정상적으로 증대하고 있는 프로세스는 폭주하고 있을 가능성이 높다.
정상 종료가 되지 않으면 Kill –KILL PID로 강제 종료한다.
3) 서버의 cpu 부하 상태 확인
- 서버의 반응이 늦을 때 / top 에서 cpu bound, I/O 가 확실히 튀는 것을 봤다면! 일단 어떤 process가 얼마나 cpu를 사용하고 있는지 빠르게 파악해보자!
ps aux --sort=-%cpu | morecommand는ps명령어를 기반으로 cpu 사용율 기반 정렬을 해주며, process가 많을 수 있기 때문에 파이프로 more를 엮어준 것!
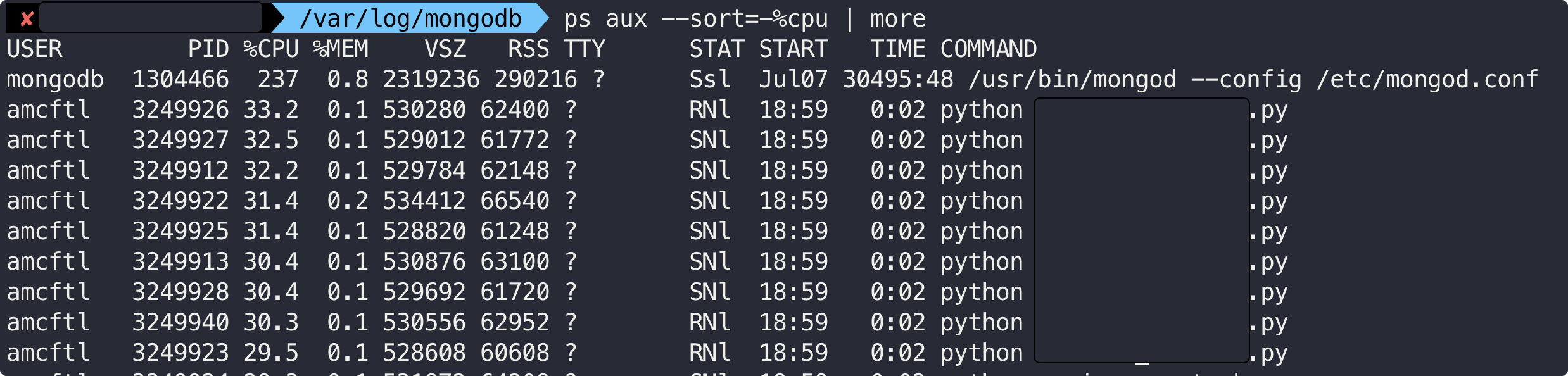
- 지금 보면 mongodb와 python process에 뭔가 사용율이 심상지 않음을 알 수 있다.
모델학습도 아닌데 이게 무슨일인가!
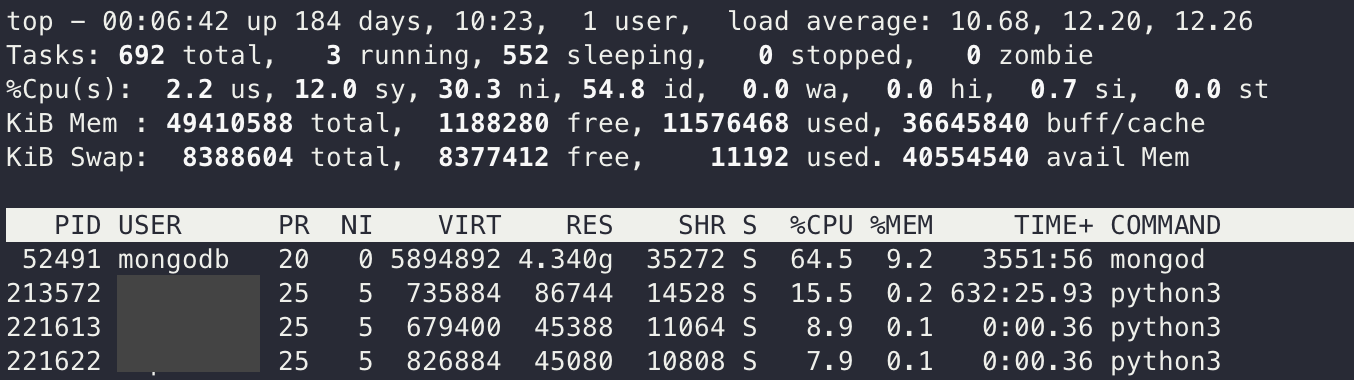
- uptime은 현재 대기중인 프로세스가 얼마나 있는지를 나타내는 load average값을 확인하는 가장 쉬운 방법이다. 리눅스 시스템에서 이 값은 대기 중인 프로세스뿐만 아니라 disk I/O와 같은 I/O작업으로 block된 프로세스까지 포함되어 있다. 이를 통해서 얼마나 많은 리소스가 사용되고 있는지 확인할수 있지만, 정확하게 이해할 수는 없다.
