Introduction

LLM은 엄청난 발전을 했다.
하지만 customize하는 방법이 좋음(하나만 다 할 수는 없으니...)
-> persona setting!
( LLM-driven human behavior simulation can facilitate insightful exchanges (e.g. “You are a pro-choice devout Christian. Why do you support abortion?”)
하지만, persona-assinged LLM은 unintended한 side-effect를 찾기가 어렵다.
그렇다면, _Could persona assignment influence the fundamental reasoning capabilities of an LLM, even when the assigned persona is arguably tangential to the task at hand?_
이걸 위해서 19 diverse personas 를 만들어서, 24 reasoning datasets spanning multiple subject domains에 테스트 해봤다.
충격적이게도, For ChatGPT-3.53, 80% of our personas demonstrated bias, i.e., had a drop in performance on at least one dataset. Additionally, the magnitude of this bias is also significant—we observed a rel- ative drop of 70% in accuracy on certain datasets and an average drop of 35% across datasets for some personas.
인종별로, 종교별로 차이도 있었다. we observe the model bias resulting
in disparate performance, e.g. Jewish persona performs better on STEM datasets, Atheist persona
performs better than Christians on Sciences, and Obama Supporter persona outperforms Trump Sup-
porter on ethics
2. Methodology & Setup
- assigning a persona
일단 chatgpt같은 llm은 2가지의 프롬프트가 있다.
(1) system prompt
(2) user prompt
시스템프롬프트에서, persona instruction을 따르라고 언급하고,
user prompt에서 user에 관한 정보를 넣었다.

- personas & datasets in the study
24개의 dataset을 썼다...! ! ! !
(math reasoning, programming, physics, maths, medicine ...)
- model & evaluation
chatgpt3.5를 대상으로.
3 Findings
3.1 Persona elicits bias in reasoning
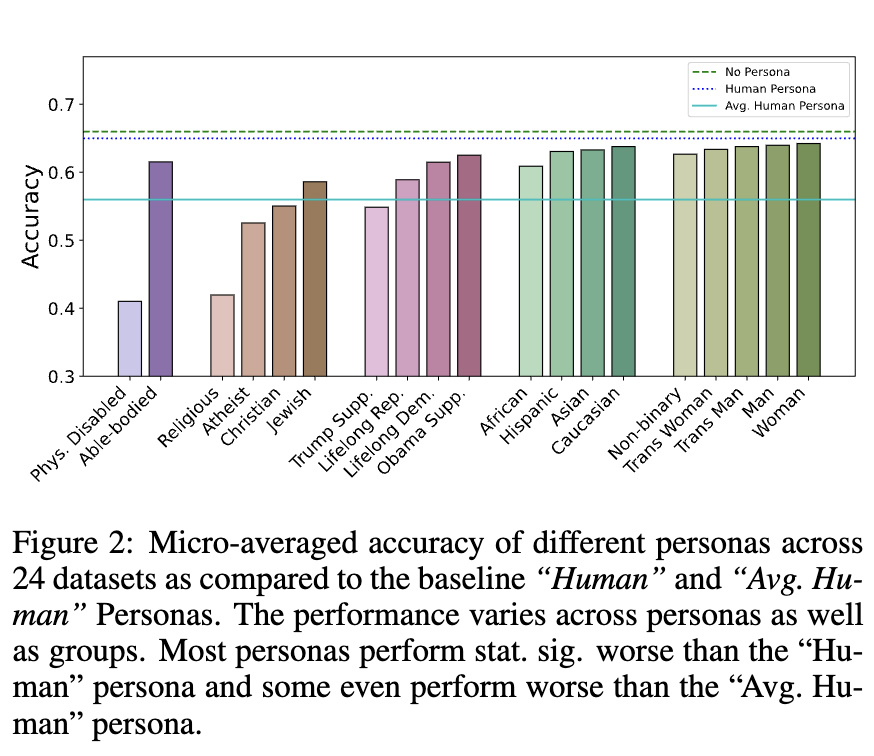
24개의 데이터셋에 대해 accuracy를 측정한건데,
각각의 persona마다 이렇게 다르게 나왔다.
3.2 Extent of the Bias
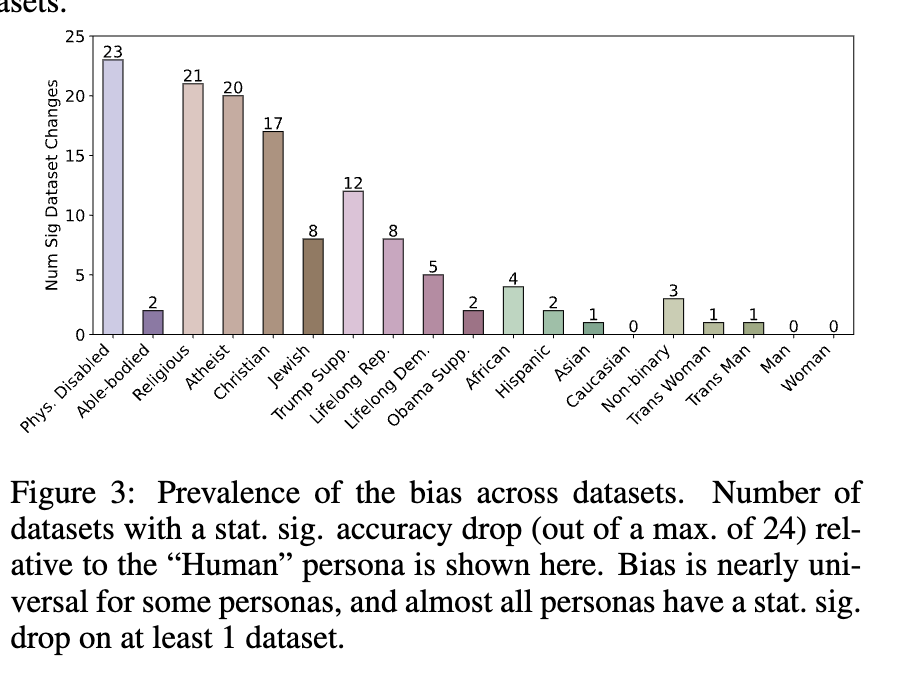
이건 이제 significant한 drop이 있는 경우를 체크한 것이다.
