3.1 다양한 데이터의 종류
우리는 기본 데이터 형식과 복합 데이터 형식을 기억해야합니다.
기본 데이터 형식에는 모두 15가지가 있는데, 이들은 크게 숫자 형식,논리 형식,문자열 형식,오브젝트 형식으로 나뉩니다.(이 중에서 문자열 형식과 오브젝트 형식은 참조형식입니다.)
복합데이터 형식은 기본 데이터 형식을 부품으로 삼아 구성되는 데이터 형식입니다. 종류에는 구조체와 클래스,배열 등이 있습니다.
데이터 형식은 기본 데이터 형식과 복합 데이터 형식으로 분류하는 동시에, 값 형식과 참조 형식으로 분류 할 수 있습니다.
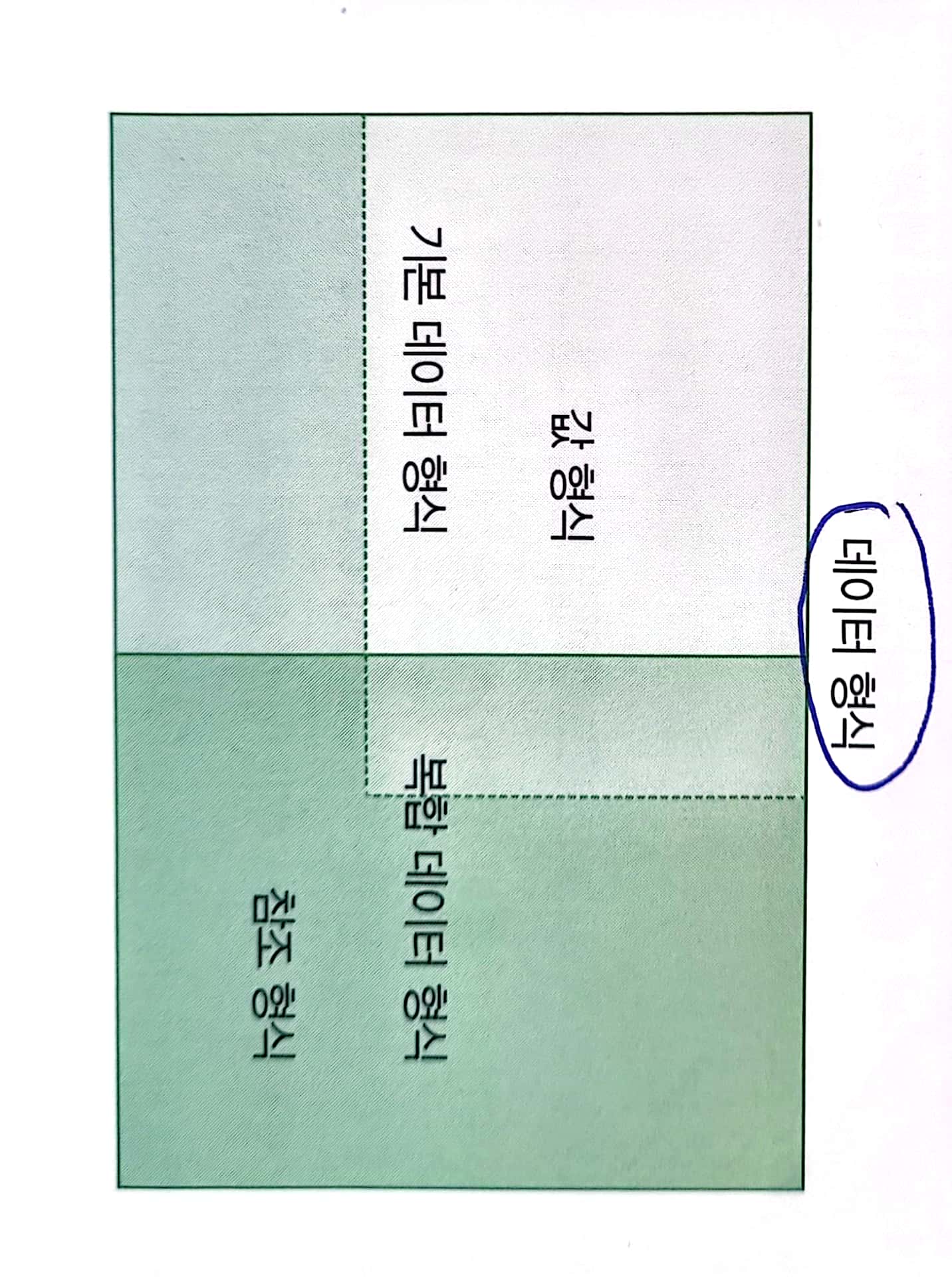
위 그림에 나타난 것처럼 기본 데이터 형식에도 값 형식과 참조 형식이 있고, 복합 데이터 형식에도 값 형식과 참조 형식이 있습니다.
3.2 변수
변수를 코드에서 보자면 값을 대입시켜 변화시킬 수 있는 요소이지만,메모리 쪽에서 보면 '데이터를 담는 일정 크기의 공간'이라는 의미를 갖기도 합니다. 변수를 선언하면 일정크기(변수의 형식에따라 다름)의 공간이 메모리에 예약됩니다.
int x;
x = 100;
int x = 100;
int x, y, z; //같은 형식의 변수들은 동시에 선언가능합니다.
int x = 0, y = 20, z = 100; //선언과 동시에 초기화를 한꺼번에 할 수도 있습니다. 3.2.1 리터럴(Literal)
literal을 사전에서 찾아보면 "문자 그대로의"라는 뜻을 가진 형용사라고 나옵니다. 컴퓨터 과학에서 리터럴은 고정값을 나타내는 표기법을 말합니다.
