실습 목표
-
직접 ResNet 구현하기
-
모델을 config에 따라서 변경 가능하도록 만들기
-
직접 실험해서 성능 비교하기
학습내용
-
Ablation Study
-
CIFAR-10 데이터셋 준비
-
블록 구성
-
VGG Complete Model
-
VGG-16 vs VGG-19
-
ResNet Ablation Study
Ablation Study
딥러닝 논문은 여러 방법을 통해서 문제 해결 방식을 제시하고, 이 방식들은 실효성을 증명되기 위해서는 제거한 모델 시험과 제시한 방식으로 추가한 모델 실험 결과를 비교합니다.
Ablation Study는 이처럼 아이디어 제거를 통해서 제안한 방법이 주는 성능이나 효과를 확인하는 실험을 뜻합니다.
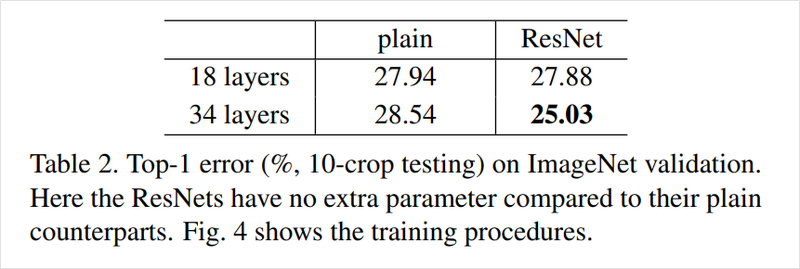
즉, ResNet논문에서 제시한 residual connection이 Ablation Study입니다. 왜냐하면 이미지넷 검증 데이터셋에 대한 Top-1 error rate 지료를 통해 residual connection이 있는 것과 없는 plain network를 비교했고 이 비교를 통해서 성능 향상을 증명했기 때문입니다.
Ablation Study 실습
실험 결과들이 실제로 유효함을 갖는지 실제 실습을 해보도록 하겠습니다. 실습 이기에 동일 데이터가 아닌 적당한 크기의 CIFAR-10 dataset을 이용하겠습니다.
우리의 실험 목적은 CIFAR-10 일반 네트워크와 ResNet구현을 하고 이 둘을 비교해서 ResNet 및 residual connection의 유효성 확인하는 것이고, 저번 블로그에 논문 정리와 구현을 했기에 코드 이해가 이전보다 잘 될 겁니다.
실습의 진행을 편하게 하도록 코드 주석처리 와 중간 중간에 용어나 진행설명 후 코드를 진행했습니다.
CIFAR-10 데이터 준비
이 데이터셋은 10개의 카테고리이고 6만 장의 이미지가 있고 32x32픽셀입니다. 이 데이터셋을 사용하면 물체의 종류 를 분류할 수 있습니다.
6만 장이라는 꽤 많은 데이터를 로드하려면 긴 시간이 걸리니 맘의 여유를 갖고 임하세요.
데이터 셋이 준비가 되면 클래스의 수와 이름을 볼 수 있습니다.
Follow the Code
- -------- 이것을 기준으로 나눠서 코드를 치는 것을 권장드립니다.
Flow
-
Tensorflow 설치
-
필요한 라이브러리 불러오기
-
GPU확인
# Tensorflow datasets패키지가 없을 시 설치하기
! pip install tensorflow-datasets
---------------------------------------
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
-------------------
# Tensorflow가 활용할 GPU가 장착되어 있는지 확인해 봅니다.
tf.config.list_physical_devices('GPU')
Flow
-
데이터 다운로드
-
데이터 특성 정보 파악
-
훈련과 테스트 데이터 개수 파악
# 데이터 로드
import urllib3
urllib3.disable_warnings()
#tfds.disable_progress_bar() # 이 주석을 풀면 데이터셋 다운로드과정의 프로그레스바가 나타나지 않습니다.
(ds_train, ds_test), ds_info = tfds.load(
'cifar10',
split=['train', 'test'],
shuffle_files=True,
with_info=True,
) # tfds.load(): 기본적으로 ~/tensorflow_datases 경로 데이터셋을 다운로드하고 혹시 데이터셋 경로를 바꾸고 싶다면, data_dir인자 사용하기
-----------
# Tensorflow 데이터셋을 로드하면 꼭 feature 정보를 확인해 보세요.
print(ds_info.features)
-------------
# 데이터의 개수도 확인해 봅시다.
print(tf.data.experimental.cardinality(ds_train))
print(tf.data.experimental.cardinality(ds_test))
Input Normalization
이미지는 픽셀의 수를 사용하여 이미지 크기를 알 수 있고 픽셀이 가진 채널 값을 통해서 픽셀의 색을 표현하기도 합니다. 이렇게 다양한 것이 다 들어오면 모델은 혼란을 느낄 수 있기에 우리는 먼저 입력 데이터 정규화를 합니다.
