Preview

프로젝트 개요
- 팀 구성: 3명
- 담당 역할:
- 딥러닝 학습을 위한 영상 및 이미지 어노테이션
- YOLO 학습
- LSTM기반 손동작 인식 분류
- 수작업 시 발생할 수 있는 오류를 최소화 하고 지침을 명확히 할 필요성
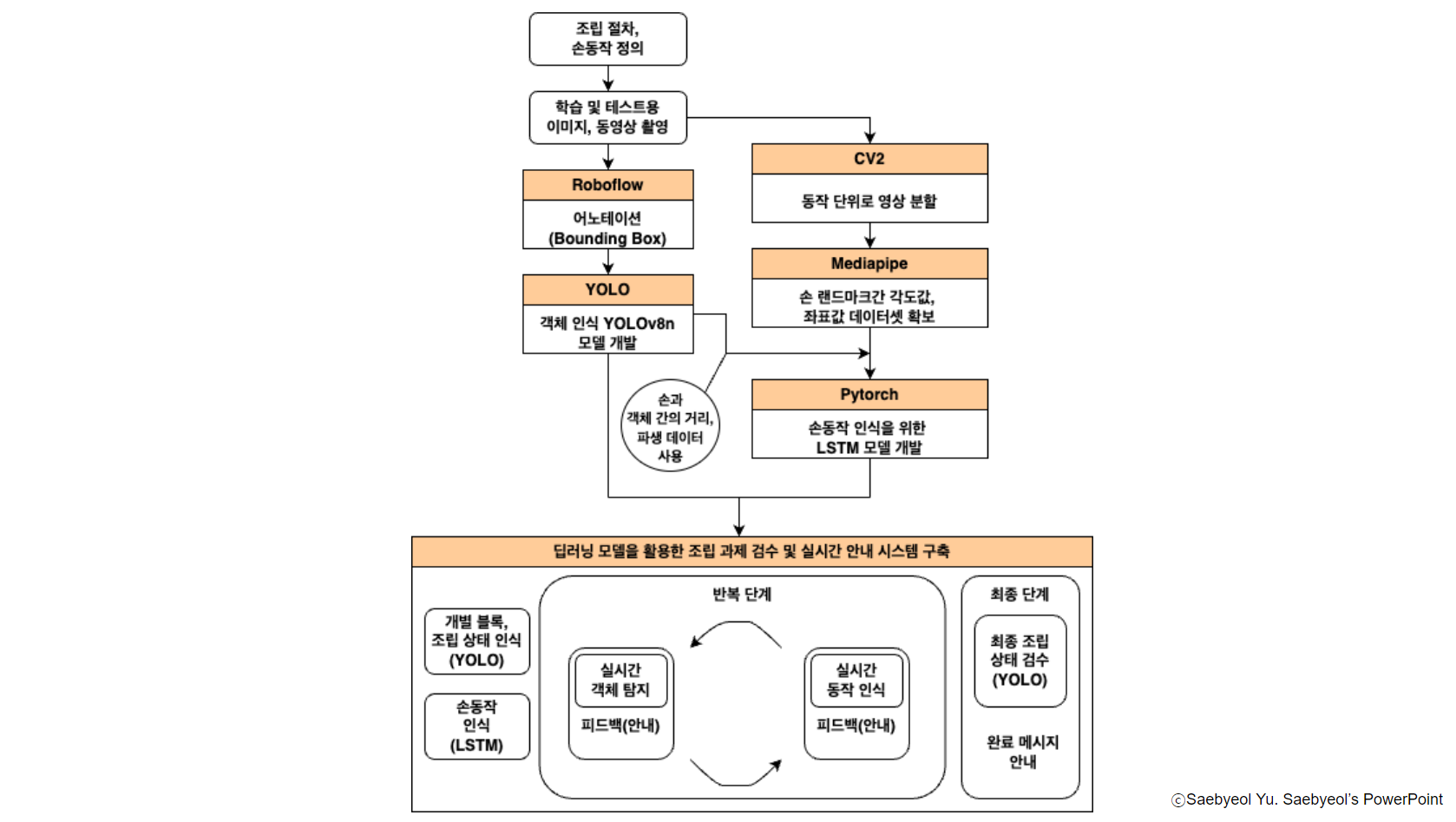
- 이미지 분류(YOLOv8n)와 동작인식 모델(LSTM)을 이용한 조립 과정 실시간 보조
- 주요 액션:
프로젝트 상세
1. 데이터
-
YOLO학습을 위한 이미지 데이터와 LSTM학습을 위한 영상데이터로 구성
-
YOLO 데이터
-
개별 블럭 데이터(16class)와 조립 단계별 데이터(5class)(1200EA)

[왼: 개별 블럭 데이터] [오: 조립 단계별 데이터]
-
조립 단계학습에 오답 데이터 추가
- 조립 과정에서 실수를 정확히 식별
- 조립의 정확도 향상
-
통합 데이터(16+5 = 21class)구축 및 성능 비교
