
💽CNN을 활용한 Scene 이미지분류
📚목차
- 프로젝트 목표
- 데이터셋
- Convolution 연산
- LeNet
- CustomLeNet
- AlexNet
- LightResNet
- ResNet
- 실전프로젝트
- 느낀 점
📌프로젝트 목표
풍경이미지를 어떤 카테고리에 속하는지 분류하는 모델을 만드는 것으로 다음 프로젝트에서는 3가지 모델을 실습하는 것을 목표로 한다.
- LeNet
- AlexNet
- ResNet
또한, 데이터 증진 기법으로 2가지를 실습한다.
- Mixup
- Transfer Learning
📌데이터셋
Kaggle에서 데이터셋을 불러온다.
https://github.com/ndb796/Scene-Classification-Dataset-Split
위 데이터는 Scene Classification 데이터셋으로 6개의 클래스로 구분되어 있는 데이터셋이다.
# 깃허브에서 데이터셋 다운로드하기 !git clone https://github.com/ndb796/Scene-Classification-Dataset-Split # 폴더 안으로 이동 %cd Scene-Classification-Dataset-Split
의 과정을 통해 Colab에서 사용하도록 불러올 수 있었다. 데이터는 다음과 같은 13,627개의 학습데이터의 개수를 가지고 있다.
클래스 0. 빌딩(buildings): 2,105개
클래스 1. 숲(forests): 2,205개
클래스 2. 빙하(glacier): 2,363개
클래스 3. 산(mountains): 2,438개
클래스 4. 바다(sea): 2,224개
클래스 5. 거리(street): 2,292개
또한 검증 데이터의 개수는 3,407개로 구성되어 있다.
클래스 0. 빌딩(buildings): 523개
클래스 1. 숲(forests): 540개
클래스 2. 빙하(glacier): 594개
클래스 3. 산(mountains): 599개
클래스 4. 바다(sea): 560개
클래스 5. 거리(street): 591개
위 데이터에 기본적인 data augmentation을 진행한다.
- RandomResizedCrop(): 랜덤으로 이미지의 일부를 잘라내 변형한다.
- RandomHorizontalFlip(): 랜덤으로 이미지를 좌우반전한다.
또한 ImageNet 데이터셋의 설정을 이용해 **정규화**를 진행한다. 코드는 다음과 같다.
import torch
from torchvision import datasets, transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # device object
transforms_train = transforms.Compose([
transforms.RandomResizedCrop((64, 64)), # 데이터증진1
transforms.RandomHorizontalFlip(), # 데이터증진2
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화(normalization)
]) # 학습이미지의 정규화 및 데이터 증진
transforms_val = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화
])
train_dataset = datasets.ImageFolder(train_path, transforms_train)
val_dataset = datasets.ImageFolder(val_path, transforms_val)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=True, num_workers=2)
class_names = train_dataset.classes
print('Class names:', class_names)데이터를 시각화도 진행하려한다. 위에서 tensor로 변환해줬기 때문에 다시 numpy로 변환하여 출력해야한다.
import torchvision
import numpy as np
import matplotlib.pyplot as plt
# 화면에 출력되는 이미지 크기를 적절하게 조절하기
plt.rcParams['figure.figsize'] = [12, 8]
plt.rcParams['figure.dpi'] = 60
plt.rcParams.update({'font.size': 20})
def imshow(image, title):
# torch.Tensor => numpy 변환하기
image = image.numpy().transpose((1, 2, 0))
# 이미지 정규화(normalization) 해제하기
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
# 화면에 이미지 출력하기
plt.imshow(image)
plt.title(title)
plt.show()
# 학습 데이터셋에서 하나의 배치를 불러와 보기
iterator = iter(train_dataloader)
# 현재 배치에 포함된 이미지를 출력하기
inputs, classes = next(iterator)
out = torchvision.utils.make_grid(inputs[:4])
imshow(out, title=[class_names[x] for x in classes[:4]])
📌Convolution 연산
이해하기 어려웠지만 또 계산하기는 생각보다 쉬웠던 부분이었다.
- 입력 데이터의 높이: height
- 입력 데이터의 너비: width
- 필터의 높이: filter_height
- 필터의 너비: filter_width
- 스트라이드(stride): stride
- 패딩 크기: padding
라고 했을 때 계산식은 다음과 같다.(소수점 아래는 버린다.)
