1.Abstract = Introduction 요약. (거의 같음)
2.Introduction에서 언급하는 내용의 종류 (보통 모든 논문이 intro 에 쓰는 내용들이 있음) 파악하기.
3. Intro와 Experiment 사이에 보통 무엇을 설명하는지, 설명하는 깊이의 정도 파악하기.
4. Experiments 에서 언급하는 요소들 (실험 세팅, 실험 결과의 정도, 비교군(benchmark) 들) 파악..
Abstract
현재 : audio-text cross-model learning에 focus가 많다.
문제 : 존재하는 audio-text dataset들은 sound event에 대한 simple description만 존재한다.
해결책 : 이 논문에서는, detailed information을 분석. 그리고 그 분석을 바탕으로 자동화된 pipeline을 구축하는 것을 제안한다.
소리가 시간 도메인에서 혼합되고 연결될 수 있다는 특성을 활용하여, 우리는 오디오 혼합을 시뮬레이션할 때 시간적 관계, 소리의 크기, 화자의 정체성, 발생 횟수의 네 가지 측면에서 세부 정보를 제어.
1. Introduction
현재
Audio-text learning의 현재 : 최근 인기를 얻고 있다. visual-language learning과 비슷하게, 기계는 text의 존재 아래 더 효과적으로 audio concept들 학습한다.
문제
문제 : Human-Annotated data의 부재
해결책1 : template나 generative model - category label -> caption으로 바꾸기
해결책1에 대한 문제 : text description들이 sound event에만 limited되었다. detailed information은 X
소리 : 경적 소리 -> caption : “a horn blares”
이건, 발생 시간과 같은 세부정보는 무시한 것임. 발생 횟수 이런 것도 무시한 것.
해결책2 : 인간이 diverse audio sample들에 coherent,detailed caption제공
해결책2에 대한 문제 : 불가하다. 이미지에서는 명확 <> 오디오에서는 명확하지 않음. 오히려 명확하지 않은 audio-text pair들은 training의 품질을 떨어뜨릴 것.
해결책3 : 세부 정보를 제어하고 해당 세부 정보에 기반하여 캡션을 생성하는 시뮬레이션 프레임워크
프레임워크
- AudioCaps를 기반으로 오디오-텍스트 시뮬레이션에서 사용할 청각적 세부 정보 분류 체계를 만듦.
1) a detailed sound event taxonomy 확립
설명 가능한 청각적 세부 정보와 이에 해당하는 소리 범주를 포함하는 상세한 소리 사건 분류 체계를 확립
이 분류 체계는 인간이 작성한 주석을 분석하고, AudioCaps 데이터셋을 클러스터링하여 만들어짐.
2) Sound Description detail 요약
그런 다음, AudioCaps의 캡션을 분석하여 일반적으로 소리를 설명할 때 사용되는 세부 정보와 각 세부 정보에 적용 가능한 소리 사건을 요약했습니다.
3) 구체적인 방법 (Simulation)
- Freesound 플랫폼에서 단일 소리 사건을 선별합니다.
- 단일 소리 사건을 혼합하여 다중 소리 사건 오디오를 시뮬레이션합니다. 이는 음성 처리에서 사용되는 방식과 유사합니다.
- 시뮬레이션 과정에서 생성된 메타데이터(예: 발생 횟수 등)는 ChatGPT를 통해 자연어 텍스트로 변환됩니다.
4) 효과
- 이렇게 하여 상세하고 잘 정렬된 오디오-텍스트 데이터를 만들 수 있습니다.
개념 증명으로, 우리는 시뮬레이션된 데이터가 오디오 캡셔닝에 미치는 효과를 검증했습니다. - 소량의 시뮬레이션 데이터를 사용하여 모델을 미세 조정한 결과, 모델이 더 상세한 캡션을 생성할 수 있게 되었습니다.
- 우리가 제안한 파이프라인은 캡셔닝 향상뿐만 아니라 오디오 생성 및 크로스모달 이해 측면에서 오디오-텍스트 간의 세부 정보를 개선하는 데도 유망합니다.
