numpy 라이브러리에 대해서 학습
라이브러리 선언
import numpy as npnumpy array로 변경방법
temp = [10,8,6,7,'hi']
temp1 = [10,8,6,7]
temp2 = ['hi']
x = np.array(temp)
z = np.array(temp1)
y = np.array(temp2)
print(type(x)) # ndarray type
print(type(y))
print(type(z))여기서 numpy는 무조건 array이다. 이말은 list와 달리 하나의 자료형만 들어갈 수 있다는 얘기다. 자세한건 아래 api 주소를 들어가보자
https://numpy.org/doc/stable/reference/index.html#reference
다차원 배열
score = [[1,2,3,4],
[5,6,7,8]]
x = np.array(score)
x출력 결과
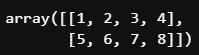
위 처럼 array 형태로 나오게 된다.
type() 이라는 함수를 통해 우리가 만든 x의 type 을 알 수 있다.
그 밖에
원하는numpydata.dtype : data type 을 확인할 수 있다. ex) int64,int32 ...
.shape : 어레이의 크기를 확인 할 수 있는 함수이다.
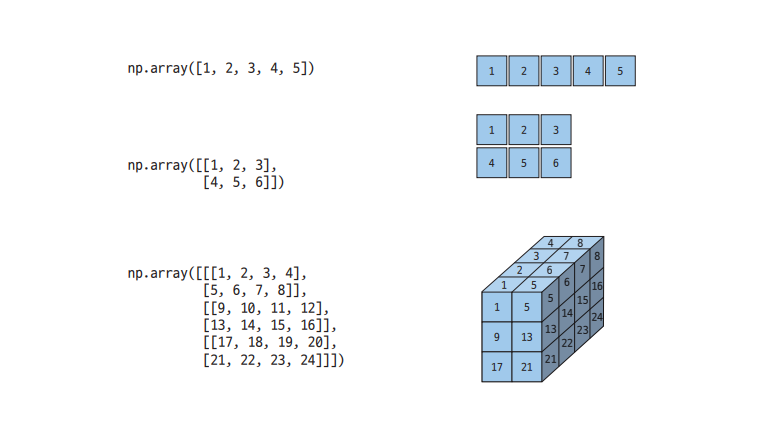
위 사진은 다차원 배열의 그림이다. 저런식으로 구성되어있고 axis 가 중요한데 다음 그림에서 설명하겠다.
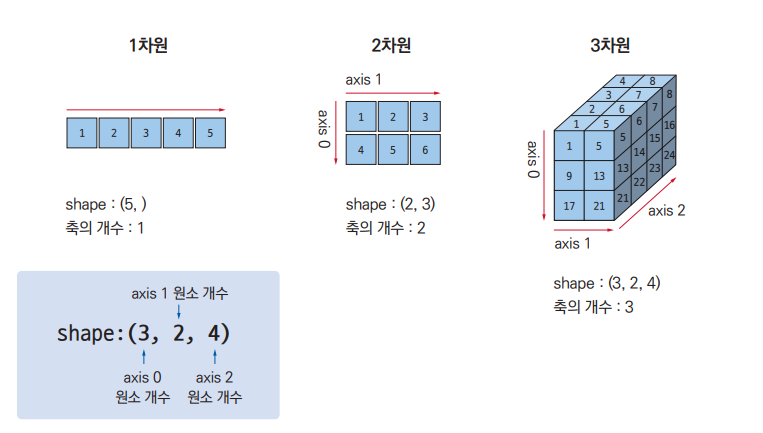
위 그림은 배열의 차원을 보여주는 axis 1은 보통 columns 을 뜻하고 0은 row를 뜻한다. 이를 잘아아야 추후에 pandas를 이용한 data 처리를 잘하게된다.
슬라이싱, 인덱싱
인덱싱에는 두가지 종류가 존재한다.
1. fancy indexing
2. boolean indexing
첫 번째로 fancy indexing 은 다음 예제를 보게되면 이해 할 수 있다.
X = np.array([[4,5,6],[8,9,0]])
X[1,[1,2]] # fancy indexing이에 대한 출력은 array([9,0]) 이런식으로 되는데 이유는 앞에 1은 첫번째 행에서 row를 참조하고 그뒤로 1부터 2까지 모두 indexing 해라이므로 [8,9,0] 에서 1번째와 2번째는 9,0이므로 저런식으로 나오게된다. (배열은 무조건 처음 index 가 0이다.
다음으로 boolean indexing인데 추후 one-hot vector에서 많이 쓰이기 된다.
X = np.array([1,2,3,4,5])
idx = [False,True,True,False,False] # boolean indexing
X[idx]array([2, 3]) 이런식의 결과가 출력된다.
그 밖에 다양한 덧셈 평균구하는 함수
np.sum(X,axis=1) # 1번 column 을 기준으로 더해라라는 뜻이다.
np.mean() # 여기도 api를보게되면 axis 기준으로 평균낼수있다.
broadcasting
X.astype(np.int64) # 데이터 타입을 int64로 바꾼다. 추후에 데이터가 너무많아 메모리를 너무 많이 잡아먹는 상황에서 int8 이나 bit수를 줄여 메모리 사용을 줄이게 해주는 역할을 수행한다.
난수 생성함수
[0.0,1) 0과 1사이의 값을 반환하는 함수이다.
세가지 종류가있는데
-
np.random.random(3) # array의 shape를 설정할수있다.
np.random.random((3,3))이런식으로 2차원 array도 가능 -
np.random.rand() # 정규분포 추출 함수
-
np.random.randint() # 난수를 정수로 바꾸고 싶을때 사용한다.
np.random.randint(1,1000,(3,2)) 이런식으로 1~1000사이 값으로 3,2 shape의 크기로 출력한다. -
np.random.seed() # 랜덤때문에 모델 성능이 오른건지 아니면 모델때문에 성능이 오른건지 확인이 힘들때 시드를 고정시킨다. 그러면 값이 안바뀌고 랜덤으로 그 부분에서 뽑아온다.
np.random.seed(2022)
np.random.randn(3)
이와같이 만들면 된다.
연산
행렬 곱과 덧셈, 그리고 dotproduction(내적) 을 numpy 에서 지원해준다. 다음과 같은 함수들이 존재한다.
np.add(x,y) # 덧셈
np.subtract(x,y) # 뺄셈
np.divide(x,y) # 나눗셈
np.multiply(x,y) # 이함수가 특이한데 원래 행렬 곱은 다른방식이지만 이방법은 같은 위치의 값끼리 곱해서 출력을 하는 함수이다. 즉 내적이 아니다.
np.dot(x,y) # 내적
저장 savez()
확장자는 npz이다.
뒤에는 내가 저장할 값을 dictionary 형태로 저장할수있어 다음과 같이 적는다.
np.savez('원하는파일이름.npz',xvar = x, yvar = y)
load
mydata = np.load('datapath') # 데이터 경로를 적어 로드한다.
여기서 우리가 key 값으로 설정한 값을 딕셔너리처럼 사용하면 뽑아낼수있다.
x = mydata['xvar']