1.VAE란?
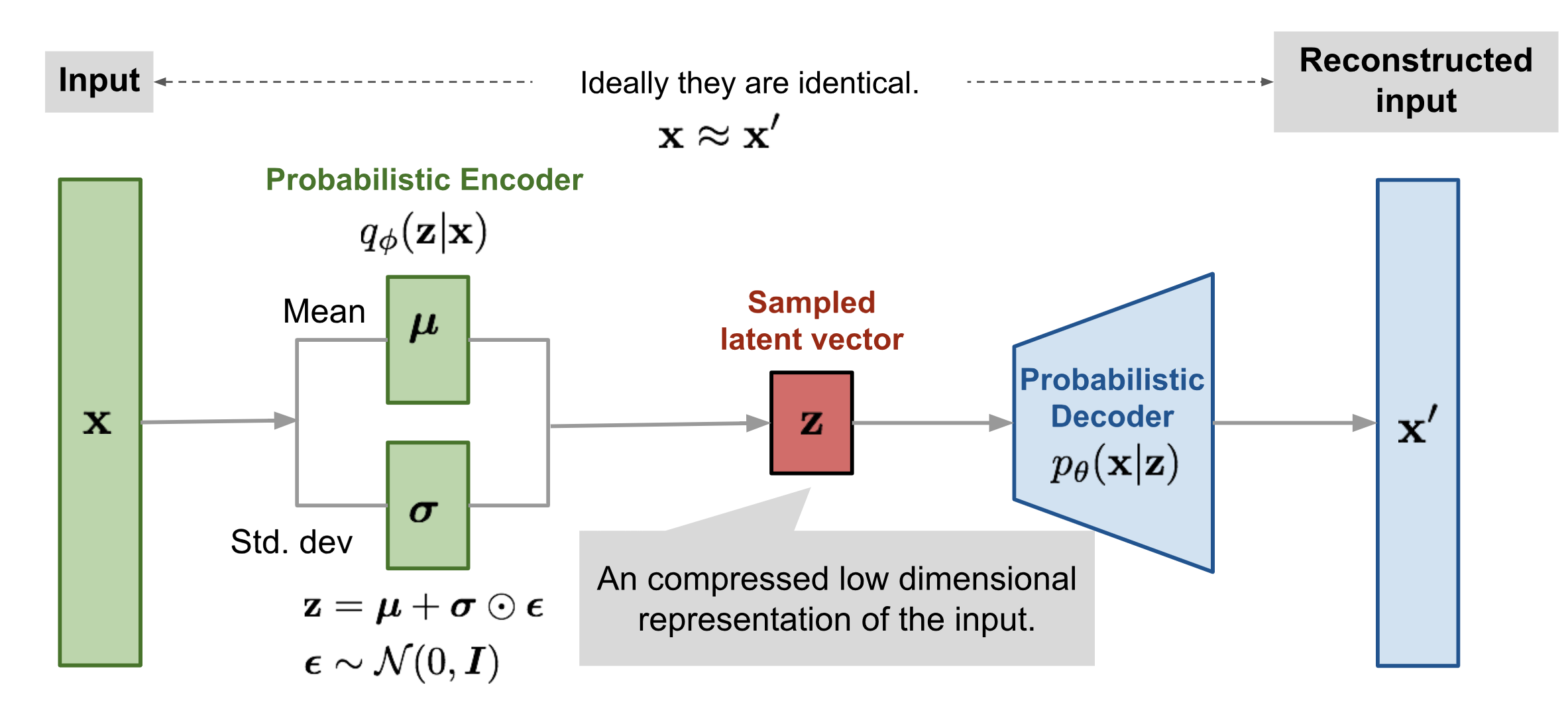
- VAE의 구조는 위와같이 생겼습니다.
