
표준 스트림과 stdin, stdout, stderr
표준 스트림(Standard Stream)
- 스트림(Stream) 이란?
- 프로그램이 드나드는 데이터를 흐름으로 표현한 단어
- 종류
- 입력 스트림(Strandard input, STDIN, 0)
- 출력스트림(Standard output, STDOUT, 1)
- 오류 메시지 출력 스트림(Standard Error, STDERR, 2)
- 실제 리눅스의
/dev디렉토리에서 위 세 개의 표준 스트림을 앞서 언급한 파일 형태로 담고 있다.
- stdin
- 표준 입력은 프로그램으로 들어가는 입력값의 데이터(보통은 문자열) 스트림이며, Standard Input 을 줄여서
stdin으로 표현한다. - 리눅스 쉘에서 표준 설정은 키보드이다.
- 모든 프로그램에서 입력을 요구하지 않으며, 대표적인 예로 비밀번호를 입력할 때 표준 입력 스트림을 사용한다.
- 표준 입력은 프로그램으로 들어가는 입력값의 데이터(보통은 문자열) 스트림이며, Standard Input 을 줄여서
- stdout
- 표준 출력은 프로그램이 출력 데이터를 기록하는 스트림으로, Standard Output 을
stdout으로 줄여 표현한다. - 표준 출력은 텍스트 터미널에서 이루어지며, 표준 입력과 마찬가지로 모든 프로그램이 출력을 요구하는 것은 아니다.
- 표준 출력은 프로그램이 출력 데이터를 기록하는 스트림으로, Standard Output 을
- stderr
- 표준 오류는 프로그램이 오류 메시지나 진단을 출력하기 위해 일반적으로 쓰이는 또다른 출력 스트림이다.
- Standard Error 를 줄여
stderr로 줄여 표현한다.
파일 디스크립터 (file descriptor)
리눅스의 모든 파일을 관리하는 방식
명령어 실행 (컴퓨터에게 작업을 요청 -> 프로세스 생성)
- 실제 프로그램을 실행시키는 작업
- 이러한 프로그램은 파일로 존재
- 파일을 실행 시키기 위해서는 먼저 파일을 열어야 한다.
- 파일이 열리면 커널이 해당 프로세스가 동작하는데 필요한 장치나 파일을 번호를 붙여 관리하며, 이러한 번호를 파일 디스크립터 테이블에 저장
- 자주 사용하는 장치들은 미리 번호가 예약되어 있다.
파이프라인과 리다이렉션
리다이렉션(Redirection)
리눅스에서는 세 개의 표준 스트림을 자동으로 열게됩니다. 표준 스트림을 이용한 파이프라인과 리다이렉션이 가능합니다. 파이프라인은 한 명령의 출력을 다른 명령의 입력으로 사용하는 것이고, 리다이렉션은 명령의 입력이나 출력을 파일로 대체하는 것입니다.
리눅스에서는 표준 입력, 표준 출력, 표준 오류를 파일로 리다이렉션 할 수 있습니다. 리다이렉션을 쓰고 싶다면 기호인 >, < 를 사용합니다. 다음은 몇 가지 예시입니다.
- > : 출력 리다이렉션
command > file:command의 출력을file로 저장합니다.file이 존재하지 않으면 생성합니다. 이미 존재하는 파일이면 덮어씁니다.command1 > file1 2>&1:command1의 표준 출력과 표준 오류 출력을 모두file1로 리다이렉션합니다.2>&1은 표준 오류 출력을 표준 출력으로 리다이렉션 하는 것을 의미합니다.
- >> : 출력 리다이렉션(추가 모드)
command >> file:command의 출력을file에 추가합니다.file이 존재하지 않으면 생성합니다.
- < : 입력 리다이렉션
command < file:command의 입력을file로부터 읽어옵니다.
- << : 여러 줄의 입력을 받습니다.
command << EOF:EOF라는 문자열을 입력할 때까지 입력된 모든 내용을command의 입력으로 넘깁니다.
