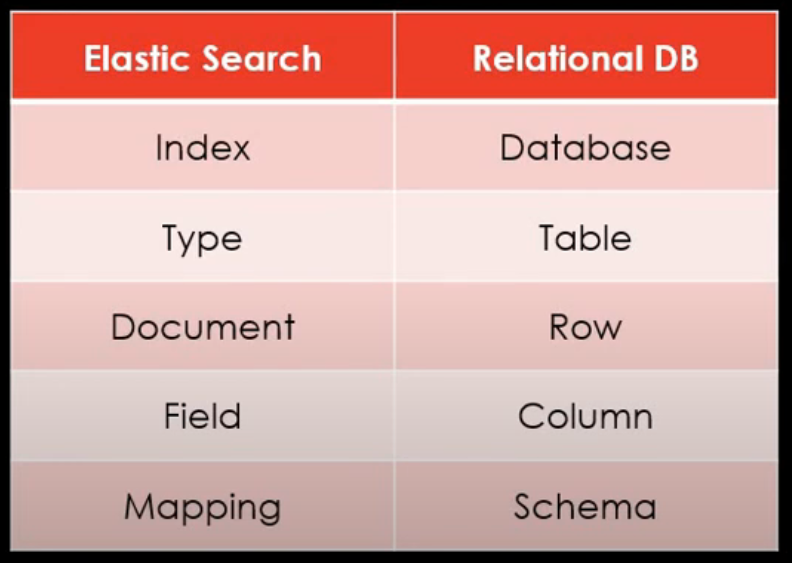
ElasticSearch 기본(1)
What is elasticsearch?
모든 데이터 색인을 통해 근 실시간으로 검색 및 분석이 가능한 검색 엔진

Elasticsearch를 사용하는 이유?
- 오픈 소스 검색 엔진
- 역 인덱스 구조
- 속도,확장성,복원력 등 광범위한 기능 제공
- 분산형 설계로 인한 데이터 보관의 안정성
색인이란?
책 속의 낱말이나 구절, 또 이에 관련한 지시자를
찾아보기 쉽도록 일정한 순서로 나열한 목록
-> 엘라스틱서치를 통해 정보를 검색하기 위한 색인 작업 필요
1. 전체 데이터 색인
DB에 저장된 모든 데이터를 저장
2. 부분 데이터 색인
실시간으로 수정된 데이터에 대하여 색인된 데이터를 수정
데이터 정합성의 문제로 인해 두 가지로 나눔
