TX-ray
Background
지도학습 평가 기법 문제
-
오직 예상되는 모델 지식과 의미론(영문학적)만 측정한다
-
모델과 조사 영역이 일치하지 않을 때 mislead
-
주석처리는 예상하지 못한 의미를 발견하지 못한다.
Goal
어떻게 모델들이 탐사하고 측량하는지 보도록 하기
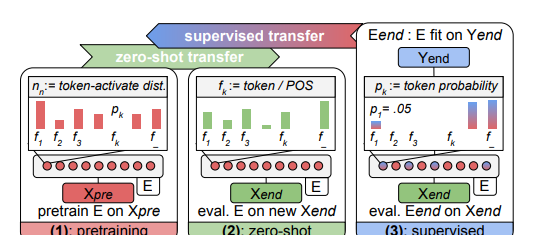
-
learns: How does self-supervision abstract/learn knowledge?
- during initial/pretraining on ext Xpre
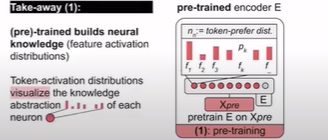
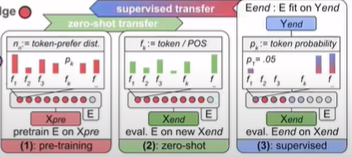
임의로 인코더를 사용하여 언어 모델 사전 훈련에 데이터 공급하면 손실이 감소되지만 입력 레코드의 각 토큰에대해 최대 활성화가 가능하게 되어서 선호하는 기능을 가진 각 뉴런에 기본적인 활성화 기록을 남길 수 있습니다.

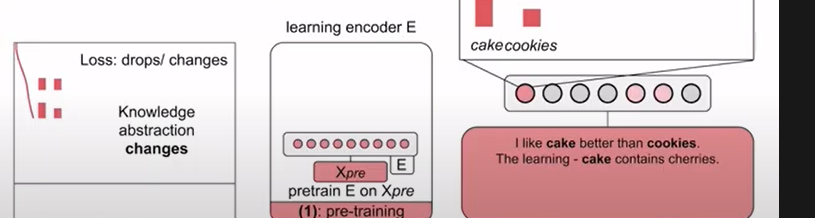
아래와 같이 토큰 선호도 분포의 형태로 손실 및 모델 표현이 가능하게 되어 뉴런의 기능에 대해 활성화를 많이 얻을 수 있습니다.

그 후, 평균을 내어 빈도 분포와 정규화를 통해 확률 분포를
- applies: How is knowledge (Zero-shot) applied to new inputs X?
각 뉴런의 활성화선호가 사전 훈련된 것과 유사한지 알 수 있다.
이는, 사전 훈련에서 새로운 말뭉치로 transfer된 뉴런에 대한 지식이라는 것을 알려주고 차이가 있을 시 그것에 대해 수량화하고 측정할 수 있습니다.
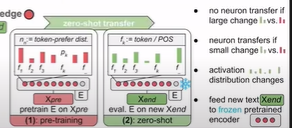
거리의 헬링 기법을 사용하여 수치화가 가능합니다.
*제거 할 수 있는 것
-
이전할 수 있는 지식 가짐
-
동일한 활성화 패턴을 갖는 뉴런에 대한 일반화
- Condition?: 사전 훈련 및 새로운 말뭉치에 관해
-
adapts: How is knowledge adapted by supervision?(tx-ray이용)
지도학습 신호가 함수(f)에 어떻게 사용되는지입니다. 왜냐하면, 사전 훈련된 인코더를 조정하여 지식을 변경하면 특정 뉴런이 전문화되거나 수정이 되기도 하고 더 나아가 knowledge추가되기도 합니다.
추가되는 경우는, 사전 훈련 중 일부 뉴런이 선호되지 않았기에 새로운 뉴런이 추가되는 것입니다.
재미나게도, 사전 훈련 하지 않을 것을 선호하고 그 중 대부분의 뉴런은 지도학습에 의해 미세조정이 되지 않은 것입니다.
즉, 오래된 지식이 많게 조정되거나 비활성화된 것과 같습니다.

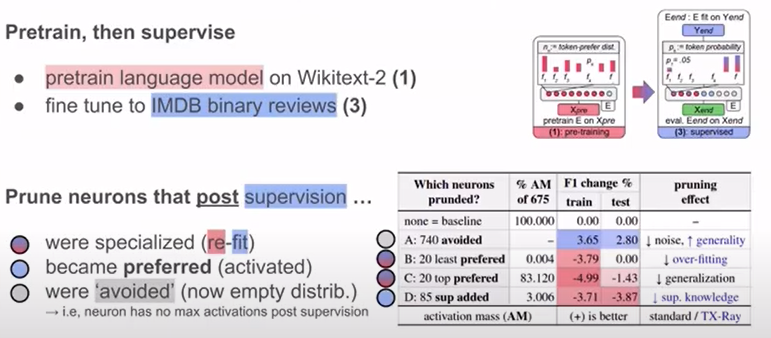
Experiment: XAI to guide pruning
-
도메인에서 언어 모델을 사전 훈련
-
뉴런의 절반 제거(avoid or non-preferences)
-
노이즈 제거
-
실험c
- 일반성 증가: 가장 활동적인 선호 뉴런 갖고 prun하면 일반화 능력 손실
-
실험d
- 뉴런 제거: 지도학습 도중 추가된 뉴런, 성능 저하
-
훈련 data
- important knowledge
- 뉴런의 중요도로 분해 가능
Take-Aways
- 각자의 뉴런에서 일반화 및 전문화 사용 가능