출력 높이(output height) = (height + 2 padding − filter_height) / stride + 1
출력 너비(output width) = (width + 2 padding − filter_width) / stride + 1
📌LeNet
LeNet의 특징은 다음과 같다.
- Convolutional Neural Network를 최초로 적용한 간단한 아키텍처
- Convolution 연산과 Pooling 연산을 사용
- PyTorch에서 모델에 별도의 Softmax 레이어를 두지 않고 학습할 때 nn.CrossEntropyLoss()를 사용하는 것이 일반적
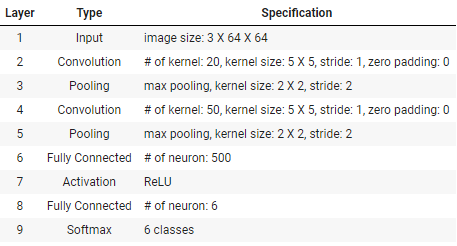
위 표와 같은 조건이 주어졌을 때 LeNet모델은 이렇게 만들 수 있다.
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# → 차원(dimension): (3 x 64 x 64)
self.conv1 = nn.Conv2d(in_channels=3, out_channels=20, kernel_size=5, stride=1, padding=0)
# → 차원(dimension): (20 x 60 x 60)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# → 차원(dimension): (20 x 30 x 30)
self.conv2 = nn.Conv2d(in_channels=20, out_channels=50, kernel_size=5, stride=1, padding=0)
# → 차원(dimension): (50 x 26 x 26)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# → 차원(dimension): (50 x 13 x 13)
self.fc1 = nn.Linear(50 * 13 * 13, 500)
# → 차원(dimension): (500)
self.fc2 = nn.Linear(500, 6)
# → 차원(dimension): (6)
def forward(self, x):
x = self.pool1(self.conv1(x))
x = self.pool2(self.conv2(x))
x = torch.flatten(x, 1) # 배치(batch)를 제외한 모든 차원 flatten하기
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# LeNet모델
def train(net, epoch, optimizer, criterion, train_dataloader):
print('[ Train epoch: %d ]' % epoch)
net.train() # 모델을 학습 모드로 설정
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad() # 기울기(gradient) 초기화
outputs = net(inputs) # 모델 입력하여 결과 계산
loss = criterion(outputs, targets) # 손실(loss) 값 계산
loss.backward() # 역전파를 통해 기울기(gradient) 계산
optimizer.step() # 계산된 기울기를 이용해 모델 가중치 업데이트
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print('Train accuarcy:', 100. * correct / total)
print('Train average loss:', train_loss / total)
return (100. * correct / total, train_loss / total)
def validate(net, epoch, val_dataloader):
print('[ Validation epoch: %d ]' % epoch)
net.eval() # 모델을 평가 모드로 설정
val_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(val_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs) # 모델 입력하여 결과 계산
val_loss += criterion(outputs, targets).item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print('Accuarcy:', 100. * correct / total)
print('Average loss:', val_loss / total)
return (100. * correct / total, val_loss / total)
# train(학습), validate(검증) 함수
import time
import torch.optim as optim
net = LeNet()
net = net.to(device)
epoch = 30
learning_rate = 0.002
file_name = "LeNet.pt"
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002)
train_result = []
val_result = []
start_time = time.time() # 시작 시간
for i in range(epoch):
train_acc, train_loss = train(net, i, optimizer, criterion, train_dataloader) # 학습(training)
val_acc, val_loss = validate(net, i + 1, val_dataloader) # 검증(validation)
# 학습된 모델 저장하기
state = {
'net': net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print(f'Model saved! (time elapsed: {time.time() - start_time})')
# 현재 epoch에서의 정확도(accuracy)와 손실(loss) 값 저장하기
train_result.append((train_acc, train_loss))
val_result.append((val_acc, val_loss))
# 실제적인 학습함수위 과정에서 epoch는 30으로 고정시키고 여러번의 learning rate로 실험을 하였다. lr이 0.007 이상인 경우 손실값이 NaN으로 나왔는데 이로 인해 학습률이 너무 커서 발산하였다는 것을 알 수 있었다.
