논문 스터디를 위해 차근차근...Anomaly Detection 공부를 진행해볼 예정이다!
논문 제목은 Deep Learning for anomaly detection : A survey 이다.
먼저 여기 논문에서는 딥러닝 기반 anomaly detection(DAD)의 연구 방법에 대해서 먼저 설명을 하고, 그리고 application에 대해 설명하고 있다.
일단 Anomaly Detection에 대해 알아보기 전에, Anomaly의 정의에 대해 알아보는 것은 필수이다.
Anomalies의 정의
Anomaly는 abnormalities,discordants,deviants,또는 outlier라고 부른다. 기형,이상 등으로 해석하면 될 것 같다.
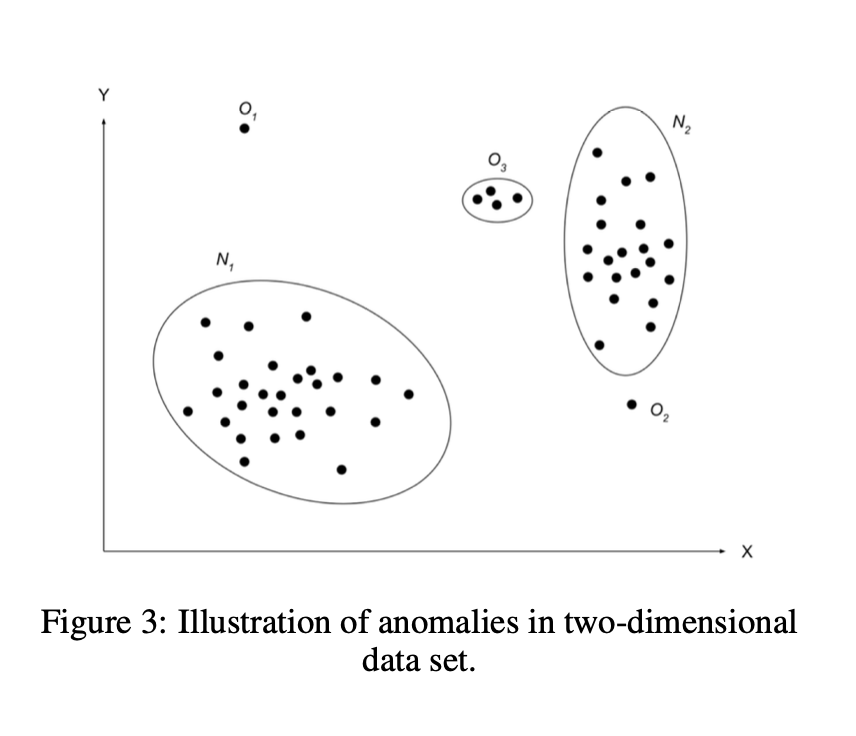
N1,N2는 normal data instance 지역이고
region O3, Point 01, Point02는 데이터 포인트들로부터 떨어지는 이상치이다.
이상치가 일어나는 이유는 여러가지이다.
ex) malicious actions, system failures, intentional fraud 등등
이말인 즉슨, 이상치를 일단 탐지하면 그것이 바로 흥미로운 인사이트의 시작이라는 것이다.
Novelties
Novelty detection은 데이터에서 새로운 패턴을 찾는 것이다.
모든 새로운 것들이 anomality가 되는 것이 아니라, novelties 중에서도 novelty score가 decision threshold score에서 벗어나는 경우에 anomaly가 된다.
