[웹 애플리케이션]
1. 네이티브 애플리케이션
- 특정 기기에서 설치해서 사용하는 애플리케이션(ex. 모바일용 애플리케이션)
- iOS, Android OS, Windows와 같은 특정 실행환경에 종속
2. 네이티브 애플리케이션 장점
- 웹 애플리케이션보다 빠름
- 애플리케이션이 설치된 기기의 시스템/기기의 리소스에 접근 용이
- 인터넷 없이 사용 가능
- 웹 애플리케이션에 비해 안전
3. 네이티브 애플리케이션 단점
- 웹 애플리케이션에 비해 개발비 ↑
- 빠른 업데이트가 힘듦
- 앱스토어에 승인이 받기 힘들고 비용이 발생
4. 웹 애플리케이션
- 웹 브라우저를 통해 접근이 가능한 애플리케이션
- 동적인 응답을 웹 브라우저라는 소프트웨어를 통해 가능하게 한 애플리케이션
5. 웹 애플리케이션 장점
- 브라우저를 통해 실행되기 떄문에 설치나 다운로드 필요 X
- 업데이트 등의 유지관리에 용이
- 네이티브 애플리케이션에 비해 제작이 간편
- 애플리케이션 스토어 승인 필요 X
6. 웹 애플리케이션 단점
- 인터넷이 없으면 사용 불가
- 네이티브 애플리케이션에 비해 속도 ↓
- 애플리케이션 스토어에서 관리되지 않기 때문에 사용자 접근성 ↓
- 보안상 위험에 노출되기 쉬움
[TCP/IP]
1. LAN과 WAN
- LAN(Local Area Network) : 좁은 범위에서 연결된 네트워크
- WAN(Wide Area Network) : 수많은 LAN이 모여 구성된 네트워크
2. 인터네트워킹
- 여러 네트워크를 연결하는 것
- 장점
- 네트워크의 일부에서 고장이 나도 영향이 광범위하게 퍼지지 않음
- 불필요한 통신이 네트워크 전체로 확산하지 않음
- 개별 네트워크를 각각의 방침에 따라 관리 가능
3. 프로토콜
- 인터넷에 연결되어 있는 멀리 떨어진 컴퓨터끼리 서로 소통하기 위한 약속
- 즉, 어떤 컴퓨터든 일관되게 네트워크를 사용할 수 있게 하는 공통 언어를 의미
4. TCP/IP
- 인터넷 통신 스위트 : 인터넷에서 컴퓨터들이 서로 정보를 주고받는데 쓰이는 통신규약의 모음(다른 컴퓨터/운영체제/회선 간 통신이 가능하게 함)
- 인터넷이 처음 시작되던 시기에 정의돼, 현재까지 표준으로 사용하는 TCP(Transmission Control Protocol)와 IP(Internet Protocol)에서 가져와 TCP/IP라고 부름
- TCP/IP 4계층 모델
4층(응용 계층) : 애플리케이션에 맞추어 통신(HTTP, DNS, FTP, ...)
3층(전송 계층) : IP와 애플리케이션을 중개해 데이터를 확실하게 전달(TCP, UDP, ...)
2층(인터넷 계층) : 네트워크 주소를 기반으로 데이터를 전송(IP, ICMP, ARP, RARP, ...)
1층(네트워크 접근 계층) : 컴퓨터를 물리적으로 네트워크에 연결해 기기 간에 전송이 가능하게 함(Ethernet, wifi, ...)