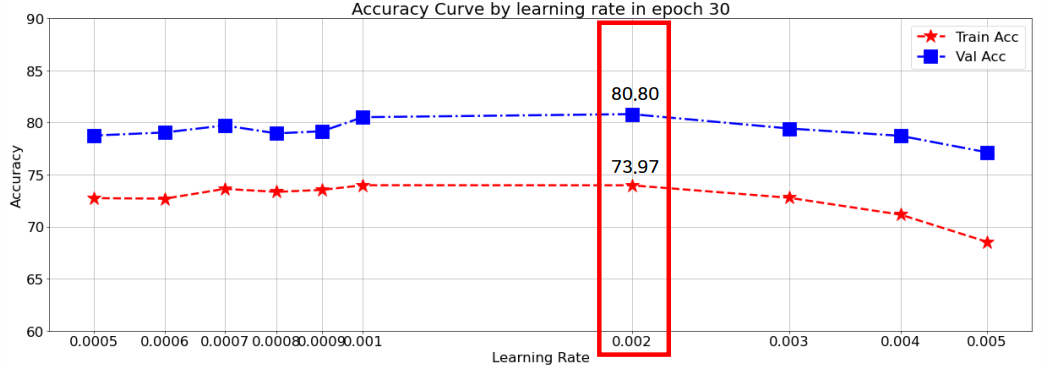
정확도가 제일 높았던 0.002에서의 손실그래프는 다음과 같다.
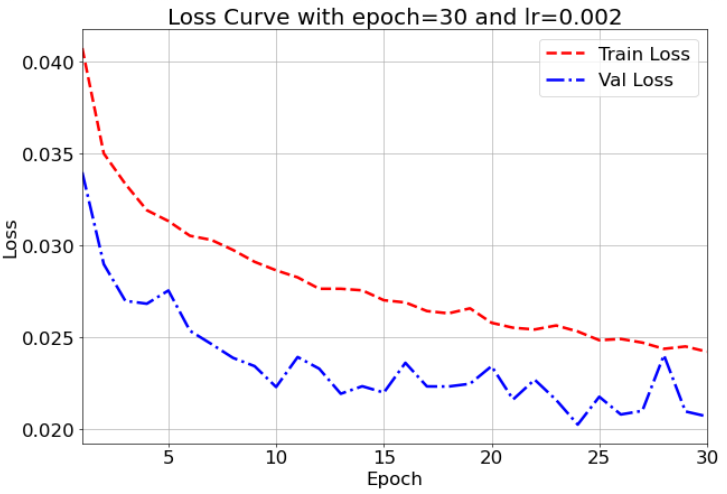
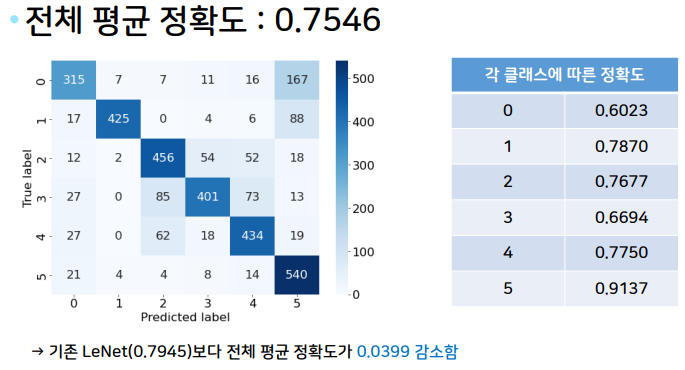
각 클래스에 대해 얼마나 정확히 분류하는지 확인해보기 위해 confusion matrix를 확인해보기로 하였다.
# 네트워크에 데이터셋을 입력하여 혼동 행렬(confusion matrix)을 계산하는 함수
def get_confusion_matrix(net, num_classes, data_loader):
net.eval() # 모델을 평가 모드로 설정
confusion_matrix = torch.zeros(num_classes, num_classes, dtype=torch.int32)
for batch_idx, (inputs, targets) in enumerate(data_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
_, predicted = outputs.max(1)
for t, p in zip(targets.view(-1), predicted.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
return confusion_matrixconfusion matrix를 정의한 코드이며 다음을 통해 확인할 수 있다.
