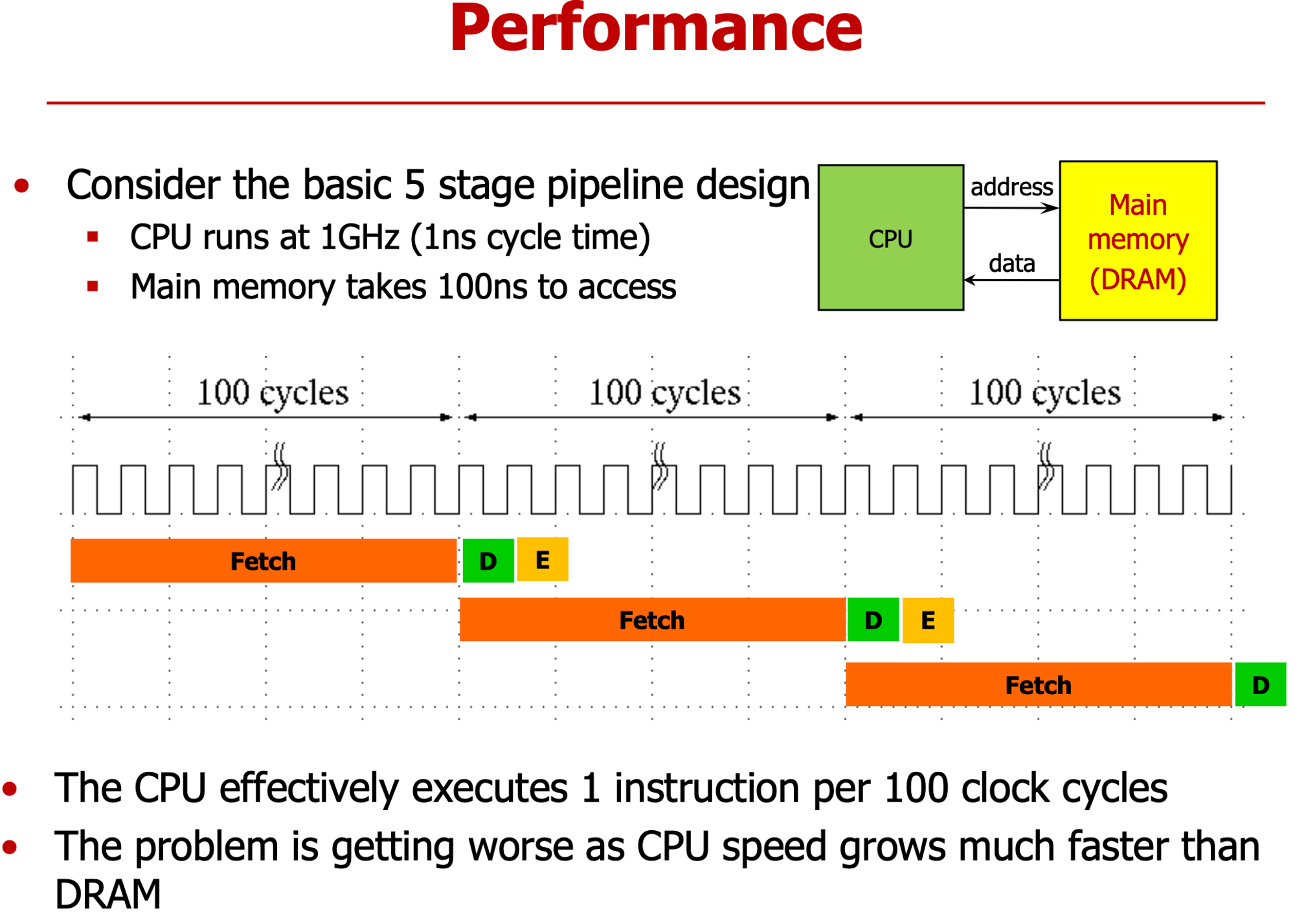
- Memory 접근 시간 오래 걸려 → IF Stage에 100cycle 소요 == CPI =100
- CPU와 메모리 사이 성능 차이 커지면 성능 악화
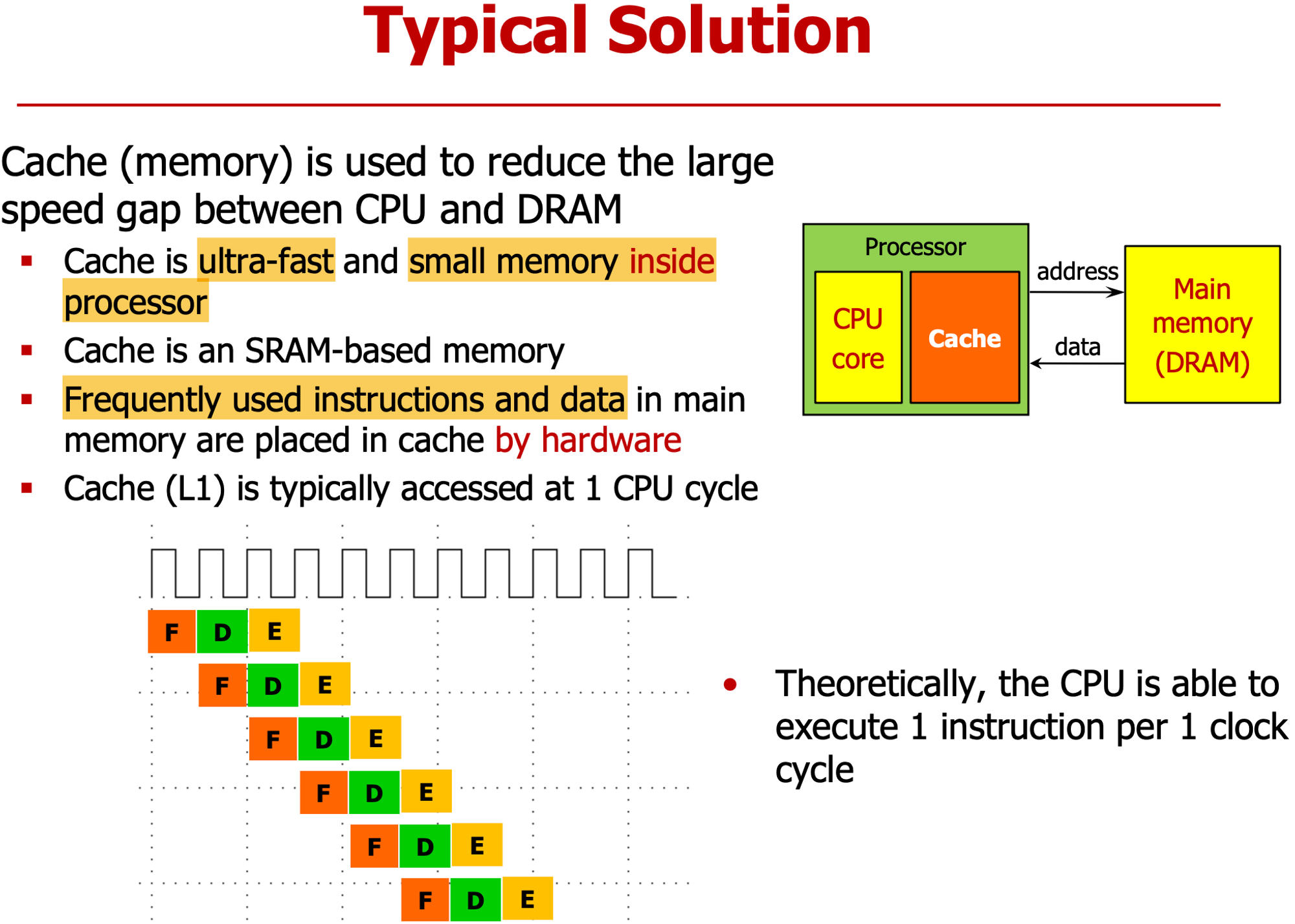
- 그 차이를 줄이기 위해 CPU에 cashe 달았다.
