텍스트와 바이트
기본 인코더/디코더
텍스트를 바이트로 혹은 바이트를 텍스트로 변환하기 위해 파이썬 배포본에는 100여 개의 코덱(인코더/디코더)이 포함되어 있다. 코텍은 open(), str.encode(), bytes.encode() 등의 함수를 호출할 때 encoding인수에 전달해서 사용할 수 있다.
#전혀 다른 바이트 시퀀스를 만드는 세 개의 코덱으로 인코딩한 문자열
for codec in ['latin_1', 'utf_8', 'utf_16']:
print(codec, 'El Nino'.encode(codec), sep='\t')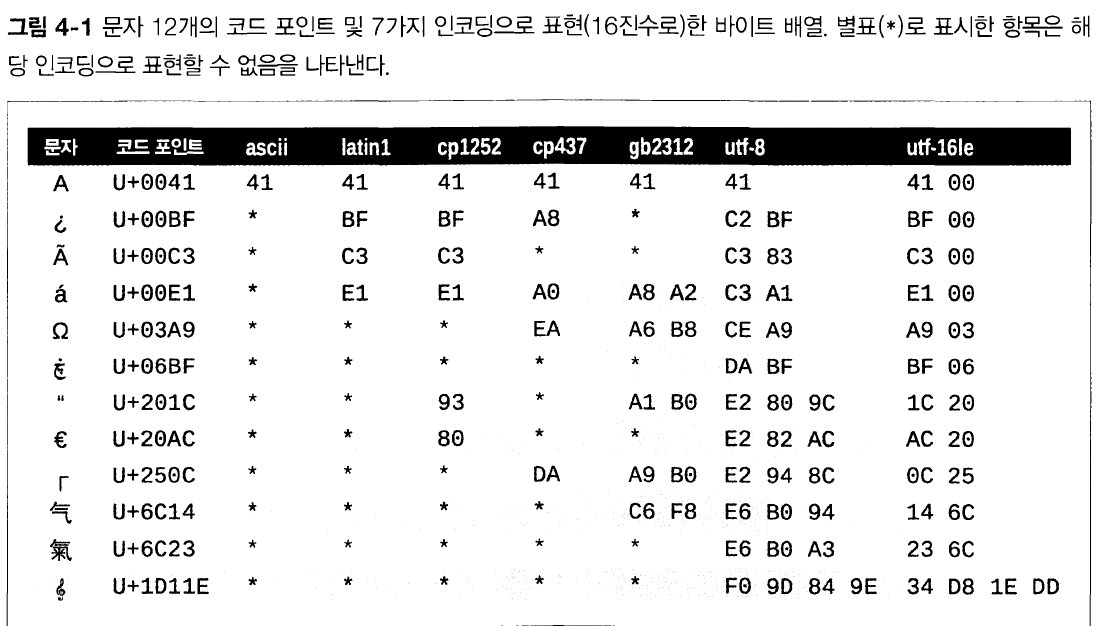
latin1(iso8859_1)
cp1252와 같은 다른 인코딩 방식 및 유니코드 자체의 기반이 되는 중요한 인코딩 방식이다.
cp1252
마이크로소프트에서 둥근 따옴표 및 유로화 기호등을 추가해서 latin1을 확장하는 것이다.
cp437
상자를 그리기 위한 문자를 포함해서 IBM PC에서 사용하는 문자셋이고 나중에 등장한 latin1과 호환되지 않는다.
gb2312
중국 본토에서 사용하는 간체를 인코딩하기 위한 레거시 표준이고, 아시아 언어를 위해 널리 사용되던 다중바이트 인코딩 방식 중 하나다.
utf-8
웹에서 8비트 인코딩을 하기 위해서 가장 널리 사용되는 인코딩 방식으로, 아스키코드와 하위 호환된다.
utf-16le
16비트 인코딩 체게인 UTF-16의 한 형태다.

성장을 도울 아카이빙 블로그