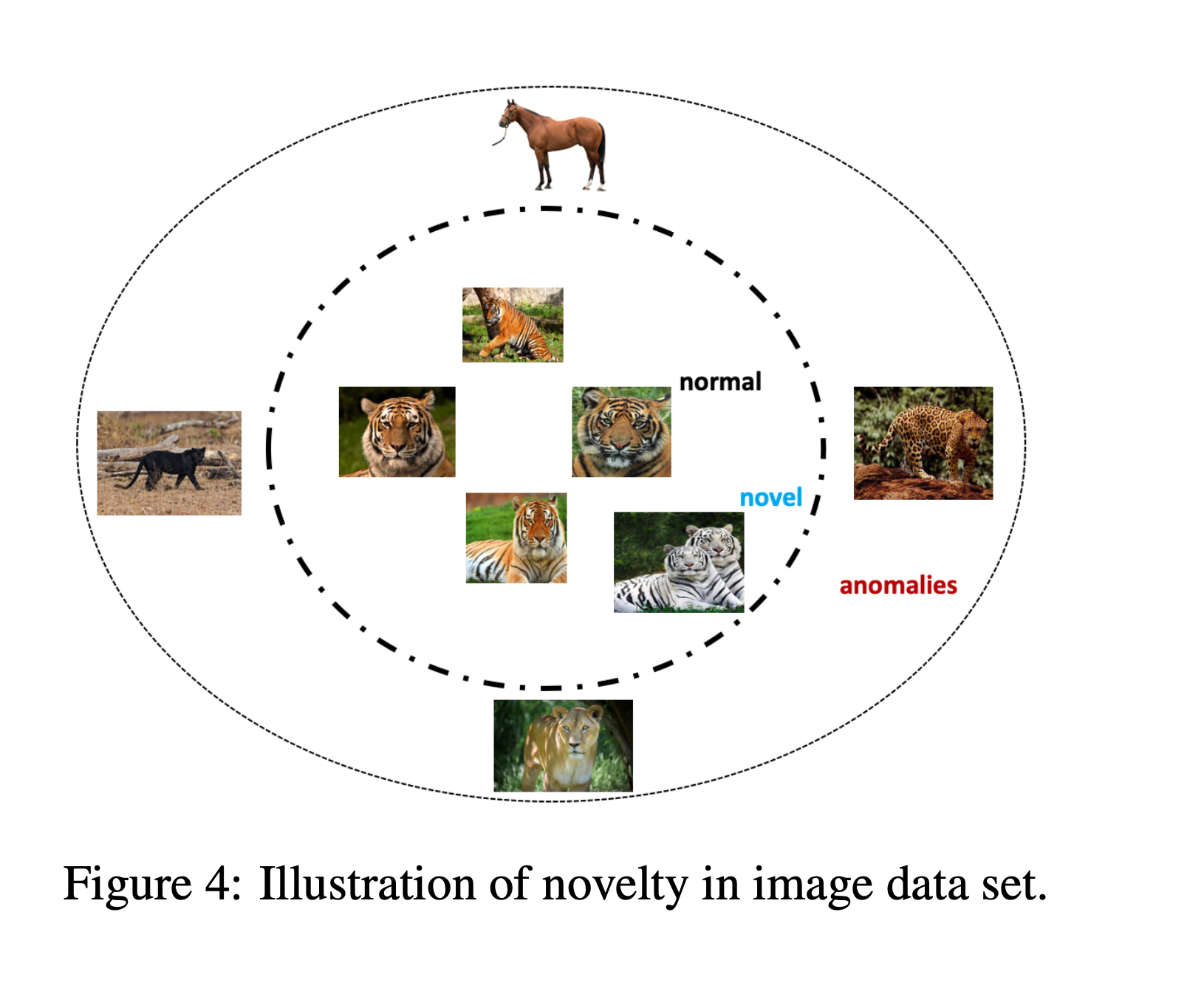
이 그림을 보면 쉽게 판단할 수 있다.
일단 백색 호랑이 사진의 경우, 계산된 novelty 스코어가 threshold에서 벗어나지 않기 때문에 그냥 novel이라고 판단된다.
하지만 표범 사진의 경우, 계산된 novelty 스코어가 threshold에서 벗어나기 때문에 anomaly라고 판단된다.
이제 개념을 알아보았으니, Deep anomaly detection(DAD)에 대해 알아볼 차례이다.
Motivation and challenges : Deep anomaly detection(DAD) Techniques
기존의 방법들에 문제가 있는데,
일단 성능 측면에서 기존의 전통적인 알고리즘은 좋은 성능을 내지 못한다는 것이고,
그리고 데이터 스케일 측면에서 큰 데이터에서 이상치를 찾지 못한다는 것이다.
