XML(eXtensible Markup Language)
계층 구조로 이루어져있고 HTML과 비슷하지만 원하는 이름의 태그를 만들 수 있다는 특징이 있고, HTML보다 문법 오류를 더 엄격하게 다룹니다.
-
Tags: 요소의 시작과 끝을 나타냄
-
Attributes: 키워드나 값의 짝을 XML시작 태그에 표시
-
Serialize/De-Serialize: 데이터 전송, 저장 및 변환

<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes" />
</person>- 공백을 신경쓰지 않으나 텍스트 영역에선 중요
*계층구조
-
들여쓰기가 핵심
-
자식노드 부모노드가 있다
-
자식노드를 태그로 갖는 부분도 있다.

코드로 정리
import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print('User count:', len(lst))
for item in lst:
print('Name', item.find('name').text)
print('Id', item.find('id').text)
print('Attribute', item.get("x"))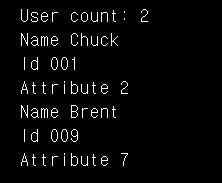
XML 스키마

다음과 같은 함수를 활용하면 XML에 접근해 원하는 데이터를 추출할 수 있습니다.
import xml.etree.ElementTree as ET
data = '''<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>'''
tree = ET.fromstring(data)
print('Name:',tree.find('name').text)
print('Attr:',tree.find('email').get('hide'))
# Name: Chuck
# Attr: yes조금 더 복잡하지만 XML의 구조를 이해하고 있으면 다음과 같이 반복문을 활용해 XML의 데이터에 접근할 수도 있습니다.
import xml.etree.ElementTree as ET
input = '''<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print('User count:', len(lst))
for item in lst:
print('Name', item.find('name').text)
print('Id', item.find('id').text)
print('Attribute', item.get("x"))
#User count: 2
#Name Chuck
#Id 001
#Attribute 2
#Name Brent
#Id 009
#Attribute 7
성장을 도울 아카이빙 블로그