결국,
Summarization -> Simulation
이 흐름을 잘 기억해두면 된다. 일단 소리 사건을 요약을 하고 나서 Simulation을 하는 것이 목적.
2. Auditory Detail Taxonomy Based On Human Perception
Taxonomy 구축하기 ( 분류 체게 구축하기 )
아까 Summarization -> Simulation이라고 했으니,
일단, Simulation부터 보자.
2.1 Sound Event Categories from Text Clustering
문제점
[19] J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in Proc. IEEE ICASSP, 2017, pp. 776– 780.
[20] H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vg- gsound: A large-scale audio-visual dataset,” in Proc. IEEE ICASSP, 2020, pp. 721–725.
이 논문들에서의 문제점이 있었으니...
1) 중복 존재
다른 카테고리임에도 불구하고 overlap이 있었음...
2) 유사성 존재
들리기에 비슷한 catergory도 다른 이벤트라고 다뤄졌다.
물론, 사람의 귀에는 다른데...
결과
=> audio-text 를 simulating하는 것은 Challenge하다.
=> training할 때도 문제가 된다. (비슷한 소리를 가지고 전혀 다른 caption을 만들어내니까)
해결책
CLustering하기!!
인간 annotated caption들(AudioCaps)을 clustering 한다.
- sound event phrases extract하기
- CLAP embedding으로 변환
- K-means (64) .
- 이때 대표 레이블은 chatGPT를 통해 query됨.
2.2 Details in Sound Descriptios
이건 Summarization!!!
해결책
- AudioCaps에 POS tagging하기
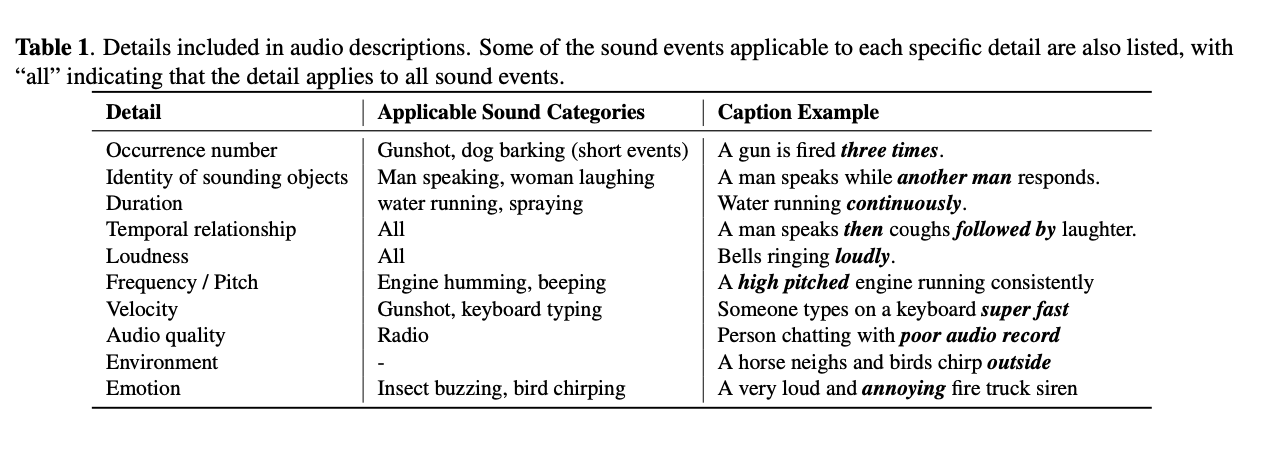
duration, loudness : single event와 관련
temporal relationship : different events와 관련
occurance number : short-duration event에만 적용 가능
identity : 인간이 말할 때의 사건들에만 적용가능
=> 따라서, 이러한 요약된 것을 바탕으로 Simulation에 적용하는 것임!!
예시
캡션 분석 및 분할:
"A dog is barking loudly and a car horn is honking."