전체색인과 부분색인이 동시에 진행이 되면 데이터 정합성이 안맞는 문제가 발생하기 때문에 항상 개별적으로 실행되어야합니다.
전체 색인이 진행되기 전, 부분 색인이 진행 중인지 체크해야함
전체 색인 시 항상 새로운 인덱스를 생성하고 기존에 사용중이던 인덱스는 백업용으로 보관
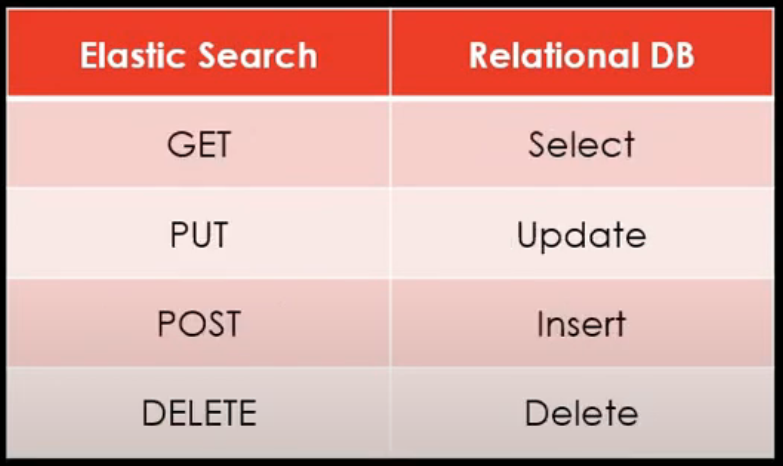

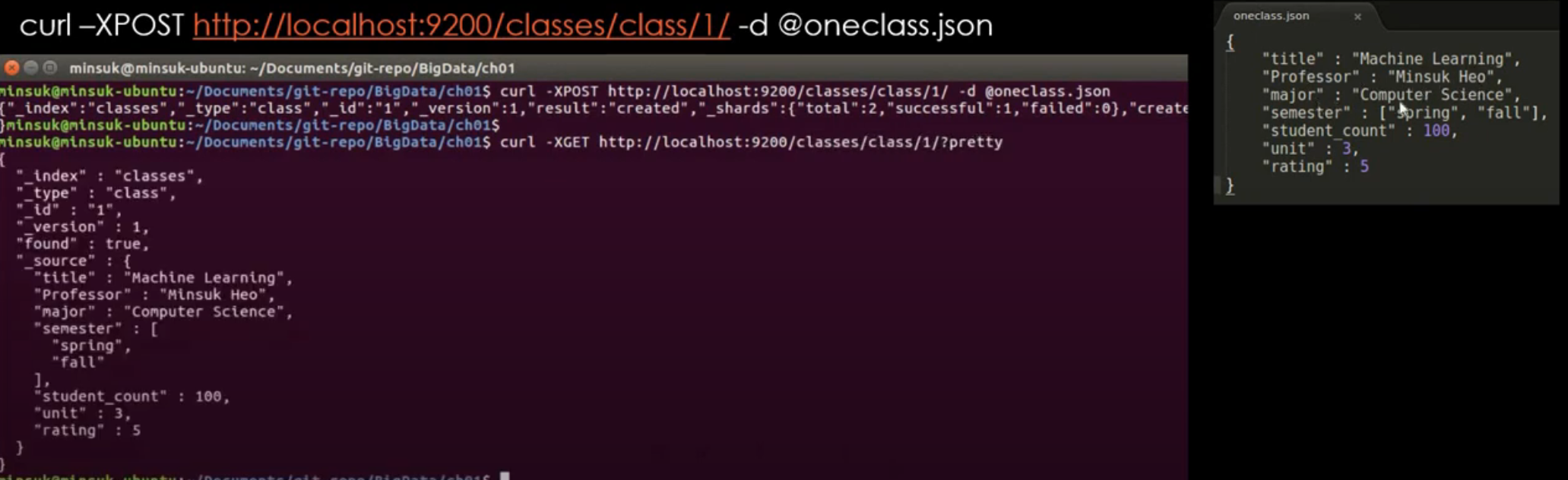
엘라스틱서치는 rest api 처럼 구현이 되어있다.
파일로 데이터 업로드하기
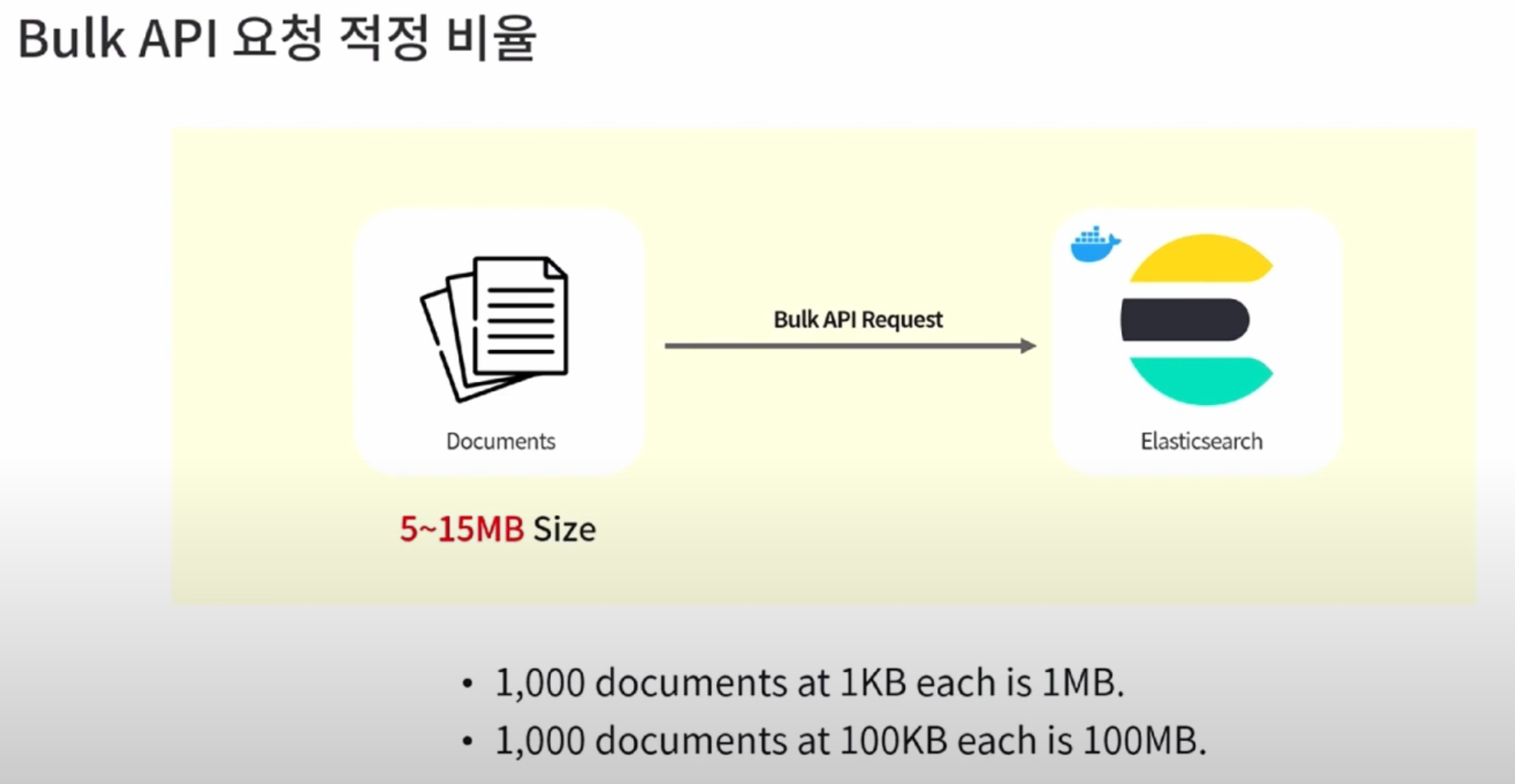
Bulk 대량의 데이터 업로드하기
curl -X POST http://localhost:9200/_bulk?pretty -data-binary @classes.json약 3,000,000개 이상의 상품 데이터를 색인하는데 얼마나 걸릴까?
5000개씩 업데이트 해준 결과 전부 완료되는데 50~1시간 소요
-> async로 2,000개의 데이터를 20개씩 병렬 처리로 indexing 요청
500,000개의 데이터를 약 1분만에 indexing 처리
전부 완료되는데 약 6분~7분 소요
부분 데이터 색인: 이미 색인된 데이터를 최신화 데이터로 재색인해주는 과정
검색 품질
만족할 수 있는 검색 품질?
- 얼마나 검색이 일치하는가
- 얼마나 적절하게 형태소 분석이 되는가
- 사용자 요청에 얼마나 유의미한 용어를 추출해 내는가
형태소 분석 및 사용자/동의어 사전 도입
ElasticSearch Analyzer
- 색인 시 입력된 데이터를 텀(term)으로 추출하기 위한 과정
- 하나의 텍스트를 최소한의 의미를 가진 여러개의 텍스트로 분석하는 것을 의미
ex) 남성 운동화 -> 남성, 운동화, sneakers...