이걸 해결하기위해 Deep learning 기반의 anomaly detection이 등장했다고 볼 수 있다. DAD의 가장 큰 장점은 직접 특징을 추출할 필요가 없다는 것이다. 근데 그럼에도 불구하고 DAD에도 해결되지 않은 단점이 존재하는데 이상치가 아닌 것과 이상치의 경계가 종종 명확하게 구분이 되지 않는다는 것이다.
그럼 과연 관련된 연구는 어느정도 진행이 되었을까??
Related Work
이 서베이에 따르면 cyper-intrusion , medical , IoT, Sensor network, video 등에 적용을 하려는 시도가 있다고 한다.
하지만!
현재는 상대적으로 anomaly detection을 위한 deep learning approach들이 적다고 한다. 특히, outlier detection을 위한 연구가 부족하다고 한다.
근데 대부분 deep autoencoder를 활용한 연구를 진행한다고 한다.
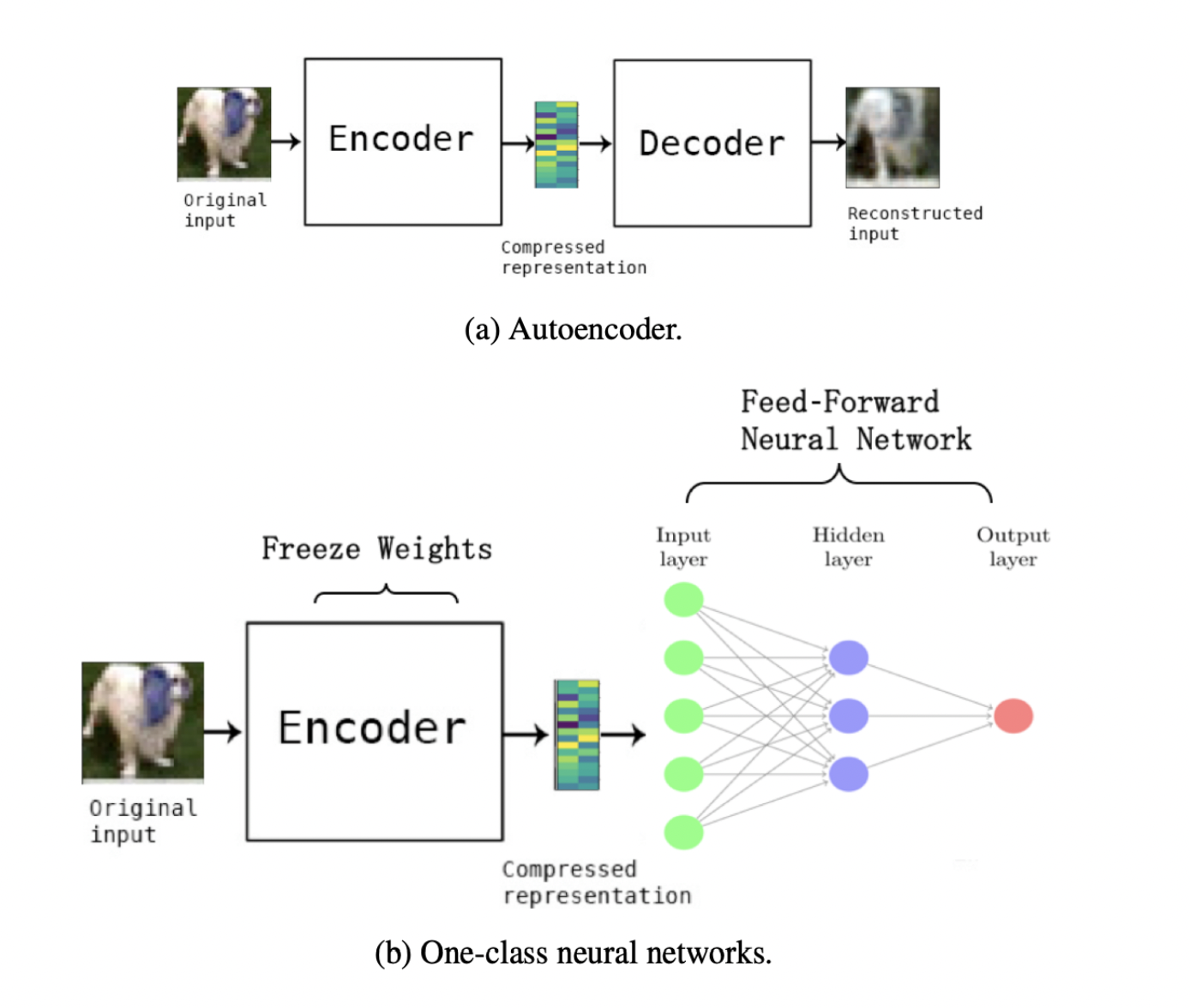
Deep AutoEncoder란
일단 autoencoder의 기본 컨셉은 x를 넣었을 때, 비슷한 x'이 나오도록 하는 것이다.