- data x에 관한 latent variable Z가 존재한다고 했을 때
- Latent variable z에서 샘플링을 하여 디코더를 걸쳐 input data와 유사한 데이터를 만들어 내는 모델입니다.
a. VAE가 하고싶은 것
-
training data x와 비슷한 데이터를 만들어 내는 것이 목적입니다.
-
N개의 Sample을 가진 x 라는 데이터가 있다고 해보자. 논문에서는 이 데이터가 관측되지 않은 연속형 확률 변수 z 를 내포하는 어떤 Random Process에 의해 형성되었다고 가정합니다.
-
우리는 생성 과정을 통해 나오는 p(x)를 최대화 시키고 싶고, p(x)는 아래와 같이 표현될 수 있습니다.
p(x)=∫p(x∣ z)p(z)dz
하지만 위의 식을 최대화 하기위해서는 3가지에 대해 생각해봐야 합니다.
latent variable z를 정의해야하고, p(x∣z)도 정의해야합니다.
그리고 마지막으로 적분을 어떻게 할것인지 정해야합니다.
(모든 가능한 latent variable z에 대해서 적분하는건 매우 비효율적, 사실상 불가능)
-
latent variable z
Z의 분포를 평균이 0이고 분산이 I인 다변량 정규분포로 가정
-
decoder p(x∣z) -> pθ(x∣z)
p(x∣z)는 θ를 parameter로 갖는 분포로 가정합니다. 보통 정규분포, 베르누이분포를 사용합니다.
θ에 의해 parameterized 되니 pθ(x∣z)로 쓰여질수 있습니다.
자세히 쓰면 p(x∣z)=p(x;g(z;θ))=defpθ(x∣z)로 쓸수 있습니다.
즉 pθ(x∣z)자체가 뉴럴넷이 아니고, g(z;θ)가 뉴럴넷이며, 이 뉴럴넷의 output은 분포의 모수입니다. 그리고 pθ(x∣z)는 그러한 모수를 가지는 확률분포로 정의됩니다.
-
적분 issue를 해결하기 위해선 탐색해야하는 공간을 줄여서 parameter θ를 더 잘 찾기 위해 조건부 확률을 이용해 확률공간을 줄입니다.(의미 있는 z에 대해서만 적분해보자!)
-
바로 p(z∣x)를 도입하는것 입니다. 이는 z를 p(z)에서 샘플링 하는 것 대신에 x를 보여줄테니 그때 나오는(x를 잘 설명하는) z에서 샘플링 하겠다 라는 의미입니다.
-
하지만 p(z∣x)는 모릅니다. 따라서 이때 qϕ(z∣x)를 도입해줍니다. 이를 우리가 잘 아는 분포인 정규분포나 균일분포로 정의하고 파라미터들을 조정해서 p(z∣x)와 최대한 유사하게 만들어주면 됩니다.
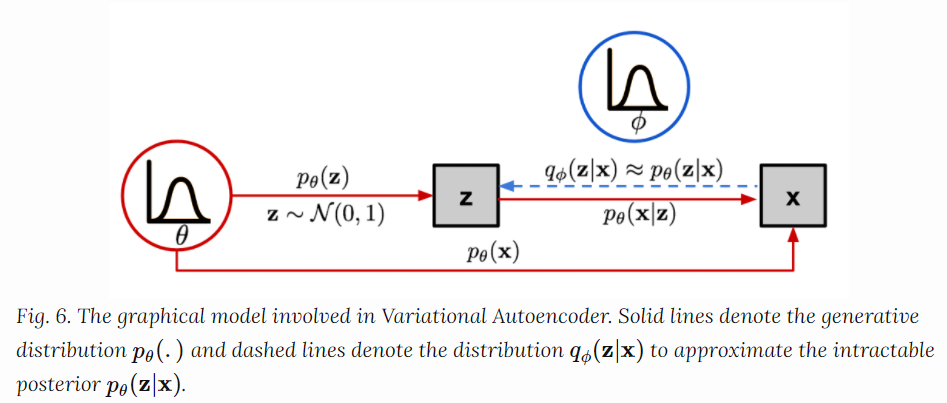
- pθ(x∣z)는 생성 모델을 정의하고, probablistic decoder라고도 알려져있습니다.