예를 들어 int x = 30;에서 x는 변수, 30은 리터럴입니다. 조금 더 예를 들어보겠습니다.
int a = 100; //변수 a, 리터럴 100
int b = 0x200; //변수 b, 리터럴 0x200
float c = 3.14f; //변수 c, 리터럴 3.14f
double d = 0.1234567; //변수 d, 리터럴 0.1234567
string s = "abcdefg"; //변수 s, 리터럴 abcdefg3.3 값 형식과 참조 형식
값 형식은 변수가 값을 담는 데이터 형식을 말하고,
참조 형식은 변수가 값이 있는 곳의 위치를 담는 데이터 형식을 말합니다.
C#에는 두가지 메모리 영역이 있는데 스택과 힙입니다
이 두 메모리 영역중에서 값 형식과 관련된것은 스택 메모리 영역이고,
참조 형식과 관련이 있는것은 힙 메모리 영역입니다.
스택
- 데이터를 쌓아 올리는 구조의 메모리
- 나중에 쌓인 데이터를 먼저 제거
- 처음에 쌓인 데이터를 나중에 제거
- 쌓인 순서의 역순으로 필요없는 데이터를 자동으로 제거(자동메모리)
값 형식(Value Type)이 들어가는 메모리 공간입니다. 일반적인 value type인 int, char, bool 같은 것이 있습니다. (string은 reference type입니다) 사용자가 선언한 struct도 value type으로 stack에 저장됩니다. 선언되었던 코드 블록이 끝나면 자동으로 메모리에서 해제됩니다.
힙
- 자유롭게 데이터를 저장할 수 있는 메모리
참조 형식(reference type)이 추가되는 메모리 공간입니다.
코드 블록과 상관없이 데이터가 사라지지 않습니다. 참조 형식의 변수는 heap과 stack 영역을 동시에 이용하는데 heap 영역에는 데이터의 값을 저장하고, stack 영역에는 데이터의 주소를 저장합니다. 따라서 코드 블록이 끝나는 순간 stack에 있는 데이터의 주소는 사라지지만 heap 영역에 존재하는 데이터의 값은 남아있게 됩니다. C#에서는 가비지 컬렉터(GC : Garbage Collector)가 주기적으로 heap을 청소합니다.
3.3.1 스택과 값 형식
코드 블럭 {} 안에 생성된 모든 값 형식의 변수들은 스택 메모리에 쌓이고, 코드 블록이 끝나면 메모리에서 제거 됩니다.
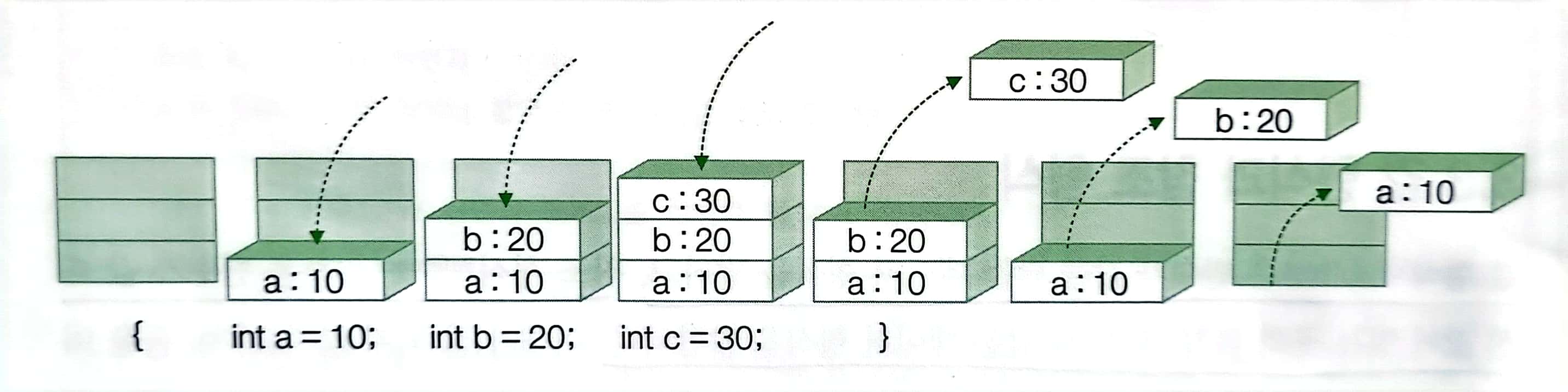
위 그림은 코드가 한 줄씩 실행 될때 마다 스택 메모리에 적재되었다가 걷혀 나가는 과정을 보여줍니다.
코드블록안에 생성된 모든 값형식의 변수들은 닫는 괄호 " } "를 만나는 순간 c,b,a순서로 메모리에서 제거됩니다.
- 메모리에 값을 담는 데이터 형식
- 스택에 할당(즉, 자동으로 제거됨)
- 기본 데이터 형식과 구조체가 여기에 해당
3.3.2 힙과 참조 형식 (참조 형식은 스택과 힙을 같이 사용)
프로그래머가 힙 메모리에 데이터를 올려 놓으면 코드블럭이 끝나는 시점과 상관 없이 데이터를 유지합니다. 힙에 올려둔 데이터를 프로그래머가 더 이상 참조 하는곳이 없으면 가비지 컬렉터가 수거해 갑니다. 참조 형식은 힙 영역에 데이터를 저장하고, 스택영역에는 데이터가 저장된 힙 메모리의 주소를 저장합니다.