예시:
-
ls > file.txt:ls명령의 결과를file.txt파일에 저장합니다. -
ps aux > ps.txt:ps aux명령의 결과를ps.txt파일에 저장합니다.-
정확하게 말하자면,
ps aux의 출력 스트림을 ps.txt 이라는 파일로 전환하여 저장하는 것을 의미한다. 따라서ps aux명령의 결과는 콘솔의 화면이 아닌ps.txt파일에 기록된다.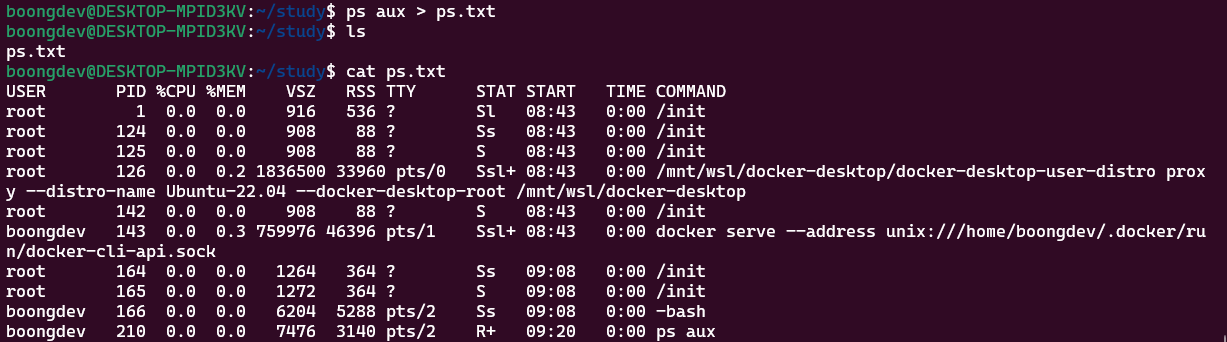
ps aux 명령이 실행되지 않고 ps.txt 파일에 저장되는 모습
-
-
cat < file.txt:file.txt파일의 내용을 출력합니다. -
sort < file.txt > sorted_file.txt:file.txt파일의 내용을 알파벳순으로 정렬한 후sorted_file.txt파일에 저장합니다. -
head < ps.txt:head명령은 파일의 처음 부분을 설명한 라인(line) 만큼 출력하는 명령이다. 기본값으로 10줄이 세팅 되어 있다.ps.txt파일의 처음 10줄을head입력 스트림으로 전환하여 보내게 된다.- 응용 :
head < ps.txt > sample.txtps.txt의 내용을head명령의 입력 스트림으로 전환하여 전송한다.head명령은 입력 받은ps.txt의 내용에서 10줄을 출력한다.head명령의 출력 스트림을sample.txt파일에 연결한다.head명령의 출력 스트림은 결과를sample.txt파일에 저장한다.
- 응용 :
파이프(Pipe)
파이프(Pipe)는 한 명령어의 출력을 다른 명령어의 입력으로 사용할 수 있게 해주는 기능입니다. 파이프라인(Pipeline)은 파이프를 사용해 여러 명령어를 연결하여 실행하는 것입니다.
파이프는 | 기호를 사용합니다. 다음은 파이프의 예시입니다.
command1 | command2:command1의 출력 스트림을command2의 입력 스트림으로 전달합니다.
예시:
-
ls | grep file: 디렉토리의 파일 목록을 출력하고, 그 중 "file" 이라는 문자열이 포함된 파일만 검색합니다.-
[/bin 디렉토리 안] ls -l | grep ssh: 결과grep명령어는 추후에 정리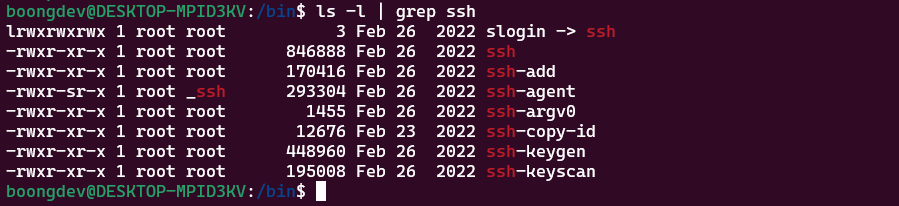
ssh 문자열이 들어있는 모든 파일들을 검색
-
-
ps aux | grep firefox: 프로세스 목록을 출력하고, 그 중 "firefox" 라는 문자열이 포함된 프로세스만 검색합니다. -
cat file.txt | grep keyword | wc -l:file.txt파일의 내용 중 "keyword" 라는 문자열이 포함된 라인의 개수를 출력합니다.위의 예시에서
grep과wc는 앞선 명령어의 출력을 입력으로 받아 처리합니다. 이렇게 명령어를 파이프라인으로 연결함으로써, 여러 개의 명령어를 조합해 원하는 결과를 얻을 수 있습니다.