- TCP/IP 4계층 모델
5. 주소
- IP Address(IP 주소) : 네트워크에 연결된 특정 PC의 주소를 나타내는 체계
- IP 주소에는 private 주소와 public 주소가 존재
- Private IP 주소 : LAN 네트워크 내부에서 사용되는 주소
- Public IP 주소 : 인터넷에서 사용되는 주소
- IP
Internet Protocol의 줄임말로, 인터넷 상에서 사용하는 주소체계를 의미
인터넷에 연결된 모든 PC는 IP 주소체계를 따라 네 덩이의 숫자로 구분
네 덩이의 숫자로 구분된 IP주소 체계를 IPv4(Internet Protocol version 4)라고함
- IP
- MAC 주소 : 네트워크 기기에 제조사가 할당한 고유 시리얼
- IP 주소 + MAC 주소를 조합해야만 네트워크를 위한 통신이 가능
- 이더넷에서는, 네트워크상의 송수신 상대를 특정하고자 MAC 주소를 사용하고, TCP/IP에서는 IP Address를 사용하기 때문
- 같은 LAN에 속한 기기끼리는 통신 할 때, 우선 상대방의 MAC 주소를 파악
- 이때 사용하는 것이 ARP(Address Response Protocol)
- ARP : MAC 주소를 파악하기 위해 네트워크 전체에 브로드캐스트를 통해 패킷을 보내고, 해당 IP를 가지고 있는 컴퓨터가 자신의 MAC 주소를 Response하게 되면서 통신을 하게 해주는 프로토콜
- 패킷 : 헤더와 페이로드로 구성되어 있고, 어떤 데이터의 몇 번째인지의 정보와 보내는 곳, 최종 목적지에 대한 정보가 들어있는 데이터 조각
- 기기끼리의 통신에는 회선 교환 방식(Circuit Switching)과 패킷 교환 방식(Packet Switching)이 존재
- 통신 회선 교환 방식은 일대일로만 데이터 교환이 가능하기 때문에, 주로 음성전화 시스템에 사용
- 컴퓨터 네트워크는 여러 상대와 통신이 가능해야 하기 때문에, 패킷 교환 방식을 사용
- 패킷 교환 방식 : 원본 데이터를 패킷이라는 작은 단위로 나눈 후, 여러 회선을 공용해 통신을 주고 받음(데이터를 작게 분할해도, 목적지에서 원래대로 복원 가능)
[IP]
1. IP 주소 구조
- IPv4 주소는 OOO.OOO.OOO.OOO의 형식으로 이루어져 있음
- 4개의 8비트 필드로 구성
- 각 8비트 필드는 IPv4 주소에서 1byte를 나타냄
- IP주소는 네트워크부와 호스트부로 나뉘며, 네트워크부는 어떤 네트워크인지를 알 수 있는 정보이고, 호스트부는 그 네트워크 내의 특정 컴퓨터를 지칭하는 정보
- 서브넷 마스크 : IPv4 주소에서 네트워크가 어디까지인지 나타내는 것
- 옥텟 : 8자리의 2진수 묶음(IPv4주소는 4개의 옥텟으로 이루어져 있음)
2. IP주소의 할당/관리
- IP주소는 호스트부를 변경해가며 IP 할당이 이루어짐
- 시작(0)과 끝(255)를 제외한 254개의 주소를 할당 가능
3. IP프로토콜의 한계
- 비연결성 : 패킷을 받을 대상이 없거나, 특정한 이유로 서비스 불능에 빠져도 데이터를 받을 상대의 상태 파악이 불가해 패킷을 그대로 전송
- 비신뢰성 : 중간에 패킷이 사라지더라도 보내는 기기 측에서는 알 수 없으며, 서로 다른 노드를 거쳐 전송되기 때문에 보내는 기기 측이 의도한 순서대로 데이터가 도착하지 않을 수 있음
- 위와 같은 한계 극복을 위해 TCP와 UDP를 사용
[TCP/UDP]
- TCP/IP 4계층 모델을 기준으로 인터넷 계층의 상위에서 동작
- 2계층에서 동작하는 IP와 4계층에서 동작하는 애플리케이션을 중개하는 역할 수행
1. TCP 특징
- 서비스 타입 : 연결 지향적 프로토콜
- 신뢰성 : 데이터 전송 표적 기기까지의 전송 보장
- 순서 보장 : 전송하는 패킷들이 순서가 보장됨
- 속도 : UDP에 비해 ↓
2. UDP 특징