- 자주 사용되는 명령어와 데이터 저장
- H/W에 의해 운영, S/W로 제어 불가
- Cashe 제어라함은 프로그래머가 자주 쓰는 명령어,데이터 선정해 저장하는 것
- L1 Cashe : 1 cycle에 fetch 가능
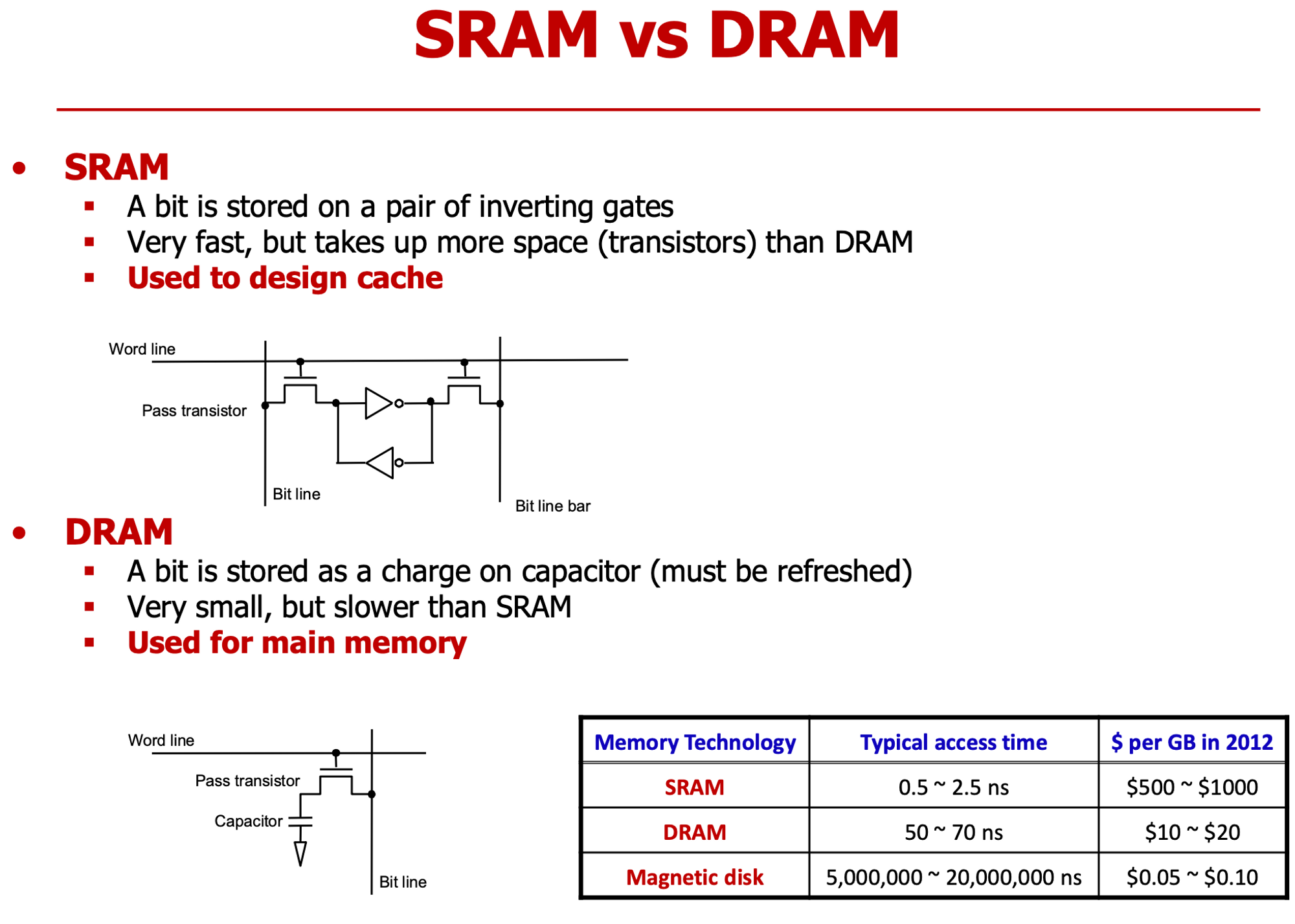
SRAM
- Cross-Coupled Inverter
- 트랜지스터 기반의 Positive-Feedback
DRAM

- DL1 : data cashe, IL1 : Instructon cashe
- 데이터를 위한 캐시, 명령어를 위한 캐시 구분
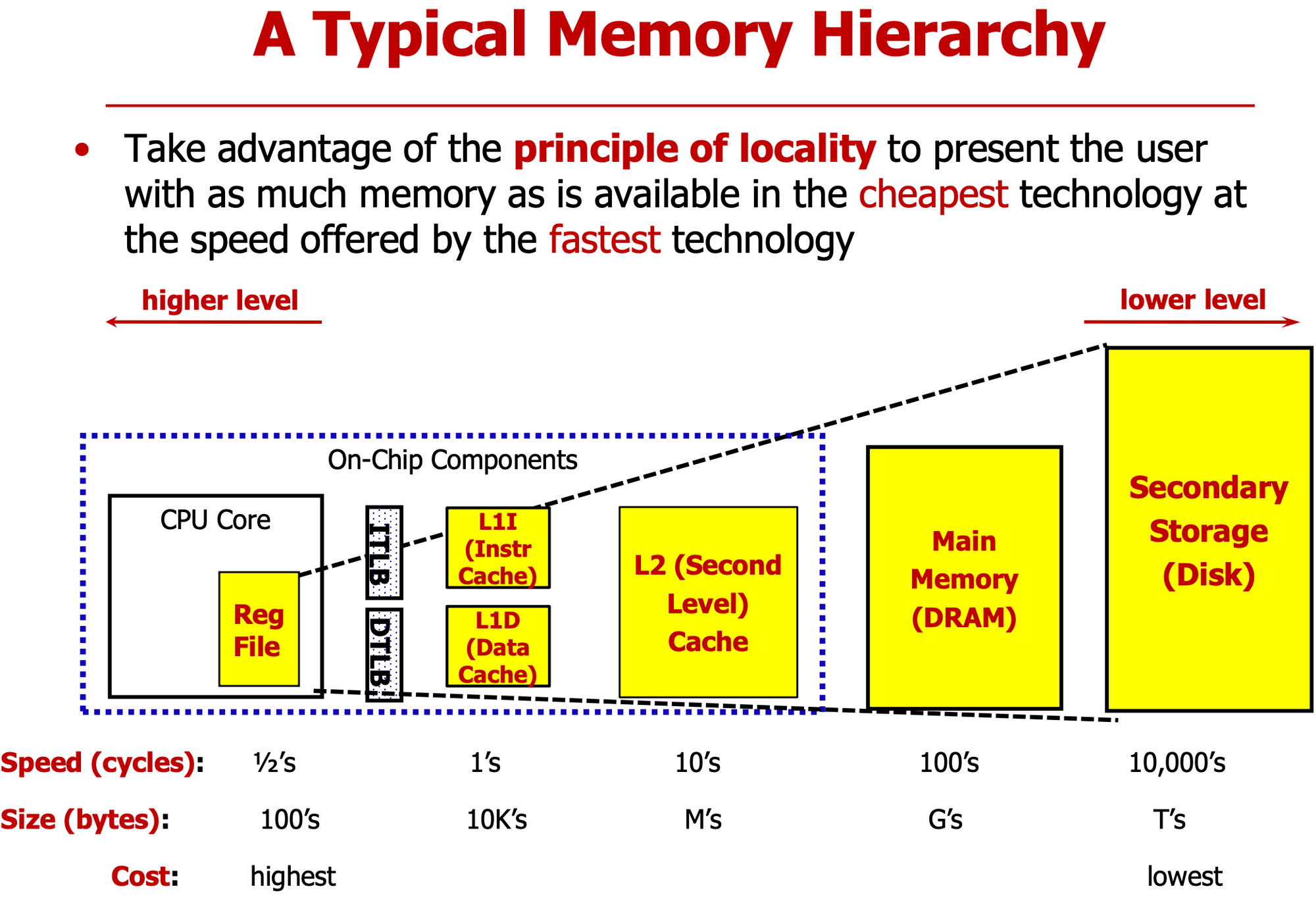
- 처리시간과 용량은 비례관계
- Principle of Locality
- 비용 → 용량 큰 메모리, 속도 → 용량 작은 메모리
- L1 Cashe를 L1I, L1D로 따로 설계해 Structure Hazard 예방
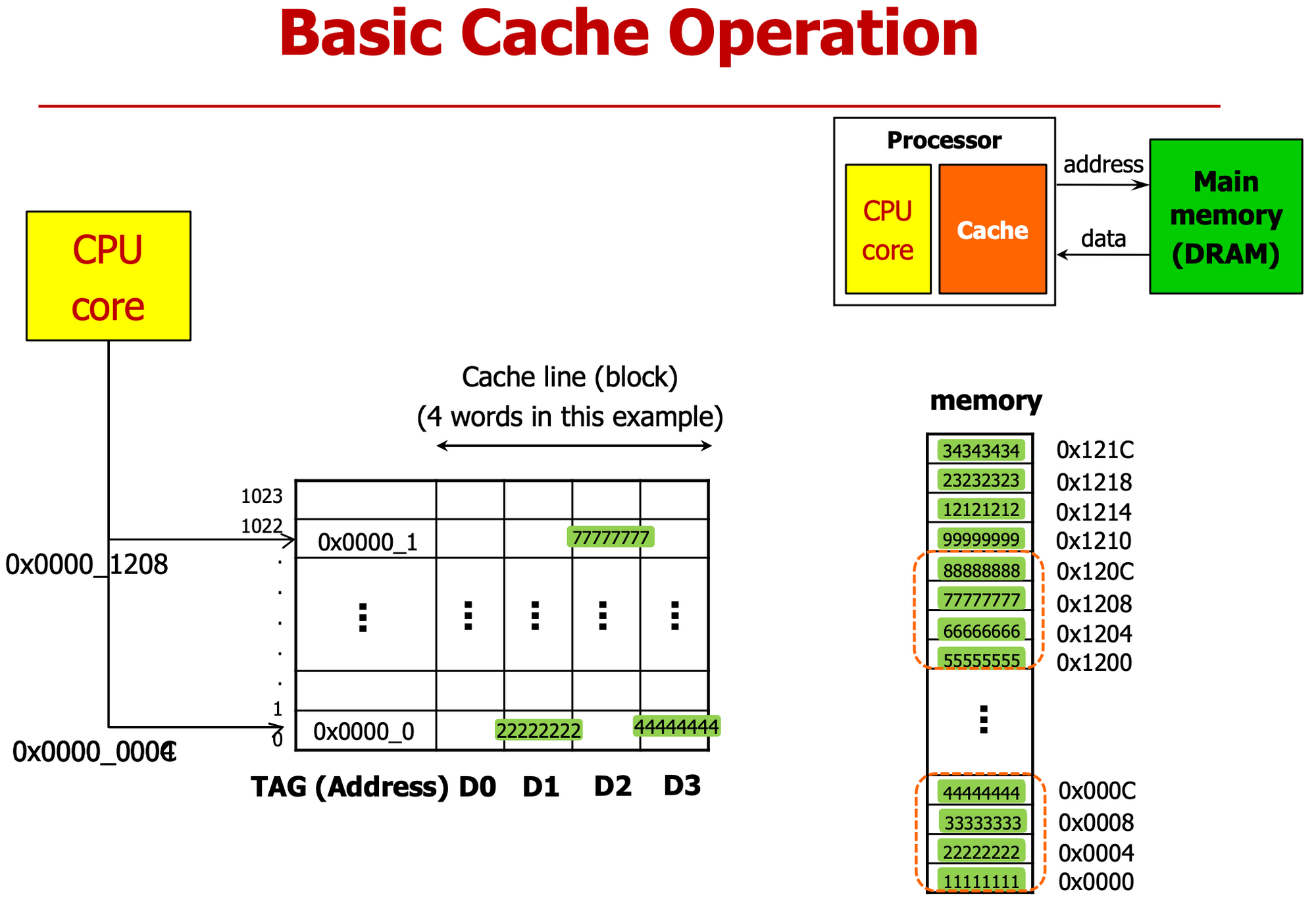
- D0 D1 D2 D3에 word 하나 씩 저장 가능, 즉 전체는 4개 word를 1024묶음 저장 가능
- TAG는 주소와 비슷
- Cashe Line : 4개 word 저장하는 Row, 즉 Cashe line이 1024개