이게 어떻게 이상탐지에 적용될 수 있을까를 생각해보면 ,
1) 정상 데이터의 학습 세트를 사용하여 deep autoencoder를 학습
2) deep autoencoder을 사용하여 새로운 데이터를 재구성하기
3) 재구성 오차를 계산
4) 재구성 오차의 분포를 확인하고 적절한 임계값을 설정
5) 새로운 데이터를 autoencoder를 통과시켜 재구성 오차를 계산
6) 재구성 오차가 임계값을 초과하는 경우, 해당 데이터는 이상 데이터로 간주
본격적인 Anomaly Detection에 들어가기에 앞서,
anomaly detection에 관한 문제를 먼저 설명한 다음,
anomaly detection이 활용되고 있는 분야에 관해 먼저 설명을 하고 나서
딥러닝 기반 anomaly detection 테크닉에 대해 자세하게 설명할 예정이다.
- Deep learning 기반의 anomaly detection -> 2. 적용분야 -> 3. 딥러닝 기반의 해결책(Solution)
1. Deep learning 기반의 anomaly detection
(논문의 8장에 해당하는 내용이다)
인풋 데이터 /
레이블의 유무에 따른 지도학습, 준지도학습, 비지도학습 /
훈련 목적에 따른 DHM,OC-NN /
Anomaly 타입에 따른 Point Anomalies, Contextual Anomaly Detection, Collective or Group Anomaly detection /
딥러닝의 아웃풋에 따른 Anomaly score, Labels
인풋 데이터
sequential data / non-sequential data 로 나뉘기도 한다.
low-dimensional data / high-dimensional data 로 나뉘기도 한다.
딥러닝은 high-dimensional data를 학습 시킬 수 있음!!
레이블 유무
P1 : Anomalies는 희귀함 => label을 얻기가 힘듦
P2 : Anomaly는 시간에 따라 달라짐
1) 지도학습
데이터 : normal 데이터(레이블O) + anomaly데이터(레이블O)
=> 잘 안 쓰임. (레이블링 이슈 + class imbalance)
2) 준지도학습
데이터 : normal 데이터(레이블O) + anomaly데이터(레이블X)
예시 : deep autoencoer 사용
훈련은 normal data(레이블O)
추론은 anomaly data(레이블x)준지도학습이란?
지도학습과 비지도학습은 들어봤어도, 준지도학습은 못들어봤을 수도 있다!
데이터 : 적은 data(레이블O)+ 대용량 data(레이블X)
3) 비지도학습
데이터 : normal 데이터(레이블X) + anomaly데이터(레이블O)
=> 다른 딥러닝 기법들보다 효과가 좋음.
학습 목표
1) DHM ( Deep Hybrid Models)
feature extractor : autoencoder
model : OC-SVM
P(C) anomaly detection에만 커스텀되어진 trainable objective의 부재
E 다른 feature들을 뽑아내기가 어려움.
S Deep-one-class classification , One class neural network (OC-NN)
S(해결책)으로 등장한 OC-NN에 대해 알아보자.
2) OC-NN(One-Class Neural Networks)
OC-NN
기존 Hybrid 방법 :
이미 학습된 딥 러닝 모델을 이용해 특징을 추출 => 추출된 특징이 이상치 탐지에 맞게 학습되었다고 할 수 없음
제안한 방법 :
학습된 Autoencoder로 특징을 추출 + 다시 전이 학습(Transfer Learning)을 이용해 재학습 => 특정 데이터의 이상치 탐지에 적합한 특징을 학습할 수 있음.