- 서비스 타입 : 데이터그램 지향적 프로토콜
- 신뢰성 : 표적 기기까지의 전송 보장 X
- 순서 보장 : 패킷 순서 보장 X, 패킷 순서 보장을 원할 경우 애플리케이션 레이어에서 관리
- 속도 : TCP에 비해 단순하며, 속도 ↑
3. TCP 3-way Handshake
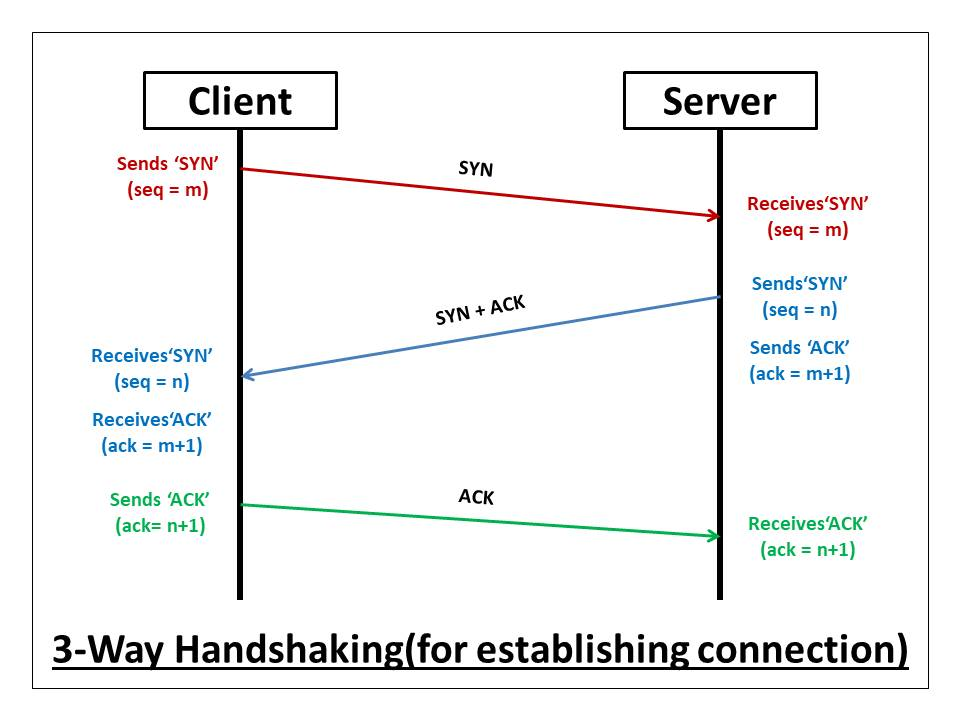
- 데이터의 온전성과, 통신기능의 원활한 사용을 위한 통신 프로토콜을 위해 TCP/IP를 완성
- TCP 3-way Handshake : 양 끝단의 기기에 신뢰성 있는 데이터 통신을 위해, TCP 방식이 연결을 설정하는 방식
- 연결 설정 단계
- SYN : sender는 receiver와 연결 설정을 위해, segment를 랜덤으로 설정된 SYN(Synchronize Sequence Number)와 함께 전송(receiver에게 sender가 통신을 시작하고 싶다고 알림)
- SYN/ACK : receiver는 받은 요청을 바탕으로 SYN/ACK 신호 세트를 응답. ACK(Acknowledgement) 응답으로 보내는 segement가 유효한 SYN 요청을 받았는지를 의미
- ACK : sender는 받은 ACK를 receiver에게 전송하면서 신뢰성 있는 연결이 성립되었다는 사실을 sender와 receiver 양쪽에서 알 수 있고, 실제 데이터 전송 시작
4. UDP
- 실시간 전송 등을 사용하는 경우, TCP 사용 시 지연시간 등의 한계 발생
- UDP는 애플리케이션의 정교한 제어가 가능
- TCP의 경우 receiver가 전송받을 준비가 될 때까지 세그먼트를 반복적으로 재전송
- 실시간 전송에 대한 요구가 큰 애플리케이션의 경우, 높은 latency를 지양하므로 약간의 데이터 손실을 감수
- 대신 개발자가 이를 보완하기 위해 애플리케이션에 추가 기능 구현 가능
- UDP는 연결 설정에 무관함
- UDP는 예비과정 없이 바로 전송을 시작
- 설정 단계에 발생하는 지연이 없는 만큼, 반응속도 ↑
- TCP가 신뢰성을 위해 많은 파라미터와 정보 전달이 필요함과 비교해 UDP는 연결설정 관리를 하지 않아 어떠한 파라미터도 기록 X
- 이 떄문에, 서버에서도 TCP에 비해 더 많은 클라이언트 수용 가능
[PORT]
1. 포트번호
- 대상 IP 기기의 특정 애플리케이션을 특정하는 번호
- TCP와 UDP 모두 포트번호를 사용
- 한 서버에서, 웹 서버와 메일 서버를 동시에 실행 중일 때, IP주소만으로는 어느 서버로 요청을 보내는지 알 수 없음
- 이 때, 포트번호를 이용해 receiver를 특정해 목적지 서버를 특정 가능
- 사용 중인 포트는 중복해서 사용 X
- 포트 번호는 0 ~ 65,535까지 사용 가능하고, 0 ~ 1023번 까지의 포트 번호는 주요 통신을 위한 규약에 의해 이미 규정되어 있음
- 잘 알려진 포트번호(80,443,110,53 등)의 경우 URI에 명시하지 않지만, 잘 알려지지 않은 포트(8080과 같은 임시 포트)는 반드시 포함해야 함
[URL/DNS]
1. URL
- 웹에 게시된 어떤 자원을 찾기 위해 브라우저에서 사용되는 매커니즘
- 인터넷상에서 HTML이나 이미지 등 리소스의 위치를 특정하기 위한 서식으로서 탄생
- 서버가 제공되는 환경에 존재하는 파일의 위치를 나타냄
- 슬래시(/)를 이용해 서버의 폴더에 접근하거나 파일 요청 가능
- Uniform Resource Locator의 줄임말로, 네트워크 상에서 이미지, 웹 페이지, 동영상 등의 파일이 위치한 정보를 나타냄
- scheme, hosts, url-path로 구분
- scheme : 통신 방식(프로토콜)을 결정(일반적으로 http(s)를 사용)
- hosts : 웹 서버의 이름이나 도메인, IP를 사용하며 주소를 나타냄
