💽Matplotlib
📚배운 강의 내용
- Matplotlib으로 데이터 시각화하기
- Matplotlib의 기본적인 사용법
- Matplotlib의 다양한 plot
📌Matplotlib으로 데이터 시각화하기
먼저 matplotlib 패키지를 설치해야 사용할 수 있다. 터미널이나 shell에서 아래 명령어를 작동하면 된다.
pip install matplotlibpandas 설치가 끝났다면 사용하는 법은 어렵지 않다. 기본적으로 import를 이용해 matplotlib 패키지를 불러오며 우리가 보통 자주 사용하게 될 라이브러리는 matplotlib 에 포함된 pyplot이다. plt라고 편하게 줄여 사용하곤 한다.
import matplotlib.pyplot as plt📌Matplotlib의 기본적인 사용법
❗️matplotlib의 기본적인 함수와 1차함수 그래프 그리기
plt.plot([1, 2, 3, 4, 5]) # plotting을 하는 함수
plt.show() # plt을 확인하는 함수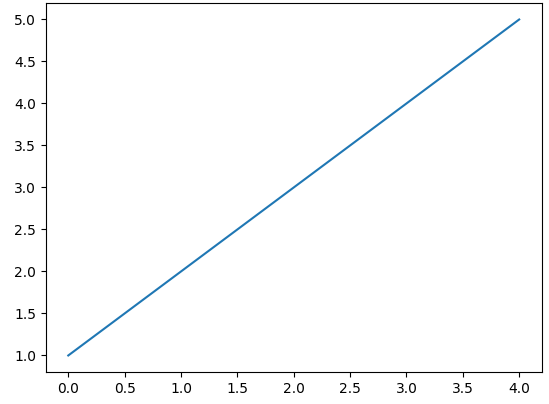
plt.plot([4, 2, 4, 2, 5])
plt.show()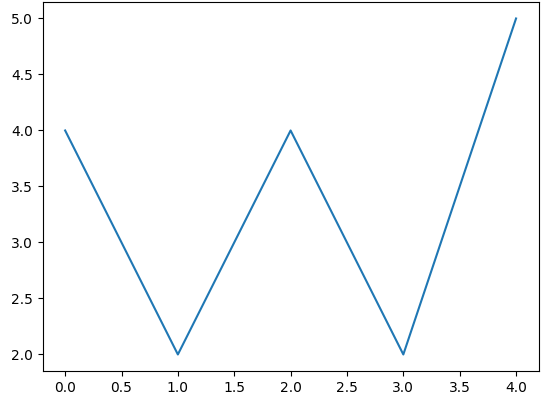
위 그래프들을 통해 알 수 있는 것은, plot()안의 인자들은 y를 의미하고 x는 인덱스번호를 의미한다는 것이다.
plt.plot([4, 2, 4, 2, 5])
은 결국
plt.plot(x=index, y=[4,2,4,2,5])
와 같은 의미이다.plt.figure()함수를 통해서 plotting할 도면을 선택하고 그 사이즈를 결정할 수도 있다. figsize는 tuple형태로 선언되며 사용법은 다음과 같다.
plt.figure(figsize = (6,6))❗️matplotlib로 2차함수 그리기
# numpy.array를 이용해서 함수 그리기
# y = x^2
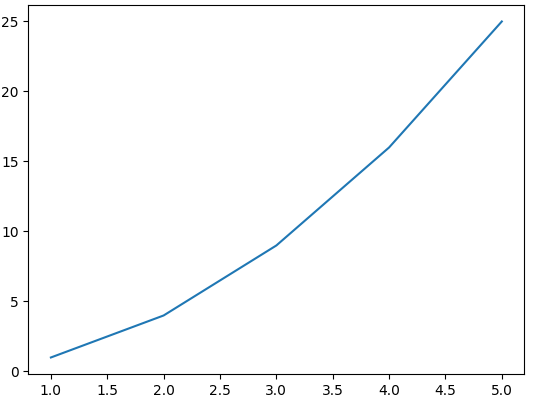
x = np.array([1,2,3,4,5])
y = np.array([1,4,9,16,25]) # f(x)
plt.plot(x,y)
plt.show()
위 그래프의 문제점은 x, y값이 5개뿐이라 부드러운 2차함수의 모양과는 거리가 있다는 점이다. 따라서 이런 문제를 해결하기 위해 다른 방법을 도입했다.
