
📚 서론
본격적으로 데이터베이스 관련 수업이 시작했다. 이번 포스트에서는 데이터 형식, DDL, DML, DCL, TCL 등에 대해 정리했다.
📘 SQL
📗 데이터 형식
📕 문자형 데이터 형식
- CHAR(n): 고정 길이 문자열 데이터 타입이다.
- VARCHAR(n): 가변 길이 문자열 데이터 타입이다. (최대 n개까지의 문자)
- TINYTEXT(n) : 문자열 데이터 타입 최대 255 byte
- TEXT: 긴 문자열 데이터 타입이다. 크기가 가변적이며 길이 제한이 없어 자유롭게 값을 받을 수 있다.
CREATE TABLE 예시테이블 (
id INT PRIMARY KEY,
name CHAR(20),
intro VARCHAR(100),
memo TINYTEXT(200),
detail TEXT
);
📕 숫자형 데이터 형식
- INT, INTEGER(4 byte), SMALLINT(2 byte), BIGINT(8 byte): 정수형 데이터 타입이다.
- FLOAT(n), REAL, DOUBLE: 부동 소수점 숫자 데이터 타입이다.
- DECIMAL(i, j), NUMERIC(i, j): 고정 소수점 숫자 데이터 타입이다.
CREATE TABLE 주문 (
주문번호 INT PRIMARY KEY,
고객명 VARCHAR(50),
주문일자 DATE,
총금액 DECIMAL(10, 2),
할인율 FLOAT,
수량 INTEGER,
재고량 BIGINT,
평균평점 REAL
);
INSERT INTO 주문 (주문번호, 고객명, 주문일자, 총금액, 할인율, 수량, 재고량, 평균평점)
VALUES (1, '홍길동', '2023-08-04', 50000.00, 0.1, 3, 1000000, 4.5),
(2, '김철수', '2023-08-04', 75000.00, 0.05, 2, 500000, 4.8),
(3, '이영희', '2023-08-03', 120000.00, 0.2, 5, 800000, 4.2);
📕 날짜형 데이터 형식
- DATE: 날짜 데이터 타입이다. YY-MM-DD
- TIME: 시간 데이터 타입이다. hh:mm:ss
- DATETIME: 날짜 및 시간 데이터 타입이다.
- TIMESTAMP: 날짜 및 시간 데이터 타입이다.
CREATE TABLE 직원 (
사번 INT PRIMARY KEY,
성명 VARCHAR(50),
입사일 DATE,
퇴사시각 TIME,
생년월일 DATETIME,
최근변경 TIMESTAMP
);
INSERT INTO 직원 (사번, 성명, 입사일, 퇴사시각, 생년월일, 최근변경)
VALUES (101, '홍길동', '2023-08-04', '18:30:00', '1990-03-15 12:30:00', CURRENT_TIMESTAMP),
(102, '김철수', '2023-08-04', '09:15:00', '1985-11-25 08:45:00', CURRENT_TIMESTAMP),
(103, '이영희', '2023-08-03', '17:00:00', '1992-06-10 14:20:00', CURRENT_TIMESTAMP);
📗 DDL data definition language 데이터 정의어
데이터베이스, 테이블, 인덱스 등의 구조를 정의하는 명령어
📕 CREATE
새로운 데이터베이스, 테이블, 인덱스 등을 생성
제약조건
- PRIMARY KEY: 기본 키 제약 조건으로, 해당 열은 유일한 값을 가져야 한다. 개체 무결성 제약조건 명세
- UNIQUE: 해당 열의 값이 유일해야 한다. 대체 키를 명세, 후보 키, null 값은 중복가능하다.
- NOT NULL: 해당 열의 값은 NULL일 수 없다.