정규화는 채널별 최대값이 255로 해주어서 이미지의 표현이 0과1사이로 들어오도록 합니다.
Flow
-
입력데이터 정규화
-
클래스 개수 파악
-
클래스 종류 파아
-
클래스 사진들 눈으로 보기
# 정규화 및 이미지 크기 재조정
def normalize_and_resize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
# image = tf.image.resize(image, [32, 32])
return tf.cast(image, tf.float32) / 255., label
---------------
### 정규화된 데이터셋 적용하기
def apply_normalize_on_dataset(ds, is_test=False, batch_size=16):
ds = ds.map(
normalize_and_resize_img,
num_parallel_calls=1
)
ds = ds.batch(batch_size)
if not is_test:
ds = ds.repeat()
ds = ds.shuffle(200)
ds = ds.prefetch(tf.data.experimental.AUTOTUNE)
return ds
-----------
#클래스 개수
ds_info.features["label"].num_classes
-----------------
# 클래스 종류
ds_info.features["label"].names
-----------
# 크기가 일정한 데이터셋의 사진들이 출력됩니다.
fig = tfds.show_examples(ds_train, ds_info)
--------------
# 크기가 일정한 데이터셋의 사진들이 출력됩니다.
fig = tfds.show_examples(ds_test, ds_info)
Ablation Study 실습
블록 구성하기
블록은 주요 구조를 모듈화 시켜 조금씩 바꿔 쓸 수 있는 단위를 말합니다
레이어는 기본적인 라이브러리등에서 제공하는 단위입니다.
ResNet을 한 방에 이해해서 바로 구현하면 좋지만 조금 더 간단한 VGG를 예시로 구현하겠습니다.
VGG블록은 CNN레이어(3X3) 여러 개 와 Max pooling레이어 한 개로 이뤄져있고 한 블록 내 레이어의 채널은 하나로 유지가 되기에 다른 CNN레이어의 채널 수와 다를 수 있습니다.
그리고 CNN의 레이어 수와 채널을 조절하면서 만들어야합니다.
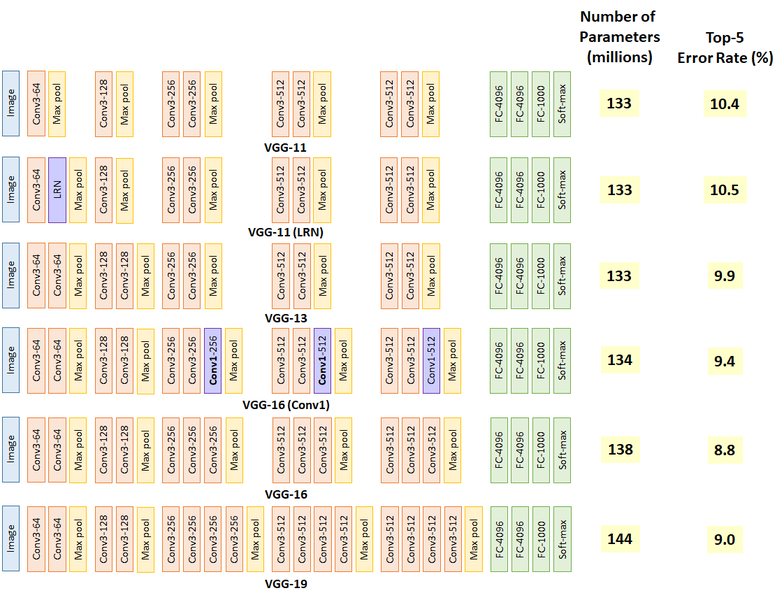
여러 VGG종류 중에서 16과 19 기본 구조 블록을 만들겠습니다.
Flow
-
함수로 VGG모델 만들기
-
Input_layer와 Output 지정
-
Summary(모델 구성)
# function for building VGG Block
def build_vgg_block(input_layer,
num_cnn=3,
channel=64,
block_num=1,
): #block_num은 레이어의 이름 붙여주기
# 입력 레이어
x = input_layer
# CNN 레이어
for cnn_num in range(num_cnn):
x = keras.layers.Conv2D(
filters=channel,
kernel_size=(3,3),
activation='relu',
kernel_initializer='he_normal',
padding='same',
name=f'block{block_num}_conv{cnn_num}'
)(x)
# Max Pooling 레이어
x = keras.layers.MaxPooling2D(
pool_size=(2, 2),
strides=2,
name=f'block{block_num}_pooling'
)(x)
return x
-------------------
vgg_input_layer = keras.layers.Input(shape=(32,32,3)) # 입력 레이어 생성
vgg_block_output = build_vgg_block(vgg_input_layer)
----------------
# 블록 1개짜리 model 생성
model = keras.Model(inputs=vgg_input_layer, outputs=vgg_block_output)
# 케라스의 Model클래스에서 I/O정의하면
model.summary() # 블록 모델 요약본 확인 가능
Ablation Study
VGG Complete Model
블록 내의 CNN 레이어 수와 채널 수는 블록마다 달라지고 함수로 전달이 되어야합니다. 각 블록은 CNN의 수와 채널을 리스트로 전달하겠습니다.