- 하나의 데이터가 1word, 주소값도 4씩 증가
- CPU Core가 0x0004의 0x2222_2222 요구
- Cache가 메모리에서 받아
- 0x2222_2222 뿐만 아니라 하나의 cache line codnrl dnlgo 4개 words 다 가져온다
- 0x1111 ~ 0x4444
- 1번 이후 CPU Core가 0x000C에 위치한 데이터(0x4444) 요구하는 경우
- 이미 cache가 보유하고 있어서 전달 가능
- 이것이 Locality를 활용한 성능향상 예시이다.
- 1,2번 이후 CPU가 0x1208 위치한 데이터 (0x7777) 요구 시
- 이전에 cache가 load한 적 없어 → 메인 메모리에 요청
- 해당 데이터의 Locality Data (0x5555 ~ 0x8888) 모두 전송

Temporal Locality (Time)
- 특정 메모리 주소 접근할 때, 빠른 시간내에 다시 접근할 확률 높다 → 최근에 접근했던 데이터 cache에 저장
Spatial Locality (Space)
- 특정 메모리 주소 접근할 때, 해당 주소 근처 데이터 다시 접근 확률 높아 → cache block 가져올 때 여러 word 데이터 가져와

- D는 100회 접근. Cache가 D를 저장해놓으면 메모리 접근 99번 안해도 됨 (Temporal)
- A,B,C 차례대로 요청. 하나의 배열 데이터 요청 시 한꺼번에 가져오는 게 효율적 (Spatial)

Block
- cache - DRAM 사이 주고받는 데이터 최소 단위
- 현재 대부분 64bytes
Hit
- 요청한 데이터가 cache에 있는 경우
- Hit → 성능 향상
- Hit Rate : Hit 일어날 확률
- Hit Time : Hit 발생 시 cache에 접근하는 시간
Miss
- 요청한 데이터 cache에 없는 경우
- Miss → 메모리에 접근해야 해 시간 소요
- Miss Rate
- Miss Time
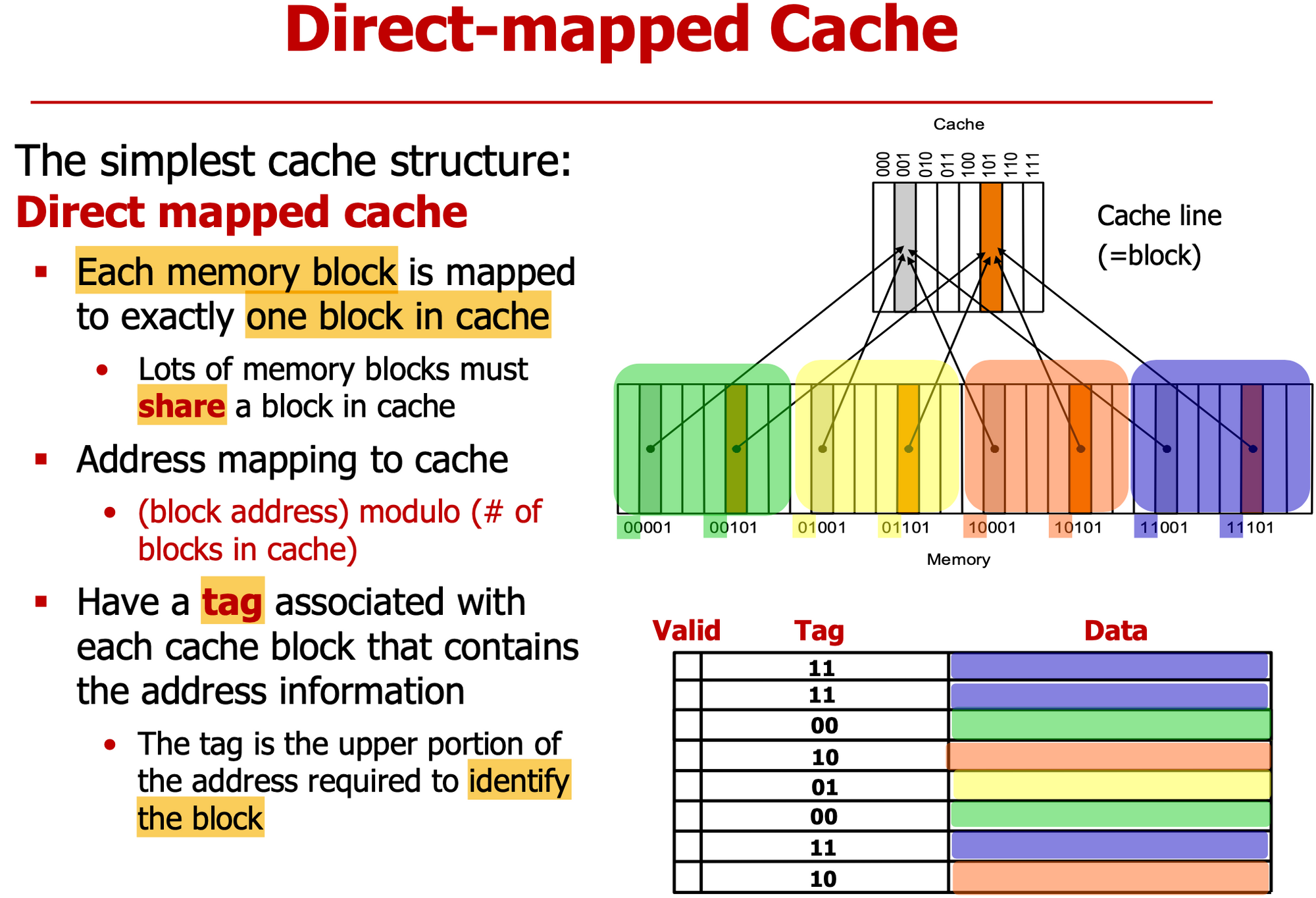
Direct-mapped cache
- 메모리의 특정 block이 cache 저장될 위치가 정해져있다
- cache는 작으므로 여러 메모리 block이 cache block을 공유한다
- block address % cache block 개수
- 그림과 같이 cache line이 8개로 이루어져 있으면 하위 3bits로 어느 Line에 저장됐는지 알 수 있다
- Tag : 메모리 block 구분하기 위해 상위 bits를 cache에 저장한다
