학습 목표
- 데이터 분석을 위해 판다스의 데이터프레임과 시리즈를 이해하며 실습해 봅니다.
핵심 키워드
-
DataFrame, Series
-
read_csv
-
shape, index, columns, values, dtypes
-
df.info(), df.describe()
-
df.isnull().sum(), df.isnull().mean()
-
df["열"]
-
df.loc["행"], df.loc["행", "열"]
라이브러리 로드
# 데이터 분석을 위한 pandas 라이브러리
# 데이터 시각화를 위한 seaborn
import pandas as pd
import seaborn as sns
print(pd.__version__) # 1.3.5
print(sns.__version__) #0.11.2데이터셋 불러오기

- seaborn 데이터셋 위치 : https://github.com/mwaskom/seaborn-data
# df
sns.load_dataset("mpg") #seabron내장 데이터셋: 연비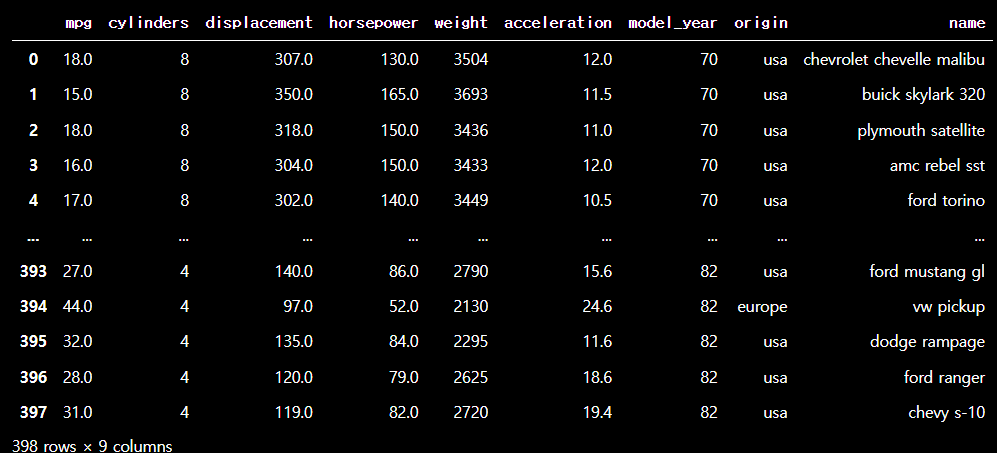
#pandas로 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/mpg.csv")
df.shape #(398,9)# index 값만 보기
df.index # RangeIndex(start=0, stop=398, step=1)# columns 값만 보기
df.columns
# 결과
Index(['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'model_year', 'origin', 'name'],
dtype='object')# values 값만 보기
df.values
# 데이터 타입만 보기
df.dtypes
데이터셋 일부만 가져오기
# head 을 통해 일부만 가져오기
df.head()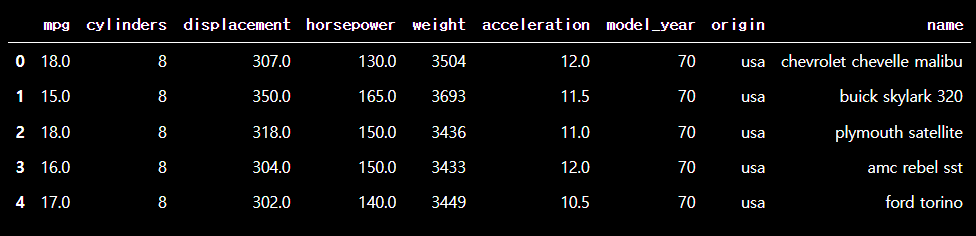
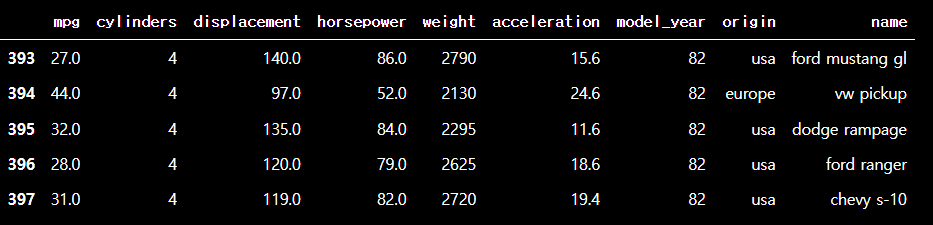
# tail 을 통해 일부만 가져오기
df.tail()
# sample을 통해 랜덤하게 일부만 가져오기
df.sample(3, random_state=42) #random_state 값을 고정 시키는 용도