# np.arange(a, b, c) c: 간격이므로 숫자값으로 고정
x = np.arange(-10, 10, 0.01) # -10 ~ 10 까지 0.01 간격으로
plt.plot(x, x**2) # x, x^2
plt.show()
위 방법을 도입하면 우리가 흔히 알고 있는 2차함수의 기본 그래프가 그려지는 걸 확인할 수 있다.
❗️matplotlib그래프에 각종 설명 추가하기
plt에 xlabel, ylabel을 통해 x축과 y축에 설명을 추가할 수 있다.
x = np.arange(-10, 10, 0.01) # -10 ~ 10 까지 0.01 간격으로
plt.xlabel("x value")
plt.ylabel("f(x) value")
plt.plot(x, x**2) # x, x^2
plt.show()
x축과 y축의 범위 설정 역시 가능하다.
plt.axis() 함수를 통해 x, y값의 최소 최대를 설정할 수 있다.
x = np.arange(-10, 10, 0.01) # -10 ~ 10 까지 0.01 간격으로
plt.xlabel("x value")
plt.ylabel("f(x) value")
plt.axis([-5, 5, 0, 25]) # [x_min, x_max, y_min, y_max]
plt.plot(x, x**2) # x, x^2
plt.show()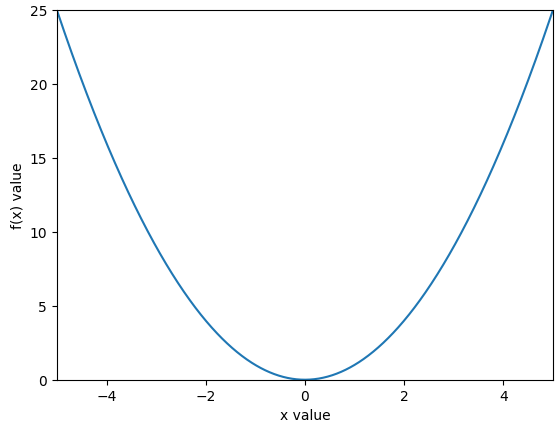
그렇다면 x, y축에 눈금을 원하는 대로는 어떻게 설정할 수 있을까?
xticks(), yticks()라는 함수를 이용하면 된다.
x = np.arange(-10, 10, 0.01) # -10 ~ 10 까지 0.01 간격으로
plt.xlabel("x value")
plt.ylabel("f(x) value")
plt.axis([-5, 5, 0, 25]) # [x_min, x_max, y_min, y_max]
plt.xticks([i for i in range(-5, 6, 1)]) # x축의 눈금 설정 -5 ~ 5까지 1의 간격
plt.yticks([i for i in range(0, 28, 3)]) # y축의 눈금 설정 0 ~ 27까지 3의 간격
plt.plot(x, x**2) # x, x^2
plt.show()
마지막으로, 그래프에 title과 label을 다는 법을 알아보자.
x = np.arange(-10, 10, 0.01) # -10 ~ 10 까지 0.01 간격으로
plt.xlabel("x value")
plt.ylabel("f(x) value")
plt.axis([-5, 5, 0, 25]) # [x_min, x_max, y_min, y_max]
plt.xticks([i for i in range(-5, 6, 1)]) # x축의 눈금 설정 -5 ~ 5까지 1의 간격
plt.yticks([i for i in range(0, 28, 3)]) # y축의 눈금 설정 0 ~ 27까지 3의 간격
plt.title("y = x^2 그래프") # title 설정
plt.plot(x, x**2, label ='graph') # x, x^2 #label을 graph로 선언
plt.legend() # plot이 진행된 이후 선언해야한다.
plt.show()
📌Matplotlib의 다양한 plot
앞서 plt.plot()이 꺾은선 그래프를 그려주는 것을 확인할 수 있었다. 그렇다면 또 다양한 그래프를 그리는 법은 어떻게 할 수 있을까?