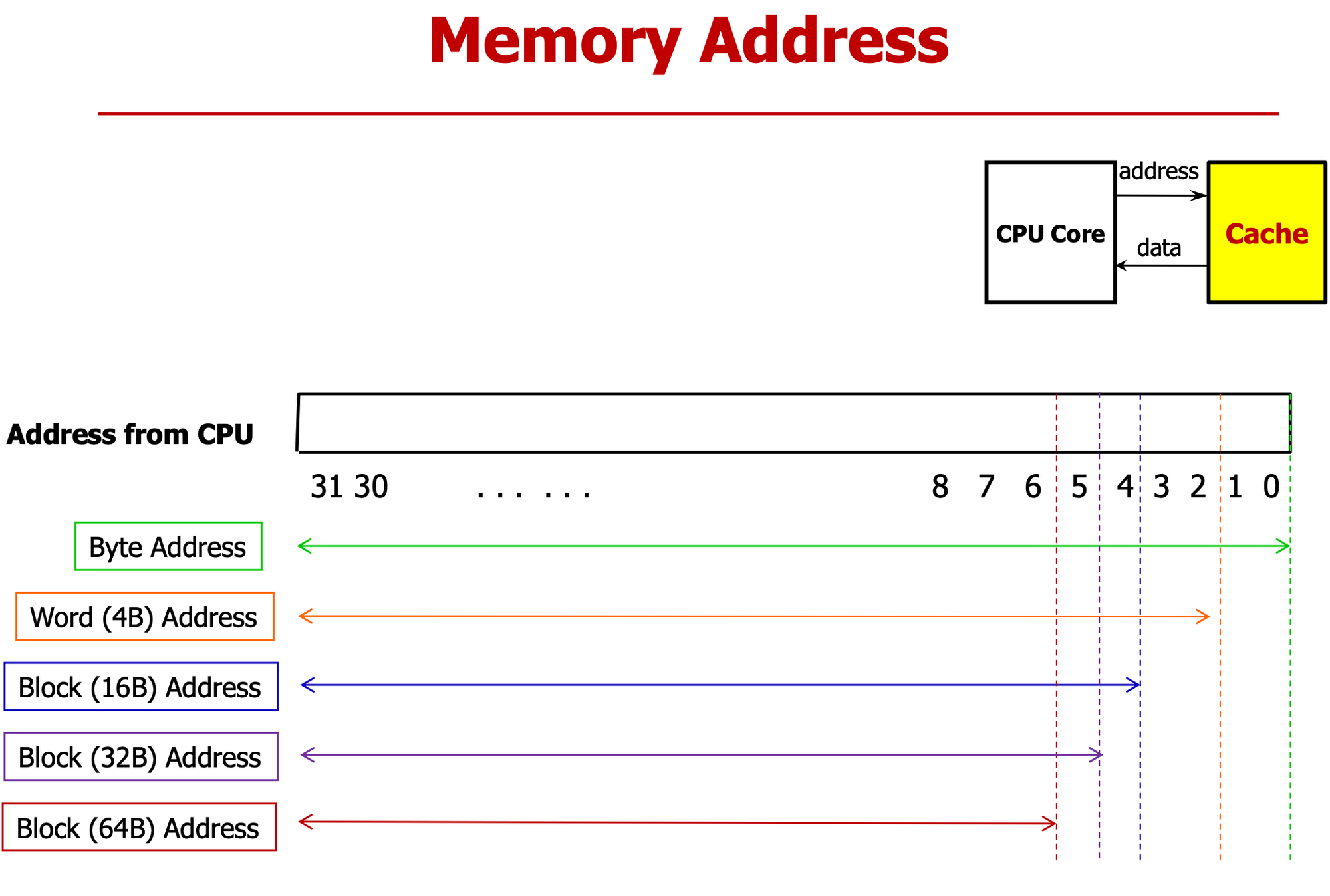
- Word-Address는 Byte-Address에서 하위 2bit를 Chopping(1 Word = 4Bytes)
- Block-Address는 Byte-Address에서 하위 6bit를 Chopping(1 Block = 64Bytes)
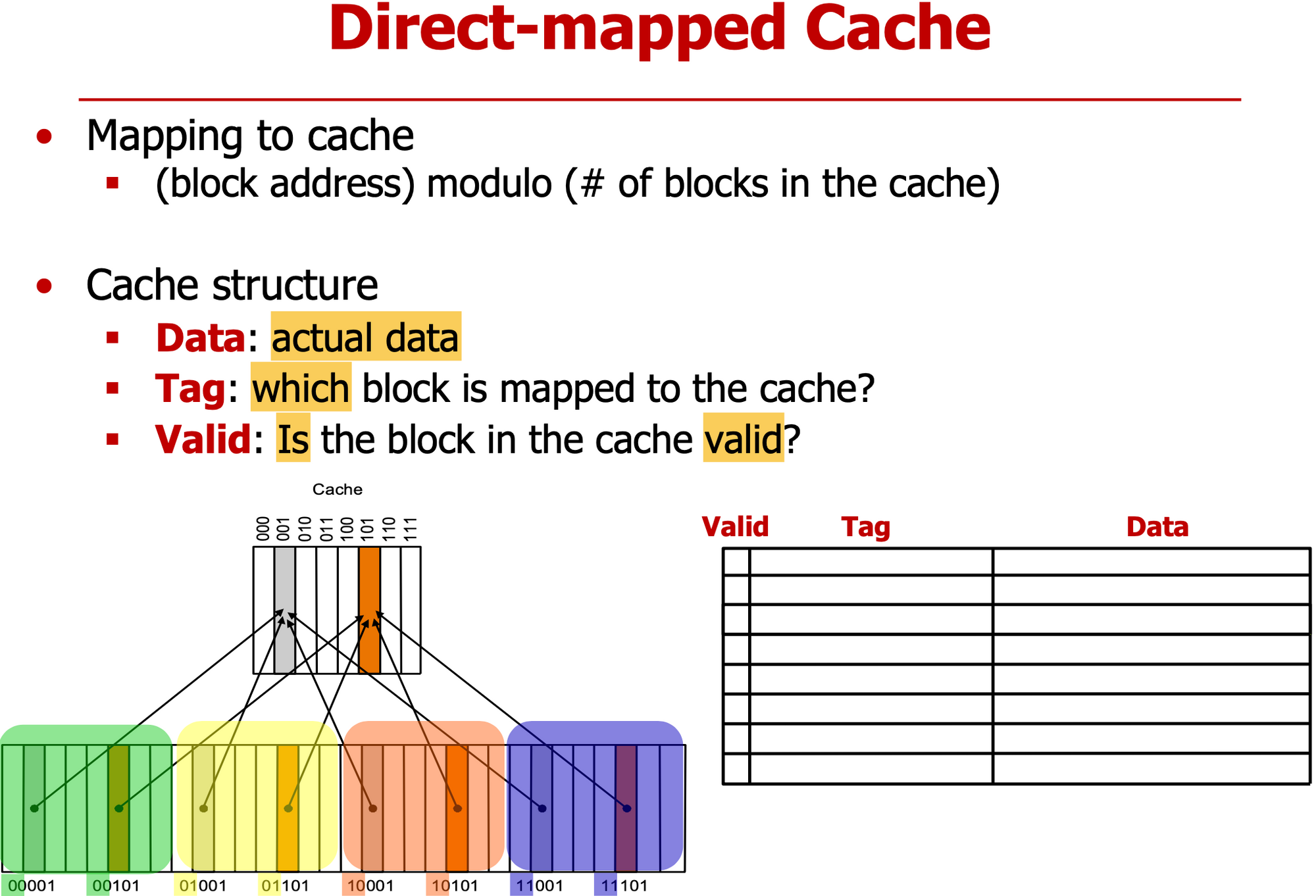
- Data
- cache에 저장된 실제 데이터
- Tag
- 메모리의 어느 주소와 mapping 되어 있는지
- Valid
- 쓰레기 값이 아닌 cache와 메모리 사이의 상호작용을 통해 저장된 데이터인지
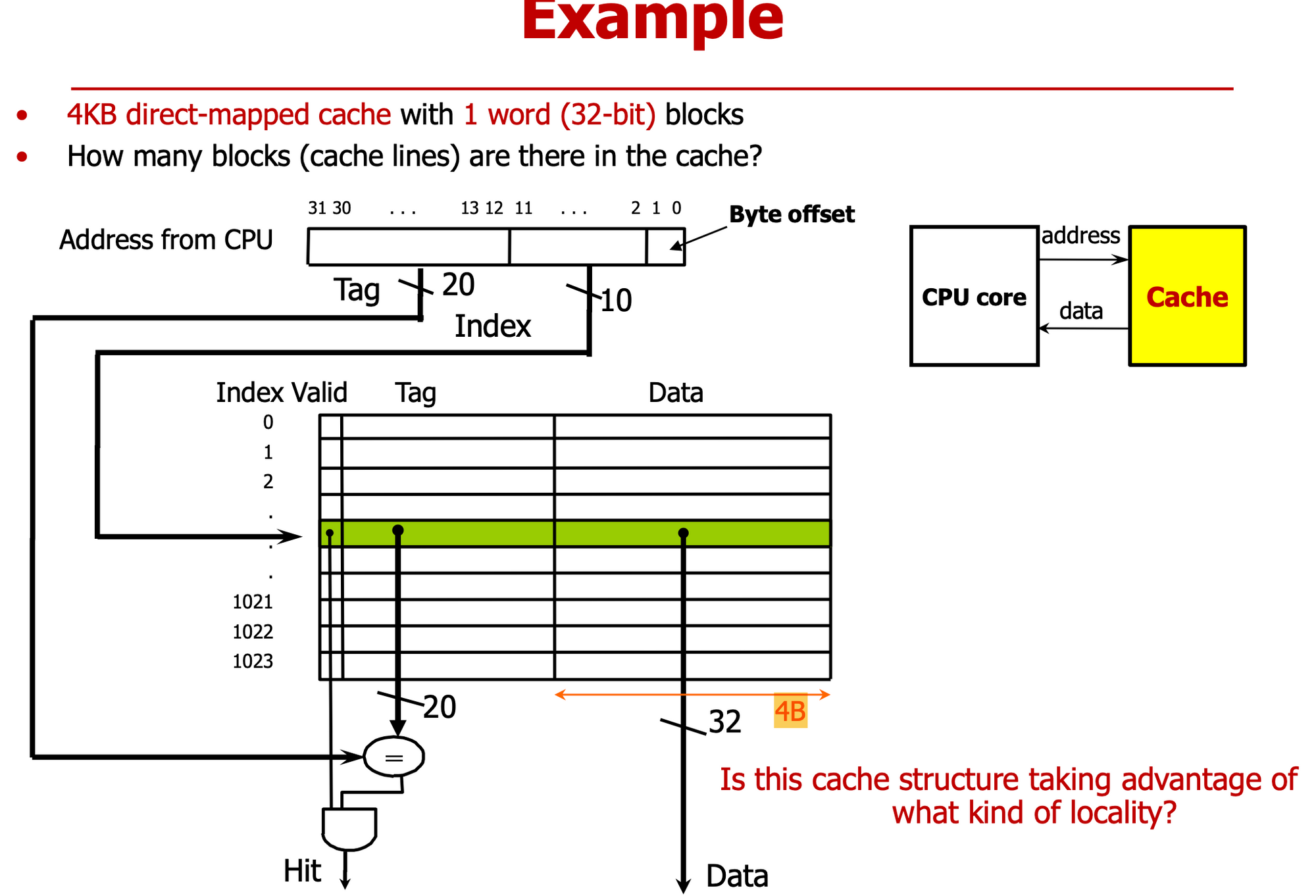
-
4KB Cache는 1024개 word cache line으로 구성되어 있다
- 4KB = 데이터의 용량
-
Byte offset (2bits)
- Word 단위 데이터 Byte로 구분하기 위해
-
index (10bits)
- 1024개 cache line 구분
-
Tag (20bits)
- 중첩된 데이터를 구분
-
vaild bit가 1이어야 정상 데이터
-
is this taking advantage of what kind of locality?