분할: ["A dog is barking loudly", "a car horn is honking"]
CLAP 임베딩 및 클러스터링:
"A dog is barking loudly" -> 임베딩 벡터화
"a car horn is honking" -> 임베딩 벡터화
클러스터링 결과: ["dog barking", "car horn honking"]
품사 태그 적용:
"A dog is barking loudly" -> "dog", "barking" (명사/동사), "loudly" (부사)
"a car horn is honking" -> "car horn" (명사), "honking" (동사)
세부 정보 요약:
"loudly" -> 소리 크기
소리 이벤트와 연결: "dog barking"에 "loudly" 적용 가능
그래서 결국,
2.1의 Sound Event Categories from Text Clustering은 말 그 자체로, 소리의event categories를 분류하는 거고!!
2.2의 Details in Sound Descriptions는 말 그대로 소리 이벤트에 대한 Detail을 추출하는 거다!!!
2.1은 이 소리를 어떤 소리로 분류하지? 2.2는 여기서 어떤 details(특징)이 있는 걸까??
3. Detailed Audio-Text Simulation Pipeline
3.1 Single-Event Sound Curation
문제점
소리 사건 데이터의 품질이 낮음. (배경소음이 있다)
해결책
FreeSound의 소리는 clean하다.
1. Search Query 작성
2. FreeSound에서 소리 획득하기
3. 시간에 따라 필터링
너무 짧은 거 혹은 너무 긴 거는 버림.
4. 모델로 필터링
TAG 모델 : 대상 소리 이벤트가 발생하는 시간을 감지합니다. 비대상 소리 구간이 너무 긴 클립은 제외하거나 여러 구간으로 나눈다.
CLAP 모델 : 오디오 클립과 이벤트 설명 간의 유사도 점수를 계산하여, 점수가 낮은 클립을 제외.
=> 이 두개의 thresholds는 경험적으로 selected 되었다.
5. 최종 데이터 : 115개의 sound event들이 있고 각각 50개 넘는 sample들!!
결국, 데이터의 품질과 양 사이에서 균형을 맞추기 위해 자동화된 파이프라인을 사용한다. 즉, 고품질 데이터를 수집하려면 필터링을 많이 해서 데이터 양이 줄어들 수 있고, 데이터를 많이 수집하려면 필터링을 덜 해서 데이터의 품질이 떨어질 수 있는데, 이 둘 사이에서 적절한 균형을 맞춘다는 의미!
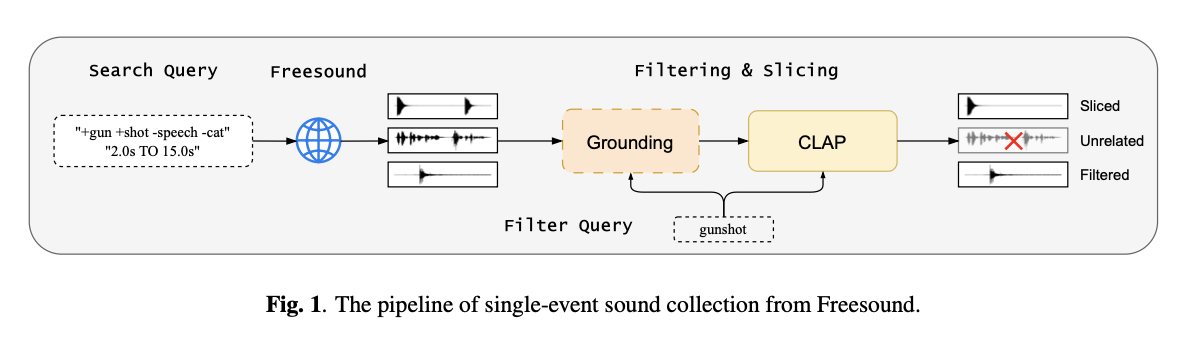
어떻게 두개의 thresholds가 경험적으로 select된거지? 흠...너무 생략됐따.