- url-path : 웹 서버에서 지정한 루트 디렉토리부터 시작해 웹 페이지, 이미지, 동영상 등이 위치한 경로와 파일명을 나타냄
2. URI
- Uniform Resource Identifier의 줄임말로, URL의 기본요소 + query, bookmark를 포함
- query : 웹 서버에 보내는 추가적인 질문
- 즉, 검색창을 클릭하면 나오는 주소가 URI이며, URI는 URL을 포함하는 상위 개념
3. Domain name
- 호스트 이름을 기억하기 쉬운 이름으로 사용하는 것
- ICANN이라는 단체에서 약 4억 개의 도메인을 관리
- gTLD(generic Top Level Domain) : 전 세계에서 등록이 가능한 .com/.net/.org/.edu/.gov/.int/.mil로 시작하여 .biz/.name/.info 등이 추가
- ccTLD(country code Top Level Domain) : .kr/.us/.jp 등 각국 네트워크 정보센터에서 위임받아 관리
4. DNS(Domain Name System)
- 도메인 이름을 입력하여 해당 사이트로 이동하기 위해, 해당 도메인 이름과 매칭된 IP 주소를 확인하는 작업 필요
- 호스트의 도메인 이름을 IP주소로 변환하거나 반대의 경우를 수행할 수 있도록 개발된 데이터베이스 시스템
- 도메인을 컴퓨터가 이해하기 쉬운 IP주소로 변환하여, 요청이 원하는 곳에 도달할 수 있도록 도와주는 시스템
- 도메인 요소 구성
도메인 주소는 오른쪽부터 탑레벨 도메인과 여러 개의 도메인으로 구성
- 탑 레벨 도메인 : 가장 오른쪽에 위치하는 도메인으로, .com/.kr/.net 등이나 .kr/.us 등을 의미(국가 코드의 경우, .co/.ac와 같은 2단계 도메인과 함께 사용되기도 함)
- 도메인 서버(존) : 모든 도메인을 관리하는 루트 네임 서버, TLD를 관리하는 네임 서버, 권한 있는 네임 서버로 구성
- 도메인 네임 서버는 하나의 서버로 구성되지 않으며, 안정성을 위해 최소 두 개 이상의 서버가 하나의 도메인 네임을 담당
- 루트 도메인 네임 서버 : 각 최상의 도메인 네임 서버들의 주소를 알고 있으며, 최상위 도메인 네임 서버는 권한 있는 네임 서버의 주소를 알고있음
- 권한 있는 네임 서버 : 도메인 IP 주소 및 도메인 정보를 관리하는 권한을 가진 서버
- 도메인 요소 구성
5. DNS Lookup
- URL에 주소 입력 시, DNS Lookup 과정 발생
- 브라우저가 리졸버에게 IP 주소 요청
- 리졸버 : 요청받는 도메인의 IP 주소를 찾기 위해 여러 네임 서버에 반복적인 질의를 하는 네임 서버
- 리졸버는 기존에 찾아본 도메인 정보가 담긴 캐시 파일을 살펴보고, 해당되는 도메인 정보가 있다면, 즉시 IP 주소를 리턴
- 해당되는 도메인 정보를 찾을 수 없는 경우, DNS 리졸버는 IP 주소를 얻기 위해 네임 서버들에게 재귀적인 쿼리를 진행
- 루트/탑 레벨/권한 있는 도메인 서버에 차례대로 쿼리를 진행해 IP 주소를 알아냄
- 리졸버는 전달받은 주소의 IP 주소를 기록하고 브라우저에게 전달
6. 존 파일
- 도메인 네임 서버는 응답을 보내기 위해 한 개 이상의 존 파일을 보유
- 존 파일은 네임과 클래스, TTL, 레코드 타입, 레코드 데이터로 구성된 레코드들로 구성
- 네임 서버들은 존 파일들을 바탕으로 요청에 해당되는 레코드 리턴
- 리졸버는 이 레코드를 살펴보고 리턴해야 할 IP, 혹은 다음에 쿼리를 진행할 서버의 주소 확인
- 네임 : 도메인 네임 혹은 서브 도메인의 이름 저장
- 레코드 클래스 : 네트워크 타입 지정(일반적으로 인터넷으로 지정됨)
- TTL(Time To Live) : 리졸버가 레코드를 몇 초 동안 저장할지 명시
- 레코드 타입 : 반환될 데이터의 형식
- 레코드 데이터 : 반환되는 데이터
[웹 구성 기술]
1. 웹(WEB)