- 메모리에 다른 변수의 주소를 담는 데이터 형식
- 힙에 할당(가비지 콜렉터에 의해 제거됨)
- 복합데이터 형식과 클래스 등이 여기에 해당
object a = 10;
object b = 20;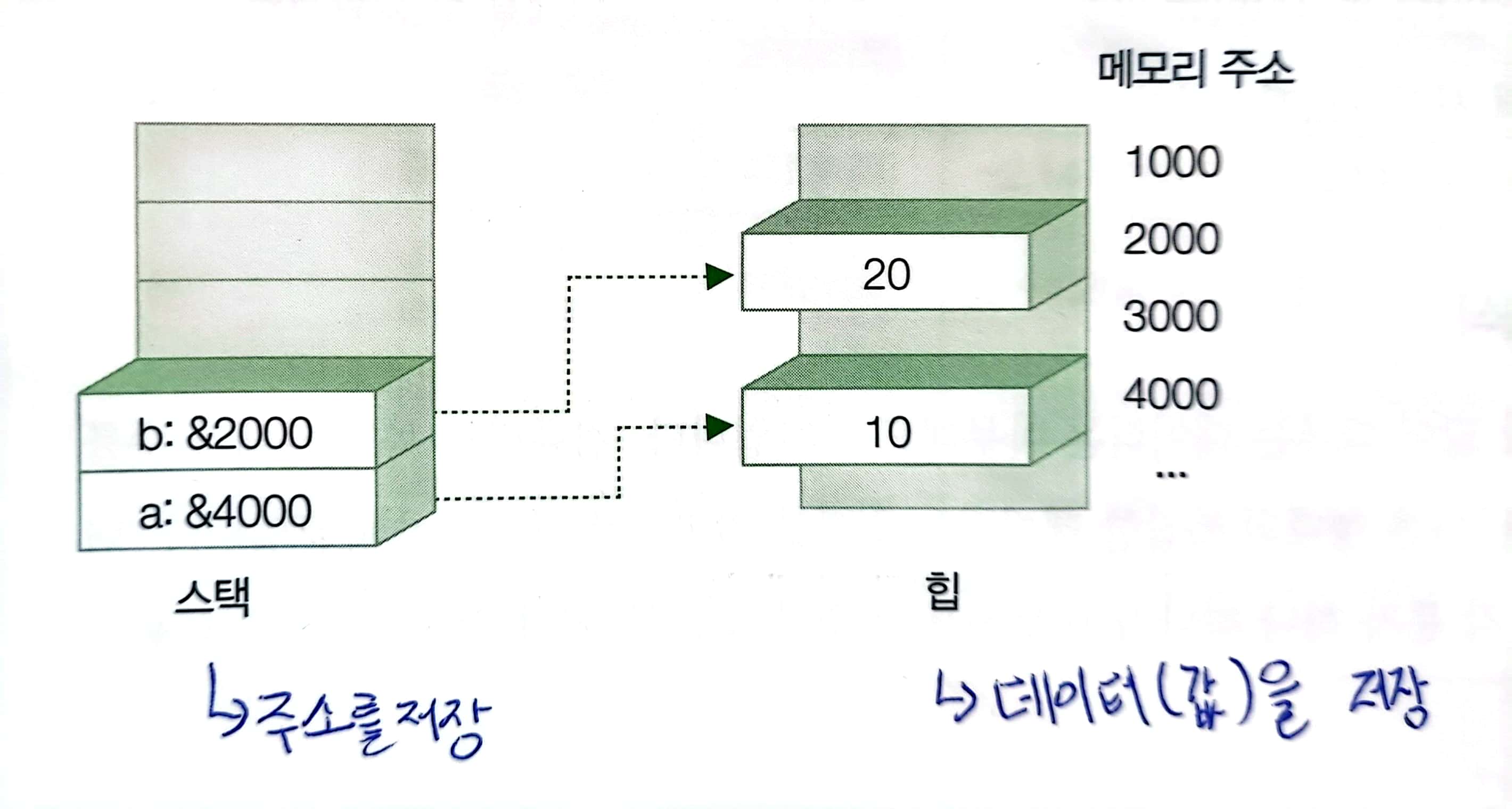
3.4 기본 데이터 형식
3.4.1 숫자 데이터 형식
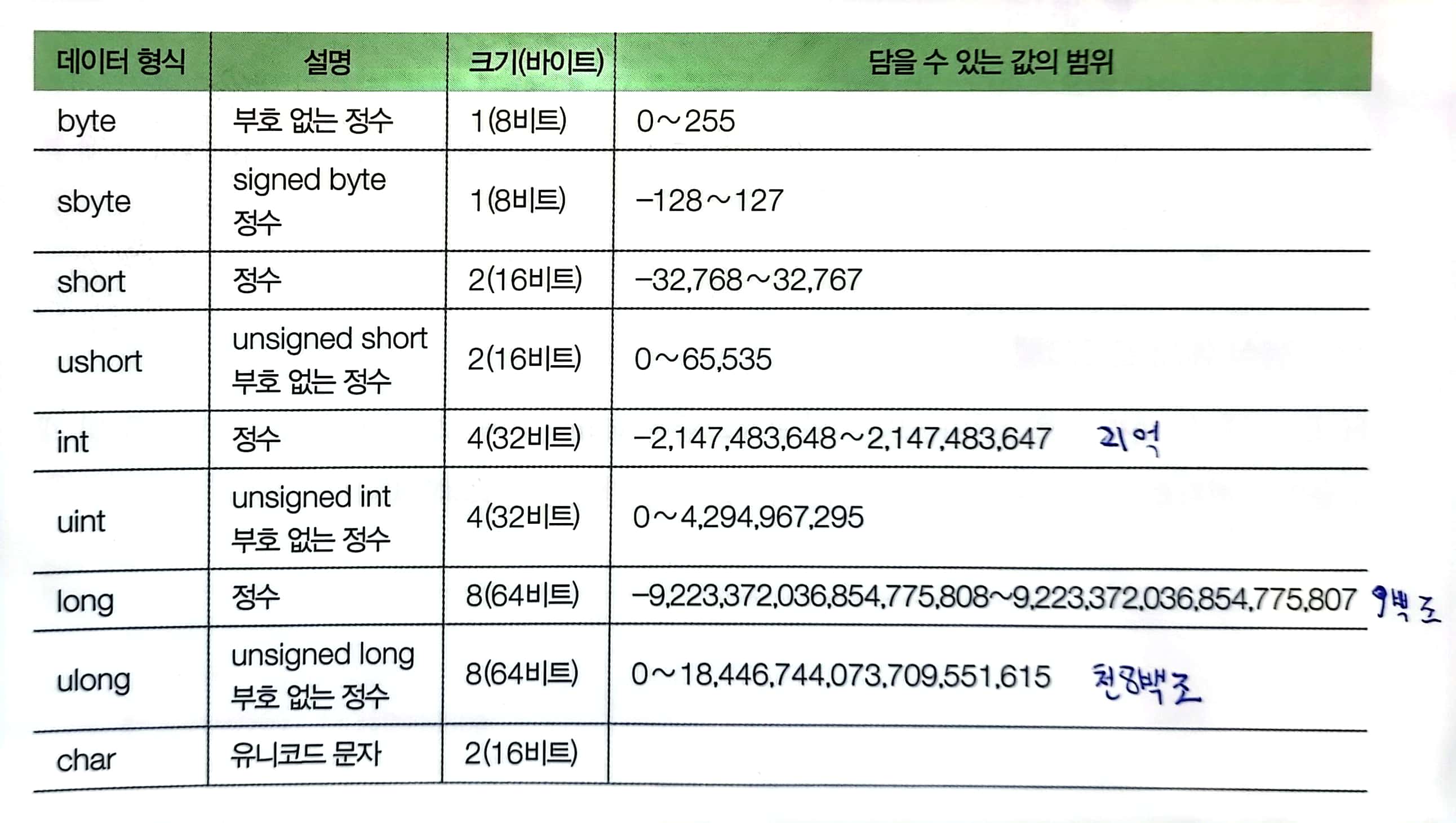
C#은 15가지 기본 자료 형식중에 12가지를 숫자 데이터 형식으로 제공합니다. 이 12가지 형식은 다시 정수 계열, 부동 소수 계열, 소수 계열 이렇게 3가지로 나뉩니다.
[정수계열 형식]
12가지 숫자 형식 중에 9가지가 정수 계열 형식입니다.
9가지 정수 형식은 각각 크기와 담을수 있는 데이터의 범위가 다른데, 프로그래머가 코드에 사용될 데이터가 어느 정도의 범위에 있는지 판단한 뒤 적절한 데이터 형식을 선택함으로써 메모리를 효율적으로 사용 할 수 있게 하기 위함입니다.
byte a = 255; //0~255 (양수)
sbute b = -128; //-128~127(음수~양수)
short c = -32_000; //자릿수 구분자(_)를 사용하면 편리합니다.
ushort d = 64_000;
int e = -2_100_000_000;
uint f = 4_200_000_000;
long g = -9_200_000_000_000_000_000;
ulong h = -18_400_000_000_000_000_000;[2진수,10진수,16진수 리터럴]