요약하기
# info 를 통해 요약정보 보기
df.info()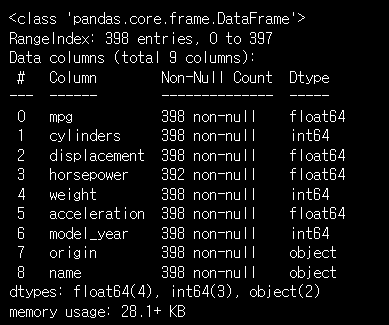
결측치 확인
# 결측치 수 확인
#df.isna()가능
df.isnull().sum()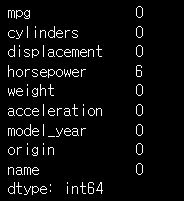
# 결측치 비율 확인
df.isnull().mean()
기술통계
# describe 로 기술통계 확인하기
df.describe()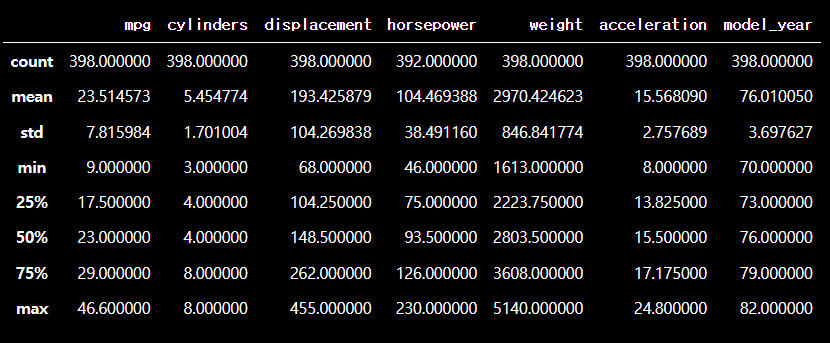
df.describe(include ="object")
Series(대괄호1개)
df["mpg"]
type(df["mpg"]) #pandas.core.series.Seriesdf["name"]
DataFrame(대괄호2개)
df[["origin", "name"]] #여러 개의 컬럼을 가져올 때 대괄호로 묶어서 가져오기
loc
-
행(index) 인덱싱
-
.loc[행]
-
.loc[행, 열]
-
.loc[조건식, 열]
# loc 로 하나의 행을 가져옵니다.
df.loc[0]#첫 번째
# loc로 2개의 행을 가져와 봅니다.
df.loc[[0,1]]# loc로 행, 열을 가져와 봅니다.
df.loc[0,"name"] # 'chevrolet chevelle malibu'# loc로 여러개의 행, 열을 가져와 봅니다.
df.loc[[0,1], ["name", "origin"]]
정리
-
import로 데이터 라이브러리 부르기
-
데이터 로드를 통해 데이터셋 불러오기(by df, sns)
-
값만 보기
-
index: 인덱스값
-
columns: 행
-
values: 값
-
dypes: 유형
-
-
데이터 일부만 가져오기
- head(n) : 맨 위에서 n개
- tail(n) : 맨 끝에서 n개
-
데이터 요약하기
-
info()
-
describe():지수 통계 값 알기
-
isnull(): 결측치 수 확인
-
-
Series
-
대괄호 1개
-
1차원
-
-
Dataframe
-
대괄호 2개
-
2차원
-
-
색인
-
열(column) 인덱싱
-
[컬럼]
-
[[컬럼1, 컬럼2, 컬럼3]]
-
-
loc
-
행(index)인덱싱
-
.loc[행]
-
.loc[행,열]
-
.loc[조건식, 열]
-

성장을 도울 아카이빙 블로그