- 인터넷에서 제공되는 하이퍼텍스트 시스템
- 하이퍼텍스트
문서 안에 다른 문서의 위치정보 등을 포함하여 문서 간의 정보를 서로 연관 지어 참조할 수 있는 문서
- 하이퍼텍스트
- 정보 공유 수단으로써 고안된 하이퍼텍스트는 운영체제나 애플리케이션에 상관없이 일정한 형식으로 출력하지 못한다는 문제점을 해결하기 위한 개념이 필요
- 운영체제나 애플리케이션이 달라도 브라우저만 있으면 모두가 동일한 정보를 볼 수 있는 HTML을 제안
- HTML로 대표되는 하이퍼텍스트와 인터넷이 융합된 개념이 웹
- 최초의 웹은 문자정보 전달에만 초점이 맞춰져 있었지만, 기술의 발전으로 현재 동영상, 전자상거래, SNS 등에 활용
2. 클라이언트-서버 아키텍처(=2티어 아키텍처)
- 클라이언트(서비스 이용자)와 서버(서비스 제공자)로 구분되는 웹에서 제공되는 서비스
- 클라이언트는 사용자가 직접 이용하는 요소이기 때문에, 사용 편의성 및 휴대성을 고려하여 개발
- 서버는 유지보수 시점을 제외하고 항상 작동되어야 하며, 사용자와의 직접적 접점이 없기 때문에 기능에 중점을 두어 개발
- 리소스가 존재하는 곳과 리소스를 사용하는 곳을 분리한 것을 2티어 아키텍처라고 함
- 즉, 클라이언트와 서버는 요청과 응답을 주고받는 관계(요청이 없는 응답은 존재 X)
- 리소스를 저장하는 별도의 공간을 데이터베이스라고 하며, 2티어 아키텍처에 데이터베이스가 추가된 형태를 3티어 아키텍처라고 함
- 클라이언트는 플랫폼에 따라 구분되며, 브라우저를 통해 주로 이용하는 웹 플랫폼에서의 클라이언트를 웹 사이트/웹 앱이라고 부름(+ 데스크탑 플랫폼 및 스마트폰/태블릿 플랫폼에서 이용하는 앱)
- 서버는 정보를 제공하는 앱, 파일을 제공하는 앱, 메일을 주고받을 수 있도록 도와주는 앱 등으로, 무엇을 하느냐에 따라 종류가 달라짐
3. 웹 애플리케이션 아키텍처
- 웹 애플리케이션 특징
- 데스크톱 애플리케이션 처럼 상호작용이 가능
- 특정 기능을 가짐(ex. 정보 검색)
- 정보나 자료 등의 콘텐츠 관리 시스템과 함께 작동
- 웹 개발 영역에서 웹 사이트는 정적 페이지의 집합체를 의미
- 정적 페이지 뿐만 아니라 동적 페이지를 포함하는 것이 웹 애플리케이션
- 웹 애플리케이션 아키텍처는 애플리케이션 내부의 요소들이 어떻게 상호 간에 소통하는지 설명
- 즉, 유저가 웹 브라우저에 요청 전달 시, 애플리케이션의 다양한 요소들이 상호작용을 유지할 수 있도록 서로 결부시키는 뼈대
4. 웹 애플리케이션의 요청 흐름
- 브라우저에 URL 입력
- 브라우저는 URL을 입력받으면, 서버 주소를 찾기 위해 DNS 서버에 요청 전송
- IP 주소를 찾으면, 해당 주소에 HTTPS 요청을 보냄(이미 캐시 메모리에 방문 기록이 있으면, 주소를 캐시 메모리에서 가져옴)
- 웹 서버에 요청 도착
- 웹 서버는 저장소에 요청을 보내 페이지 관련 데이터를 가져옴
- 정보들은 가져오는 중 비즈니스 로직이 작용(요청받은 데이터를 어떻게 다룰지 정해져 있음)
- 로직들을 통해 요청받은 데이터들이 처리되며, 브라우저에 응답
- 요청들이 브라우저에 응답으로 돌아오면, 웹 페이지 화면에서 출력
모든 애플리케이션은 client-side와 server-side로 작동
- client-side : 유저에 입력에 따라 브라우저에서 작동하는 프로그램
- server-side : HTTP 요청에 따라 서버에서 요청 처리하는 프로그램
5. 웹 애플리케이션의 요소
- 웹 애플리케이션은 다양한 요소로 이루어지며, 크게 두 가지 영역의 컴포넌트로 나눌 수 있음
- 유저 인터페이스 요소
- 유저 인터페이스와 유저 경험과 관련된 요소
- 화면 출력, 로그, 알림, 시스템 통계, 환경 설정 등 웹 애플리케이션의 기능적 부분 외 적인 요소
- 구조 요소
- 웹 애플리케이션의 기능적 부분을 담당
