
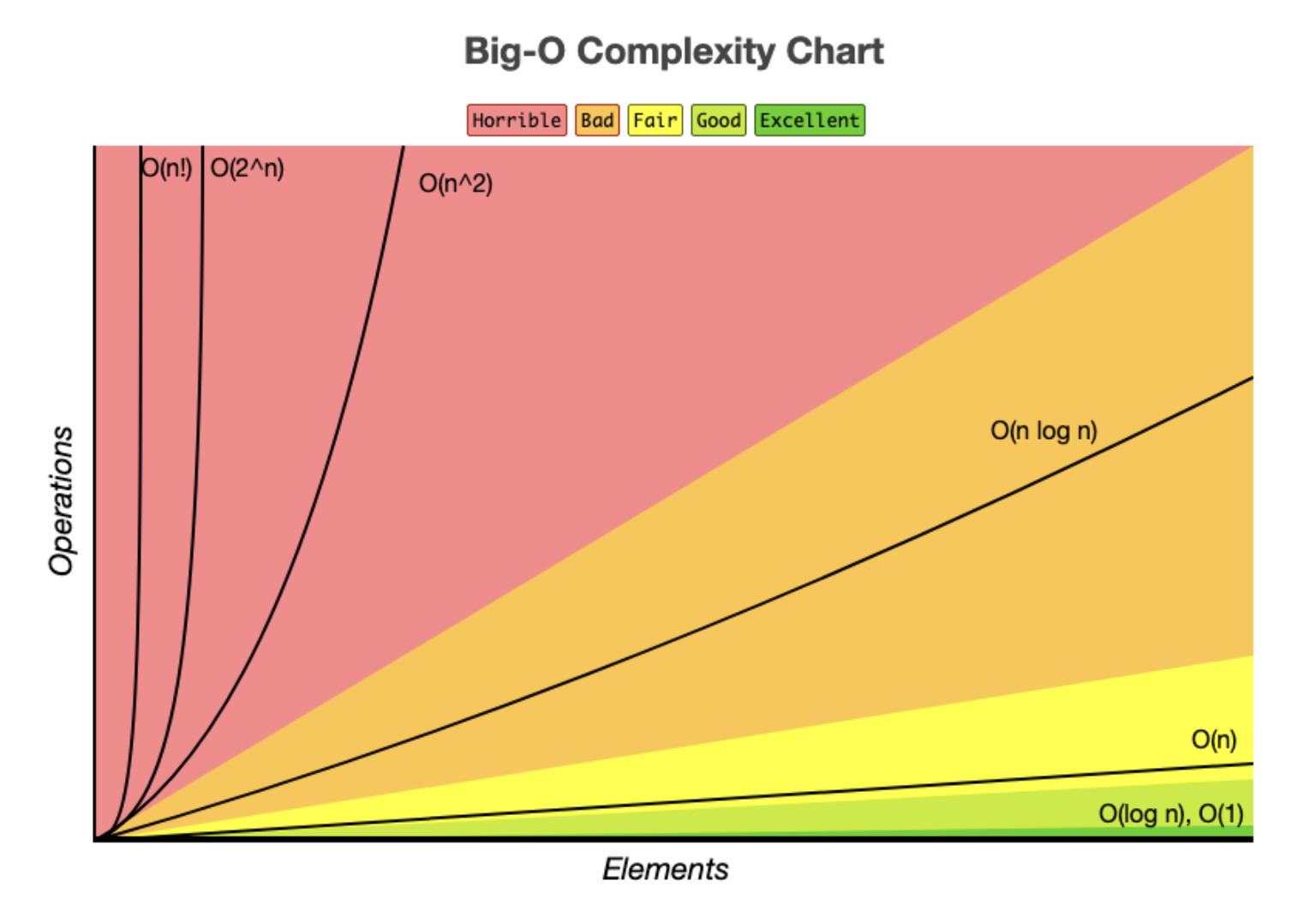
💡 Big O 표기법
함수의 증감 추세를 비교하는 점근 표기법에서 상한선(최악의 상황)을 표현하는 표기법이다. computer science에서는 알고리즘의 성능을 비교할때 사용합니다.
💡 Time Complexity: 시간복잡도
입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.
Constant Time(상수 시간) - O(1)
func constantTime(_ n: Int) -> Int {
let result = n * n
return result
}loop가 없고 단순한 계산결과를 return 하는 알고리즘 입니다.
Linear Time(선형 시간) - O(n)
func linearTime(_ A: [Int]) -> Int {
for i in 0..<A.count {
if A[i] == 0 {
return 0
}
}
return 1
}알고리즘의 성능이 매개변수를 통해 전달된 값의 크기에 의존합니다.
linear time은 수행 시간의 길이가 입력값의 크기에 정비례합니다.
Logarithmic time(로그 시간) - O(log n)
func logarithmicTime(_ N: Int) -> Int {
var n = N
var result = 0
while n > 1 {
n /= 2
result += 1
}
return result
}BST(Binary Search Trees)같은 빠른 알고리즘들 입니다. 그들은 결과를 찾을때 마다 결과를 반으로 나눕니다. 이 반으로 나누는것이 O(log n) 로그 시간 알고리즘 입니다.
Quadratic Time(2차 시간) - O(n^2)
func quadratic(_ n: Int) -> Int {
var result = 0
for i in 0..<n {
for j in i..<n {
result += 1
print("\(i) \(j)")
}
}
return result
}2중 루프를 사용하는 알고리즘에서 주로 발생합니다. 정답을 얻을 수는 있지만 속도가 느립니다.
💡 Space Complexity(공간 복잡도)
알고리즘이 실행될 때 사용하는 메모리의 양을 나타낸다.
일반적으로 Big O는 시간 복잡도를 말합니다. 공간 복잡도는 변수가 얼마나 선언됐는지 그리고 변수들과 관련된 cost와 관련있습니다.
💡 Trading off space of time
두 배열의 공통 원소가 있는지 찾는 알고리즘을 다음과 같이 2가지로 표현할 수 있습니다.
공간복잡도 관점에서는 매우 효과적이지만 시간복잡는 O(n^2)으로 큰편입니다.
// Naive brute force O(n^2)
func commonItemsBrute(_ A: [Int], _ B: [Int]) -> Bool {
for i in 0..<A.count {
for j in 0..<B.count {
if A[i] == B[j] {
return true
}
}
}
return false
}
commonItemsBrute([1, 2, 3], [4, 5, 6])
commonItemsBrute([1, 2, 3], [3, 5, 6])space를 사용해서 Hash Map 방법을 사용하면 시간복잡도를 줄일 수 있습니다.
// Convert to hash and lookup via other index
func commonItemsHash(_ A: [Int], _ B: [Int]) -> Bool {
// Still looping...but not nested - O(2n) vs O(n^2)
var hashA = [Int: Bool]()
for a in A { // O(n)
hashA[a] = true
}
// Now lookup in the hash to see if elements of B exist
for b in B {
if hashA[b] == true {
return true
}
}
return false
}
commonItemsHash([1, 2, 3], [4, 5, 6])
commonItemsHash([1, 2, 3], [3, 5, 6])예시에서처럼 저장 공간이 부족한 경우에는 시간 복잡도를 늘려서 해결하고 저장 공간을 활용할 수 있는 경우에는 저장 공간을 사용해서 시간 복잡도를 줄일 수 있습니다.