(근데 나는 이것을 잘 아직 모르는듯하다)
이상치의 종류
1) Point Anomalies
특징 : 랜덤하게 발생하는 것
2) Contextual Anomaly Detection
== conditional anomaly
특징 : 특정한 상황에서 anomalous한 것
피처 : contextual features(time & space) + behavioural features
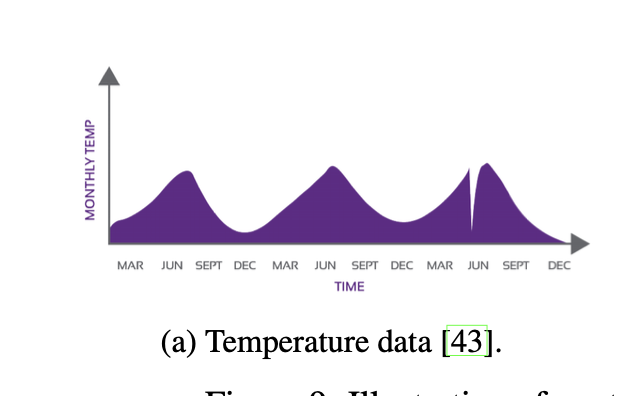
(여기서 보면 6월 이전에 갑자기 막 떨어지는 것을 볼 수 있다. 이것이 Contextual Anomaly Detection의 사례)
3) Collective or Group Anomaly Detection
== Conditional Anomalies , Group Anomalies
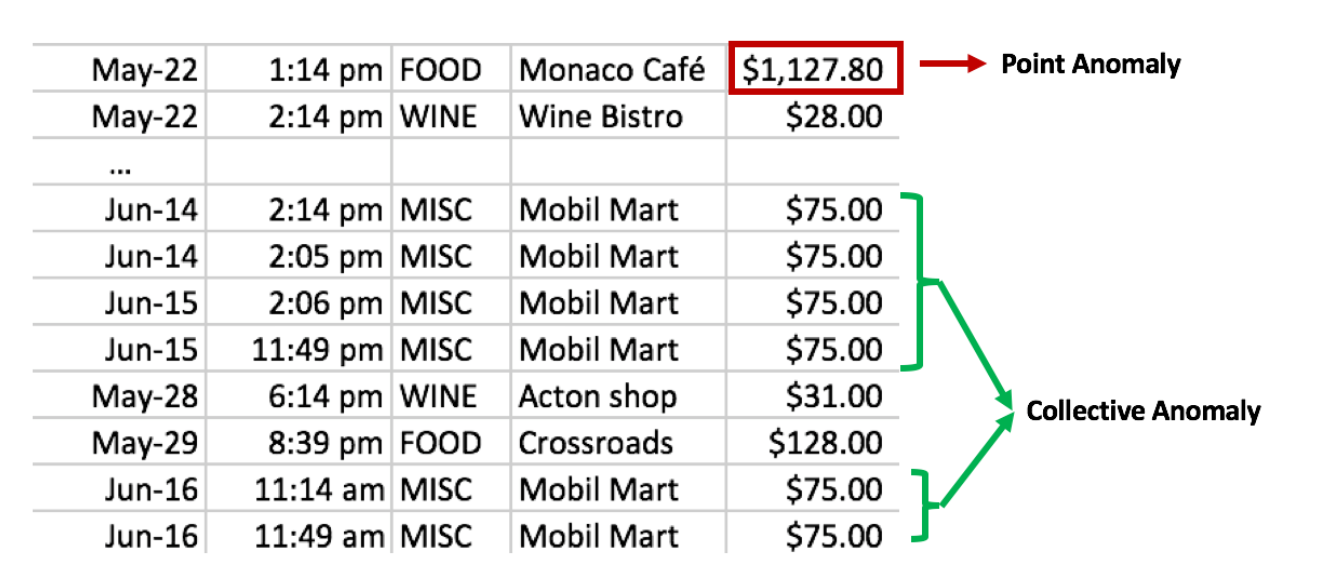
(여기서 보면, 그룹으로 anomaly라는 것을 알 수 있다)
Output
1) Anomaly Score
Anomaly Score는 각각의 데이터 포인트에 대한 outlierness의 정도!