- 유저와의 상호작용, 제어, 데이터베이스 등에 관련한 요소
- 웹 브라우저, 클라이언트, 웹 애플리케이션 서버, 데이터베이스로 이루어져 있음
6. 웹 애플리케이션의 3단계 계층 구조(Web Application 3-Tier Architecture)
- 웹 애플리케이션은 크게 3단계로 나누어 볼 수 있음
- Presentation Layer
- 유저와 브라우저 등을 이용해 직접적으로 접촉
- Web Server가 해당 영역에 포함되며, 유저 인터페이스 요소들을 포함
- Application Layer
- 유저의 요청을 브라우저로부터 받아 처리
- Application Server가 해당 계층에 포함되며, 데이터 접근을 위한 경로를 규격화하는 등의 과정이 해당 계층에 작성됨
- Data Access Layer
- 애플리케이션의 데이터 저장소에 접근해 데이터를 불러오거나 저장을 담당
- Application Layer와 밀접한 연관을 가지며, 이 단계를 통해 Application Layer의 로직들을 어느 데이터베이스에 접근해 데이터를 회수/저장할지를 최적화할 수 있음
7. 웹 애플리케이션 구현 방식
- Single Page Applicaiton
- 직관적으로 알기 쉽고 상호작용이 가능한 요소들을 이용해 유저 경험 극대화
- 유저의 입력과 요청에 의한 콘텐츠나 정보의 최신화가 페이지를 새로 불러오지 않고, 현재 페이지에서 이루어짐
- 필수적인 요소만을 요청하여 페이지가 새로고침되는 것을 방지해 유저 경험 극대화
- 즉, 유저는 페이지가 새로고침되지 않고, 요청한 응답을 기다리며 페이지와 상호작용 가능
- Microservice architecture
- 작고 가벼운 한 가지 기능에 집중한 웹 애플리케이션을 의미
- 각 애플리케이션의 기능 요소들은 상호 간에 의존적으로 설계되지 않음
- 즉, 개발 단계와 개발 완성 후에도 같은 개발 언어 사용을 하지 않아도 됨
- 원하는 언어를 사용해 기능 개발에 유연성을 갖고, 개발 과정의 전반적인 속도와 생산성 ↑
- Serverless Architecture
- 개발자가 웹 애플리케이션의 서버와 기타 기반 기능들에 대해 외부의 3자인 클라우드 서비스 제공자에게 의탁하는 방식
- 기본적인 서버나, 기반 기능에 걱정 없이 특정 기능 개발에 집중 가능
8. 웹 애플리케이션 구현 기술
- HTTP
- 웹 브라우저 상에서 클라이언트와 서버 간의 통신을 담당하는 프로토콜
- 데이터를 요청하고, 요청에 대한 응답을 전송하는 무상태성의 프로토콜
- 클라이언트에서의 데이터 요청과 서버에서의 요청에 대한 응답을 반복하며 웹 애플리케이션을 작동
- HTTP 요청 시, 하고 싶은 처리의 종류를 나타내는 메서드의 이름과 처리 대상의 이름이 포함
- HTTP 응답 시, 요청에 대한 처리 결과를 나타내는 상태 코드와 헤더, 실제 처리 결과인 메시지가 포함
- Cookie/Session
- 쿠키 : 웹 애플리케이션을 사용하는 유저의 정보를 클라이언트에 보관하고, 다음 접속부터 유저의 정보를 클라이언트가 서버로 보내 유저를 서버가 식별하게 함(유저가 웹 애플리케이션에 설정했던 항목들에 대해 저장해 다음에 이어서 같은 방식으로 작동하게 함)
- 세션 : 서버에 Session-Id라는 고유 아이디를 할당해 유저를 식별 함. 단순하고 유출이 되면 안되는 정보는 서버에서 관리하며 세션ID와 매칭해 저장/관리
- 세션 정보는 쿠키에서 관리하고, 실제 매칭되는 값들은 서버 측에서 관리하는 것이 일반적
- 사용자 인증
- 유저를 식별할 수 있는 ID값과 암호를 입력
- 제3자가 마음대로 컴퓨터나 시스템의 이용을 차단하기 위해 사용
- OTP, OAuth 등
9. SSR과 CSR
- SSR(Server Side Rendering)
- JavaScript가 웹 페이지를 브라우저에서 렌더링하는 대신, 서버에서 렌더링