→ Temporal (Cache를 사용하면 무조건)
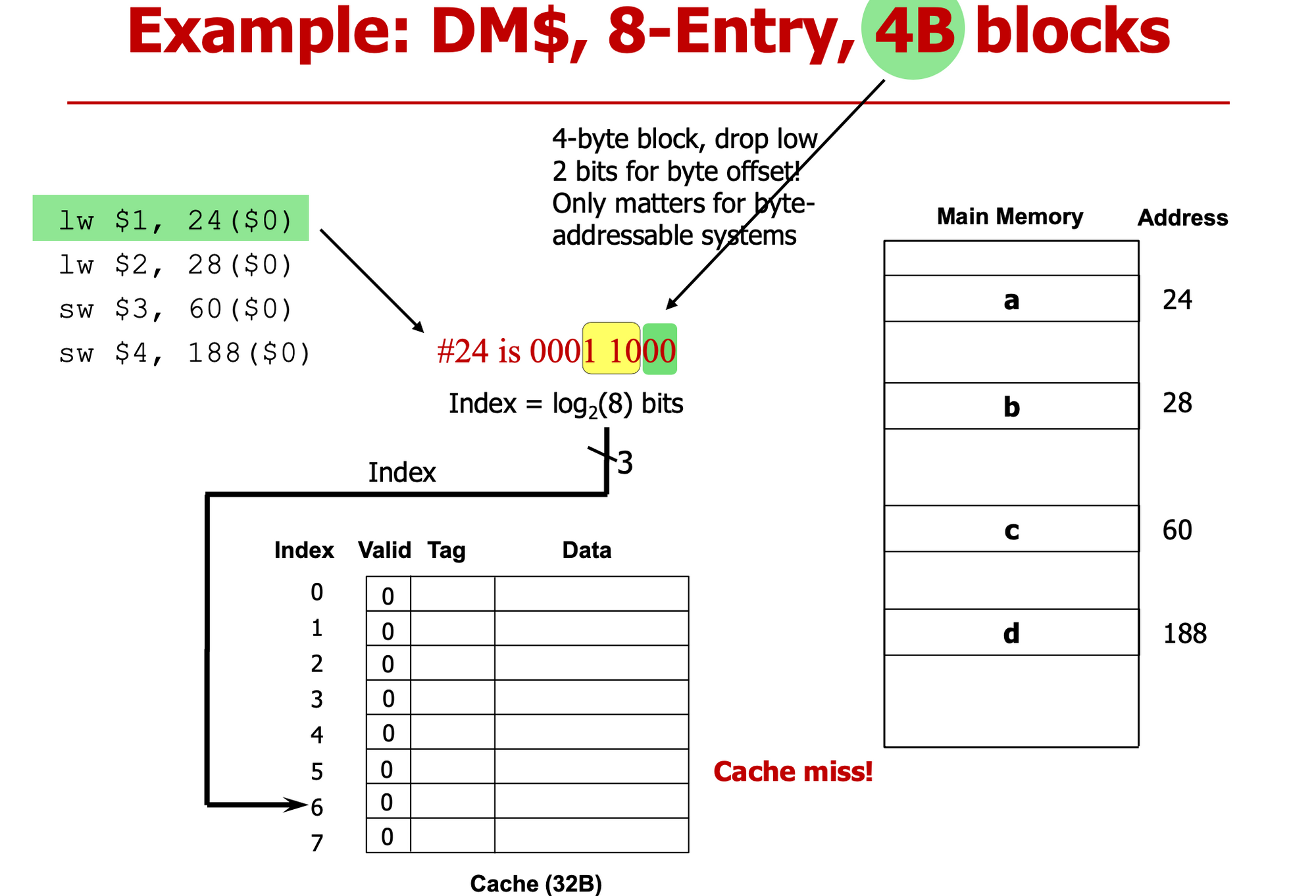
- 0001 1000 : byte address → byte offset 2bit ⇒ 000 110 : block address
- 하위 3bit : index, 상위 bit: Tag
- valid = 0 → Miss
- Main memory 가서 block 읽어와 & Tag 채워 (상위bit) & valid =1 세팅 ⇒ cpu에 전달
000 111 00
→ 000 111
valid =0 miss …

- Write(sw) 할 때는 여러 고려사항 있다
- 001 111, index : 7 → valid=1, But Miss (∵ Tag 달라)
write 어떻게 진행할 건지 선택
- $3을 메모리 60번지에 직접 써 (cache 연동X == write no-allocate)
- 메모리에 있는 값 가져와서 Cache에 써 (cache 연동 O, write-allocation)
- c를 cache에 가져와, tag 바꿔, $3을 cache에 써
- 그러면 cache - memory 값 달라지게 된다 → 언제 값을 쓸지 선택
- 나중에 replace 할 때 써 ⇒ write back → Dirty bit 필요
- dirty bit = 1 : 아직 Update 안됐다 (cache - memory 값 다르다)
- 나중에 replace 할 때 써 ⇒ write back → Dirty bit 필요

- 101 111 → 60과 공유, tag가 달라 ⇒ Miss
- 기존에 cache 있는 값 방출해야
- 이때 dirty bit=1 : main memory에 replace 해야 돼 → 이전에 60번지에 update 안한 값 지금 쓴다.

- 마찬가지로 cache에만 쓰고 메모리는 값 변경 안했어 → dirty bit = 1 세팅

Read-Hit
- CPU가 읽고자하는 데이터가 이미 Cache에 존재
- CPU가 Cache에서 읽어오면 된다
Read-Miss
- 원하는 데이터가 cache에 없다