2) Labels
2. 적용 분야
(논문의 9장에 해당하는 내용이다)
Intrusion Detection(Host-Based Intrusion Detection Systems , Network Intrusion Detection Systems) /
Fraud Detection - 신용카드에서 , 보이스 피싱 , 보험사기 /
Malware Detection - 보험 남용/
Medical Anomaly Detection /
Social Network - 스팸 발송자,온라인 사기꾼 /
Log Anomaly Detection /
IoT Anomaly Detection - 소프트웨어, RFID 등에서의 탐지 /
Industrial Anomaly Detection - 에너지시스템, 풍력 터빈에서의 damage를 찾기 위해/
Anomaly Detection in Time Series - 타임시리즈 데이터에서는 collective outlier들 존재. 하지만 정의된 패턴이 없고, 노이즈가 있을 수 있으며 , 타임시리즈 데이터의 길이가 길수록 복잡도 증가 /
Video Surveillance
3. Deep Anomaly Detection Models
(논문의 10장에 해당하는 내용이다)
Supervised deep Anomaly Detection
Assumption :
데이터 클래스를 분리!하는 것에 초점을 둚
Feature extraction + classifier network
장점 + 단점 :
좀 더 정확, 빠름
Semi-supervised deep Anomaly Detection
Assumption :
inpust dpace와 learnt feature에서 가까운 포인츠들은 같은 레벨일 가능성이 있다.
장점 + 단점 :
GAN이 semi-supervised에 쓰이면 좋은 성능
Hybrid deep Anomaly Detection
representative feautures(딥러닝 모델) + anomaly detector(svm, rbf)
Assumption : deep neural network가 관계 없는 특성들을 분리시켜줌
장점 + 단점 :
차원축소 , 효율적 ,
One-class neural network for anomaly detection
논문 내용만으로는 잘 이해가 안간다…
Un-supervised Deep Anomaly Detection
오토인코더가 그 예시이다.
Assumptions :
“정상 지역”이 구분이 됨
대부분의 데이터들은 정상 데이터
Outlier score를 거리나 밀도로 구함
장점 + 단점 :
내재된 데이터의 특징들을 배운다.
비용 절감적임.
하지만 노이즈에 굉장히 민감.
etc
전이학습 - 소스도메인에서 타겟도메인으로…! (같은 feature space와 같은 분포를 가지고 있다는 전제 하에)
제로샷 - 훈련데이터에서 보지 못한 것들을 인식하는 것을 목표로 하는 기법. 근데 데이터에 대한 natural language description이나 attributes들이 있어야하는데 그걸 얻기가 어려움.
앙상블 - robustness를 높이기 위해 오토인코더의 connectivity architecture를 다르게 하는 아이디어가 제안되었음.
클러스터링 - 비슷한 패턴들을 그룹화
강화학습 - 이상치에 대한 어떤 가정도 안하고 , 새로운 이산치들을 찾아가면서 보상을 받음.
통계 - 실시간 데이터로!
4. Deep Neural network architectures for locating anomalies
(논문의 11장에 해당하는 내용이다)
Dnn, spn, word2vec, generative, cnn , sequence , autoencoders
Spn
Cnn과 lstm둘다를 활용하여 spatio-temporal features를 뽑아냄
Word2vec
Data instances (문장들, time sequence data) 에 대항 관계를 캡처 할 수 있음. 인풋으로 워드 임베딩 피처를 얻는 것이 퍼포먼스 향상 시킨다고 나옴.
Generative models
원래의 데이터의 분포를 학습하는 것! 그래서 조금의 변화가 있는 새로운 데이터 포인트를 만들어내는 것. 이러한 gan의 특성을 사용하면 anomaly를 찾는 데에 효과적.
Cnn
복잡한 히든 feauture를 뽑아내는 것이 이상치 탐지에 도움!
Sequence model
Rnn이나 lstm으로!
Autoencoder
하나의 레이어만 사용해서 선형변환 + 비선형변환 가능
아키텍쳐를 구성하는 것은 cnn(이미지), lstm(연속적인 데이터)
이런것들 쓰면 손으로 직접 feature를 선정할 필요가 없고 raw데이터 사용 가능.