import pandas as pd
import seaborn as sns
net = LeNet()
net = net.to(device)
file_name = "./checkpoint/LeNet.pt"
checkpoint = torch.load(file_name)
net.load_state_dict(checkpoint['net'])
# 평가 데이터셋을 이용해 혼동 행렬(confusion matrix) 계산하기
confusion_matrix = get_confusion_matrix(net, 6, val_dataloader)
print("[ 각 클래스당 데이터 개수 ]")
print(confusion_matrix.sum(1))
print("[ 혼동 행렬(confusion matrix) 시각화 ]")
res = pd.DataFrame(confusion_matrix.numpy(), index = [i for i in range(6)], columns = [i for i in range(6)])
res.index.name = 'True label'
res.columns.name = 'Predicted label'
plt.figure(figsize = (10, 7))
sns.heatmap(res, annot=True, fmt="d", cmap='Blues')
plt.show()
print("[ 각 클래스에 따른 정확도 ]")
# (각 클래스마다 정답 개수 / 각 클래스마다 데이터의 개수)
print(confusion_matrix.diag() / confusion_matrix.sum(1))
print("[ 전체 평균 정확도 ]")
print(confusion_matrix.diag().sum() / confusion_matrix.sum())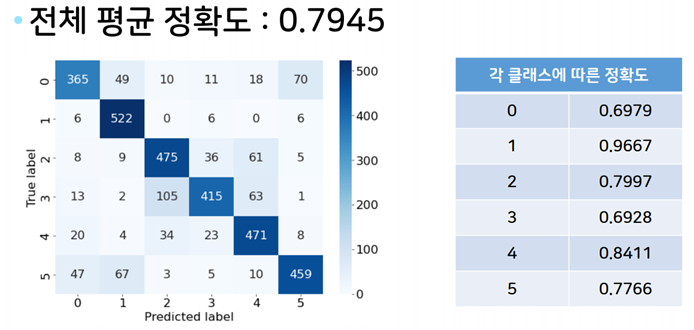
📌CustomLeNet
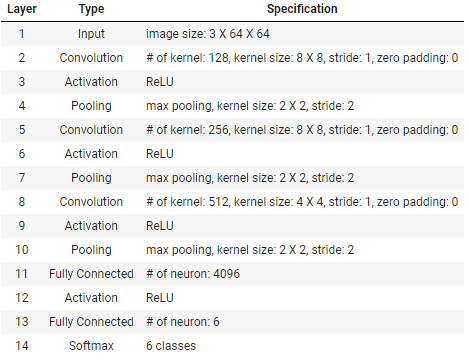
다음의 조건이 주어졌을 때 Custom으로 모델을 만드는 과제가 주어졌다.
- 커널 크기와 커널의 개수 증가
- Fully Connected 레이어의 차원 증가
두가지의 조건이 붙은 셈인데 다음과 같이 작성하였다.
class CustomLeNet(nn.Module):
def __init__(self):
super(CustomLeNet, self).__init__()
# → 차원(dimension): (3 x 64 x 64)
self.conv1 = nn.Conv2d(in_channels=3, out_channels=128, kernel_size=8, stride=1, padding=0)
# → 차원(dimension): (128 x 57 x 57)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# → 차원(dimension): (128 x 28 x 28)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=8, stride=1, padding=0)
# → 차원(dimension): (256 x 21 x 21)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# → 차원(dimension): (256 x 10 x 10)
self.conv3 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=4, stride=1, padding=0)
# → 차원(dimension): (512 x 7 x 7)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# → 차원(dimension): (512 x 3 x 3)
self.fc1 = nn.Linear(512 * 3 * 3, 4096)
# → 차원(dimension): (4096)
self.fc2 = nn.Linear(4096, 6)
# → 차원(dimension): (6)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = torch.flatten(x, 1) # 배치(batch)를 제외한 모든 차원 flatten하기
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x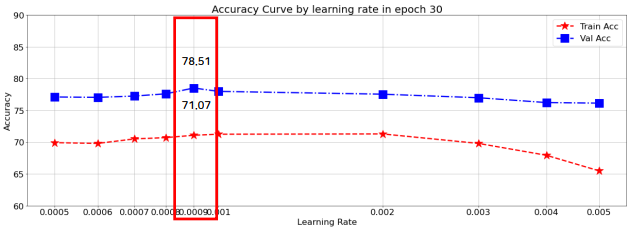
0.0009 lr에서 정확도가 제일 높게 나온 것을 확인할 수 있었다. 하지만 기본 LeNet을 구동했을 때보다 정확도가 낮은 것을 확인할 수 있었다.