Flow
-
VGG모델 생성함수
-
VGG16
-
VGG19
# VGG 모델 자체를 생성하는 함수입니다.
def build_vgg(input_shape=(32,32,3),
num_cnn_list=[2,2,3,3,3],
channel_list=[64,128,256,512,512],
num_classes=10):
assert len(num_cnn_list) == len(channel_list) #모델을 만들기 전에 config list들이 같은 길이인지 확인합니다.
input_layer = keras.layers.Input(shape=input_shape) # input layer를 만들어둡니다.
output = input_layer
# config list들의 길이만큼 반복해서 블록을 생성합니다.
for i, (num_cnn, channel) in enumerate(zip(num_cnn_list, channel_list)):
output = build_vgg_block(
output,
num_cnn=num_cnn,
channel=channel,
block_num=i
)
output = keras.layers.Flatten(name='flatten')(output)
output = keras.layers.Dense(4096, activation='relu', name='fc1')(output)
output = keras.layers.Dense(4096, activation='relu', name='fc2')(output)
output = keras.layers.Dense(num_classes, activation='softmax', name='predictions')(output)
model = keras.Model(
inputs=input_layer,
outputs=output
)
return model
----------
# 기본값을 그대로 사용해서 VGG 모델을 만들면 VGG-16이 됩니다.
vgg_16 = build_vgg()
vgg_16.summary()
---------
# 원하는 블록의 설계에 따라 매개변수로 리스트를 전달해 줍니다.
vgg_19 = build_vgg(
num_cnn_list=[2,2,4,4,4],
channel_list=[64,128,256,512,512]
)
vgg_19.summary()
Ablation Study
VGG-16 vs VGG-19
VGG의 레이어 차이를 비교하기 위해서 16과19를 비교하겠습니다.
Flow
-
파라미터 설정
-
CIFAR10 dataset 부르기
-
VGG16모델 훈련
-
VGG19모델 훈련
-
VGG16 과 VGG19의 손실과 정확성비교하기 (그래프 시각화)
# 파라미터 설정
BATCH_SIZE = 128
EPOCH = 20
-------------------------
# CIFAR10 데이터셋 부르기
(ds_train, ds_test), ds_info = tfds.load(
'cifar10',
split=['train', 'test'],
as_supervised=True,
shuffle_files=True,
with_info=True,
)
ds_train = apply_normalize_on_dataset(ds_train, batch_size=BATCH_SIZE)
ds_test = apply_normalize_on_dataset(ds_test, batch_size=BATCH_SIZE)
-----------
#VGG16 모델 훈련
vgg_16.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=0.01, clipnorm=1.),
metrics=['accuracy'],
)
history_16 = vgg_16.fit(
ds_train,
steps_per_epoch=int(ds_info.splits['train'].num_examples/BATCH_SIZE),
validation_steps=int(ds_info.splits['test'].num_examples/BATCH_SIZE),
epochs=EPOCH,
validation_data=ds_test,
verbose=1,
use_multiprocessing=True,
)
------------
#VGG19모델 훈련
vgg_19.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=0.01, clipnorm=1.),
metrics=['accuracy'],
)
history_19 = vgg_19.fit(
ds_train,
steps_per_epoch=int(ds_info.splits['train'].num_examples/BATCH_SIZE),
validation_steps=int(ds_info.splits['test'].num_examples/BATCH_SIZE),
epochs=EPOCH,
validation_data=ds_test,
verbose=1,
use_multiprocessing=True,
)
-----------------
# 손실 비교(낮을 수록 좋음)
import matplotlib.pyplot as plt
plt.plot(history_16.history['loss'], 'r')
plt.plot(history_19.history['loss'], 'b')
plt.title('Model training loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['vgg_16', 'vgg_19'], loc='upper left')
plt.show()
--------------------
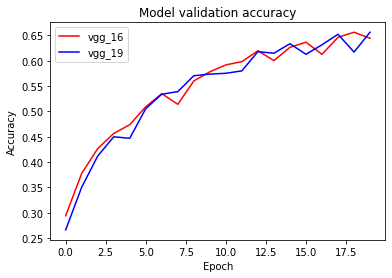
## 정확성(높을 수록 좋음)
plt.plot(history_16.history['val_accuracy'], 'r')
plt.plot(history_19.history['val_accuracy'], 'b')
plt.title('Model validation accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['vgg_16', 'vgg_19'], loc='upper left')
plt.show()
결론
코드를 통해서 직접 실습을 해보고 그래프를 통한 시각화 또한 하니 논문구현을 해본 것 같아서 재미있었습니다.