-
-
LSTM 데이터
- Grab데이터와 Release데이터 라벨링(1200EA)

- YOLO박스를 활용한 손과 객체의 거리(x1, y1, x2, y2)
- mediapipe의 hand Landmark 21ea * 3(x,y,z 좌표) = 63
- 총 변수 개수: 63 + 4 = 67
- YOLO와 mediapipe를 동시에 사용하는 이유
- YOLO만 사용할 경우: 집지 않고 객체와 손이 가까이 있는 것만으로 "Grab"으로 인식
- mediapipe만 사용할 경우: 위치데이터가 있지 않아 객체와 손이 멀리 있어도 잡는 척만 하면 "Grab"으로 인식
- YOLO로 위치데이터, mediapipe로 손동작을 인식
- 서로의 단점 보완
- Grab데이터와 Release데이터 라벨링(1200EA)
2. Modeling
- YOLO학습
- YOLOv8n 선정
- 높은 정확도와 빠른 처리속도로 실시간 검수에 적합
- 개별 블록 데이터 모델(16class), 조립 단계 인식 모델(5class)
- 통합 모델(21class) 생성 후 성능 비교
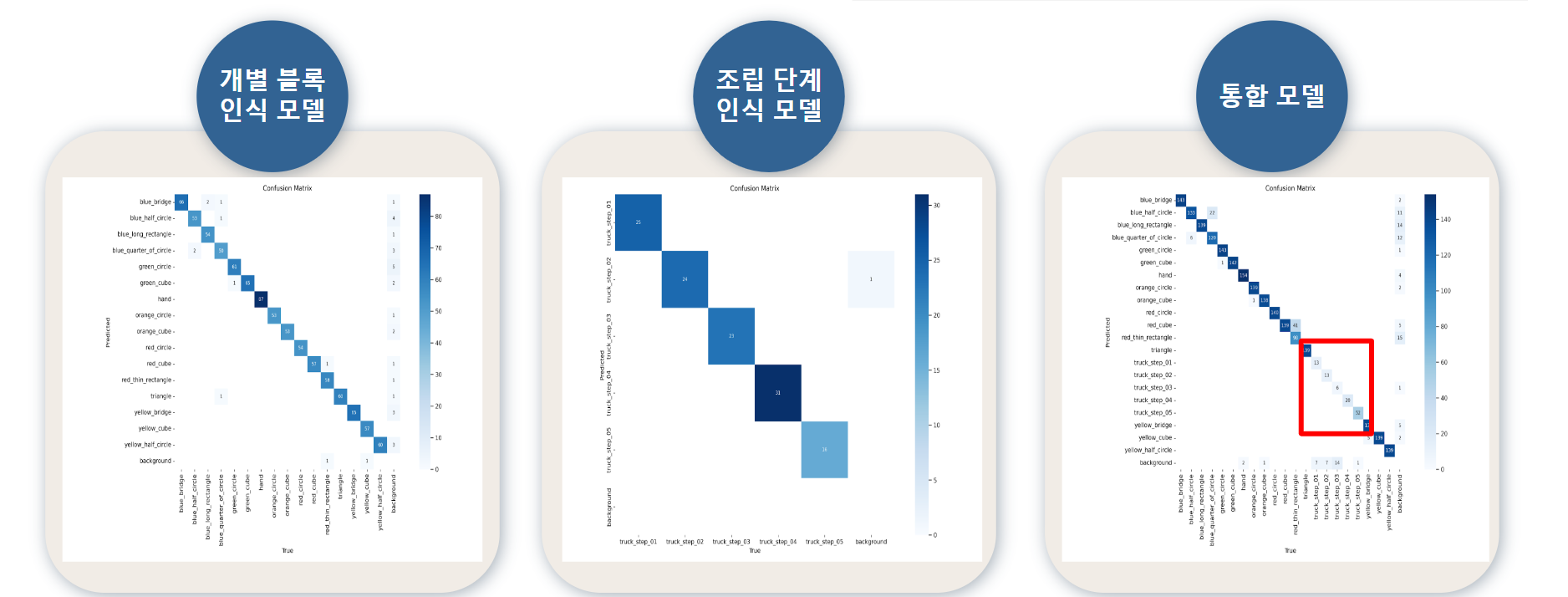
- 통합데이터 모델보다 분리된 모델의 정확도가 높음
- 분리된 모델은 각각의 작업에 특화
- YOLOv8n 선정
- LSTM학습
- 연속적인 데이터를 처리하는데 강한 모델
- 시간에 따라 변화하는 패턴을 인식하고 기억하는 능력이 뛰어남
- CNN보다 Frame-to-Frame Oscillations(프레임 간 진동)이 완화되어 보다 안정적이고 일관적으로 분류
- Frame-to-Frame Oscillations 예시
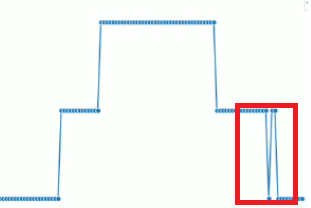
- Frame-to-Frame Oscillations 예시
- 모델 성능 확인