파이프라인 실행 과정
터미널은 하나의 프로세스이고, 명령어 실행은 해당 터미널의 정보를 기준으로 백그라운드에 자식 프로세스가 fork 되어 명령어를 실행하게 된다.
즉 ls 명령어를 입력하면, 자식 프로세스 1개가 fork 되어 백그라운드에서 부모 프로세스의 정보를 기준으로 해당 명령어 즉, stdin(표준 입력 스트림) 을 통해 정보를 입력받고 stdout(표준 출력 스트림) 을 통해 ls 명령어를 호출한 터미널로 정보를 반환한다.
그럼 파이프(Pipe) 끼리 어떻게 연결되나?
$ ls | sort | less동작과정
ls를 실행하는 자식 프로세스 및 파이프 명령어 개수 만큼 프로세스를 fork 한다. 프로세스는wait상태로 대기한다.- 부모 프로세스로부터
stdin을 통해 정보를 받는다. ls프로세스는ls명령을 실행한다.ls프로세스는stdout을 통해 다음 자식 프로세스stdin으로 데이터를 출력한다.- 반복하고 마지막 프로세스가 부모 프로세스로
stdout을 return 하고 부모 프로세스는 결과를 출력한다.
부모 프로세스 → … → stdin → 프로세스 내부 명령 실행 → stdout → stdin → … → 부모 프로세스
출력 관련 명령어
파일 일기
man : 메뉴얼 출력 명령어
man <명령어>- 명령어에 대한 메뉴얼을 출력하는 명령어

cat : 파일 내용 출력
cat <옵션> <파일 이름>- 파일 내용을 출력하는 명령어
- 다른 CLI 도구나 파일로 리디렉션 하는 데 기본적으로 사용하는 명령이므로 잘 기억할 것
- 자주 쓰는 옵션
-n: Line 번호와 함께 출력
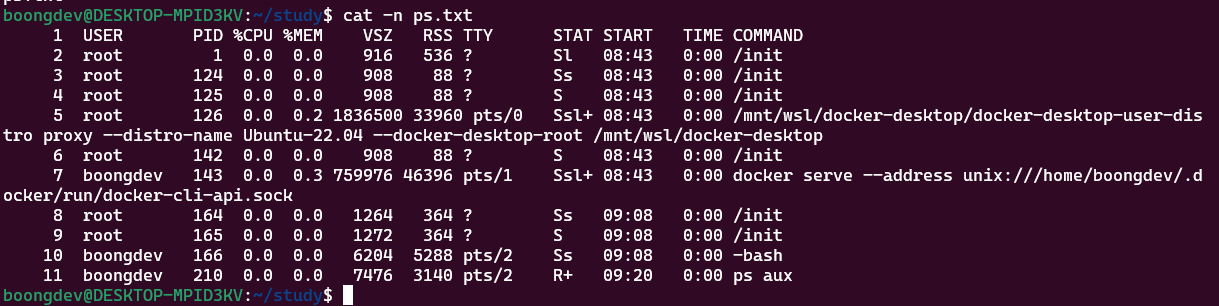
-n 옵션으로 파일 내용 앞 line 번호가 쓰여진 것을 확인할 수 있다
more : 파일을 화면 단위로 끊어서 출력
more <옵션> <파일 이름>- 자주 쓰는 옵션
+<number>: 예) +3 : 입력한 line 을 포함한 페이지를 추력(3번째 줄부터 출력)+/<string>: 예) +/Gatsby : 입력한 문자열이 포함된 페이지를 추력 (Gatsby 문자열을 포함한 줄부터 출력)
less : 파일 내용 출력
less <옵션> <파일 이름>- 자주쓰는 옵션
-N: line 번호와 함께 출력
head : 파일 앞부분 출력
head <옵션> <파일 이름>- 자주 쓰는 옵션
-n <number>: 지정한 라인까지 출력
tail : 파일 뒷부분 출력
tail <옵션> <파일 이름>- 자주 쓰는 옵션
-n <number>: 지정한 라인까지 출력-f: 즉시 종료되지 않고, 파일의 내용이 추가되는 상태를 지켜보면서 계속 이어서 출력-f옵션은 시스템 관리자라면 필수적으로 알아야 하는 옵션- 애플리케이션 로그가 쌓이는 것을 실시간으로 확인하고자 할 때 많이 사용한다.