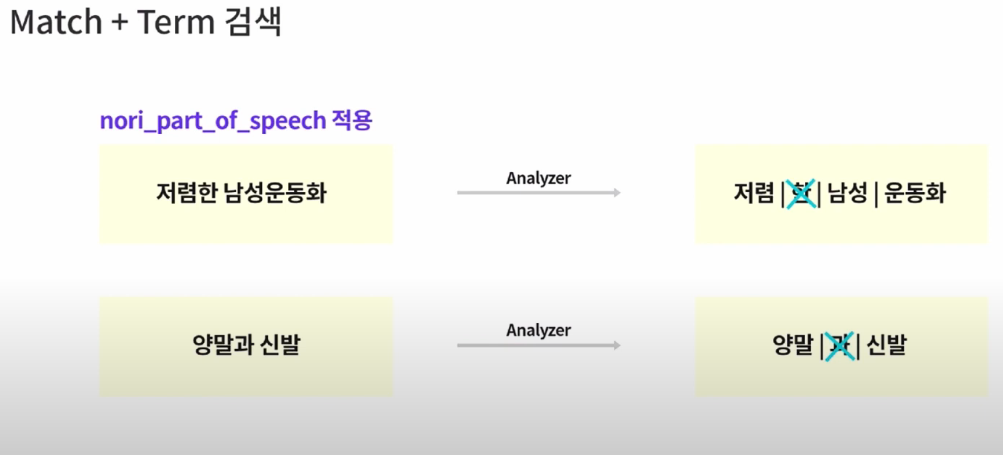
형태소 분석이 중요한 이유
ex) 남성 운동화 -> 남성운|동화 이렇게 나올 수도 있음
Nori tokenizer
남성 | 운동 | 화
1) 사용자 사전 도입 - user_dictionary.txt
사용자 사전에 운동화라는 단어를 넣음으로써 운동화라는 단어가 형태소 분석이 되지 않도록 할 수 있음
2) 동의어 사전 도입 - synonym.txt
사용사 사전과 동의어 사전을 서버에 등록하기 위해서 자동화 배포 필요
더욱 자연스러운 검색 결과 응답을 위한 검색 쿼리 개선
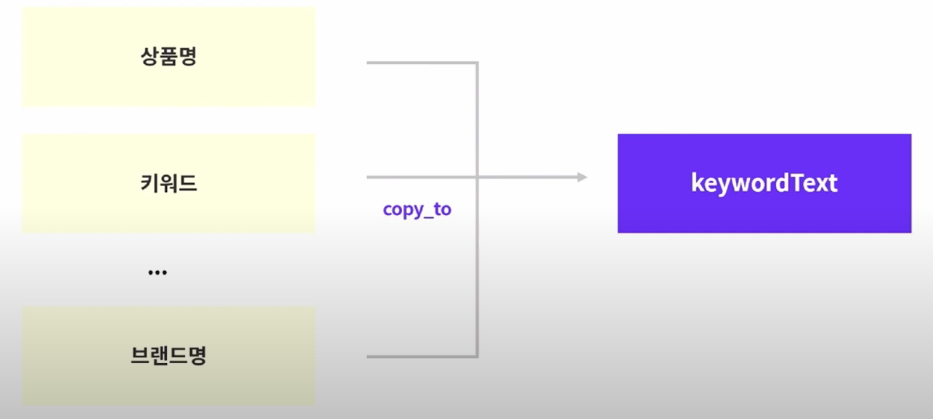
copy_to 기능

minimum_should_match
뜬금없는 검색결과를 방지하기 위해서 사용한 기능
검색어 : 김치 냉장고 -> 와인 셀러 냉장고 상하 온도 조절(미러형)
1) 매치 쿼리에 and 연산자 조건을 추가했다.