- FOREIGN KEY: 외래 키 제약 조건으로, 다른 테이블과 연결된 열을 지정한다. 참조 무결성 제약조건 명세
- option 에 set null, set default, cascade
- on delete set null
- 참조 튜플(열 값)이 삭제되면 null로 설정
- on update cascade
- 참조 튜플(열 값)이 갱신되면 갱신된 값이 파급적으로 갱신됨
- CHECK: 해당 열의 값이 주어진 조건을 만족해야 한다. 제약조건을 명세
- DEFAULT : 투플 생성시 애트리뷰트의 초기값
- ON UPDATE : 투플이 업데이트시마다 애트리뷰트의 변경값
CREATE TABLE 테이블명 (
id INT PRIMARY KEY AUTO_INCREMENT, -- PRIMARY KEY 제약: id 컬럼은 고유한 값이어야 한다.
name VARCHAR(50) NOT NULL UNIQUE, -- NOT NULL 및 UNIQUE 제약: name 컬럼은 NULL이 아니어야 하며, 중복된 값이 없어야 한다.
age INT CHECK (age >= 0), -- CHECK 제약: age 컬럼 값은 0 이상이어야 한다.
address VARCHAR(100), -- 일반 컬럼 (제약 없음)
other_table_id INT, -- FOREIGN KEY 제약: 다른 테이블과 연결된 외래키이다.
other_column VARCHAR(50) DEFAULT '기본값', -- DEFAULT 제약: 컬럼의 초기값은 '기본값'이다.
last_updated TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, -- ON UPDATE 제약: 튜플이 업데이트될 때마다 해당 컬럼의 값을 현재 시간으로 갱신한다.
FOREIGN KEY (other_table_id) REFERENCES 다른테이블명(참조컬럼) -- 참조 무결성 제약: other_table_id 컬럼은 다른테이블명 테이블의 참조컬럼과 관계를 맺는다.
ON DELETE SET NULL -- 참조 튜플이 삭제될 때 other_table_id를 NULL로 설정한다. (옵션: SET NULL, SET DEFAULT, CASCADE)
ON UPDATE CASCADE -- 참조 튜플이 업데이트될 때 other_table_id의 값을 자동으로 갱신한다.
);
📕 ALTER
RESTRICT: 참조하는 뷰나 제약조건이 있으면 실행 실패CASCADE: 참조 뷰나 제약조건도 모두 삭제한다.
이미 존재하는 데이터베이스, 테이블, 인덱스 수정
-- 테이블에 새로운 열 추가
ALTER TABLE 테이블명 ADD COLUMN 열이름 데이터유형;
-- 테이블의 열 데이터 유형 변경:
ALTER TABLE 테이블명 MODIFY COLUMN 열이름 새로운_데이터유형;
-- 테이블의 열 이름 및 데이터 유형 변경
ALTER TABLE 테이블명 CHANGE COLUMN 기존_열이름 새로운_열이름 새로운_데이터유형;
-- 테이블에서 열 삭제
ALTER TABLE 테이블명 DROP COLUMN 열이름;
-- 테이블의 인덱스 제거
ALTER TABLE 테이블명 DROP INDEX 인덱스_이름;
-- 테이블에 기본 키 설정
ALTER TABLE 테이블명 ADD PRIMARY KEY(기본_키_열_이름);
-- 테이블에서 기본 키 제거
ALTER TABLE 테이블명 DROP PRIMARY KEY;
-- 테이블 이름 변경
ALTER TABLE 기존_테이블명 RENAME 새로운_테이블명;📕 DROP
존재하는 데이터베이스, 테이블, 인덱스 삭제
RESTRICT: 참조하는 뷰나 제약조건이 있으면 실행 실패
-- 데이터베이스를 삭제하고자 할 때, 해당 데이터베이스에 참조하는 테이블이나 뷰가 있으면 삭제를 중단한다.
DROP DATABASE IF EXISTS my_database RESTRICT;
-- 테이블을 삭제하고자 할 때, 해당 테이블을 참조하는 뷰가 있거나 다른 테이블의 외래 키로 사용되면 삭제를 중단한다.