❗️산점도(Scatter Plot)
산점도란, 점으로 그래프를 그려주는 것을 말한다.
데이터의 분포를 알고자 할 때 자주 사용한다.
plt.scatter(x=[0,1,2,3,4],y=[1, 2, 3, 4, 5]) # plotting을 하는 함수
plt.show() # plt을 확인하는 함수
❗️박스 그림(Box Plot)
- 수치형 데이터에 대한 정보 (Q1, Q2, Q3, min, max)
y = np.random.randint(0, 20, 20) # 0 ~ 19 사이의 난수를 20번 생성
plt.boxplot(y)
plt.show() # plt을 확인하는 함수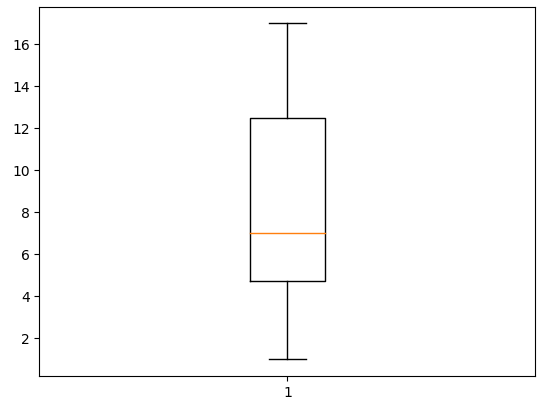
그림의 맨 밑과 맨 위는 각각 최솟값과 최댓값을 표현해주는 것이고 박스를 표현하는 밑선은 Q1, 즉 백분위의 25%값, 노란선은 median값, 그 위 선은 75%에 해당하는 Q3값을 의미한다.
이처럼 데이터의 분포를 알아보고자 할 때 사용한다.
❗️막대 그래프(Bar Plot)
- 범주형 데이터의 값과 그 값의 크기를 직사각형으로 나타낸 그림
x = np.arange(20) # 0 ~ 19
y = np.random.randint(0, 20, 20) # 0 ~ 19 사이의 난수를 20번 생성
plt.bar(x,y)
plt.show() # plt을 확인하는 함수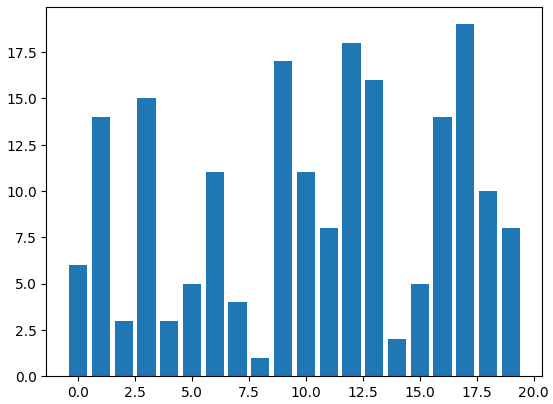
위 그래프를 좀 더 정확히 보고 싶다면 위에서 진행했던 xticks()를 활용해주면 좋다.
x = np.arange(20) # 0 ~ 19
y = np.random.randint(0, 20, 20) # 0 ~ 19 사이의 난수를 20번 생성
plt.bar(x,y)
plt.xticks(np.arange(0, 20, 1))
plt.show() # plt을 확인하는 함수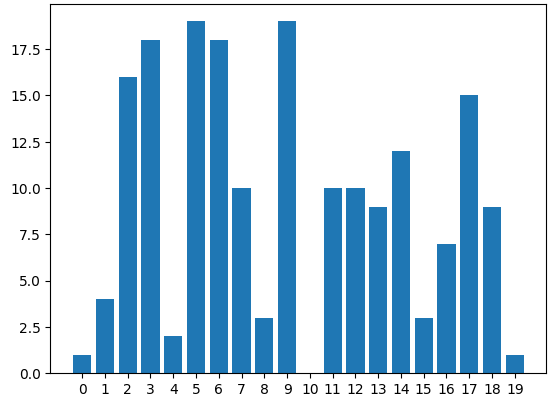
❗️히스토그램(Histogram)
- 막대 그래프와 유사함.