- 메모리에서 원하는 block을 읽어와 cache에 저장하고 cache에서 CPU로 데이터 전달
Write-Hit
- CPU가 쓰고자하는 데이터가 이미 Cache에 옮겨져 있다
Write-Miss
- Write Allocate ↔ Write-back
- Write no-Allocate ↔ Write-through
-
Write Allocate
- 메모리에서 cache로 옮기고, CPU가 cache에 접근해서 데이터
-
Write No-Allocate
- 연동 X, CPU가 메모리에 직접 쓴다
-
Write-Back
- Cache에는 값을 쓰는데, lower level cache나 메모리에는 아직 쓰지 않는다
- 추후에 cache에 있는 block이 replace(방출,교체) 될 때 update 한다 (dirty bit 필요)
-
Write-Through
- Cache와 메모리에 동시에 update한다 (그냥 다 써)
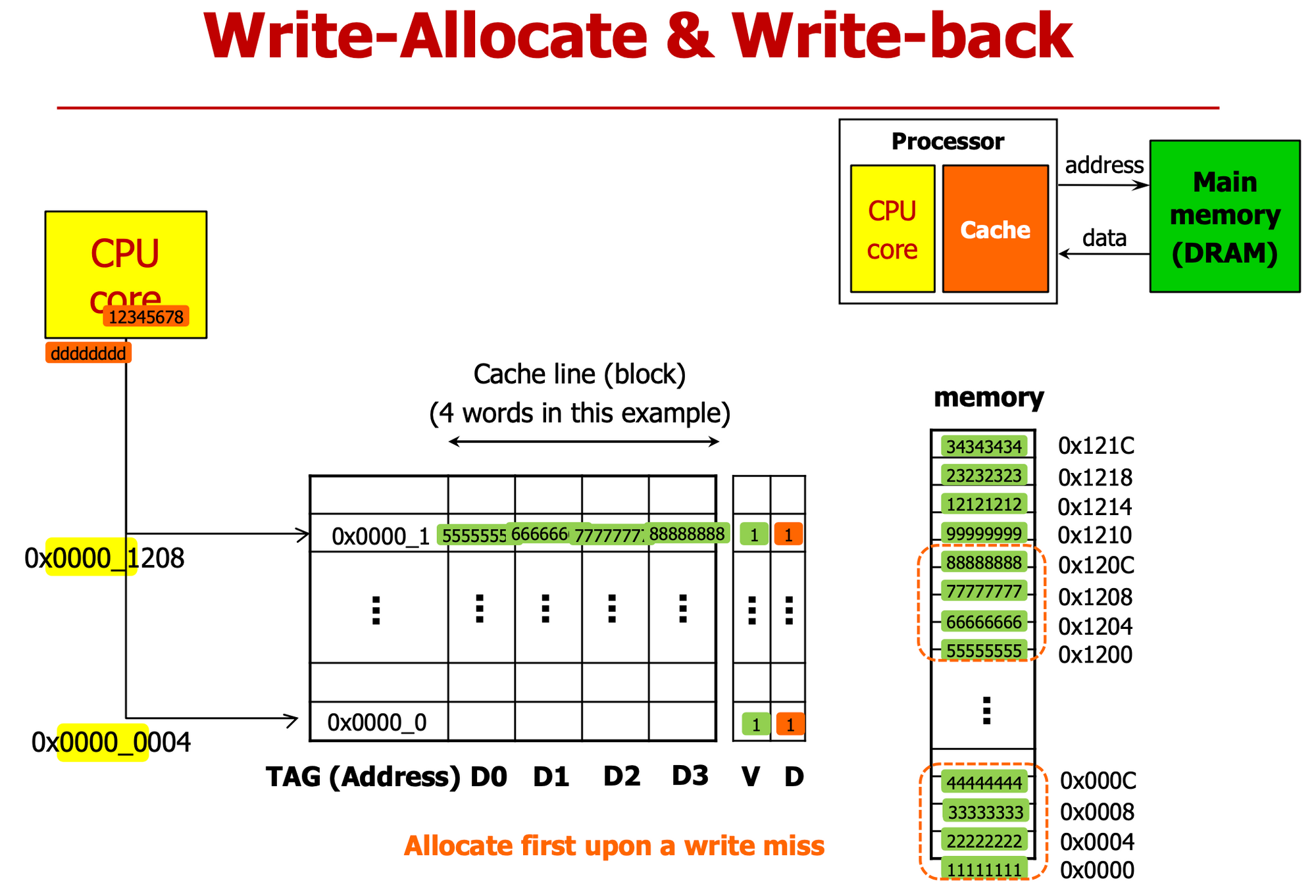
- 4 words in a block == 근처 값 같이 가져왔어 → Spatial Locality 고려했다
- 쓰기 동작 하려는 데 Cache Hit
→ 0004 할 때, 1111~4444 다가져와, d1에 dddd 넣고(cache에만 쓰고) dirty bit 1로 세팅,
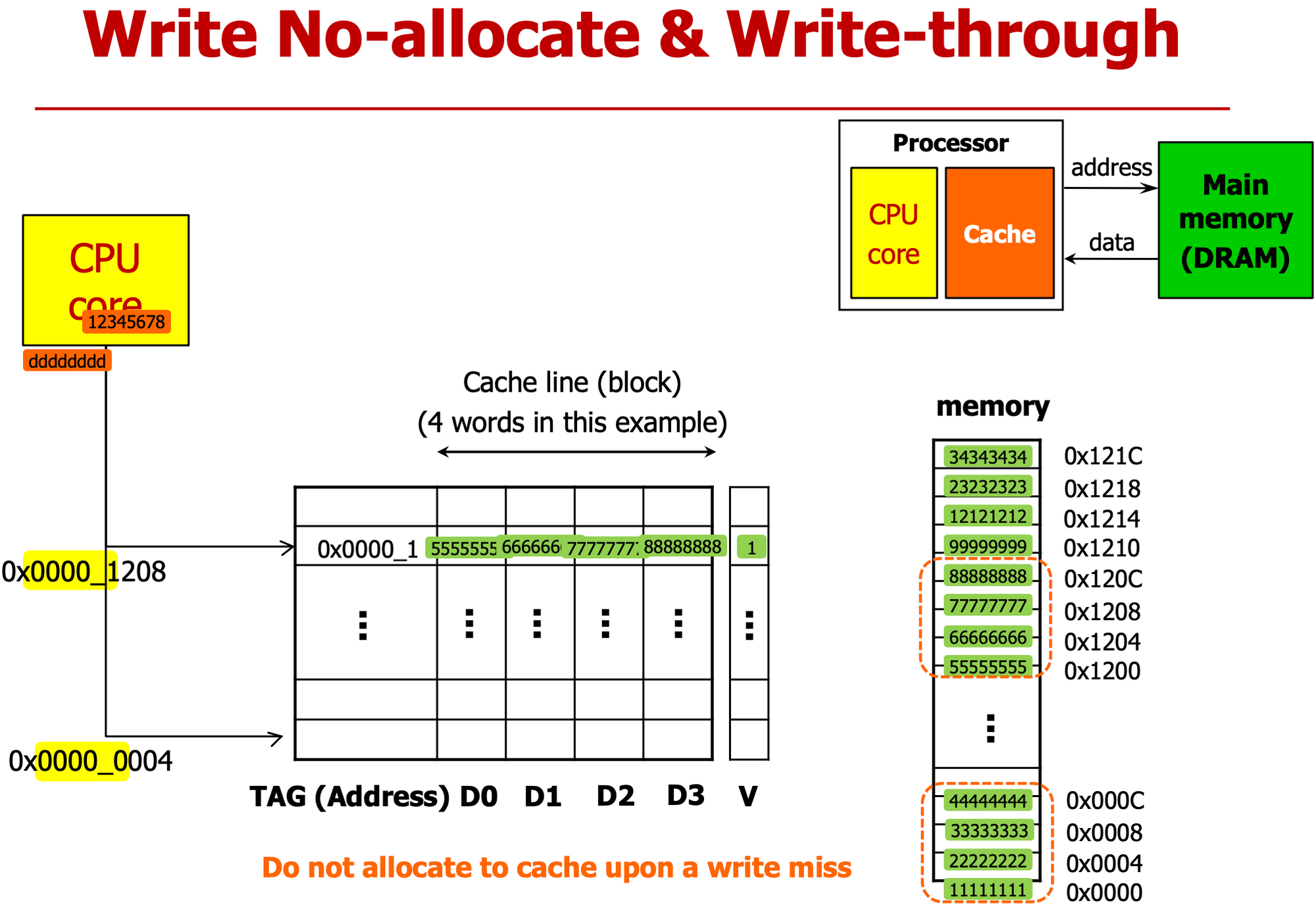
- write through - dirty bit 없어

- write t : cache memory 둘 다 써버려
- write b : cache에만
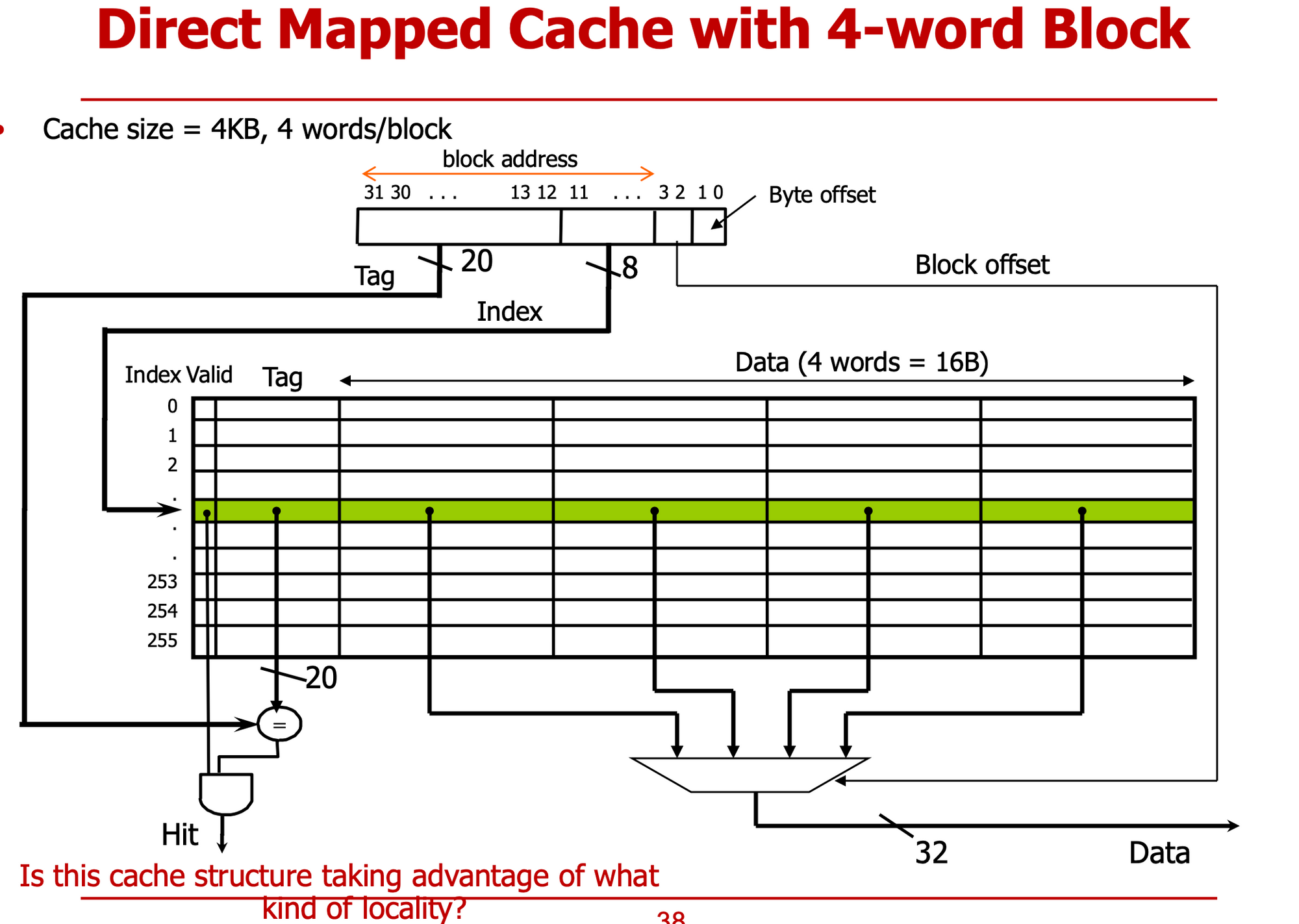
- 4-word block == 한 block에 word 4개
- 2bit 떼어내 → word addreess
- 16 bytes * index = 4kb ⇒ index = 256 (8bit)
- Block offset : word→block
- 각각의 block에 대해 block에 있는 word 4개 중 어떤 word인지 나타낸다
- temporal , spatial locality 모두고려 했다.