DROP TABLE IF EXISTS my_table RESTRICT;
-- 인덱스를 삭제하고자 할 때, 해당 인덱스를 사용하는 테이블이나 뷰가 있으면 삭제를 중단한다.
DROP INDEX IF EXISTS my_index_name RESTRICT;CASCADE: 참조 뷰나 제약조건도 모두 삭제한다.
-- 데이터베이스를 삭제하고자 할 때, 해당 데이터베이스에 참조하는 테이블이나 뷰가 있으면 함께 삭제한다.
DROP DATABASE IF EXISTS my_database CASCADE;
-- 테이블을 삭제하고자 할 때, 해당 테이블을 참조하는 뷰가 있거나 다른 테이블의 외래 키로 사용되면 함께 삭제한다.
DROP TABLE IF EXISTS my_table CASCADE;
-- 인덱스를 삭제하고자 할 때, 해당 인덱스를 사용하는 테이블이나 뷰가 있으면 함께 삭제한다.
DROP INDEX IF EXISTS my_index_name CASCADE;
📕 TRUNCATE
테이블에 저장된 모든 데이터 삭제 (튜플 삭제)
-- "employees" 테이블의 모든 데이터를 삭제한다.
TRUNCATE TABLE employees;📕 DESCRIBE
테이블의 구조 확인
show columns 를 사용해서 테이블의 구조 확인
-- "employees" 테이블의 구조를 확인
DESCRIBE employees;
-- 또는 다음과 같이 SHOW COLUMNS 문을 사용하여 구조를 확인할 수도 있다.
SHOW COLUMNS FROM employees;📕 RENAME
테이블, 뷰, 인덱스의 이름 변경
-- "old_table" 테이블의 이름을 "new_table"로 변경한다.
RENAME TABLE old_table TO new_table;📗 DML data manipulation language 데이터 조작어
테이블에 데이터를 삽입, 수정, 삭제, 검색하는 명령어
📕 SELECT
테이블에서 데이터 조회
- select 의 기본구조는 select - from - where 이다.
-- "employees" 테이블에서 연봉이 50000 이상인 직원들의 이름과 연봉을 선택
SELECT 이름, 연봉
FROM employees
WHERE 연봉 >= 50000;- order by 사용시
-- "products" 테이블에서 가격이 높은 상품을 내림차순으로 선택
SELECT 상품명, 가격
FROM products
ORDER BY 가격 DESC;- % 를 사용한 문자열 검색의 경우
-- "customers" 테이블에서 이름이 "김"으로 시작하는 고객을 선택
SELECT *
FROM customers
WHERE 이름 LIKE '김%';
-- "products" 테이블에서 상품명에 "티셔츠"라는 문자열이 포함된 상품들을 선택
SELECT *
FROM products
WHERE 상품명 LIKE '%티셔츠%';distinct를 사용한 중복 제거
-- "employees" 테이블에서 중복된 직급 정보를 제거하여 선택
SELECT DISTINCT 직급
FROM employees;- IS NULL 과 <> 차이
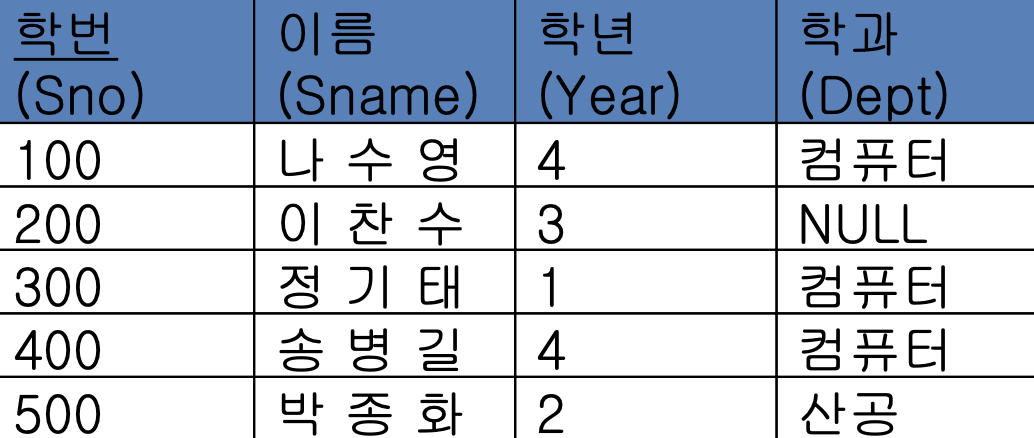
SELECT sno, sname
FROM student
WHERE dept is NULL;위 sql 문 실행 결과는 이찬수에 해당하는 row 가 출력될 것이다.
