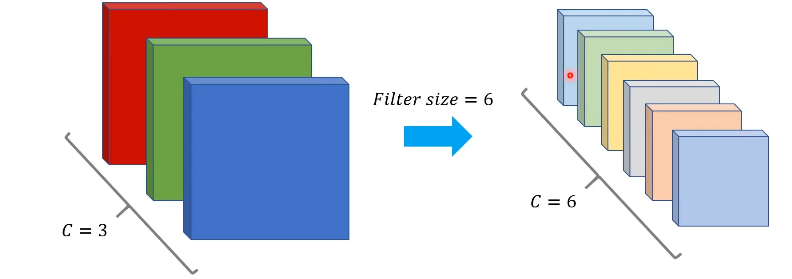
CNN 모델의 특징 맵
-
레이어가 깊어질 수록 채널 수는 증가, 넓이와 너비는 감소
-
서로 다른 필터 -> 서로 다른 적절한 특징값 추출.
-
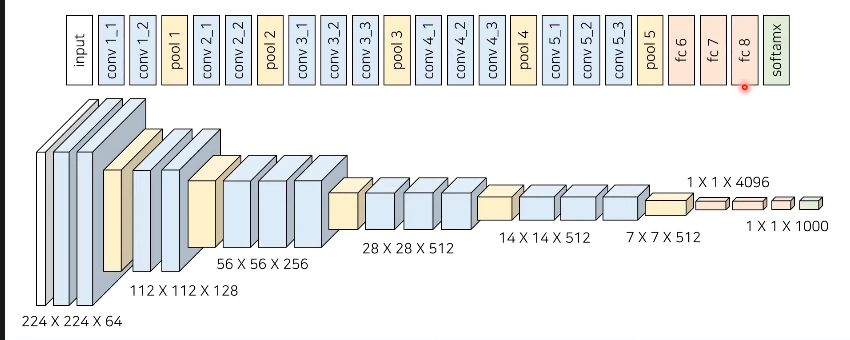
VGG 네트워크 : 3 * 3 필터 -> 레이어 깊이 늘림, 성능 좋아!!
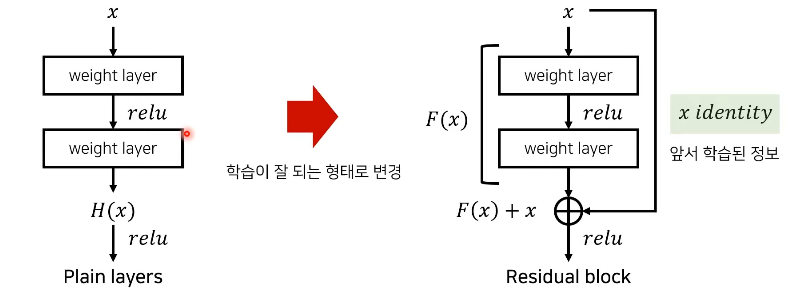
ResNet 핵심 idea
잔여 블록(Residual Block)
: 네트워크의 최적화 난이도를 낮춘다
: 내재 매핑인 H(x)를 바로 학습이 어렵기 때문에 F(x) = H(x) -x로 낮춰서 학습
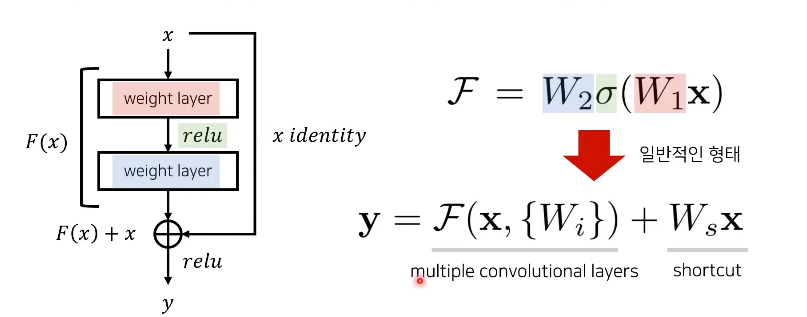
테스트 결과
: 레이어가 깊어질 수록 성능이 향상이 됨(허나, 너무 깊게 만들면 오히려 감소)