프로그래머는 경우에 따라서 2진수와 16진수를 다룰 일이 종종 생깁니다.
C#은 2진수 리터럴을 위해서 ob와(숫자 0과 알파벳 b) 16진수 리터럴을 위해 0X(또는 0x) 접두사를 제공합니다.
byte a = 240; //10진수 리터럴
byte b = 0b1111_0000; //2진수 리터럴
byte c = 0XF0; //16진수 리터럴
uint d = 0x1234_abcd; //16진수 리터럴[부호있는 정수와 부호 없는 정수]
부호 있는 정수라는 말은 음의 영역까지 다룬다는 것을,
부호 없는 정수라는 말은 0과 양의 정수만 다룬다는 것을 의미합니다.
그런데 똑같이 1바이트만 사용하는데도 부호있는 정수 sbyte는 -128~127을 담을 수 있고, byte는 0~255까지를 담는 이유는 뭘까요?
그것은 byte의 경우 비트 8개를 모두 수 표현에 사용하는 반면에 sbyte는 8개 중 7개 비트만 수 표현에 사용하고 첫 번째 비트는 부호를 표현하는 데 사용하기 때문입니다. 부호를 표현하는 데 사용하는 sbyte의 첫번째 비트는 부호 비트(sign bit)라고 합니다.
여기서 이상한 점은 -128입니다. (1비트 = 2가지 표현 가능, 1비트를 온전히 부호를 나타내는데 사용한다면 256(8비트)가지 중 254개의 숫자만 표현가능 해야하지 않나?) 그렇다면 첫 비트가 0이면 +, 1이면 -로 계산한다고 했을때
(-127 => 1111_1111), (127 => 0111_1111), 까지 즉 -128은 계산하지 못합니다.