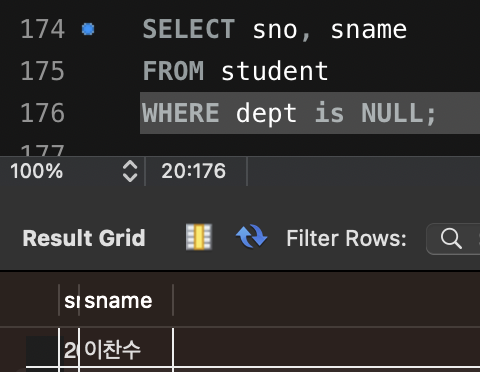
SELECT Sno, Sname
FROM Student
WHERE Dept <> '컴퓨터';그렇다면 위의 sql 문 실행결과는 어떻게 될까?
실행해보면 박종화에 해당하는 row 가 출력된다.
<> 는 not equal 이며 NULL 은 항상 false 이므로 <> 의 결과에 해당하지 않는다.
- 집계 함수(COUNT, AVG, MIN, MAX, SUM) 사용시
-- "orders" 테이블에서 주문 건수를 선택
SELECT COUNT(*) AS 주문건수
FROM orders;
-- "sales" 테이블에서 매출 평균을 선택
SELECT AVG(매출액) AS 평균매출
FROM sales;
-- "products" 테이블에서 최저가 상품을 선택
SELECT MIN(가격) AS 최저가
FROM products;
-- "employees" 테이블에서 최고 연봉을 선택
SELECT MAX(연봉) AS 최고연봉
FROM employees;
-- "sales" 테이블에서 총 매출액을 선택
SELECT SUM(매출액) AS 총매출액
FROM sales;
집계함수가 select 절에 나오면 일반 애트리뷰트는 select 에 나올 수 없고 동시에 여러 개의 집계함수를 사용할 수는 있다.
- group by 사용시
SELECT Cno, AVG(Midterm) AS m_avg
FROM Enrol
WHERE Final >= 80
GROUP BY Cno
HAVING COUNT(*) >= 3
ORDER BY m_avg DESC;group by 절 사용시, select 절에는 집계함수 이외에 그룹 애트리뷰트만 나올 수 있다.
group by 는 반드시 집계함수와 함께 사용한다.
having 은 각 그룹에 대해 필터링 조건을 명세하며 집계함수를 사용한 불린 표현식을 표현하는 게 일반적이다.
limit : 표현할 결과의 최대 개수를 제한한다.
offset : 표현할 결과를 나타내기 시작할 위치를 설정한다.
📕 INSERT
테이블에 데이터 삽입
INSERT INTO 테이블명 VALUES
(값1, 값2, 값3),
(값4, 값5, 값6);문자의 경우 값을 ''로 감싼다.