- qϕ(z∣x)는 probablistic encoder입니다. 하나의 확률분포로 볼수있습니다.
2.VAE의 Loss function
a. p(x) 분해, 변분추론(ELBO 이용)
log(p(x))=∫log(p(x))qϕ(z∣x)dz ;because∫qϕ(z∣x)dz=1 =∫log(q(z∣x)p(x,z))qϕ(z∣x)dz ;becausep(x)=p(z∣x)p(x,z)
=∫log(qϕ(z∣x)p(x,z)p(z∣x)qϕ(z∣x))qϕ(z∣x)dz
=∫log(qϕ(z∣x)p(x,z))qϕ(z∣x)dz+∫log(p(z∣x)qϕ(z∣x))qϕ(z∣x)dz
- 우리는 p(x)값을 최대화 하고 싶습니다
- log는 단조증가 함수이니 p(x)를 최대화 하나, log(p(x))를 최대화 하나 같은 의미입니다.
- 수식을 전개하면 마지막 줄을 얻을 수 있습니다.
- 첫번째 term이 ELBO(ϕ,θ)입니다. 이때 식에는 θ가 없는데? 라고 생각할수 있겠지만 전개하면 θ를 포함하는 식으로 바뀝니다.
- 두번째 term이 두 확률분포 qϕ(z∣x)와 p(z∣x)의 KL divergence입니다. 좀더 자세히 쓰면 KL(qϕ(z∣x)∣∣p(z∣x))이고 이 값은 0보다 크거나 같습니다.
- KL다이버전스에 대해서는 다른 포스팅에서 다루겠습니다. (두 분포의 거리를 측정하는 측도라고 이해하면됩니다.)
- 마지막 식에서 우리는 두번째 term인 q(z∣x)와 p(z∣x)의 KL다이버전스의 값을 줄이고 싶습니다. 왜냐면 우리는 p(z∣x)를 모르기 때문에 이를 qϕ(z∣x)로 근사했고, 당연히 근사한 분포가 원래 분포와 비슷하면(거리가 가까우면) 좋겠죠!
- 하지만 우리는 p(z∣x)를 모르기 때문에 위 식의 값을 계산할 수 없습니다.
따라서 첫번째 텀 ELBO를 maximize함으로써 두번째 term을 최소화 하려고 합니다.
(A = B + C라는 수식에서 A,B,C모두 상수라면 B를 최대화하면 C가 최소화 되겠죠, 왜냐면 B+C의 합의 결과는 정해져있기 때문이죠, 비율을 생각하면 이해가 쉬울것 같습니다.)
- 따라서 우리의 목적은 이제 첫번째 term을 최대화 하는 parameter ϕ,θ의 값을 찾는것입니다.
- 또한 위 식에서 우리는 log(p(x))>=ELBO(ϕ,θ)임을 알 수 있습니다.
b. Maximizing ELBO term
∫log(qϕ(z∣x)p(x,z))qϕ(z∣x)dz=ELBO(ϕ,θ)로 정의했습니다.
ELBO(ϕ,θ)=∫log(qϕ(z∣x)p(x,z))qϕ(z∣x)dz
=∫log(qϕ(z∣x)pθ(x∣z)p(z))qϕ(z∣x)dz
=∫log(pθ(x∣z))qϕ(z∣x)dz−∫log(p(z)qϕ(z∣x))qϕ(z∣x)dz
=Eqϕ(z∣x)[log(pθ(x∣z))]−KL(qϕ(z∣x)∣∣p(z))
c. optimization problem
우리가 최적화 할 parameter는 ϕ와 θ가 있습니다.
