딕셔너리와 집합
공통적인 매핑 메서드
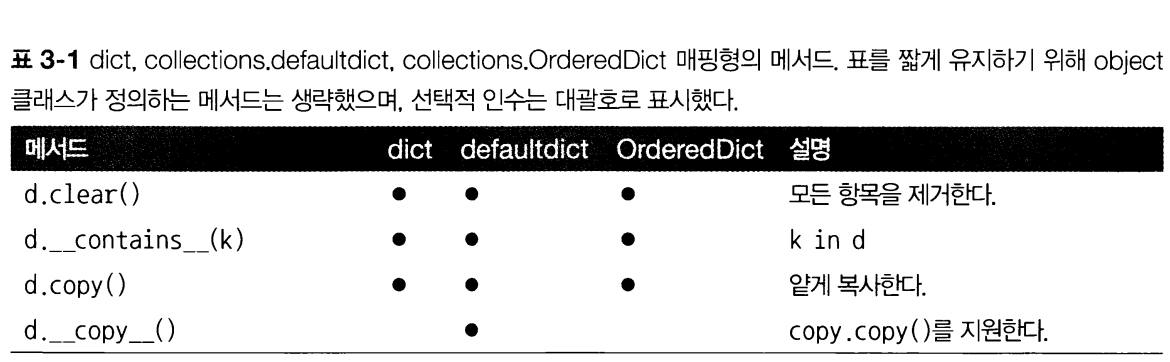
매핑이 제공하는 기본 API는 정말 많고, dict와 dict의 변형 중 가장 널리 사용되는 것은 defaultdict와 OrderedDict 클래스가 구현하는 메서드를 보여준다.

update() 메서드가 첫 번째 인수 m을 다루는 방식은 덕 타이핑의 대표적인 사례로 m이 keys() 메서드를 갖고 있는지 확인 후, 만약 메서드를 갖고 있으면 매핑이라고 간주됩니다.
그러므로, keys() 메서드가 없으면 update() 메서드는 m의 항목들이(키,값) 쌍으로 되어 있다고 간주하여 m을 반복합니다.
대부분의 파이썬 매핑은 update() 메서드와 같은 논리를 내부적으로 구현하므로 다른 매핑으로 초기화하거나 (키,값) 쌍을 생성할 수 있는 반복형 객체로 초기화할 수 있다.
매핑의 setdefault() 메서드는 늘 필요한 것은 아니고, 똑같은 키를 여러 번 조회하지 않게 해줌으로 속도를 엄청 향상시킵니다.
존재하지 않는 키를 setdefault() 처리하기
조기 실패 철할에 따라서, 존재하지 않는 키 k로 d[k]를 접근하면 dict 오류를 발생하기에 KeyError를 처리하는 것보단 기본값을 사용하는 것이 더 편리한 경우엔 d[k] 대신 d.get(k,default)를 사용한다.
허나, 발견한 값을 갱신 시 해당 객체가 가변 객체면 getitem()이나 get()메서드는 가독성과 효율성이 떨어진다.
#dict.get() 안 좋은 사례
"""단어가 나타나는 위치를 가리키는 인덱스를 만든다."""
import sys
import re
WORD_Re = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as.fp:
for line_no, line in enumerate(fp,1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
#보기 좋은 코드는 아니지만 설명
occurrences = index. get(word,[])
occurences.append(location)
index[word] = occurrences
for word in sorted(index, key=str.upper):
print(word, index[word])#dict.setdefault()사용
"""단어가 나타나는 위치를 가리키는 인덱스를 만든다."""
import sys
import re
WORD_Re = re.compile(r'\w+')
index = {}
with oepn(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp,1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index.setdefault(word,[]).append(loaction)
for word in sorted(index, key=str.upper):
print(word, index[word])
my_dict.setfault(key, []).append(new_value)
if key not in my_dict():
my_dict[key] = []
my_dict[key].append(new_value)x
성장을 도울 아카이빙 블로그