00:30:44 up 184 days, 10:47, 1 user, load average: 19.32, 14.37, 13.16- 위에 있는 3개의 숫자는 각각 1분, 5분, 15분에 load average 값이다.
- 이를 통해서 시간의 변화를 알 수 있는데, 예를들어서 장애가 발생했다는 소식을 듣고 해당 instance에 로그인 했을때 1분 동안의 값이 15분 값에 비해서 작다면 이는 장애가 발생하고선 내가 너무 뒤늦게 로그인했음을 알 수 있다.
- 위 예제에서는 1분 값이 약 19이고 15분 값이 14정도 되는것으로 볼때 최근에 상승한것을 알 수 있다. 여기서 숫자가 이 만큼 높은 것은 많은 의미를 갖고 있다.
- CPU 수요에 문제가 있을거라 추측되지만, 이 의미를 확인하기 위해선 뒤에 나오는 vmstat이나 mpstat같은 커맨드를 이용해서 확인할 수 있다.
vmstat 1virtual memory stat약자인 명령어, 1을 인자로 준 vmstat은 1초마다 정보를 보여준다. 첫번째 라인은 부팅된 뒤에 평균적인 값을 나타낸다.
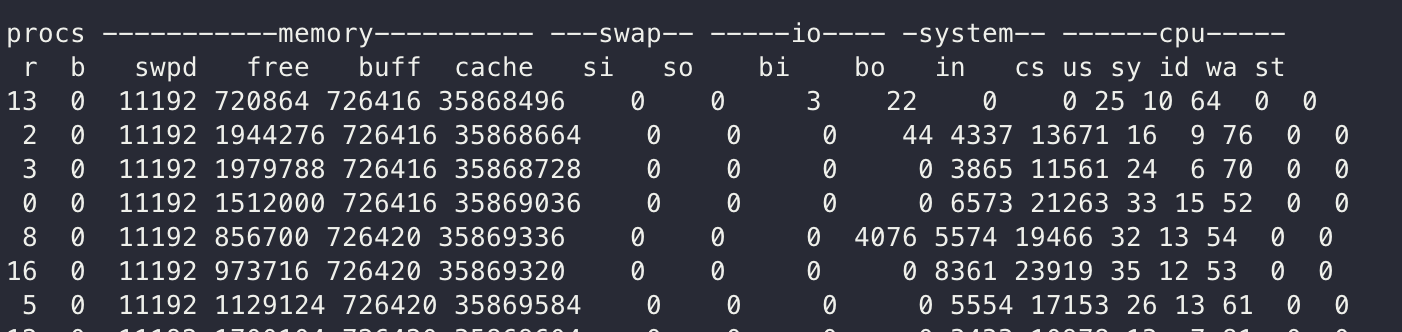
- r: CPU에서 동작중인 프로세스의 숫자다. CPU 자원이 포화(saturation)가 발생하는지 확인할때에 좋은 값이다. r 값이 CPU의 값보다 큰 경우에 포화되어 있다고 해석된다.
- free: free memory를 kb단위로 나타낸다. free memory가 너무 자리수가 많은 경우 free -m를 이용하면 조금더 편하게 확인할 수 있다.
- si, so: swap-in과 swap-out에 대한 값이다. 0이 아니라면 현재 시스템에 메모리가 부족한것이다.