i. ϕ에 대한 최적화 (ELBO 최대화)
log(p(x))>=Eqϕ(z∣x)[log(pθ(x∣z))]−KL(qϕ(z∣x)∣∣p(z))=ELBO(ϕ,θ)
- parameter ϕ는 ELBO(ϕ)를 최대화 해야합니다
- 변분추론에서 ELBO를 최대화 하는것입니다.
ii. θ에 대한 최적화 (MLE 최대화 or negative likelihood 최소화)
−∑log(p(xi))<=−∑{Eqϕ(z∣xi)[log(pθ(xi∣z))]−KL(qϕ(z∣xi)∣∣p(z)}
- Negative log likelihood를 최소화 하는것은 log likelihood를 최대화 하는것과 같습니다.
iii. 최종적인 최적화 형태
argminϕ,θ∑−Eqϕ(z∣xi)[log(pθ(xi∣z))]+KL(qϕ(z∣xi)∣∣p(z))
위의 loss function은 두개의 term으로 이루어져 있습니다.
- 첫번째 term은 Reconstruction Error 입니다. 이는 z에서 샘플링되서 생성된 데이터가 원래 데이터와 얼마나 유사한지에 관한것 입니다.
현재 샘플링함수에 대한 negative log likelihood와 같습니다.
- 두번째 term은 정규화를 해주는 term 입니다.
같은 Reconstruction Error를 갖는qϕ(z∣x)가 여러개 존재할 수 있는데, 최대한 p(z)와 비슷한 분포를 선택하라는 의미로 이해했습니다. 왜냐면 저희는 다루기 쉬운 함수를 원해 p(z)를 간단한 정규분포 가정했기 때문입니다.
3.학습 과정
- 우리는 위에서 살펴본 과정을 통해 VAE가 줄여야할 loss가 무엇인지 알아봤습니다.
그렇다면 어떻게 학습을 하는지 알아봐야합니다.
- 그에 앞서 우리는 컨트롤 하기 쉬운 Z를 원하기 때문에
Z의 분포를 평균이 0이고 분산이 I인 다변량 정규분포로 가정합니다.
- 그리고 Encoder와 Decoder도 다루기 쉬운 확률분포로 가정을합니다.
보통 Encoder는 가우시안으로 가정하고, Decoder는 multivariate bernoulli 또는 multivariate gaussian으로 가정합니다.
Loss function을 다시 써보면 다음과 같이 쓸수 있습니다.
−Eqϕ(z∣x)[log(pθ(x∣z))]+KL(qϕ(z∣xi)∣∣p(z))
학습과정의 맥락은 다음과 같습니다.
- input x를 Encoder qϕ(z∣xi)를 태워서 평균과, 분산을 구합니다.
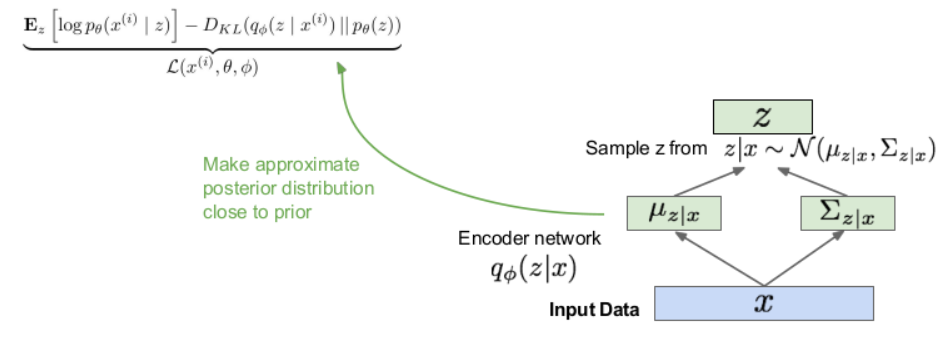
- 이전 과정에서 구해진 평균과 분산을 가지는 Gaussian distribution에서 z를 샘플링합니다.