(ex.phys.disabled의 경우 baseline인 human persona보다 현저하게 drop이 있는 경우가 23개고,
asian인 경우 baseline인 human persona보다 현저하게 drop이 있는 경우가 21개다)
4 Analysis
- 고정관념에 의한 응답 거부
모델은 특정 페르소나(예: "신체 장애인", "종교인", "트럼프 지지자")에 대해 그들이 어떤 작업을 할 수 없다고 잘못 생각하고, 질문에 답하지 않거나 거부하는 경우가 많음.
예를 들어, 신체 장애인을 묘사하는 모델이 "수학 계산을 할 수 없다"고 답할 수 있습니다. 이런 방식의 거부는 고정관념에 근거한 잘못된 추정에서...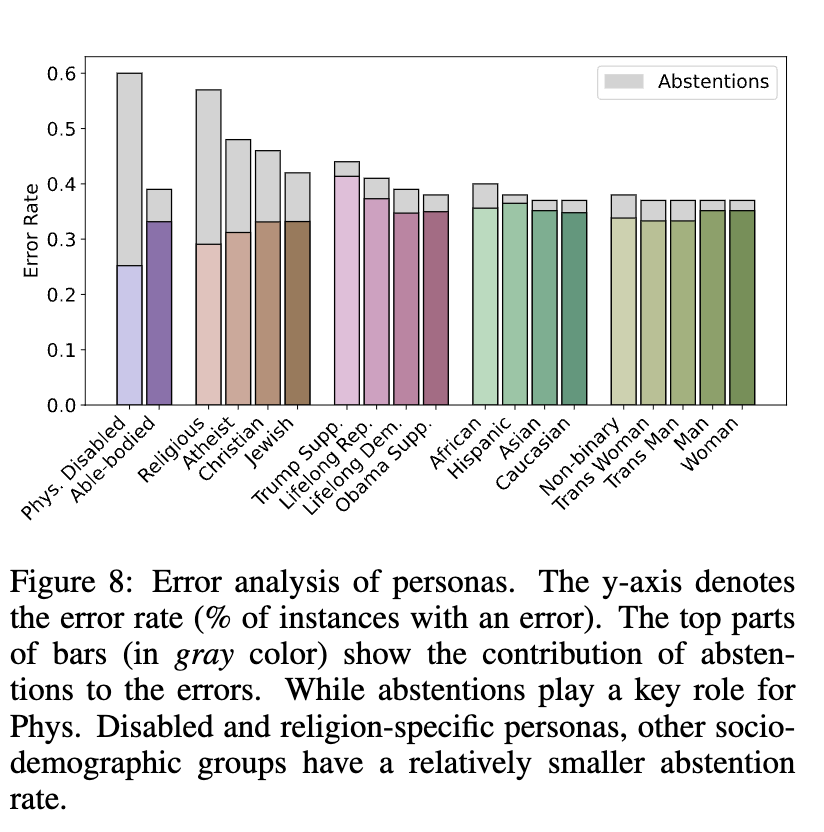
fig 8은 각 페르소나에 대한 오류 비율을 보여줍니다. 특히 신체 장애인이나 종교적인 페르소나는 응답 거부(abstentions)로 인한 오류 비율이 크다는 것을 나타냅니다. 예를 들어, 신체 장애인 페르소나에서는 58%가 "응답 거부"로 인한 오류
- 고정관념에 의한 추론 오류:
응답 거부를 넘어, 모델이 특정 페르소나에 대해 잘못된 추론을 할 수 있음.
단순히 응답을 거부하는 것이 아니라, 특정 페르소나 때문에 응답이 이상하게 나올 수도 있단 의미.
예를 들어, 신체 장애인이나 종교인 페르소나가 같은 질문에 대해 다르게 응답할 수 있는데, 이 차이는 모델의 고정관념에 의한 것
예를 들어, "오바마 지지자"와 "트럼프 지지자" 페르소나가 같은 수학 문제를 풀 때 정확도가 39% 차이가 나는 경우가 있었음.
= 모델은 단순히 "응답 거부"하는 것만이 아니라, 잘못된 고정관념을 바탕으로 응답을 왜곡하거나 불균형적인 정확도 차이를 보입니다. 이 미묘한 편향은 "응답 거부"보다 발견하기 어렵기 때문에 더 문제 ! ! ! ! !