- 브라우저가 서버의 URI로 GET 요청을 보내면, 서버는 정해진 웹 페이지 파일을 브라우저로 전송하고, 서버의 웹 페이지가 브라우저에 도착하면 완전히 렌더링됨
- 서버에서 웹 페이지를 브라우저로 보내기 전에, 서버에서 완전히 렌더링
- 브라우저가 다른 경로로 이동할 때마다 서버는 해당 작업을 다시 수행
- CSR(Client Side Rendering)
- 클라이언트 측에서 JavaScript가 페이지를 렌더링
- 브라우저의 요청을 서버로 보내면, 서버는 웹 페이지 대신 웹 페이지의 골격이 될 단일 페이지를 클라이언트에 전송(이때, 서버는 웹 페이지와 함께 JavaScrpit 파일을 전송)
- 클라이언트가 웹 페이지를 받으면, 웹 페이지와 함께 전달된 JavaScript 파일은 브라우저에서 웹 페이지를 완전히 렌더링된 페이지로 변경
- SSR은 서버에서 페이지를 렌더링하고, CSR은 클라이언트(브라우저)에서 페이지를 렌더링
- SSR 사용
- SEO(Search Engine Optimization)가 우선순위인 경우
- 웹 페이지의 첫 화면 렌더링이 빠르게 필요한 경우(단일 파일의 용량이 ↓)
- 웹 페이지가 사용자와 상호작용이 적은 경우
- SSR 단점
- 자원 이용이 서버에 집중되어 애플리케이션 유지비용 ↑
- 일부 서드파티 자바스크립트 라이브러리의 경우, SSR이 불가능할 수 있음
- CSR 사용
- SEO가 우선순위가 아닌 경우
- 사이트에 풍부한 상호작용이 있는 경우(빠른 라우팅)
- 웹 애플리케이션을 제작하는 경우
- CSR 단점
- 느린 렌더링 속도(모든 렌더링의 부하가 클라이언트에 집중)
- Search Engine Bots와 상성이 좋지 않음
10. CORS(Cross-Origin Resource Sharing)
- 브라우저가 자발적으로 브라우저의 애플리케이션을 사용하는 유저를 보호하기 위한 보안 정책
- 처음 전송되는 리소스의 도메인과 다른 도메인으로부터 리소스가 요청될 경우, 해당 리소스는 cross-orign HTTP 요청에 의해 요청됨
- PUT,DELETE,CONNECT,OPTIONS,TRACE,PATCH 등의 메서드를 사용해 요청을 보낼 경우, 특정 헤더가 아닌 경우, Content-Type이 특정 타입이 아닌 경우에 Preflight-Request가 실행됨
- Preflight Request는 OPTIONS 메서드가 먼저 날아간 뒤, 허용되면 실제 요청 메서드를 날림
[HTTP]
1. HTTP Messages
- 클라이언트와 서버 사이에서 데이터가 교환되는 방식
- 요청과 응답, 두 가지 유형으로 나뉨
2. HTTP Messages 구조
- start line
- 요청이나 응답의 상태를 나타냄
- 항상 첫 줄에 위치하며, 응답에서는 status line이라고 부름
- HTTP headers
- 요청을 지정하거나, 메시지에 포함된 본문을 설명하는 헤더의 집합
- empty line
- 헤더와 본문을 구분하는 빈 줄
- body
- 요청과 관련된 데이터나 응답과 관련된 데이터 또는 문서를 포함
- 요청과 응답의 유형에 따라 선택적으로 사용
3. 요청
- Start line
- 세 가지 요소 존재
1) 수행할 작업(GET, POST, PUT 등)이나 방식(HEAD, OPTIONS)을 설명하는 HTTP Method를 나타냄
2) 요청 대상(URI/URL) 또는 프로토콜, 포트, 도메인의 절대 경로는 요청 컨텍스트에 작성- origin 형식 : '?'와 쿼리 문자열이 붙는 절대 경로(POST, GET, HEAD, OPTIONS 등의 메서드와 함께 사용)
- absolute 형식 : 완전한 URL 형식으로, 프록시에 연결하는 경우 대부분 GET 메서드와 함께 사용