- 샘플링된 z를 decoder qϕ(z∣x)에 태워서 결과물을 출력합니다.
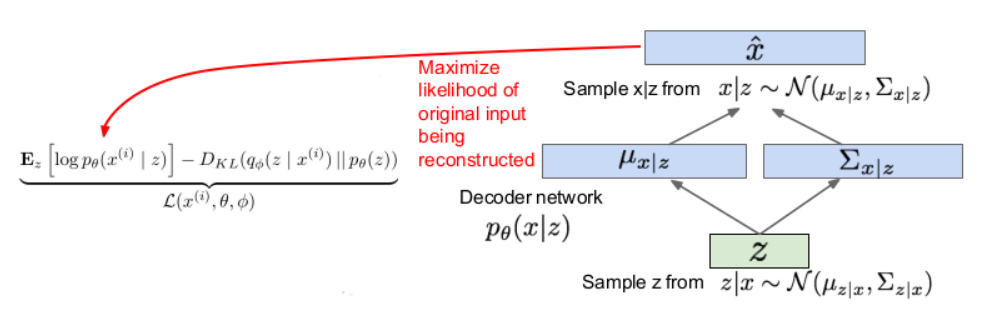
이제 위의 과정에서 back-prop을 진행해서 인코더의 평균과 분산, 디코더의 평균과 분산을 구해주면 됩니다.
- 하지만 loss function에서 첫번째 term을 보면 z∼qϕ(z∣x)임을 알수 있습니다.
샘플링은 stochastic한 과정이고 그렇기에 back prop을 해줄수 없습니다. (왜냐면 우리는 평균과 분산을 지속적으로 업데이트 해주고 싶지만 샘플링을 해버리면 지속적으로 업데이트 해주는게 의미가 없기때문이라고 이해했습니다.)
a.Reparmeterization Trick
stochastic한 과정 때문에 back prop을 사용할수 없는 문제를 해결하기 위해서 reparmeterization trick을 도입합니다. 그림으로 요약하면 다음과 같습니다.