📕 UPDATE
테이블에 저장된 데이터 수정
해당 테이블에서 where 절의 조건을 만족하는 레코드의 값만을 수정한다.
update user
set name='james'
where age > 15;📕 DELETE
테이블에 저장된 데이터 삭제
해당 테이블에서 where 절의 조건을 만족하는 레코드만을 삭제한다.
delete from user
where age > 15;| truncate | delete |
|---|---|
| 데이터베이스 테이블의 모든 데이터 삭제 | 테이블에서 특정 조건을 만족하는 행들을 삭제 |
| 테이블의 모든 레코드를 한번에 삭제 | 조건에 맞는 행들을 하나씩 찾아가 삭제하기에 truncate 보다 느리다 |
| 트랜잭션 로그를 유지하지 않고 테이블 자체를 초기화하기에 롤백 불가 | 각 행을 삭제할 때마다 트랜잭션 로그를 유지하기에 롤백 가능 |
| 테이블의 스키마는 유지되나 데이터가 모두 삭제 | 스키마와 인덱스가 유지되며 조건에 맞지 않는 데이터만 삭제 |
📗 WHERE 절 연산자
📕 비교 연산자
=: 같다>, >=: 크다, 크거나 같다.<, <=: 작다, 작거나 같다.
📕 부정 연산자
!=: 같지 않다.^=: 같지 않다.<>: 같지 않다.NOT 칼럼명=: ~와 같지 않다. => ?
📕 SQL 연산자
BETWEEN a AND b: a, b 값 사이에 있으면 참 (a, b 포함)IN (list): 리스트에 있는 값 중에서 어느 하나라도 일치하면 참LIKE 비교문자열: 비교문자열과 일치시 사용%: 0 개 이상의 어떤 문자_: 1개의 단일 문자
IS NULL: NULL 값인 경우 true, 아니면 false
📕 논리 연산자
AND: 앞과 뒤의 조건이 모두 참이어야 참OR: 하나라도 참이면 참NOT: 반전
📗 DCL data control language 데이터 제어어
데이터베이스 사용자의 권한을 부여하거나 취소하는 명령어
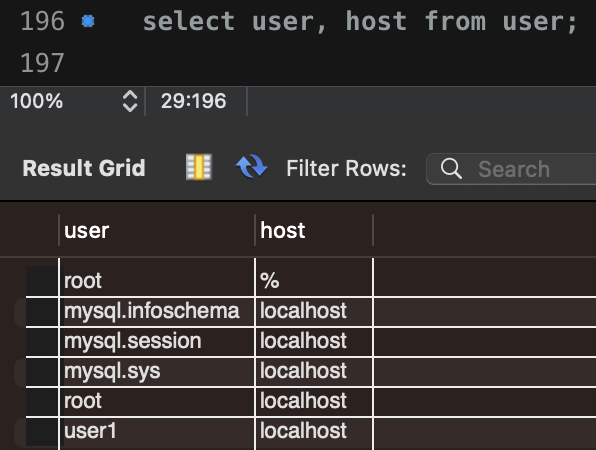
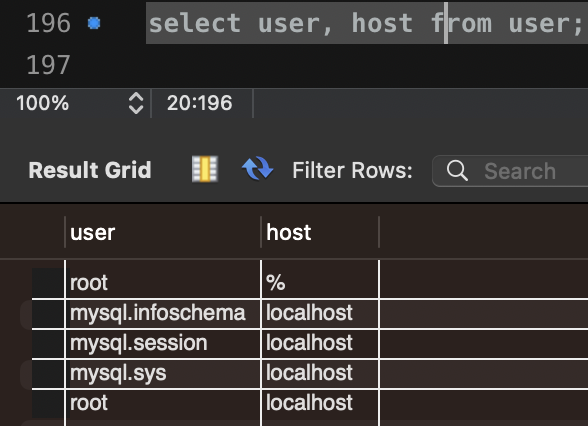
사용자 목록 조회
use mysql;
select user, host from user;
사용자를 추가하면서 접근 권한 제한
-- 사용자를 추가하면서 패스워드까지 설정
create user '사용자ID'@localhost identified by '비밀번호';
-- '%' 는 외부에서의 접근을 허용함을 의미
create user '사용자ID'@'%' identified by '비밀번호';
-- 사용자 삭제
drop user '사용자ID'@localhost;사용자 추가시
사용자 제거시
📕 GRANT
데이터베이스 사용자에게 권한 부여
권한 조회
show grants for {username}@{ip};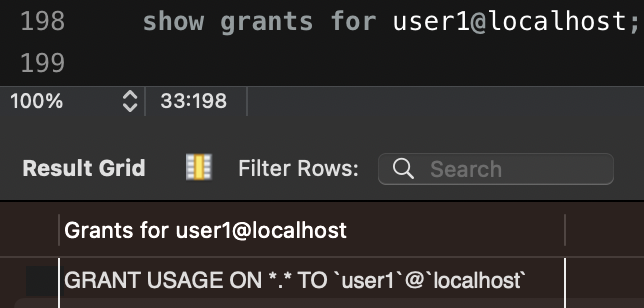
USAGE권한 지정자는 권한이 없음을 나타낸다.