이로 인해 Layer가 깊어지고 Parameter가 증가할수록 더 복잡해지기 때문에 30번의 학습횟수로는 부족하지 않았을까? 하는 생각을 갖게 하였다.
따라서 다다음 LightResNet에서 검증을 해보기로 하였다.
📌AlexNet
AlexNet의 특징은 다음과 같다.
- LRN (Local Response Normalization)을 활용
- Dropout을 활용
- ReLU를 적극적으로 활용

위 표가 주어졌을 때 다음과 같이 AlexNet을 구현할 수 있다. 앞서 진행한 LeNet과 크게 다르지 않다.
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# → 차원(dimension): (3 x 64 x 64)
nn.Conv2d(3, 96, kernel_size=5, stride=1, padding=2),
# → 차원(dimension): (96 x 64 x 64)
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
# → 차원(dimension): (96 x 31 x 31)
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
# → 차원(dimension): (256 x 31 x 31)
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
# → 차원(dimension): (256 x 15 x 15)
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
# → 차원(dimension): (384 x 15 x 15)
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
# → 차원(dimension): (384 x 15 x 15)
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
# → 차원(dimension): (384 x 15 x 15)
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# → 차원(dimension): (384 x 7 x 7)
)
self.classifier = nn.Sequential(
nn.Linear(384 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 6),
nn.Dropout(),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 배치(batch)를 제외한 모든 차원 flatten하기
x = self.classifier(x)
return xAlexNet의 confusin matrix는 다음과 같다.
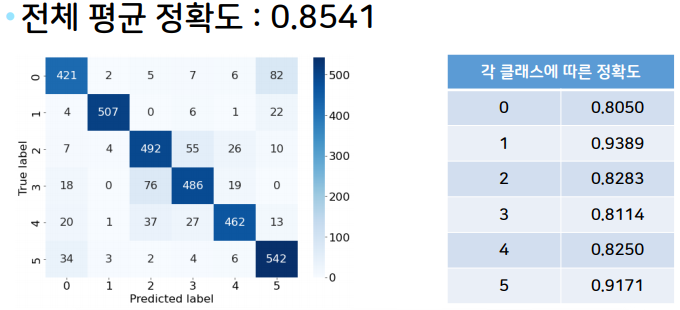
📌LightResNet
레이어의 깊이에 따라 여러 버전을 갖고 있는 모델이다.
20, 32, 44, 56, 110 레이어의 버전등이 있으며 일반적으로 더 깊은 레이어의 ResNet이 더 높은 정확도를 보인다.
# ResNet을 위한 BasicBlock 클래스 정의
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
# 3x3 필터를 사용 (stride 값이 2라면, 너비와 높이가 절반으로 감소)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes) # 배치 정규화(batch normalization)
# 3x3 필터를 사용 (stride 값이 1이므로, 너비와 높이가 유지)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes) # 배치 정규화(batch normalization)
self.shortcut = nn.Sequential() # identity인 경우
if stride != 1: # stride가 1이 아니라면, identity mapping이 아닌 경우
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # (핵심) skip connection
out = F.relu(out)
return out
# LightResNet 클래스 정의
class LightResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=6):
super(LightResNet, self).__init__()
self.in_planes = 16
# 16개의 3x3 필터(filter)를 사용
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
# 첫 레이어를 제외하고는 너비와 높이를 줄이기 위해 stride를 2로 설정
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2)
self.linear = nn.Linear(64, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) # 첫째 블록만 너비와 높이 감소
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes # 다음 레이어를 위해 채널 수 변경
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1) # 배치(batch)를 제외한 모든 차원 flatten하기
out = self.linear(out)
return out
def LightResNet20():
return LightResNet(BasicBlock, [3, 3, 3])
def LightResNet32():
return LightResNet(BasicBlock, [5, 5, 5])
def LightResNet44():
return LightResNet(BasicBlock, [7, 7, 7])
def LightResNet56():
return LightResNet(BasicBlock, [9, 9, 9])
def LightResNet110():
return LightResNet(BasicBlock, [18, 18, 18])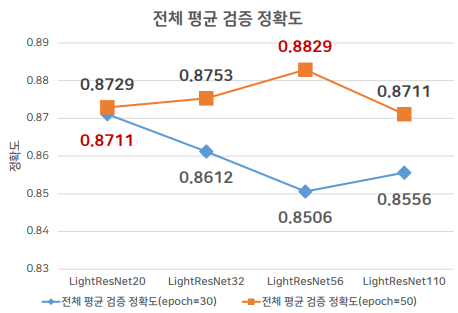
위 모델에서 44를 제외하고 각각 epoch 30, 50으로 진행해보았다. 앞서 제시한 의문처럼 30번만 학습했을 때는 20레이어의 정확도가 제일 높았지만, 50번 학습을 진행했을 때는 56레이어의 정확도가 제일 높았고, 전체적으로 정확도가 높아졌다. 이를 통해 레이어가 깊어질수록 더 학습을 진행해야 하고 epoch가 높아지는 만큼 적당히 레이어도 깊어졌을 때 그 시너지가 발휘된다는 것을 알게 되었다.