- us, sy, id, wa, st: 모든 CPU의 평균적인 CPU time을 측정할 수 있다. 각각 user time, 커널에서 사용되는 system time, idle, wait I/O 그리고 stolen time순이다.(stolen time은 hypervisor가 가상 CPU를 서비스 하는 동안 실제 CPU를 차지한 시간을 이야기한다.)
4) 프로세스 상태 점검
- 부하 원인 발견하기, 좀 더 세부적으로 프로세스의 부하원인 파익을 접근해 보자
- ps는 이 시리즈에 포함되어 있는 프로세스 설명에 살짝 소개되어 있다.
- ps -aux vs ps -ef
ps -aux # 전체 프로세스 리스트
ps -aux | grep {targetname} - USER : 실행하고 있는 유저 명
- PID : 프로세스 번호
- CPU : cpu 이용률
- %MEM : 메모리 이용률
- VSZ/RSS : 이용하고 있는 메모리 사이즈
- TTY : 표준 입력이나 표준 출력에 사용되는 단말기 종류
- STAT : 프로세스 상태
- START : 프로세스의 개시된 시간
- TIME : cpu를 이용한 시간
- COMMAND : 명령어의 이름
5) 네트워크 상태 점검
- 부정한 엑세스 감시, 설정 확인
netstat –t # -t 옵션은 TCP/IP의 상태를 표시
netstat –tl # -l 옵션은 TCP/IP로 접속을 기다리는 상태를 표시- 접속자의 주소와 정보 등이 표시되고, 접속중인 상태는 ESTABLISHED라고 표시된다.
- 부정한 엑세스 주소를 없앤다.
- TCP/IP로 접속할 수 있는 서버가 표시되고, 대기중인 상태는 LISTEN이라고 표시된다.
- 필요 없는 서버가 실행되어 있지 않은 지 확인
6) 네트워크 카드 점검
- 이더넷의 상태, 카드 설정 확인 / NIC(network interface controller)
ifconfig # 해당 명령어도 굉장히 다양하게 사용이 가능하다- 네트워크 카드의 상태를 확인하고, MAC주소(네트워크 카드 자신의 번호)나 카드에 할당되어 있는 IP주소 이더넷 충돌의 수, 통과한 패킷의 수, 하드웨어의 정보 등을 확인
7) 디스크 상태
- 용량 확인
df -h # -h 옵션으로 사람이 읽기 좋은 형태로 출력
du # 얘는 뒤에 경로를 붙이고 파이프를 이용하는게 좋다
du /var/log | sort –nr- 사용 가능한 용량이 적어졌다면 여분의 파일을 지우거나 빈 공간이 큰 영역에 디렉토리를 이동해서 그 디렉토리에 symbolic 링크를 붙이는 등의 대책이 필요하다.
- du /var/log | sort –nr 는 표시된 숫자는 KB 단위이고 디렉토리마다 사용량이 큰 순서로 표시, 일반적으로 아파치와 같은 "웹서버"의 로그가 가장 크다.
sudo du ~ -h --max-depth=1 | sort -hr- 이 명령어로 특정 경로(~ 자리) 부터 depth만큼 가면서 어떤 파일이 가장 용량이 큰지 점진적으로 접근할 수 있다.
8) 로그
- 서버 작동에 문제가 있을 시 확인, 리눅스 로그, sys-log와 journal-log 확인하기!
/var/log/boot.log – 데몬의 실행이나 종료의 로그
/var/log/cron – crond의 로그(정기적으로 명령어를 실행하는 데몬)
/var/log/dmesg – 커널의 메시지
/var/log/message – BIND나 커널, su 등 그 외의 로그
/var/log/secure – 로그인의 기록이나 tcpd의 로그(TCP Wrappers)
- 서버의 로그는 어떤 서비스, WAS 등을 사용하느냐에 따라 차이가 나기 때문에 생략
3. 서버 모니터링
1) htop
- top명령어도 충분히 많은 정보를 보여주고, 잘 이용한다면 엄청난 도움이 많이 된다. (커스터마이징도 잘됨)
- 하지만 게으른 우리는 대안을 먼저 찾는다, 그 중 하나가 htop이라고 생각한다. 그리고 htop은 추가로 설치를 해야하는 유틸 라이브러리, 패키지다.