이 외의 기타 명령어
-
wc: 파일의 줄, 단어 및 문자 수를 계산하는 데 사용- 옵션
-l: 줄 수만 계산-w: 단어 수만 계산-c: 문자 수만 계산
- 옵션
-
awk: awk는 텍스트 파일을 처리하는 프로그램으로, 파일이나 텍스트 데이터를 레코드와 필드로 구분하여 처리할 수 있습니다. 레코드는 텍스트 파일에서 행을 의미하며, 필드는 레코드 안에서 구분자로 구분된 데이터를 의미합니다. awk는 이러한 레코드와 필드를 기반으로 다양한 데이터 처리 작업을 수행할 수 있습니다. 대표적으로 데이터 추출, 통계, 변환 등의 작업이 있습니다. awk는 유닉스, 리눅스 등에서 기본적으로 제공되는 명령어 중 하나입니다.-
기본 구조 :
awk 'condition {action}' <파일 이름>awk는 텍스트 파일을 처리하는 프로그램으로, 파일이나 텍스트 데이터를 레코드와 필드로 구분하여 처리하는 기능을 제공합니다. awk는 이러한 레코드와 필드를 기반으로 데이터를 추출하거나 통계, 변환 등의 작업을 수행할 수 있습니다.자주 사용되는 기본적인
awk명령어는 다음과 같습니다. -
awk '{ print $1 }' file.txt:file.txt파일에서 첫 번째 필드를 출력합니다. -
awk '{ print $NF }' file.txt:file.txt파일에서 마지막 필드를 출력합니다. -
awk '{ print NF }' file.txt:file.txt파일에서 필드의 수를 출력합니다. -
awk '/pattern/ { print }' file.txt:file.txt파일에서 "pattern"이 포함된 라인을 출력합니다. -
awk '{ s += $1 } END { print s }' file.txt:file.txt파일에서 첫 번째 필드의 합을 출력합니다.여러 가지 기능을 조합하여 사용할 수도 있습니다. 예를 들어, 다음과 같은 명령어는
file.txt파일에서 첫 번째 필드가 3인 라인을 출력합니다. -
awk '$1 == 3 { print }' file.txt
-
-
cut: 파일에서 특정 열을 추출, 기본 구분 기호는탭 문자이다.- 옵션
-f:-d: 구분 기호 설정 옵션 (ex)cut -d ‘,’: 쉼표로 구분 기호를 설정—output-delimiter: 출력 구분 기호 설정 (기본 설정은 입력 구분 기호와 같다)
- 옵션
-
join: 파일의 공통 -
paste: 여러 텍스트 파일을 수평적으로join,merge하는 유닉스 커맨드 라인 유틸리티
-
예제 파일

-
옵션
-
-s: 수평이 아닌 수직으로 값을 읽어서 수평으로 출력한다.
-
-d: 구분자를 지정할 수 있다.
-
-
-
sed: 문자열 대체 (찾기 및 바꾸기)sed 's/<찾을문자열>/<바꿀문자열>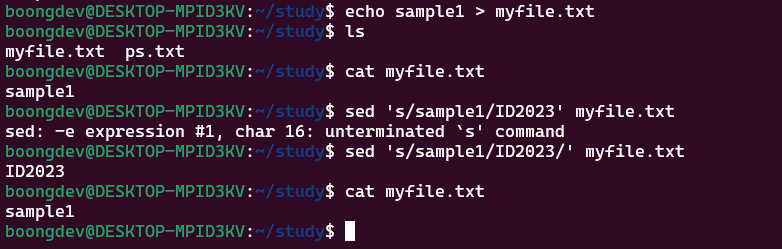
- 보시다시피 화면에 결과를 출력만 하고 파일은 바뀌지 않는다 리디렉션을 해주거나
-i옵션을 주어 원본 파일을 변경해야 한다. - 옵션
-d: 삭제-a-i: 줄 추가 또는 삽입
-
sort: 파일 내에서 줄이나 열을 정렬하는데 사용한다. 기본적으로 줄 시작 부분의 문자를 기준으로 다음 순서를 정렬한다.- 오름차순 숫자, 오름차순 문자(소문자 먼저, 그 다음 대문자)
- 옵션
-r: 정렬 기준 역순으로 바꾼다-n: 기본 정렬은 숫자 값이 아닌 문자로 숫자를 정렬한다. 숫자 값으로 정렬하려면-n옵션 사용-k: 줄의 시작이 아닌 특정 열을 기준으로 파일을 정렬할 때 사용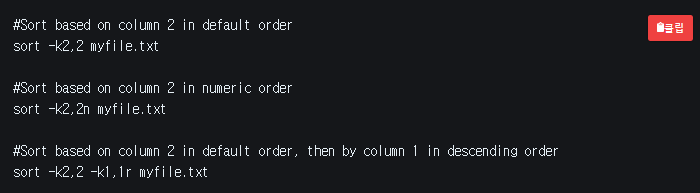