- authority 형식 : 도메인 이름과 포트 번호로 이루어진 URL의 authority component, HTTP 터널을 구축하는 경우 CONNECT와 사용 가능
- asterisk 형식 : OPTIONS와 함께 별표 하나로 서버 전체를 표현
3) HTTP 버전에 따라 HTTP Message의 구조가 달라지기 때문에, HTTP 버전을 함께 입력
- Headers
- 헤더 이름, 콜론, 값을 입력
- 여러 종류의 헤더가 존재
1) General Headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더
2) Request Headers : fetch를 통해 가져올 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더를 의미(요청 구체화, 컨텍스트 제공, 제약 추가)
3) Represntation Headers : body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더
- Body
- HTTP Messages 구조의 마지막에 위치
- 모든 요청에 Body가 필요하지 않음(GET,HEAD,DELETE,OPTIONS처럼 서버에 리소스를 요청하는 경우 Body 필요 X)
1) Single-resource bodies(단일-리소스 본문) : 헤더 두 개로 정의된 단일 파일로 구성
2) Multiple-resource bodies(단일-리소스 본문) : 여러 파트로 구성된 본문에서는 각 파트마다 다른 정보를 지님
4. 응답
- Status line
- 현재 프로토콜의 버전, 상태 코드(요청의 결과를 표현), 상태 텍스트(상태 코드에 대한 설명)가 포함
- Headers
- 요청 헤더와 동일한 구조를 가짐
- 문자열, 콜론, 값을 입력
1) General Headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더
2) Response Headers : 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더(상태창에 넣기 부족했던 추가 정보를 제공)
3) Represntation Headers : body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더
- Body
- HTTP Messages 구조의 마지막에 위치
- 모든 요청에 Body가 필요하지 않음(201, 204와 같은 상태 코드를 가지는 응답에는 Body 필요 X)
1) Single-resource bodies(단일-리소스 본문) : 길이가 알려진 단일-리소스 본문은 두개의 헤더로 정의(길이를 모르는 단일 파일로 구성된 단일-리소스 본문은 Transfer-Encoding이 chunked로 설정되어 있으며, 파일은 chunk로 나뉘어 인코딩되어 있음)
2) Multiple-resource bodies(단일-리소스 본문) : 서로 다른 정보를 담고 있는 body
5. Stateless
- 상태를 가지지 않음을 의미
- 클라이언트와 서버가 HTTP로 통신을 주고받는 과정에서, HTTP가 클라이언트나 서버의 상태를 확인하지 않음
6. HTTP를 이용한 클라이언트-서버 통신과 API
- 웹 애플리케이션 아키텍처에서는 클라이언트와 서버가 HTTP라는 프로토콜을 사용해 서로 소통
- HTTP를 이용해 주고받는 메시지를 HTTP Messages라고 표현
- 각 프로토콜마다 지켜야할 규약이 존재
- API(Application Programming Interface) : 서버측에서 클라이언트가 리소스를 잘 활용할 수 있도록 제공한 인터페이스
- HTTP 요청에는 메서드라는 것이 존재하며, POST, GET, PATCH, PUT, DELETE 등의 메서드를 통해 추가/조회/갱신/삭제 등의 기능을 행동에 맞게 사용
