1. Back propagation 관점에서의 이해
-
Back Propagation에서 뉴럴넷의 학습은 Loss function을 가중치에 대해 편미분 한 값들을 아랫단으로 전파하며 가중치를 업데이트 해줬다.
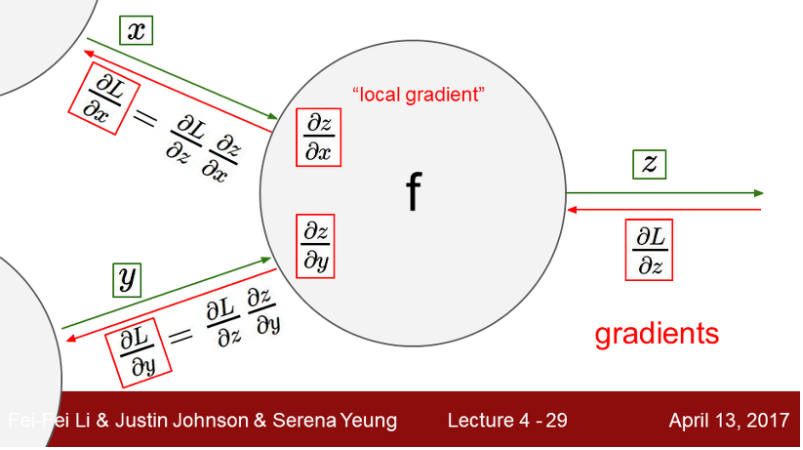
upstream gradients * local gradient !
-
이렇게 이해를 할 수도 있습니다!

-
이런식으로 loss function(마지막 레이어의 출력)을 최소화 하는 방향으로 가중치들을 업데이트 해줍니다.
-
그렇게되면 입력이 들어왔을 때 입력에 따른 출력을 얻을 수 있습니다. 그리고 이는 변하지 않습니다. 즉 이라는 입력을 받았다면 무조건 만 출력된다는 것입니다!
2. Maximim Likelihood관점에서의 이해

이활석님 오토인코더의 모든것 강의노트 중 19페이지
https://www.youtube.com/watch?v=o_peo6U7IRM&t=2308s
-
loss function(마지막 레이어의 출력)을 최소화 하는 방향으로 학습합니다.
-
하지만 출력에 대한 관점을, 우리가 학습시킨 네트워크에 feed forward 시켰을 때의 출력이 주어졌을 때 그게 정답일 확률을 최대화 하는 관점으로 갖습니다.
-
back prop관점에서는 feed forward 시켜줄 모델만 정해주면 됐지만, MLE관점을 도입할 때 조건부 확률의 모델 또한 정해줘야합니다. (가우시안으로 할껀지, 베르누이로 할껀지.. 강의에서는 표준편차가 1인 정규분포로 가정하고 설명해주십니다.)
-
이때 학습의 목표는 조건부 확률분포해 대한 likelihood값이 최대가 되는것입니다. 그리고 네트워크의 출력은 가우시안(표준편차가 1인)분포의 파라미터인 평균이 됩니다.
-
위 그림을 참고했을 때 y는 고정된 값입니다(training DB에 의해서). 이때 네트워크가 결과로 파라미터 을 출력한다면 조건부 확률분포는 평균이 이고, 표준편차가 1인 정규분포이고 그때 y가 나올 likelihood는 를 평균으로 갖는 정규분포에 비해 큽니다.
-
이런식으로 likelihood를 최대화 하는 파라미터를 추정합니다. 그리고 최대값이 될 때는 평균과 y값이 같아질 때 maximum likelihood를 갖습니다.
-
이런 관점으로 확률분포의 모델을 찾으면 이제 그 모델에서 샘플링을 통해 training DB와 비슷한 데이터를 얻어낼 수 있습니다.
강의에서는 이를 고정입력, 다른 출력으로 설명합니다. 왜냐면 입력을 잘 설명하는 확률분포 모델을 maximum likelihood관점으로 찾고, 거기서 샘플링을 하면 고정된 출력이 아닌 다른 출력을 얻을 수 있기 때문입니다.