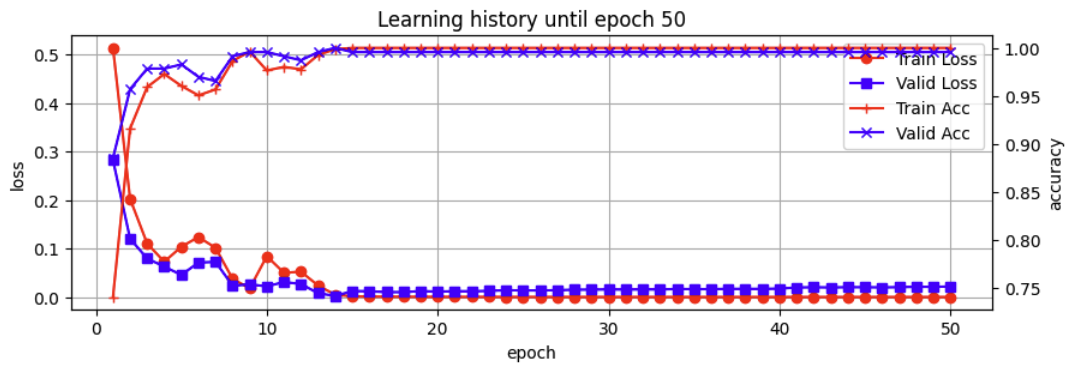
- 정확도와 Loss지표 모두 높은 수준을 유지
- 학습데이터 뿐 아니라 검증데이터에서도 성능이 높음
- 간단 예시 영상
3. 프로세스
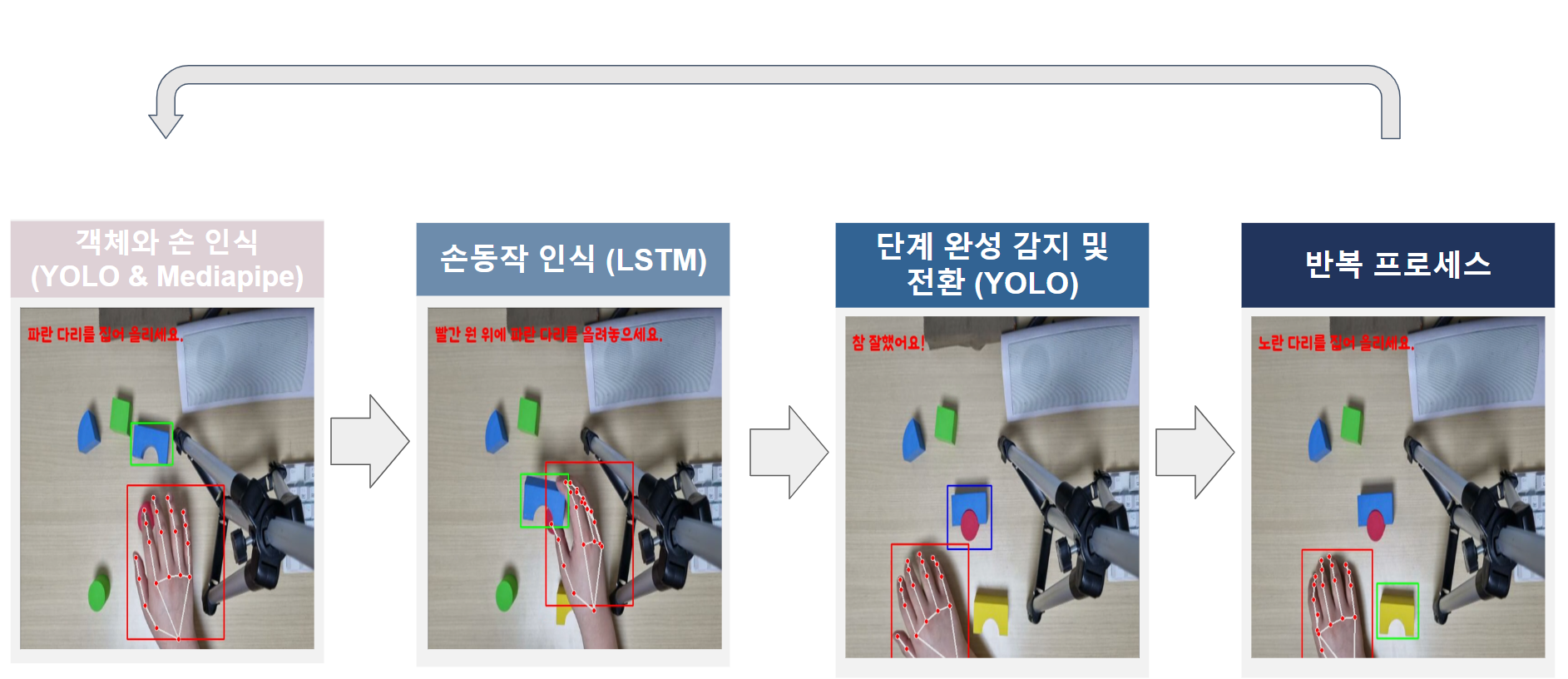
- 이번 단계에 필요한 블럭 식별하고 사용자에게 안내
- 사용자의 손동작 인식 후 조립 과정 설명
- 단계 완성 감지
- 다음 단계로 넘어가면서 완성까지 프로세스 반복
기대효과
- 제조업 적용
- 조립 과정을 정확하게 가이드
- 생산 시간 단축, 오류 감소 기대
- 비용 절감과 생산성 향상으로 이어짐
- 교육적 적용
- 실시간 가이드를 통해 학생 또는 신입 직원들이 기술적인 조립 과정을 쉽게 배우고 익힐 수 있음
- 어린이들에게 문제해결능력을 발달시키는 교육적 수단으로 활용
- 고령자가 쉽게 일상적인 조립 작업을 수행 할수 있도록 지원
- 치매예방 교육으로도 진행 가능