권한 추가
grant {권한} privileges on {스키마}.{테이블} to {username}@{ip};권한에
all지정시 모든 권한 부여,select, insert지정시 select, insert 권한 부여
grant all privileges on *.* to {username}@{ip};
grant select, insert on {스키마}.* to {username}@{ip};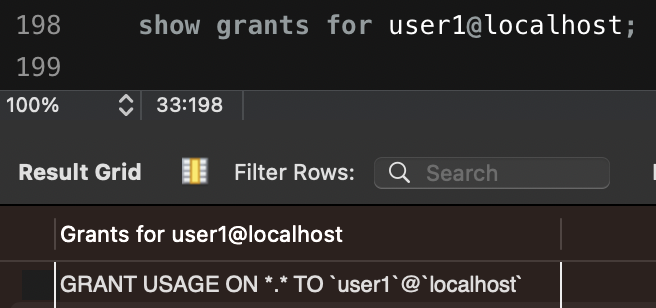
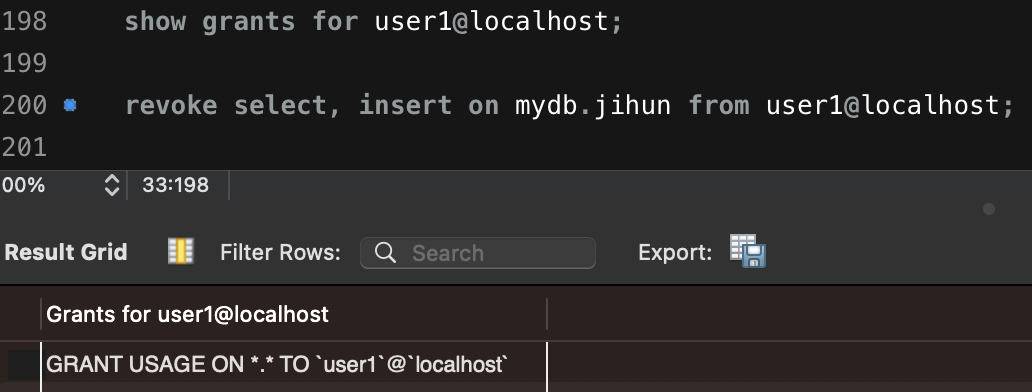
📕 REVOKE
데이터베이스 사용자의 권한 취소
revoke {권한} privileges on {스키마}.{테이블} from {username}@{ip};
📗 TCL transaction control language 트랜잭션 제어어
📕 COMMIT
트랜잭션 성공적으로 완료후 데이터베이스에 결과 반영
📕 ROLLBACK
트랜잭션 취소후 이전 상태로 되돌린다.
select, insert 는 트랜잭션이 가능하나 drop, alter 의 경우 롤백 기능을 지원하지 않고 바로 자동 commit 된다.