설치
apt-get install htop # -get 옵션 없어도 된다 ^^, sudo 붙여주자 왠만하면
htop # top처럼 바로 실행 가능한 커멘드실행 화면과 사용법

- 기존 실행화면은 위와 같다. 우 상단 모자이크는 카톡이 와서 다시 스샷 너무 귀찮아서 넣었다.ㅎㅎ
- Htop은 기본적으로 하나의 화면에서 모든 정보를 볼 수 있도록 되어 있으며, 상단에는 시스템의 주요 내용을 요약해 보여주고 있고, 그 아래에는 각 프로세스들의 각 활동 내용을 자세하게 보여준다. 그리고 모든 상황은 1초 단위로 업데이트 된다.
- 구체적으로 Htop 화면 상단 왼쪽에 CPU, Swap, Memory 사용량을 총량 비 사용량을 표시해 준다.
- 일CPU가 여러 개일 경우는 CPU 번호별로 사용률을 보여준다. 오른쪽에는 테스크 정보와 스레드 정보를 보여주고 있다.
- 또한 맨 하단에 각 기능별 단축키가 표시되어 있는데, Htop에서 F1 ~ F10까지 단축키에 각 기능들이 정의되어 있다.
- 프로세스 정보에 대한 설명 또는 부호(기호) 등은 top과 동일해서 위 내용을 숙지한다면 충분히 해석이 가능하다.
- 단축키 사용하는 방법
2) 모니터링에 대한 고찰
모니터링?
- 모니터링(Monitoring)이란 어떤 대상을 감시, 관찰한다는 뜻
- 목적은 지속적인 감시, 감찰을 통해 대상의 상태나 가용성,변화 등을 확인하고 대비하는 것이다.
- 즉 "어떤 대상의 상태나 상황을지속적으로 감시, 관찰하여 예기치 못한 상황과 오류를 대비하고 극복한다"라고 할 수 있다. 특히 IT 서비스 분야에서는 기본적으로 미리계획되어 한정된 비용과 리소스를 가지고 서비스를 제공하기 때문에 사용자경험을 중요시하는 IT 서비스에서는 그 서비스가 어떤 환경에서 운영되든모니터링의 중요성은 결코 낮을 수가 없다. 특히 확장성과 유연성을가진 클라우드 플랫폼에서는 지속적인 모니터링을 통해 수집된 데이터를기반으로 시스템 규모의 확장과 축소를 빠르게 결정해야 하기 때문에 더욱더 중요하다.
무엇을 모니터링 해야 하는가?
- 요즘은 대부분 모니터링 솔루션들은 깔끔한 웹UI가 채택되어 보기가 매우 편하고, Windows와 다양한 버전의 리눅스도 별 무리 없이 지원한다.
- SaaS 형태의 모니터링 솔루션들의 경우, 별도의 모니터링 서버 없이 간단하게 에이전트 설치만으로 몇분안에 모니터링이 가능하다.
- 서버 모니터 솔루션 개발 방향
- 다양한 서버 모니터링 도구
짧고 굵은 결론
- 핵심적인 것은 '어떤 서버 형태'에 따라 '어떤 것을 중점적으로 체크'할지가 모니터링 도입 전 가장 핵심적인 결론이다. 리소스에 대한 것은 가볍게 당연하다. 이제는 그 데이터를 어떻게 모니터링 하는데에 사용할 것인지가 당연히 더 중요하다.
- 어떤 형태의 서버라도 모든 가능성과 기능이 제공되는 솔루션을 도입하면 나쁠건 없다. 하지만 모든 도구들이 나와있는 책상에서 어떻게 우리가 빠르게 연필을 찾고 공책에 필기를 바로 할 수 있겠는가?
- 특히 도커라이징되고, POD 등을 통해 서버가 띄워지고, 클라우드 환경에서 쿠버네티스 등으로 관리를 하고, 이런 환경에서는 대상 서버를 '모니터링'하는 것은 점점 어려워지기도 한다. 그렇기 때문에 선택과 집중이 더욱 더 중요하다고 생각한다.
도움이 되는 링크 및 출처

🔥 [ AI RPA 의 시대가 기대되는, software/product 개발자 정현우 입니다. ] 🔥
진짜 정리 예술이네요.. 감동입니다..ㅠ