더불어 0은 부호가 존재하지 않는데, (-0 => 1000_0000), (+0 => 0000_0000) 이렇게 두가지 형태로 +0과 -0이 존재하게 됩니다.
따라서 부호 있는 정수를 표현할때는 2의 보수라는 알고리즘을 사용하여 이 문제들을 해결합니다.
2의 보수로 부호를 나타낼 때 장점
첫번째) -0,+0이라는 혼돈을 피할수있음.
두번째) 수 한 개를 더 표현할 수 있음.
[오버플로우]
변수에도 데이터 형식의 크기를 넘어선 값을 담으면 넘치게 됩니다.
이런 현상을 오버플로(overflow) 라고 합니다.
uint a = uint.MaxValue;
Console.WriteLine(a); //uint의 최대값 4,294,967,295
a = a + 1; //오버플로 발생
Console.WriteLine(a); 출력
4,294,967,295
0
이런 현상이 발생하는 이유는 비트연산 때문입니다.
예를들어 byte의 최대값 255를 2진수로 바꾸면 1111 1111입니다.
여기에 1을 더하면 1 0000 0000이 됩니다. 하지만 byte는 8개의 비트만 담을 수 있기 때문에
왼쪽 비트는 버리고 오른쪽 0000 0000만 남깁니다 그래서 0이 되는 겁니다.
각 데이터는 최대값을 넘기면 오버플로가 발생하지만,
최저값보다 작은 데이터를 저장하면 언더플로우가 일어납니다.
가령 byte에 -1을 담고 출력하면 255로 나타납니다.
참고로 int에 최대값을 넣고 +1을 한다면 최소값이 나오게 됩니다.
스택 오버플로(stack overflow)가 무엇인가요?
할당된 스택 내에 stack frame이 쌓이게 되는데, 과도한 재귀 또는 너무 큰 지역 변수를 선언하게 되면 stack 영역의 크기를 초과하게 되면서 다른 메모리 영역을 침범하는 현상을 말합니다.
stack frame : 함수의 매개 변수, 반환 주소 값, 함수 내부의 지역 변수 등 함수의 호출 정보
힙(heep)도 오버플로우가 발생하나요?
사용자가 heap 메모리를 관리해야하는데 할당된 메모리 크기를 초과하게 되면 역시 똑같이 다른 메모리 영역을 침범합니다. C#의 경우 GC가 알아서 관리해주지만 의도하지 않게 계속 참조하고 있거나, 너무 큰 값을 할당하면 발생할 수 있습니다.
3.4.2 부동 소수점 형식
부동 소수점은 소수점이 고정되어있지 않고 움직이면서 수를 표현한다는 뜻에서 지어진 이름입니다.
소수점을 이동시켜 수를 표현하면 고정시켰을 때보다 더 제한된 비트를 이용하여 훨씬 넓은 범위의 값을 표현할 수 있기 때문입니다.
단점은 산술 연산 과정이 정수 계열 형식보다 복잡에서 느립니다.
부동 소수점 형식에는 float과 double 두 가지가 있습니다.

부동 소수점 형식은 float보다는 double을 사용하는것을 권합니다. double이 float에 비해 메모리를 두 배로 사용하지만 float에 비해 데이터 손실이 적기 때문입니다.
decimal 형식
double 형식을 사용했는데도 데이터 손실이 걱정된다면 형식을 사용하면 됩니다.
decimal도 실수를 다루는 데이터 형식입니다. 다만 앞에서 살펴본 부동 소수점과는
다른 방식으로 소수를 다루며 정밀도가 훨씬 높습니다.

class MainApp
{
static void Main(string[] args)
{
float a = 3.1415_9265_3589_7932_3846_2643_3832_79f; //f를 붙이면 float으로 간주
double b = 3.1415_9265_3589_7932_3846_2643_3832_79; //아무것도 없으면 double
decimal c = 3.1415_9265_3589_7932_3846_2643_3832_79m; //m을 붙이면 decimal
Console.WriteLine(a);
Console.WriteLine(b);
Console.WriteLine(c);
}
} 출력
3.1415927
3.141592653589793
3.1415926535897932384626433833
3.4.3 문자 형식과 문자열 형식
char 형식은 개별 문자표현을 위해, string 형식은 문자열 표현을 위해 사용합니다.
개별문자를 다룰때는 작은따옴표(''), 문자열을 표현할 때는 큰 따옴표("")로 표시합니다.
char c = '안';
string s = "안녕하세요";3.4.4 논리 형식
논리 형식(boolean Type)은 참(True),거짓(False)을 표현하기 위한 데이터 타입입니다.
참고로 1 바이트(= 8 비트)를 써서 표현하는데 이것은 컴퓨터가 기본적으로 다루는 데이터 크기가 바이트 단위이기 때문입니다.

bool a = true;
bool b = false;
Console.WriteLine(a);
Console.WriteLine(b);출력
True
False
3.4.5 object 형식
object 형식은 모든 데이터의 부모클래스로 만들어서 모든 데이터 형식을 다룰 수 있도록 했습니다. 그리고 object는 참조 형식이기 때문에 값이 힙에 할당되고 주소를 참조합니다.
object 형식은 박싱과 언박싱 과정에서 임시 객체가 생성되기도 하는데, 간혹 이로 인해 예상치 못한 버그를 발생시키기도 하기 때문에 박싱과 언박싱은 가능한 피하는것이 좋습니다.