- 도수분포를 직사각형의 막대 형태로 나타낸다.
- "계급" 으로 나타낸 것이 차이점이자 특징 : 0, 1, 2가 아니라 0~2까지의 범주형 데이터로 구성 후 그림을 그림.
x = np.arange(20) # 0 ~ 19
y = np.random.randint(0, 20, 20)) # 0 ~ 19 사이의 난수를 20번 생성
plt.hist(y, bins=np.arange(0,20,2)
plt.show() # plt을 확인하는 함수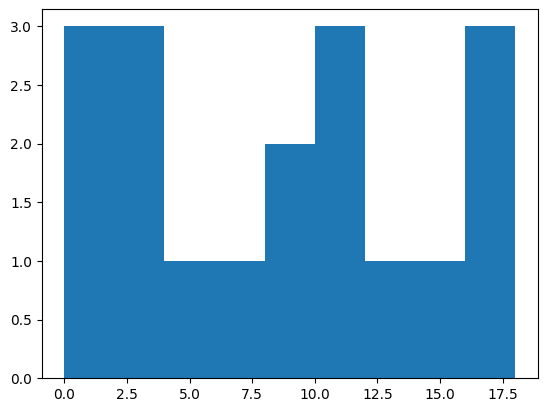
xticks()를 조정하면 더 원하는 값을 보기 쉬워진다.
x = np.arange(20) # 0 ~ 19
y = np.random.randint(0, 20, 20)) # 0 ~ 19 사이의 난수를 20번 생성
plt.hist(y, bins=np.arange(0,21,2))
plt.xticks(np.arange(0,21,2))
plt.show()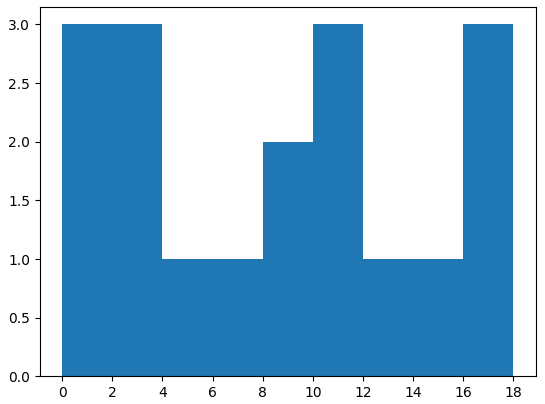
❗️원형 그래프(Pie Chart)
- 데이터에서 전체에 대한 부분의 비율을 부채꼴로 나타낸 그래프
- 다른 그래프에 비해서 비율확인에 용이하다.
z = [100, 300, 200, 400]
plt.pie(z)
plt.show()
순서대로 z의 값에 따라 pie가 그려지는 걸 확인할 수 있지만 보기에 편하지는 않다. 따라서 label을 지정해주어야 한다.
z = [100, 300, 200, 400]
plt.pie(z, labels = ['one', '2', 'three', 'four'])
plt.show()
📌Seaborn
- Matplotlib을 기반으로 더 다양한 시각화 방법을 제공하는 라이브러리
- 커널밀도그림- 카운트그림
- 캣그림
- 스트림그림
- 히트맵
❗️Seaborn 사용하기
seaborn 패키지를 설치해준다. 터미널이나 shell에서 아래 명령어를 작동하면 된다.
pip install seaborn여타 라이브러리와 마찬가지로 import를 이용해 사용한다.
import seaborn as sns❗️커널밀도그림
- 히스토그램과 같은 연속적인 분포를 곡선화해서 그린 그림
- sns.kdeplot()
x = np.arange(0, 22, 2)
y = np.random.randint(0, 20, 20)
plt.hist(y, bins=x) # y에 대해서 histogram을 작성해주고 기준은 x이다.