📌ResNet
LightResNet에 비하여 커널의 개수가 증가한 버전으로 ImageNet과 같은 큰 규모의 데이터셋에서 사용하기 적합하다.
# ResNet 클래스 정의
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=6):
super(ResNet, self).__init__()
self.in_planes = 64
# 64개의 3x3 필터(filter)를 사용
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# 첫 레이어를 제외하고는 너비와 높이를 줄이기 위해 stride를 2로 설정
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) # 첫째 블록만 너비와 높이 감소
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes # 다음 레이어를 위해 채널 수 변경
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1) # 배치(batch)를 제외한 모든 차원 flatten하기
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
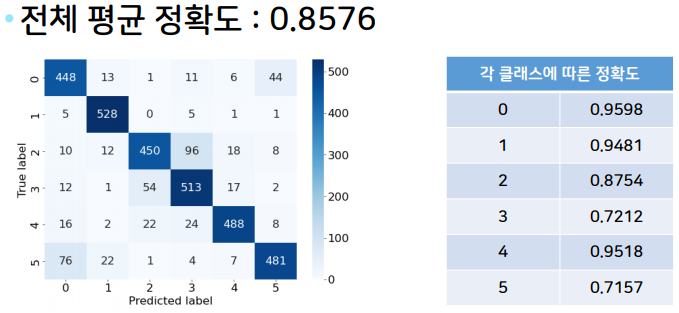
return ResNet(BasicBlock, [3, 4, 6, 3])위 코드는 ResNet을 구성해주는 코드이다. ResNet18을 학습한 결과는 다음과 같다.
이제 추가적으로 진행해볼 data augmentation을 진행하려고 한다. 먼저 실습할 것은 Mixup이다.
- Mixup
학습데이터에서 두개의 샘플 데이터를 혼합하여 새로운 학습데이터를 만드는 기술
overfitting을 방지하며 일반화 성능을 높이는 효과가 있다.
mixup_alpha = 1.0
def mixup_data(x, y):
lam = np.random.beta(mixup_alpha, mixup_alpha)
batch_size = x.size()[0]
index = torch.randperm(batch_size).cuda()
mixed_x = lam * x + (1 - lam) * x[index]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
def train_with_mixup(net, epoch, optimizer, criterion, train_dataloader):
print('[ Train epoch: %d ]' % epoch)
net.train() # 모델을 학습 모드로 설정
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets) # Mixup 진행
optimizer.zero_grad() # 기울기(gradient) 초기화
outputs = net(inputs) # 모델 입력하여 결과 계산
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam) # 손실(loss) 값 계산
loss.backward() # 역전파를 통해 기울기(gradient) 계산
optimizer.step() # 계산된 기울기를 이용해 모델 가중치 업데이트
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += (lam * predicted.eq(targets_a).sum().item() + (1 - lam) * predicted.eq(targets_b).sum().item())
print('Train accuarcy:', 100. * correct / total)
print('Train average loss:', train_loss / total)
return (100. * correct / total, train_loss / total)일반적으로 새로운 학습데이터와 새로운 클래스를 만드는 기술이기 때문에 1.5배 이상의 epoch가 요구된다. 따라서 epoch를 50으로 올려 실험을 진행했다.