3.4.6 박싱과 언박싱
박싱
object 형식은 '값' 형식의 데이터를 힙에 할당하기 위한 박싱 기능을 제공합니다.
object a = 20;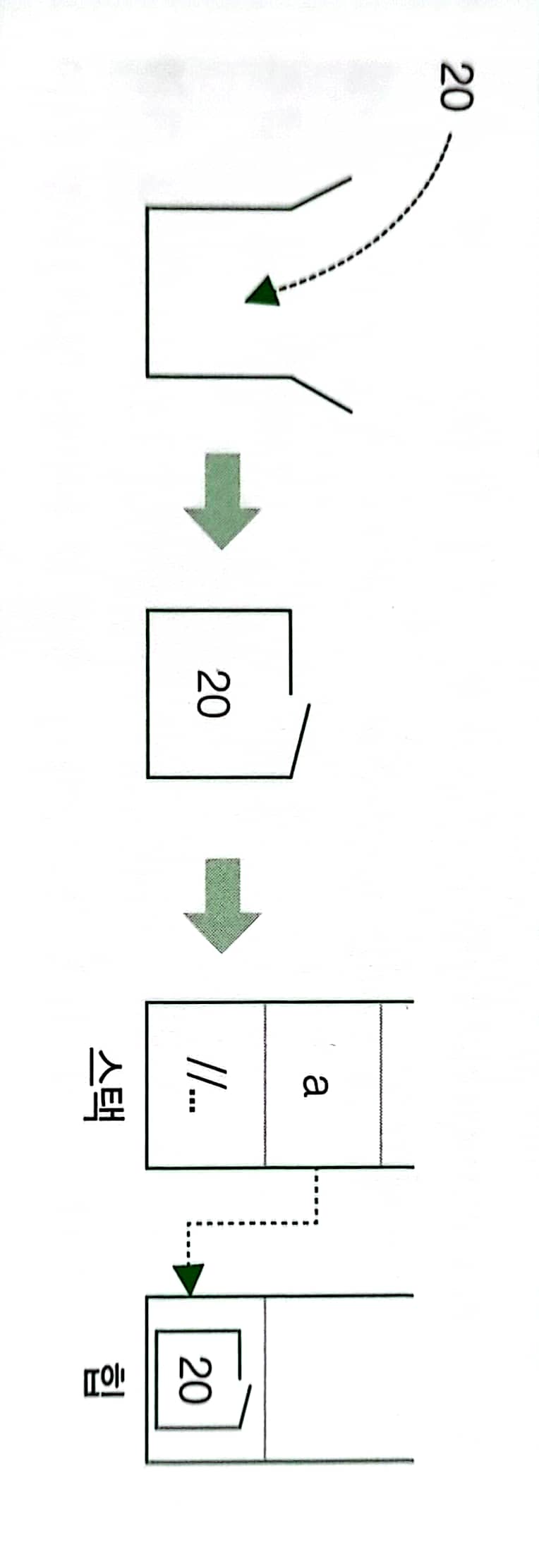
이렇게 선언 했을때 20은 힙에 할당 되고, a는 20을 참조하고 있습니다.
이 과정을 박싱이라고 합니다.
언박싱
object a = 20; //a에 담긴 값을 박싱해서 힙에 저장
int b = (int)a; //b에 담긴 값을 언박싱해서 스택에 저장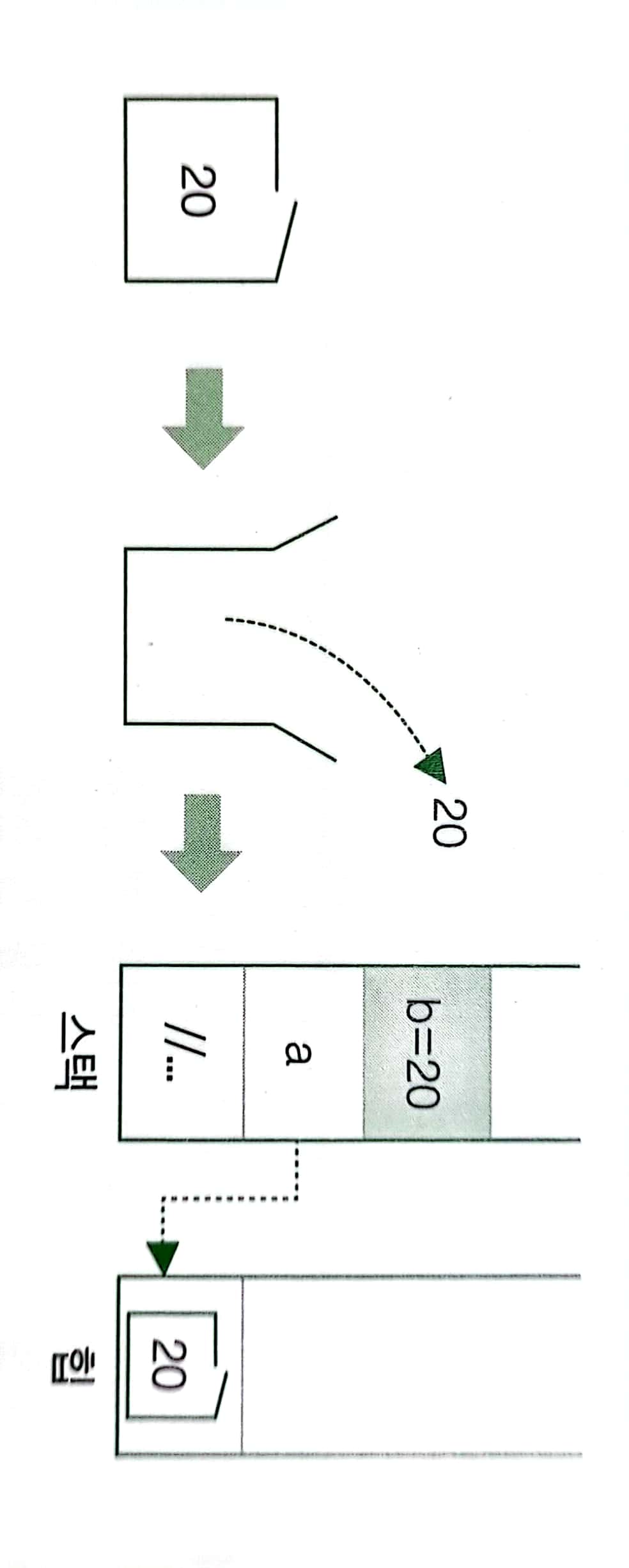
이 코드에서 a는 20이 박싱되어 저장된 힙을 참조 하고있습니다.
