회문 판별과 N-gram만들기
1) 회문 판별하기
회문: 순서를 거꾸로 읽어도 제대로 읽은 것과 같은 단어와 문장.
i) 첫 번째 글자= 마지막 글자
ii) 안쪽으로 한 글자씩 좁혔을 때 글자가 서로 같음.
2)반복문으로 문자 검사하기
word = input('단어를 입력하세요: ')
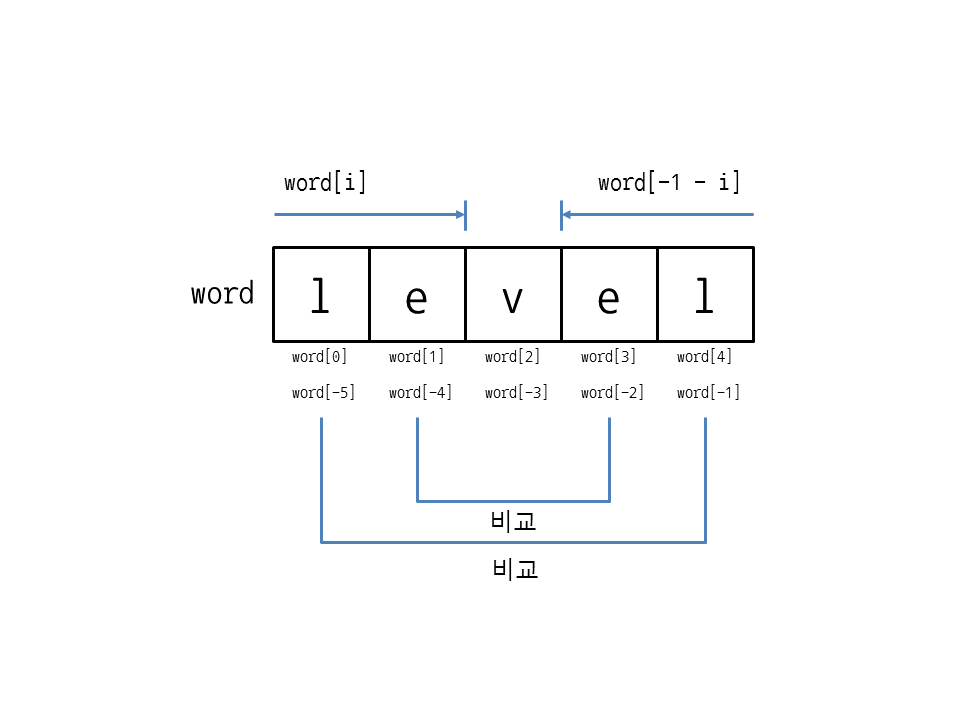
is_palindrome = True # 회문 판별값을 저장할 변수, 초깃값은 True
for i in range(len(word) // 2): # 0부터 문자열 길이의 절반만큼 반복
if word[i] != word[-1 - i]: # 왼쪽 문자와 오른쪽 문자를 비교하여 문자가 다르면
is_palindrome = False # 회문이 아님
break
print(is_palindrome) # 회문 판별값 출력
단어를 입력하세요: level (입력)
True
단어를 입력하세요: hello (입력)
Falsehttps://dojang.io/pluginfile.php/13770/mod_page/content/2/028002.png
{kind=link}
3)시퀀스 뒤집기로 문자 검사하기
word = input('단어를 입력하세요: ')
print(word == word[::-1]) # 원래 문자열과 반대로 뒤집은 문자열을 비교
단어를 입력하세요: level (입력)
True
단어를 입력하세요: hello (입력)
False4)리스트와 reversed 사용하기
>>> word = 'level'
>>> list(word) == list(reversed(word))
True5)문자열의 join메서드와 reversed사용하기
>>> word = 'level'
>>> word == ''.join(reversed(word))
True6) 반복문으로 N-gram출력
text = 'Hello'
for i in range(len(text) - 1): # 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복함
print(text[i], text[i + 1], sep='') # 현재 문자와 그다음 문자 출력
He
el
ll
lotext = 'this is python script'
words = text.split() # 공백을 기준으로 문자열을 분리하여 리스트로 만듦
for i in range(len(words) - 1): # 2-gram이므로 리스트의 마지막에서 요소 한 개 앞까지만 반복함
print(words[i], words[i + 1]) # 현재 문자열과 그다음 문자열 출력
this is
is python
python script7)zip으로 2-gram만들기
text = 'hello'
two_gram = zip(text, text[1:])
for i in two_gram:
print(i[0], i[1], sep='')8)zip과 리스트 표현식으로 N-gram만들기
>>> text = 'hello'
>>> [text[i:] for i in range(3)]
['hello', 'ello', 'llo']
>>> list(zip(* ['hello', 'ello', 'llo']))
[('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]
>>> list(zip(* [text[i:] for i in range(3)]))
[('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]N-gram의 활용
4-gram을 쓰면 picked, picks, picking에서 pick만 추출하여 단어의 빈도를 세는데 이용됩니다.
이런 특성 때문에 검색엔진, 빅데이터, 법언어학 분야에서 주로 활용됩니다.
with open('words.txt','r') as file:
for line in file:
words=line.split()
for word in words:
if list(word) == list(reversed(words)):
print(word.string('\n'))
성장을 도울 아카이빙 블로그