2) "minimum_should_match" : "100%"
검색 성능 향상 방안
- Shards Size가 작을수록
- Search Thread가 많을수록
- Search Query 응답이 빠를수록
- Node별 스펙이 좋을수록
- Data Node가 많을수록
엘라스틱 config 파일을 수정함으로써 스레드 카운터를 조정할 수 있음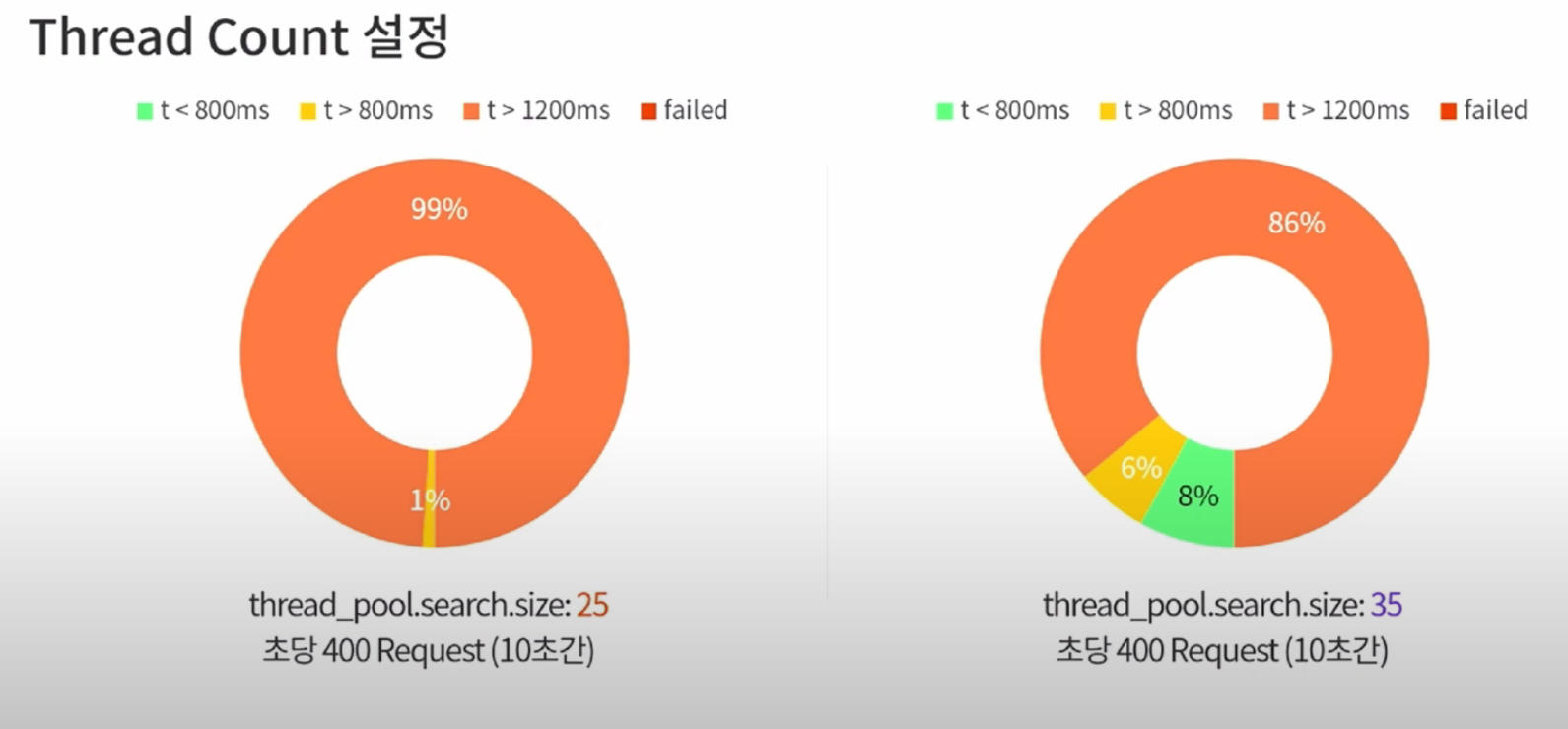
Query Tuning