b는 a가 참조하고있는 메모리로 부터 값을 복사하려고 하는 중이고요.
이때 박싱된 값을 꺼내 값 형식변수에 저장하는 과정을 일컬어 언박싱이라고 합니다.
3.4.7 데이터 형식 바꾸기
변수를 다른 데이터 형식의 변수에 옮겨담는것을 형식 변환이라고 합니다.
주의 할점은 크기가 서로 다른 형식의 데이터 변환때문에 데이터에 손상이 갈수도있습니다.
✍정수 형식 사이의 변환에서 원본 변수의 데이터가 형식 변환하려는 대상 변수의 용량보다 큰 경우에는 오버플로가 발생합니다.
int x = 128; //sbite보다 1큰수
sbyte y = (sbyte)x;✍float와 double사이의 형식 변환에서는 정밀성의 손상을 입습니다.
float x = 0.1f
double y = (double)x;💻 출력
결과) y : 0.10000000000149011612
✍부동 소수점형식과 정수 형식 사이의 변환입니다. 부동소수점형식의 변수를 정수 형식으로 변환하면 데이터에서 소수점 아래는 버리고 소수점 위의 값만 남깁니다.
0.1을 정수 형식으로 변환하면 0이 되지만 0.9도 0이됩니다.
flaot a =0.9f;
int b = (int)a;✍문자열을 숫자로 변환은 Parse()함수를 사용합니다.
int a = int.Parse("12358");✍숫자를 문자열로 변환할때는 ToString()함수를 사용합니다.
float e = 1235;
string f = e.ToString();3.5 상수와 enum(열거 형식)
상수와 열거형식은 프로그래머의 실수를 막기위한 장치로, 안에 담긴 데이터를 절대 변경할수없게 한 장치 입니다.
✍상수
- 상수 : 최초의 상태를 유지하는 수
- const 키워드를 이용하여 선언
const int Max_INT_BIT = 32;
const double b = 3.14;✍enum (열거형식)
- 하나의 이름 아래 묶인 상수들의 집합
- enum 키워드를 이용하여 선언
enum Dialogresurt { YES, NO, CANCEL, CONFIRM, OK }
Dialogresurt resurt = Dialogresurt.YES;열거 형식 예제 프로그램입니다.
using System;
namespace EmptySpace
{
public enum Dialogresult { None = 0, YES, NO, CANCEL, CONFIRM, OK } //enum 선언
class MainApp
{
Dialogresult dialogresult;
static public void RandomConsoleOut()
{
Random rnd = new Random();
int rndNumber = rnd.Next(1, 5);
switch (rndNumber)
{
case (int) dialogresult.YES: //명시적 형변환(int) 필요함
Console.WriteLine("YES");
break;
case (int) dialogresult.NO:
Console.WriteLine("NO");
break;
case (int) dialogresult.CANCEL:
Console.WriteLine("CANCEL");
break;
case (int) dialogresult.CONFIRM:
Console.WriteLine("CONFIRM");
break;
case (int) dialogresult.OK:
Console.WriteLine("OK");
break;
default:
Console.WriteLine("None");
break;
}
}
static void Main(string[] args)
{
RandomConsoleOut();
}
}
}3.6 Nullable형식
C#컴파일러는 메모리 공간에 반드시 어떤 값이든 넣도록 강제합니다.
하지만 가끔 어떤값도 가지지 않는 변수가 필요할때가 가끔 있습니다.
이런경우,nullable형식으로 메모리 공간이 비어있는 변수를 만들수 있습니다.
✍ 입력
int? a = null;
double? c = null;또한 nullable형식은 HasValue와 Value 두가지 속성을 가지고있습니다.
HasValue는 값을 가지고있는지 아닌지를 true,false로 알려주고,
Value는 변수에 담긴 값을 나타냅니다.
✍ 입력
Consol.WriteLine(a.HasValue); // false 출력
a = 37;
Consol.WriteLine(a.Value); // 37 출력
3.7 var 형식
C#은 var키워드를 통한 약한 형식 검사를 지원합니다.
int,string같은 명시적 형식 대신 var를 사용하여 변수를 선언하면 컴파일러가 자동으로 변수의 형식을 지정해줍니다. 단,var키워드를 통해 선언할때는 반드시 선언과 동시에 초기화를 해줘야 합니다. 그래야 컴파일러가 데이터를 보고 추록할 수 있기 때문입니다. 그러므로 var는 지역변수로만 사용할수있습니다. 이유는 클래스의 필드는 선언과 같이 초기화하지않는 경우가 대부분인데(생성자가 있기 때문에)var 키워드로 필드를 선언하면 컴파일러가 파악하지 못하기 때문입니다.