select * from jihun;
start transaction;
insert into jihun values ('트랜잭션', '8o4bkg2', '트랜잭션이름', 'M', '1990-03-31', '33');
select * from jihun;
rollback;
select * from jihun;
commit;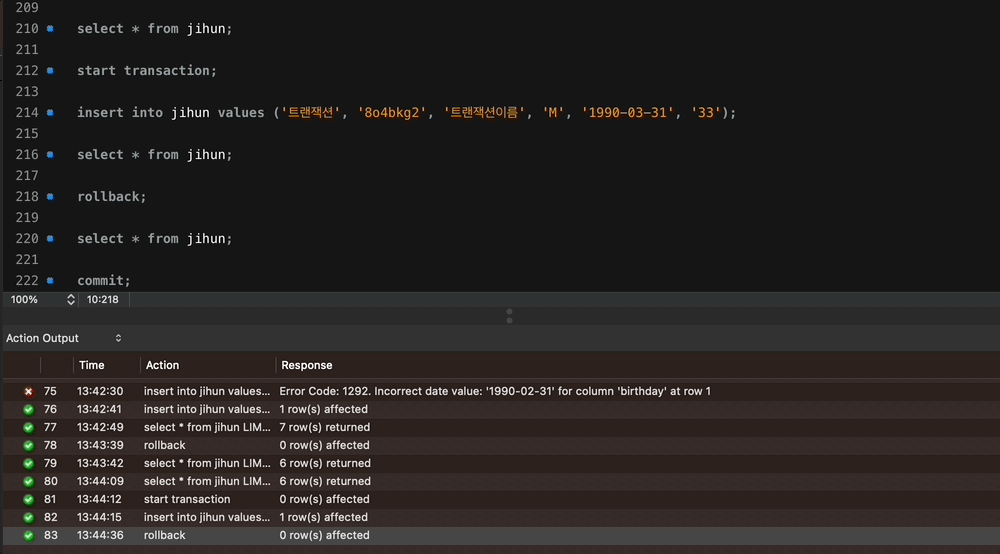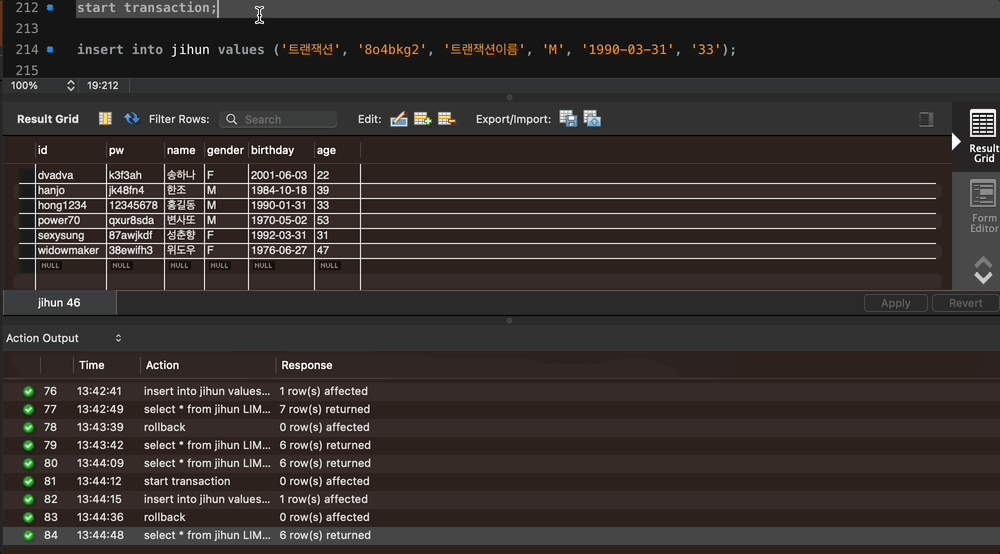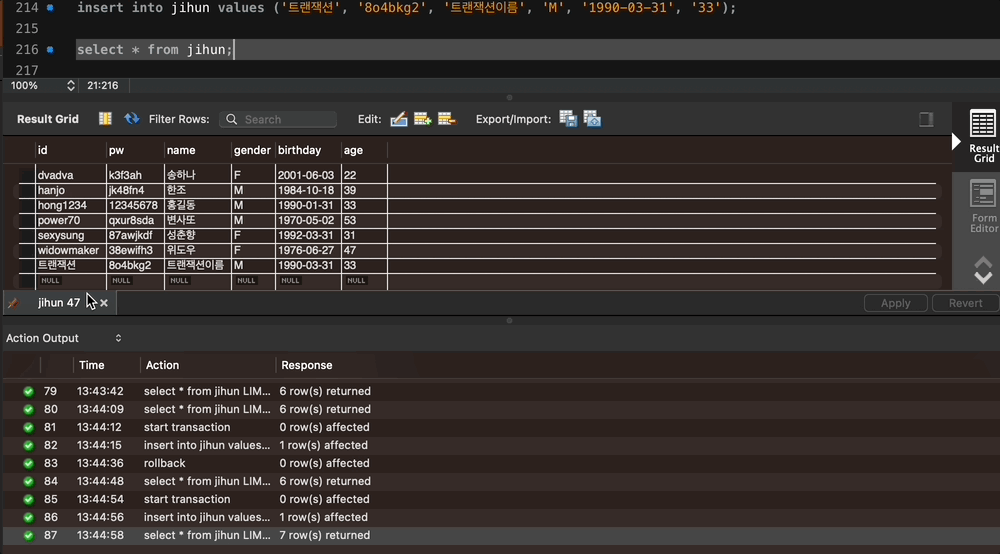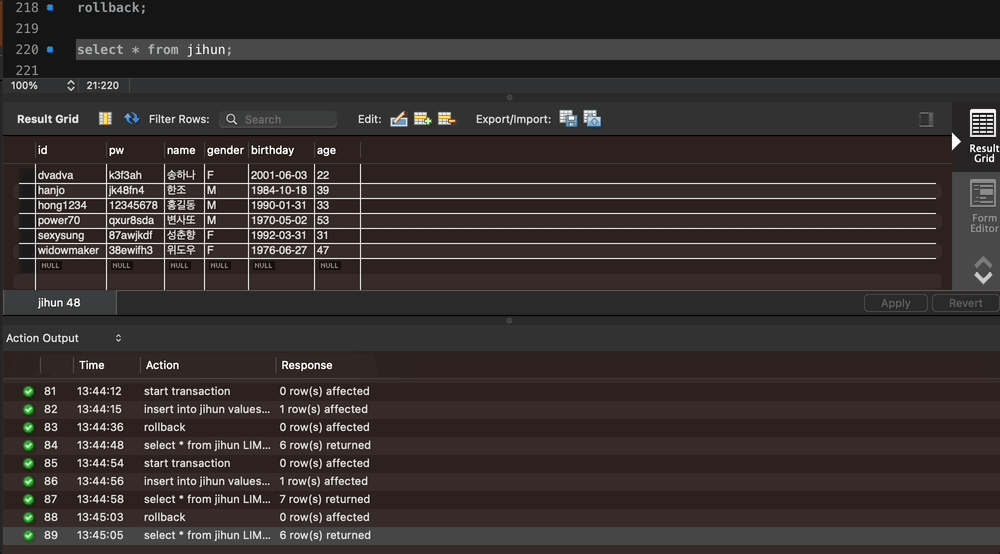
📔 레퍼런스
TCP SCHOOL - UPDATE
dev-coco - mysql 권한
ssungkang.tistory - mysql 권한
📓 결론
- sql 의 데이터 형식, DDL, DML, DCL, TCL 에 대해 조사해봤다.
join, 중첩 질의문을 사용하지 않았기에 매우 간단한 단계의 데이터베이스만 접해볼 수 있었다. 그런데 개인적으로는 이 내용들을 정리하는데 중요한 의미가 있었다고 생각한다. 어려운 내용이 아니더라도 실제로 아무것도 안보고 create, insert sql 문을 작성하라고 할때 당황스러워 할 수도 있다면 이 기본적인 정보들을 한번 정리할 필요가 있다고 생각한다.