plt.show()
x = np.arange(0, 22, 2)
y = np.random.randint(0, 20, 20)
sns.kdeplot(y)
plt.show()
위 kdeplot()에는 shade라는 인자가 있는데 기본값은 False로 설정되어 있다. 이 인자를 True로 바꾸면 밑처럼 색칠을 해줄 수 있다.
x = np.arange(0, 22, 2)
y = np.random.randint(0, 20, 20)
sns.kdeplot(y, shade=True)
plt.show()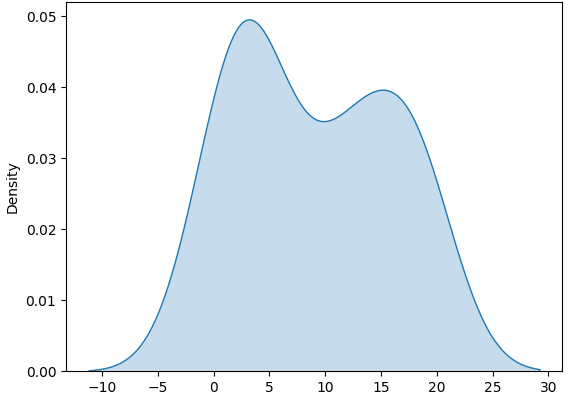
❗️카운트그림
- 범주형 column의 빈도수를 시각화 -> Groupby 후 도수를 책정해 그림을 그리는 것과 동일한 효과
- sns.countplot()
먼저 dataframe을 선언해준다.
vote_df = pd.DataFrame({"name": ['Andy', 'Bob', 'Cat'], "vote":[True, True, False]})
vode_df| name | vote | |
|---|---|---|
| 0 | Andy | True |
| 1 | Bob | True |
| 2 | Cat | False |
# in matplotlib barplot
vote_count = vote_df.groupby("vote").count()
vote_count| name | |
|---|---|
| vote | |
| False | 1 |
| True | 2 |
plt.bar(x= [False, True], height = vote_count['name'])
plt.show()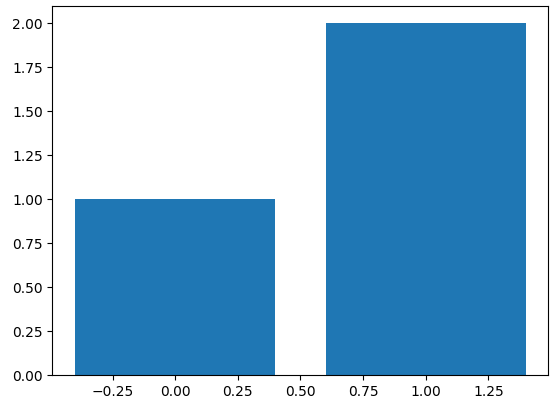
물론 이렇게 진행해도 되지만, Seaborn을 이용할 수도 있다.
sns.countplot(x = vote_df['vote'])
plt.show()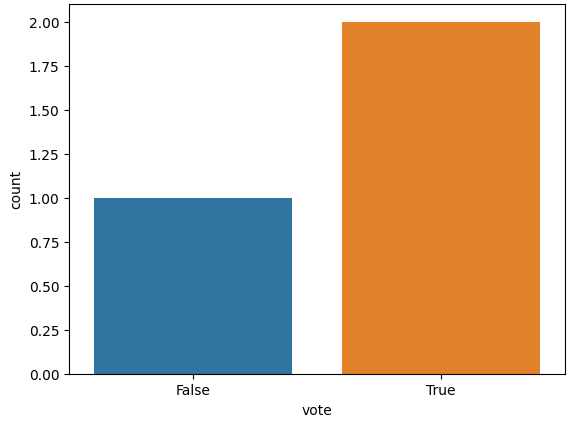
❗️캣그림(Cat Plot)
- 숫자형 변수와 하나 이상의 범주형 변수의 관계를 보여주는 함수
- sns.catplot()
school = pd.DataFrame({"name": ['Andy', 'Bob', 'Cat'], "age":[22, 21, 24], "from":['Bucheon','Incheon', 'Seoul'], "gpa":[3.24,4.1, 4.4]})