논문
-
레이어를 깊게 쌓는다면..?
: 무조건적인 성능향상 안됨
: 훈련 에러를 높인다
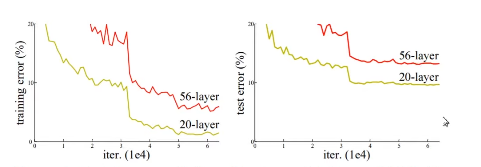
: vanishing gradients 문제
: overfitting
-
잔여학습 특징
: 깊게 레이어를 쌓았을 때 벌어지는 문제 해결
: 잔여 학습을 통해서 기존의 CNN의 문제였던 레이어가 증가시 성능 저하 문제를 해결함
: 깊은 네트워크 학습이 가능하여 좋은 성능을 보임(Conv 레이어를 더 깊게 쌓게됨)
: 학습하기 쉬운 잔여 매핑 이용 , F(x) + x
--> 추가 복잡도 와 추가 파라미터가 없다
ResNet
: 학습 난이도가 쉬어짐
: 깊이가 깊어지면 깊어질 수록 정확성이 높아짐
: CIFAR-10 , ImageNet에도 좋은 효과를 보임
: 앙상블 기법까지 적용하면 정확성이 더 좋아짐.
Related Work
- Residual Representations
- Shortcut Connections
Deep Residual learning
- Residual Learning
: identity mappings 최적화를 통해서 학습 난이도를 낮춤.
: Residual function 이 zero에 가까운 것 보다 identiy mapping과 가까울 때 좋은 방향성 제시. 잔여 x를 보존하고 필요 정보 재학습.
- Identity Mapping by Shortcuts
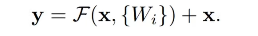
- x : shortcut conncetion
-
bias: 고려 X
-
추가 파라미터 추가 안함
-
input dimension != output dimension
-> Ws를 linear projection한다.
- Network Architectures
-
Plain Network
: VGG Networks이용
: 3 * 3 filters
: use same filters -> same output feature map size
: feature map is halved -> double filter size
: downsamplig을 conv layers에서 바로 실행
: FLOPs 감소
- Implementation
-
ImageNet
: 224 * 224 crop가 랜덤하게 샘플됨
: horizontal flip 사용
-
ResNet
: Conv 거칠 때 마다 batch 정규화 실행
-
learning rate
: 점진적으로 줄여나감
-
하이퍼파라미터 설정
: weight = 0.0001
: momentum = 0.9
Experiments
-
ImageNet Classification
: 1000 classes, 1.28 million training images, 50k validation images
-
Plain Networks
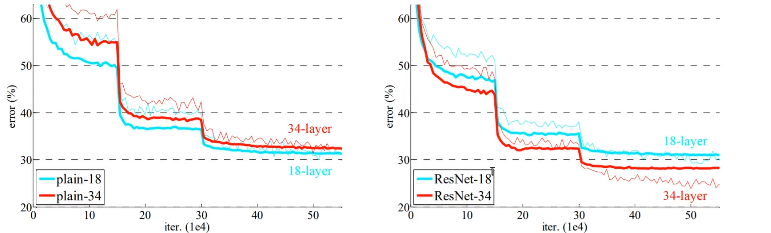
<발생 원인>
: forward or backward signals vanish -> vanishing gradients가 아님
: 기하급수적으로 수렴율이 낮아짐
- Residual Networks
: training error 감소
: 일반화 성능 향상
- shortcuts
: identity mapping or projections를 사용할지에 대해 성능 차이 알림

A) identity mapping
: zero - padding -> increase dimensions
B) increase dimensions -> projection
C) 시작부터 projection
: bottleneck architectures의 복잡도를 증가시키지 않음
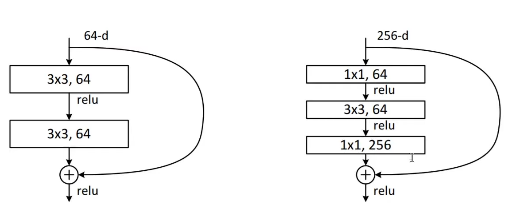
- Deeper Bottleneck Architectures
: 성능은 좋아짐
: bottleneck architectures의 복잡도를 증가시키지 않음 (by indentity shortcuts)
- CIFAR - 10
: 파라미터 수를 줄여서 resdual 구현
: fully-connected -> 6n+2 layer

코드로 실습
MNIST
https://github.com/qsdcfd/study-37/blob/main/ResNet18_MNIST_Train.ipynb
CIFAR-10
https://github.com/qsdcfd/study-37/blob/main/ResNet18_CIFAR10_Train.ipynb
ImageNet
https://github.com/qsdcfd/study-37/blob/main/Pretrained_ResNet18_ImageNet_Test.ipynb