-u: 정렬한 다음 중복을 제거한다-f: 대소문자 구분 안함
-
uniq: 중복된 항목을 제거하는 커맨드 라인 유틸리티, 보통sort명령어로 정렬을 한 결과를 파이프로uniq에 전달하여 중복 내용을 제거한다- 예제 파일
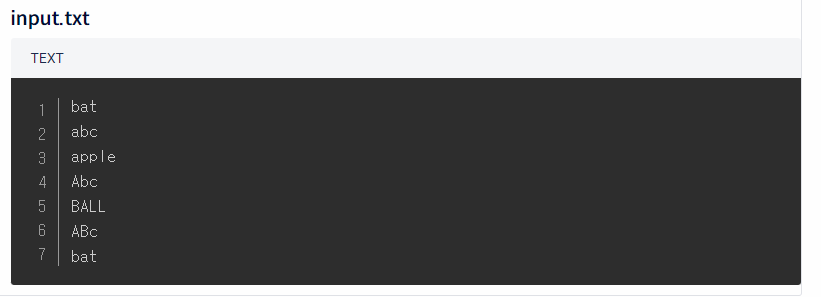
- 사용법
sort input.txt | uniq
- 예제 파일
- 옵션
- `-u` : 중복되지 않은 라인만 표시한다. 위 예제에서 line 과 bat 은 포함되지 않는다.
- `-d` : 중복되는 라인만 표시한다. 위 예제에서 line 과 bat 이 해당된다.
- `-c` : 중복 횟수를 세어 준다.
- `-i` `--ignore-case` : 대소문자 구분 무시 옵션파일 및 디렉토리 찾기 관련
find : 파일 검색
파일 검색 기본 명령어 중 하나. 파일 권한, 소유권, 수정 날짜, 크기 등과 같은 특정 기준에 따라 파일을 검색 할 수 있다.
주의점: 위치 선정을 하지 않을 경우 기본적으로 현재 디텍토리만 검색하기 때문에 원하는 결과를 얻지 못 할 수 있다. 찾고자 하는 위치를 지정해서 사용하는 것이 좋다.
$ find <위치> <옵션> 검색할 내용- 옵션
-name 내용: 지정한 내용의 이름을 가진 파일을 찾음-type <옵션>: 옵션에 따른 형태를 가진 파일을 찾음
$ find . -name '이름' # 찾을 파일 이름을 지정해서 찾기 . 는 현재 디렉토리를 뜻함
$ find . -name '이름' -type d # -type d 는 디렉토리만 찾기
$ sudo find / -size+10M # 10M 이상 찾기 디렉토리 권한 때문에 sudo 사용
# / 는 루트 디렉토리를 뜻함
$ find . -empty # 빈 파일 찾기
$ find . -newer practice.txt # practice 파일 보다 최근에 변경된 파일 찾기locate : 특정 파일 위치 찾기
특정 파일의 위치를 모를 때 활용 find 명령어에 비해 빠르지만 데이터베이스를 이용하기 때문에 정기적인 업데이트를 필요로 한다. updatedb 에 의해서 생성된 미리 빌드된 파일들의 데이터베이스를 통해 검색이 되기 때문. 속도 향상을 위해 만들어진 유틸리티 이므로 전체적인 효율성과 정확성은 조금 떨어진다.
- **locate(mlocate) 프로그램 설치하기** 리눅스 배포판에 따라
locate명령어가 기본으로 제공되는 경우도 있지만 없는 경우 설치가 필요. 기존에는 locate 패키지를 사용 최근에는 mlocate 패키지를 추천한다 (관리자 권한 필요)$ sudo apt-get install mlocate locate명령어가 빠른 이유는 검색 DB 를 미리 생성하기 때문 (파일 목록 데이터베이스,mlocate.db파일) 따라서locate명령어를 처음 사용하는 경우 DB 파일을 먼저 생성해야한다.- ****DB 파일 갱신하기(관리자 권한 필요)****
$ sudo updatedb - 사용예
$ locate gatsby.txt # 파일 이름으로 검색 $ locate -n 10 *.txt # 검색할 파일 수 지정하여 찾기 모든 txt 파일 중 10개
which : 실행파일 위치 식별
which 명령어는 실행 가능한 파일의 경로를 찾아주는 프로그램입니다.