school| name | age | from | gpa | |
|---|---|---|---|---|
| 0 | Andy | 22 | Bucheon | 3.24 |
| 1 | Bob | 21 | Incheon | 4.1 |
| 2 | Cat | 24 | Seoul | 4.4 |
sns.catplot(x='name', y='gpa', data=school) # x,y,data 선언 필수
s.fig.set_size_inches(10, 6) # figsize조절
plt.show()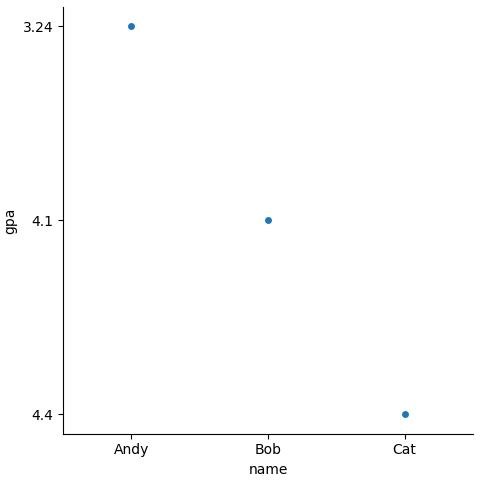
catplot은 굳이 의미하면 여러 data plot의 집합체라고 생각하는것이 편하다.
위의 그래프는 기본적으로 kind = 'strip'으로 선언되어있다.
sns.catplot(x='name', y='gpa', data=school, kind='violin') # x,y,data 선언 필수
s.fig.set_size_inches(10, 6) # figsize조절
plt.show()
위처럼 'violin'형태로 그려줄 수도 있다.
❗️스트립그림(Strip Plot)
- scatter plot과 유사하게 데이터의 수치를 표현하는 그래프
- sns.stripplot()
- sns.swarmplot()
sns.stripplot(x='name', y='gpa', data=school)
plt.show()
sns.swarmplot(x='name', y='gpa', data=school)
plt.show()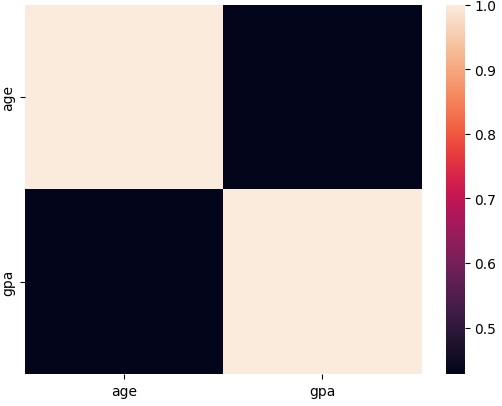
stripplot과 swarmplot을 이용해서 scatter plot처럼 그릴 수 있다.
❗️히트맵(Heatmap)
- 데이터의 행렬을 색상을 표현해주는 그래프
- sns.heatmap()
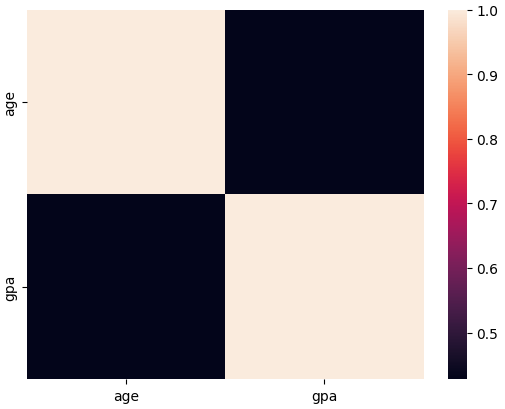
heatmap을 가장 많이 사용하는 예시는 상관계수행렬이다.
먼저 앞서 사용하던 school 데이터를 상관계수로 불러오기 위해 corr()를 사용한다.
school.corr()
school| age | gpa | |
|---|---|---|
| age | 1.00000 | 0.42766 |
| gpa | 0.42766 | 1.00000 |
sns.heatmap(school.corr())
plt.show()