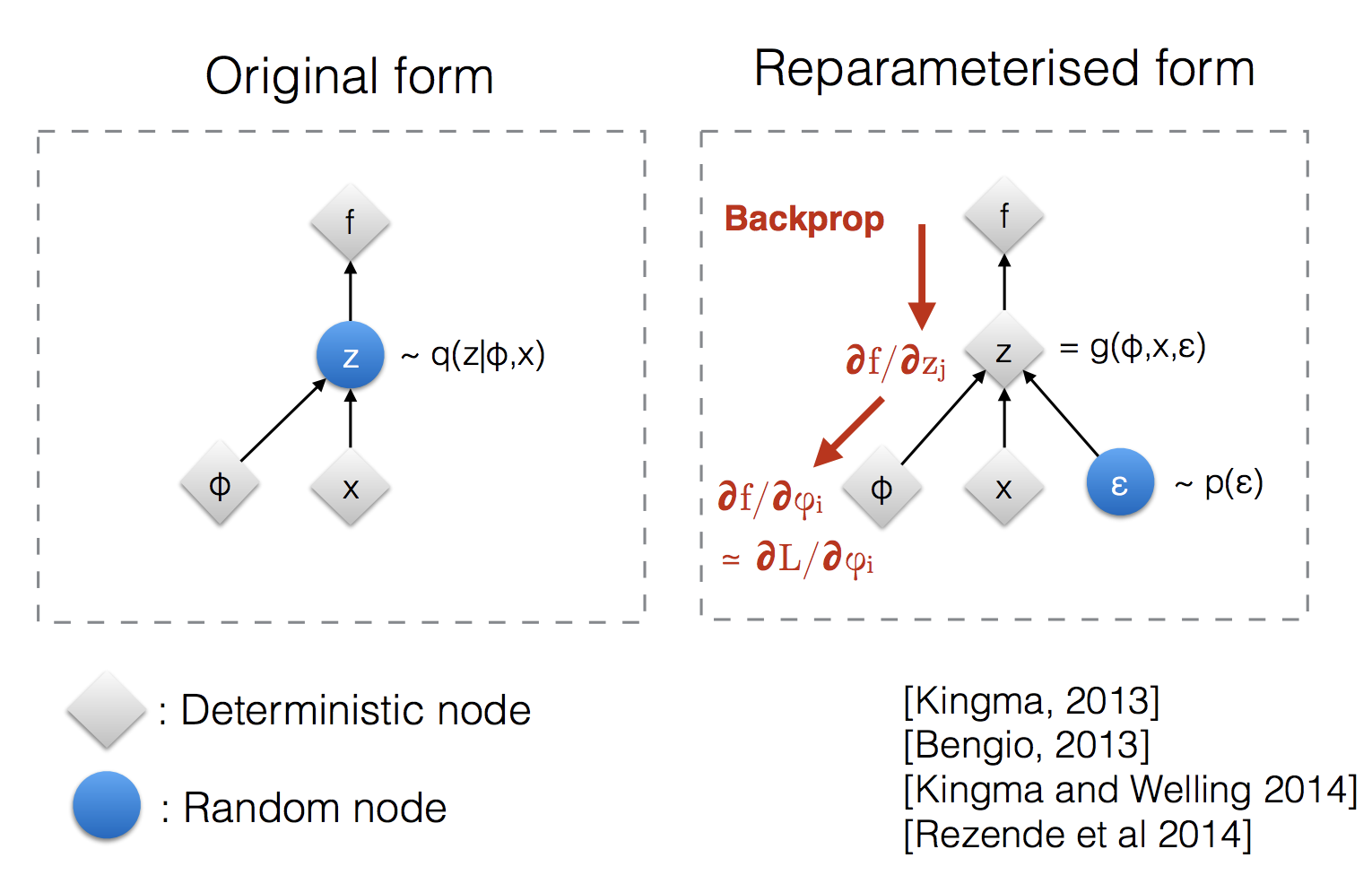
zz∼qϕ(z∣x(i))=N(z;μ(i),σ2(i)I)=μ+σ⊙ϵ, where ϵ∼N(0,I); Reparameterization trick.
위 그림의 좌측을 보면 chain rule에 의해서 gradient가 전달되어 와야하는데 z가 랜덤이기 때문에 back prop을 하지 못하니 오른쪽 처럼 바꿔서 z의 성질은 유지하지만 z가 랜덤이 아니라 deterministic 하게 만들어줍니다.
b.Generating data from Z
학습이 끝나면 encoder파트를 제거하고 샘플링한 z를 디코더 네트워크에 feed해주면 결과물로 training data와 유사한 output을 얻게 됩니다.
4.VAE와 AE의 차이
AE와 VAE의 구조는 매우 유사합니다.