- var 키워드로 선언한 변수는 컴파일러가 리터럴을 분석하여 자동으로 형식을 추론함
- 지역 변수에 대해서만 사용 가능
✍ 입력
var a = 3; //a는 int
var b = "Hello"; //b는 string✍ +) var와 object의 차이점
object a = 20; //20을 박싱하여 힙에 올림
var b = 20; //20을 b에 담아 스택에 올림메모리에 올려놓는 방식이 다릅니다.
object는 20를 박싱해서 힙에 올려두고 a가 20을 가르키도록 하겠지만,
var는 컴파일 시점에서 추론하여 var를 int로 바꿔버립니다.그러므로 var는 객체 b에 20을 담아 스택 메모리에 올립니다.
3.8 공용 형식 시스템
공용 형식 시스템은 "모두가 함께 사용하는 데이터 형식체계"라는 의미 입니다. 여기에서 모두는 C#을 비롯한 .NET을 지원하는 모든 언어를 뜻합니다. .NET을 지원 하는 언어들끼리 서로 호환성을 갖도록 하기위함입니다.
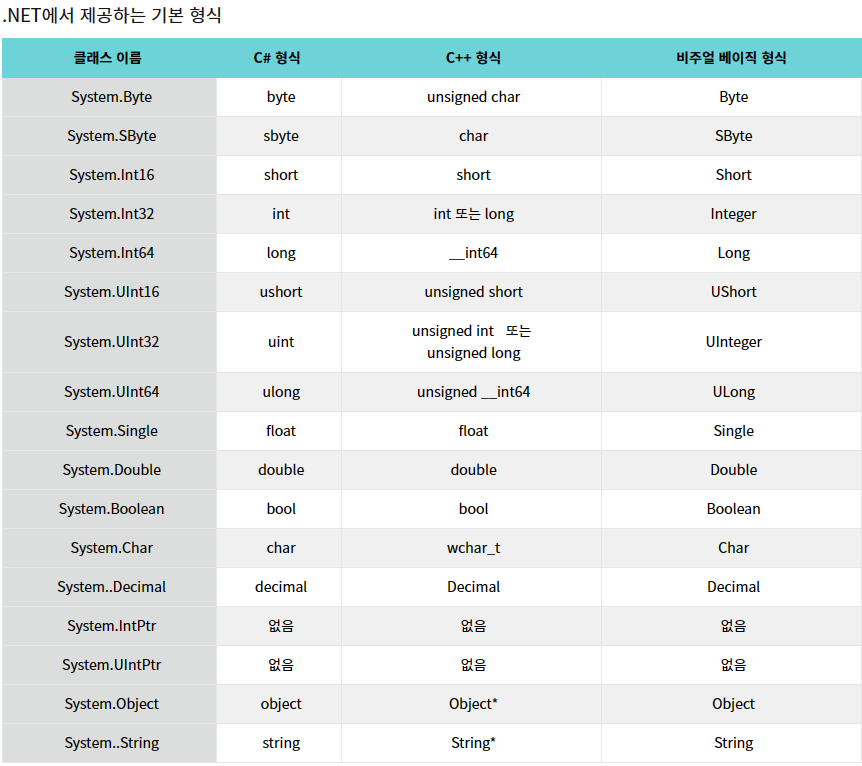
3.9 문자열 다루기
문자열 안에서 문자열 찾기
문자열내의 특정 부분을 찾는 기능입니다.

문자열 변형하기
문자열 중간에 또 다른 문자열을 삽입하거나 특정 부분을 삭제하는 등의 작업을 수행합니다.
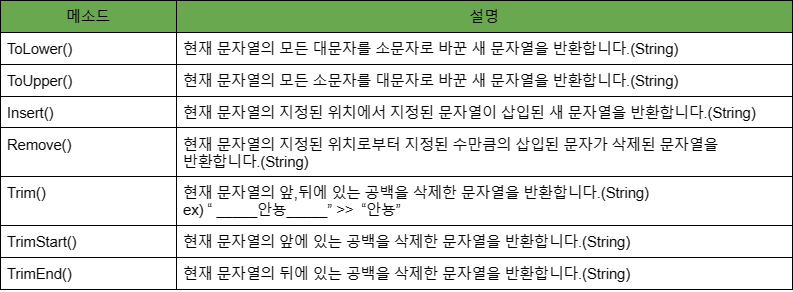
문자열 분할하기
문자열에서 - , " " 등 문자을 구분할때 쓰는 내용을 제외한 단어를 배열로 만들수있습니다.
Split,SubString의 자세한 내용

문자열 서식 맞추기
문자열이 일정한 틀과 모양을 갖추도록 합니다.
문자열 보간
보간이라는 말은 비거나 누락된 부분을 채운다라는 뜻입니다.
{0}, {1} 과 같이 서식 항목들의 순서를 정해주는 Format() 방법과 달리
문자열 보간이라는 방법은 string 안에 직접 변수 이름을 집어 넣습니다.
"문자열" 이라고 있는 이 큰 따옴표(") 앞에 달라($)표기를 해주면 중괄호 안에 변수를 입력할 수 있습니다.
문자열 보간의 자세한 내용
✍ 입력
string str1 = "맞아요 내가 보간이에용~";
Console.WriteLine($"문자열 보간이십니까? {str1}");💻 출력
문자열 보간이십니까? 맞아요 내가 보간이에용~