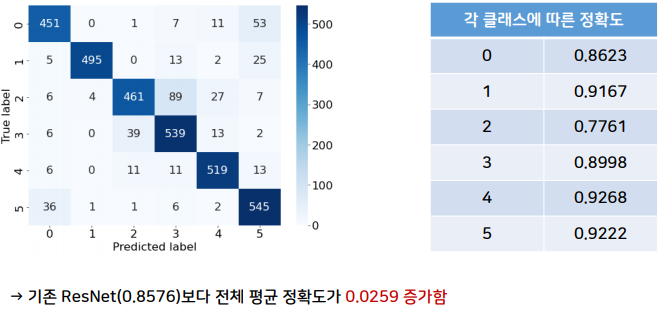
- Transfer Learning
전이 학습(Transfer Learning)이란 단기간에 우수한 정확도를 얻기 위해 효과적으로 사용할 수 있는 기법을 의미
그 중 미세조정(fine tuning)은 신경망을 미리 학습한 신경망으로 초기화하는 것을 말한다.
적은 epoch로도 빠르게 수렴한다는 특징이 있다.
transforms_train_transferred = transforms.Compose([
transforms.RandomResizedCrop((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화(normalization)
])
transforms_val_transferred = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset_transferred = datasets.ImageFolder(train_path, transforms_train_transferred)
val_dataset_transferred = datasets.ImageFolder(val_path, transforms_val_transferred)
train_dataloader_transferred = torch.utils.data.DataLoader(train_dataset_transferred, batch_size=16, shuffle=True, num_workers=2)
val_dataloader_transferred = torch.utils.data.DataLoader(val_dataset_transferred, batch_size=16, shuffle=True, num_workers=2)
print('Training dataset size:', len(train_dataset_transferred))
print('Validation dataset size:', len(val_dataset_transferred))
class_names = train_dataset_transferred.classes
print('Class names:', class_names)전이학습을 위해 사전학습된 네트워크와 동일한 크기의 입력차원을 갖도록 데이터셋을 수정하였다.
net = torchvision.models.resnet18(pretrained=True)
# 마지막 레이어의 차원을 6차원으로 조절
num_features = net.fc.in_features
net.fc = nn.Linear(num_features, 6)
net = net.to(device)
epoch = 20
learning_rate = 0.001 # 일반적으로 fine-tuning을 진행할 때는 학습률(learning rate)을 낮게 설정
file_name = "ResNet18Transferred.pt"
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002)
train_result = []
val_result = []
start_time = time.time() # 시작 시간
for i in range(epoch):
train_acc, train_loss = train(net, i, optimizer, criterion, train_dataloader_transferred) # 학습(training)
val_acc, val_loss = validate(net, i + 1, val_dataloader_transferred) # 검증(validation)
# 학습된 모델 저장하기
state = {
'net': net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print(f'Model saved! (time elapsed: {time.time() - start_time})')
# 현재 epoch에서의 정확도(accuracy)와 손실(loss) 값 저장하기
train_result.append((train_acc, train_loss))
val_result.append((val_acc, val_loss))transfer learning적용
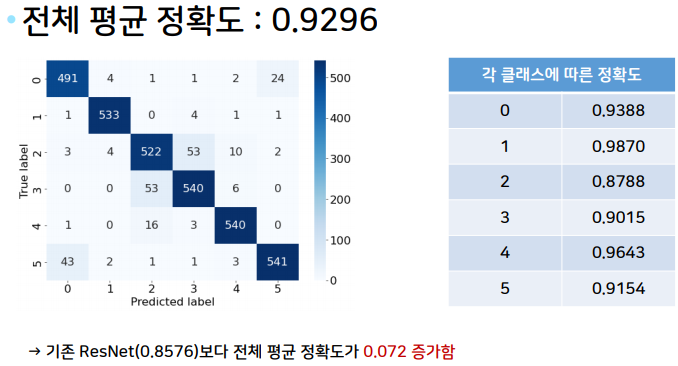
📌실전 프로젝트
지금까지 배운 것들을 토대로 정확도가 높게 나오게끔 모델을 만들어보기로 한다.
사용한 모델은
- ResNet 50
- ResNet 101
- ResNet 152
를 사용하였다.