검색하려는 모든 파일이 실행 파일인 경우 which 명령어가 유용. $PATH 시스템 환경변수에서 이진 파일을 매우 효과적으로 검색
$ which ls
usr/bin/ls
$ which python3
/usr/bin/python3패턴으로 찾기 관련
grep 명령어를 사용하여 파일 내에서 특정 패턴을 검색할 수 있습니다.
$ grep <패턴> <파일명>
사용 예
$ grep 'hello' file.txt
$ grep -i 'hello' file.txt
$ grep -n 'hello' file.txt
$ grep -r 'hello' ./directory
- 옵션
옵션 설명 -i 대소문자를 구분하지 않고 검색 -v 지정한 패턴을 포함하지 않는 라인을 출력 -n 라인 번호를 함께 출력 -w 지정한 패턴이 단어로 구분되어 있는 경우에만 검색 -r 하위 디렉토리를 포함하여 모든 파일에서 검색 -l 파일명만 출력 -c 일치하는 라인 수를 출력 -H 파일명을 출력 -E 확장 정규식 사용 -F 정규식이 아닌 문자열 검색 -m 최대 검색 결과 갯수 제한 - 예시 (끝에는 전부 파일명)
- 단어 단위로 검색 :
grep -w - 검색된 문자열이 포함된 라인 번호 출력 :
grep -n - 하위 디렉토리를 포함한 모든 파일에서 문자열 검색 :
grep -r - 최대 검색 결과 갯수 제한 :
grep -m 10 - 문자열 A로 시작해서 문자열 B로 끝나는 패턴 찾기 :
grep '^A$B'
- 단어 단위로 검색 :
정규표현식
정규표현식(regular expression)은 문자열을 처리하는 방법 중의 하나로 특정한 조건의 문자를 '검색'하거나 '치환'하는 과정을 매우 간편하게 처리할 수 있도록 하는 수단이다. 정규표현식은 일종의 패턴(pattern)이며, 이 패턴을 통해 문자열을 처리한다.
정규표현식 문법
.: 임의의 한 문자^: 문장의 시작$: 문장의 끝[]: 문자의 집합 중 하나[-]: 문자의 집합 중 범위(): 그룹화|: or 연산자?: 0 또는 1회 발생- `` : 0회 이상 발생
+: 1회 이상 발생{n}: n회 발생{n,}: n회 이상 발생{n,m}: n회 이상, m회 이하 발생
정규표현식 예제
.모든 문자 하나를 의미합니다.
^문자열 또는 행의 시작을 의미합니다.
$문자열 또는 행의 끝을 의미합니다.
[]대괄호 안에 있는 문자 중 하나와 일치합니다.
[^]대괄호 안에 있는 문자를 제외한 문자 중 하나와 일치합니다.
[-]대괄호 안에 있는 문자의 범위와 일치합니다.
()괄호 안의 문자열을 그룹으로 묶습니다.
|둘 중 하나와 일치합니다.
?0회 또는 1회를 의미합니다.
- `` 0회 이상을 의미합니다.
+1회 이상을 의미합니다.
{n}n회를 의미합니다.
{n,}n회 이상을 의미합니다.
{n,m}n회 이상, m회 이하를 의미합니다.
정규표현식을 사용하는 명령어
grep: 파일 내에서 특정 패턴을 검색할 때 사용합니다.sed: 파일 내에서 문자열을 대체(찾기 및 바꾸기)할 때 사용합니다.awk: 파일 내에서 특정 패턴을 검색하고 조작할 때 사용합니다.find: 파일 검색 기본 명령어 중 하나입니다.locate: 특정 파일의 위치를 찾을 때 사용합니다.which: 실행 파일의 위치를 식별할 때 사용합니다.
출처
https://recipes4dev.tistory.com/171
https://www.lesstif.com/lpt/linux-uniq-95879394.html
https://blog.ronin.cloud/10-simple-linux-commands/
http://hyeonjae-blog.logdown.com/posts/654302
https://www.computerhope.com/unix/uuniq.htm
https://hitomis.tistory.com/84