3.2 Audio-Text Simulation Pipeline
준비물 : single event들 + summarized audio details
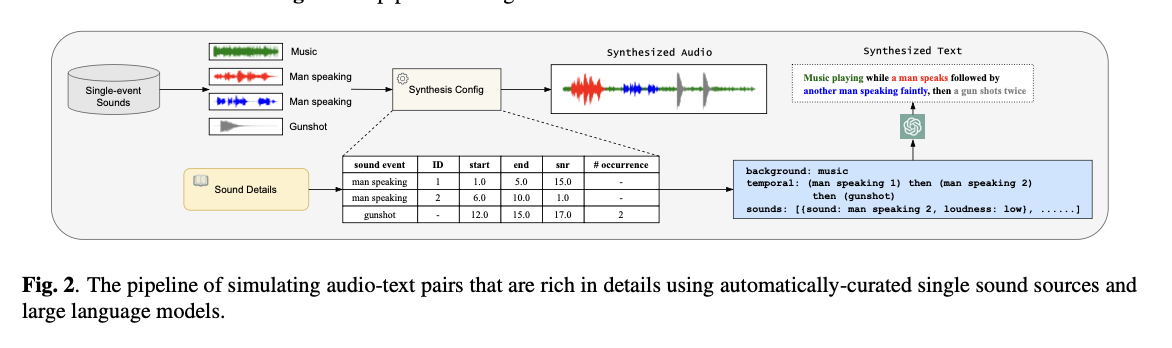
1. random하게 saple sound event를 뽑는다.
2. detail들을 바탕으로 random하게 attribute를 뽑는다.
3. audio mixture가 simulate된다.
이때, background noise는 추가하지 않는다.
4. 메타 데이터 생성
5. 메타 데이터를 chatGPT를 활용해 인간 주석 스타일로 변환한다.
4. Experimental Setup
5. Results
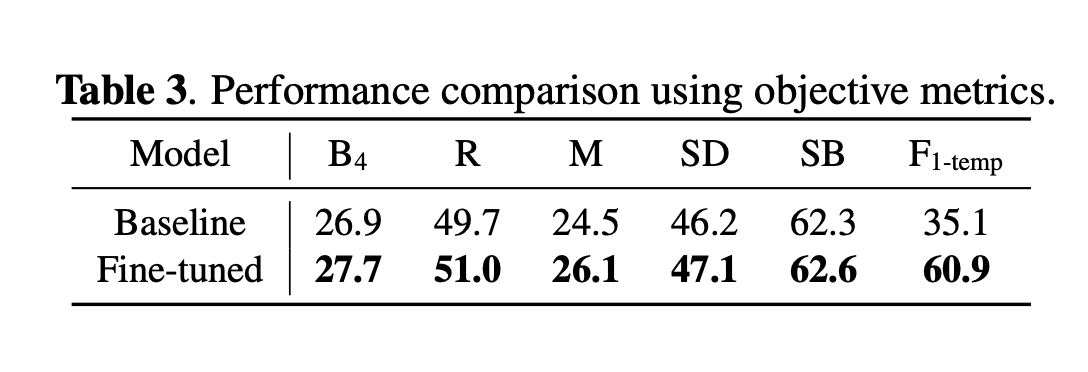
5.1 Objective Metrics
Captioning Metrics : BLEU-4 (B4), ROUGE (R), METEOR (M), SPIDEr (SD) and SentenceBERT (SB),F1
(FENSE는 포함하지 않음. grammar error penalties는 적용하지 않는다.)
(F1은 temporal relationship을 evalutate하기 위해서.)
identity나 occurance number의 경우, 적합한 metric이 없기 때문에 human evaluation을 진행한다.
F1에 관해, 그리고 Metric들에 관해 자세하게 공부를 할 필요성이 있다.
5.2 Human Evaluation
일단 baseline에서 20개를 뽑고, fine-tuned된 모델에서 20개의 sample들을 뽑는다.
결과적으로,
fine-tune된 모델에서 생성된 caption들이 더 accurate (detail들을 많이 포함하고 있음)

: fine-tune된 모델이 좀 더 detail함.
해결해야할 문제 :
시뮬레이션된 데이터와 실제 데이터 간의 분포 차이로 인해 발생하는, 입력 오디오에 존재하지 않는 세부 정보를 모델이 생성하는 문제를 해결하는 것.
6. Conclusion
개인적으로 느낀 점.
논문을 한번 읽고는 과연 이게 뭔말인가 이해가 잘 안갔음. 구체적으로 어떻게 시각화를 한다는 건지...?