전이학습(Transfer Learning)과 Mixup을 모두 적용하였고,
- Epoch : 50
- Learning rate: 0.001
- Optimizer : SGD
- Scheduler : MultiStepLR
의 조건을 적용하였다.
model_list = [50,101,152]
for models in model_list:
exec(f"net = torchvision.models.resnet{models}(pretrained=True)")
# 마지막 레이어의 차원을 6차원으로 조절
num_features = net.fc.in_features
net.fc = nn.Linear(num_features, 6)
net = net.to(device)
epoch = 50
learning_rate = 0.001
file_name = "ResNet"+str(models)+"Transferred_mixup.pt"
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002)
scheduler1 = optim.lr_scheduler.MultiStepLR(optimizer, milestones=np.arange(10,epoch), gamma=0.5)
scheduler2 = optim.lr_scheduler.MultiStepLR(optimizer, milestones=np.arange(20,epoch), gamma=0.5)
scheduler3 = optim.lr_scheduler.MultiStepLR(optimizer, milestones=np.arange(30,epoch), gamma=0.5)
scheduler4 = optim.lr_scheduler.MultiStepLR(optimizer, milestones=np.arange(40,epoch), gamma=0.5)
train_result = []
val_result = []
start_time = time.time() # 시작 시간
for i in range(epoch):
train_acc, train_loss = train_with_mixup(net, i, optimizer, criterion, train_dataloader_transferred) # 학습(training)
val_acc, val_loss = validate(net, i + 1, val_dataloader_transferred) # 검증(validation)
# 학습된 모델 저장하기
state = {
'net': net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print(f'Model saved! (time elapsed: {time.time() - start_time})')
scheduler1.step()
scheduler2.step()
scheduler3.step()
scheduler4.step()
# 현재 epoch에서의 정확도(accuracy)와 손실(loss) 값 저장하기
train_result.append((train_acc, train_loss))
val_result.append((val_acc, val_loss))
checkpoint = torch.load('./checkpoint/' + file_name)
net.load_state_dict(checkpoint['net'])
# 평가 데이터셋을 이용해 혼동 행렬(confusion matrix) 계산하기
confusion_matrix = get_confusion_matrix(net, 6, val_dataloader_transferred)
print("[ 각 클래스당 데이터 개수 ]")
print(confusion_matrix.sum(1))
print("[ 혼동 행렬(confusion matrix) 시각화 ]")
res = pd.DataFrame(confusion_matrix.numpy(), index = [i for i in range(6)], columns = [i for i in range(6)])
res.index.name = 'True label'
res.columns.name = 'Predicted label'
plt.figure(figsize = (10, 7))
sns.heatmap(res, annot=True, fmt="d", cmap='Blues')
plt.show()
print("[ 각 클래스에 따른 정확도 ]")
# (각 클래스마다 정답 개수 / 각 클래스마다 데이터의 개수)
print(confusion_matrix.diag() / confusion_matrix.sum(1))
print("[ 전체 평균 정확도 ]")
print(confusion_matrix.diag().sum() / confusion_matrix.sum())의 코드로 작성하였다.
결과
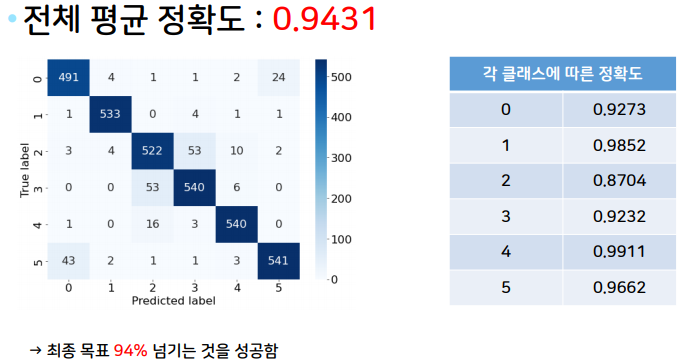
94%의 정확도를 얻을 수 있었다.
📌느낀점
데브코스를 진행하면서 벌써 2번째 프로젝트였다. 처음 진행했던 타이타닉과 다르게 CNN은 예전 대학교 연구실에서 공부해본 적도 있어서 비교적 원활하게 진행할 수는 있었지만, 다 처음보는 모델이라 쉽지 않았던 것 같다. 게다가 대규모 데이터셋은 처음 진행해봐서 컴퓨터가 버텨주지 못해 팀원이 모델실험을 진행하고 내가 발표를 정리하는 쪽으로 진행하였다.
벌써 2달이 지났고 3달째, 절반정도 왔는데 크게 달라지지 않은 것 같아서 잘하고 있는지 의문이 들 때가 있다. 블로그도 매일 포스팅해야했는데 이게 얼마만인지. 앞으로라도 열심히 해봐야겠다.
