1. group by
범주의 통계를 내줌
문제에 ㅁㅁ별 데이터 추출하기가 있으면 무조건 group by ㅁㅁ!!
select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명
group by 범주별로 세어주고 싶은 필드명;min
select 범주가 담긴 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;max
select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;avg
select 범주가 담긴 필드명, avg(평균값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;sum
select 범주가 담긴 필드명, sum(합계를 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;2. order by
어떻게 정렬해줄 것인지를 알려주는 함수
기본이 오름차순, 내림차순은 desc
select * from 테이블명
order by 정렬의 기준이 될 필드명 desc(내림차순)쿼리가 실행되는 순서: from → group by → select → order by
select name, count(*) from users group by name order by count(*);
3. Alias
같은 필드명이 여러 테이블에 있을 때 테이블.필드명을 쓰는데 그 때 쿼리가 너무 길어질 수 있으므로 별칭을 붙여줌
orders o -> orders = o
select * from orders o
where o.course_title = '앱개발 종합반'출력된 필드명이 count() 면 보기에 안좋으니까 다른 별칭으로 지어줌
count() as cnt -> count(*) = cnt
select payment_method, count(*) as cnt from orders o
where o.course_title = '앱개발 종합반'
group by payment_method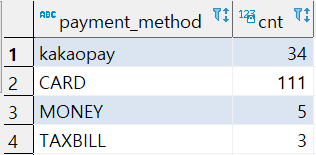

QA Engineer