- AE의 구조
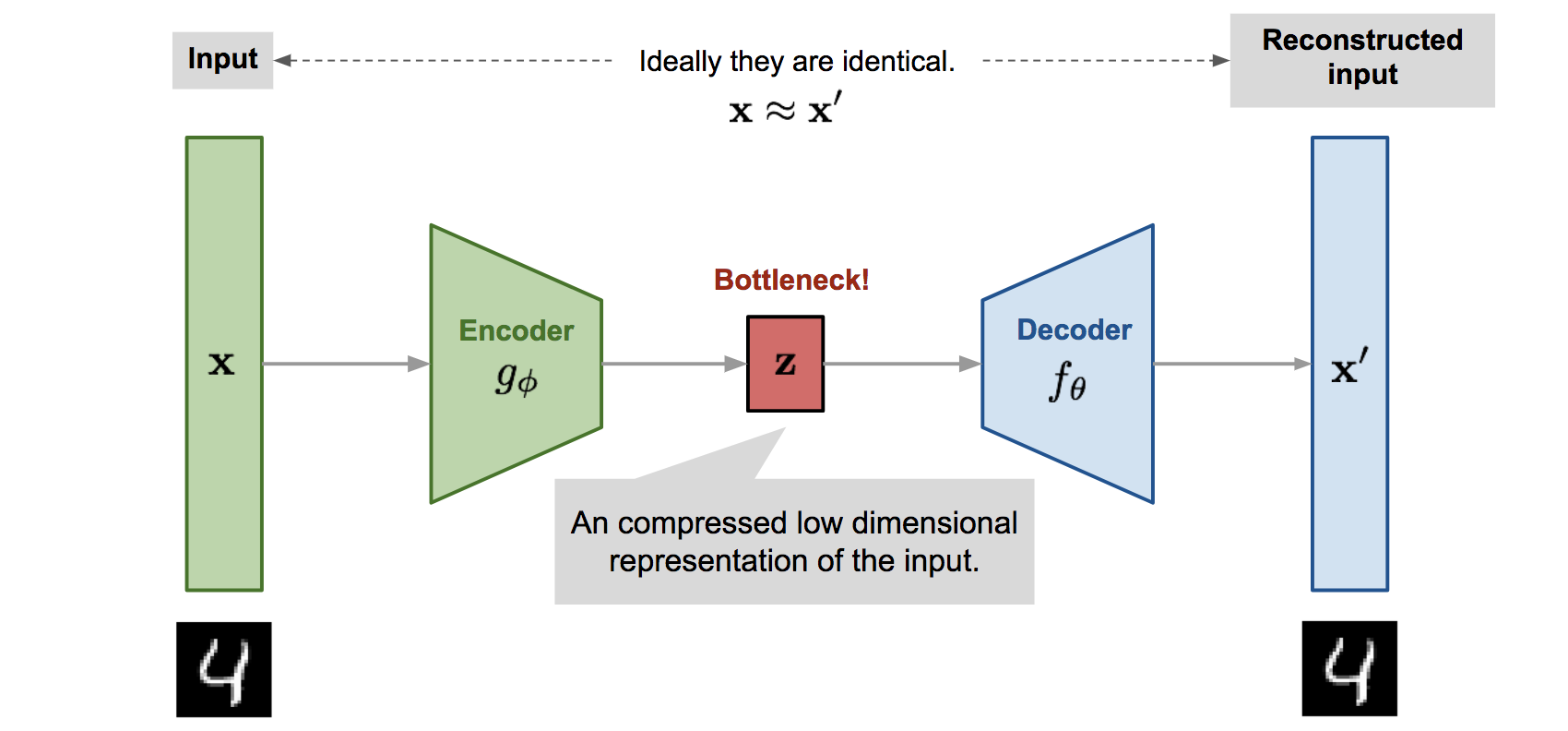
구조만 보면 AE와 VAE모두 인코더와 디코더를 가지고 있고, 인코더를 통해 차원을 줄이고 디코더를 이용해 생성합니다.
하지만 목적을 이해하면
- AE의 목적은 효과적으로 차원축소를 하는데에 있습니다. 그리고 차원축소를 하는 학습과정에서 비지도 학습 문제를 지도학습 문제로 바꾸며, 학습을 용이하기 위해 뒷단(디코더)부분을 붙혀준 것입니다.
- VAE의 목적은 효과적으로 training data와 비슷한 data를 생성하는데 있습니다. 앞단(인코더)를 붙혀줌으로써 생성할 때 원래 training data x를 잘 나타낼 수 있는 z에서 샘플링 할수 있습니다.
5.참고자료
개인적으로 이활석님의 오토인코더의 모든 것 강의를 먼저 보았고, 나중에 친구가 윤성로 교수님의 강의를 추천해주어서 시청했습니다.