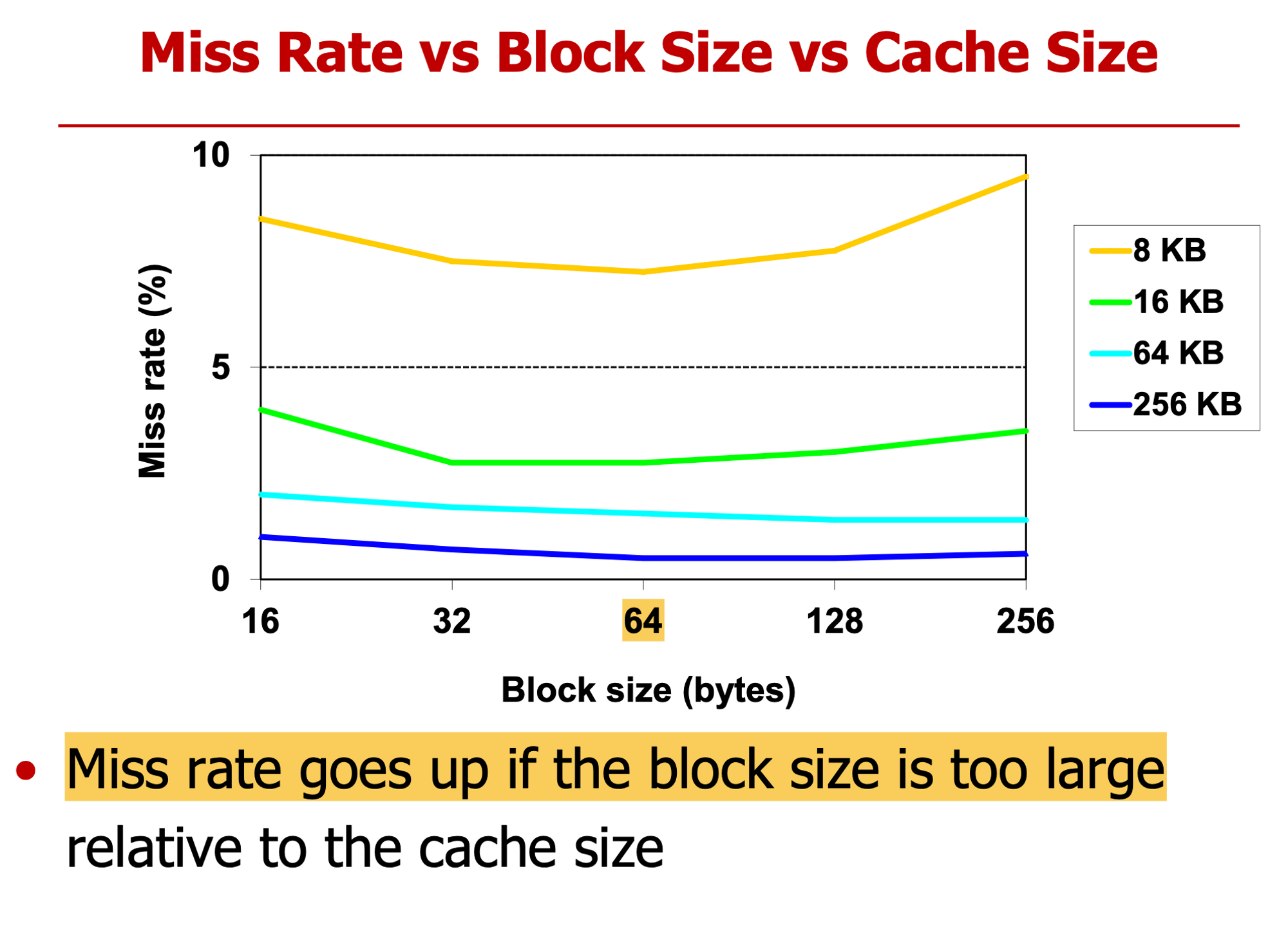
- Miss Rate을 낮추는게 중요
- 크기 클수록 miss rate 낮다
- block size 너무 커지면 성능 하락
- 너무 한 번에 많이 가져오면 기존에 있는거 교체 가능성 올라가기 때문에

- 4 word(16b), 16kb data → index =10bit (1024)
Lec 16
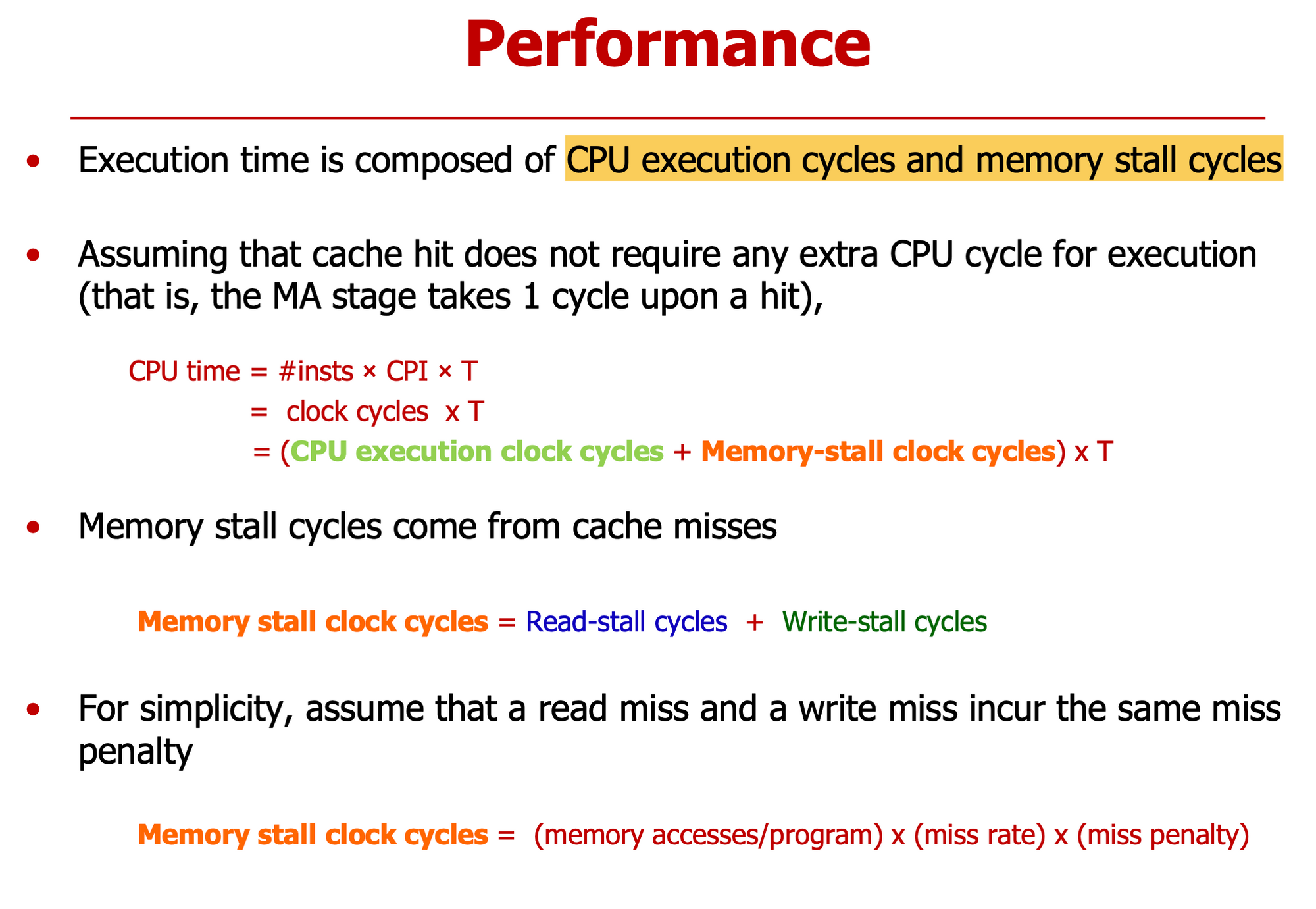
명령어 수 CPI T(cpu cycle)
memory = read stall + write stall
프로그램당 메모리 접근 횟수 * miss rate 만큼 패널티
Miss rate 좋아도 패널티 급증
→ miss rate & miss penalty 줄여야
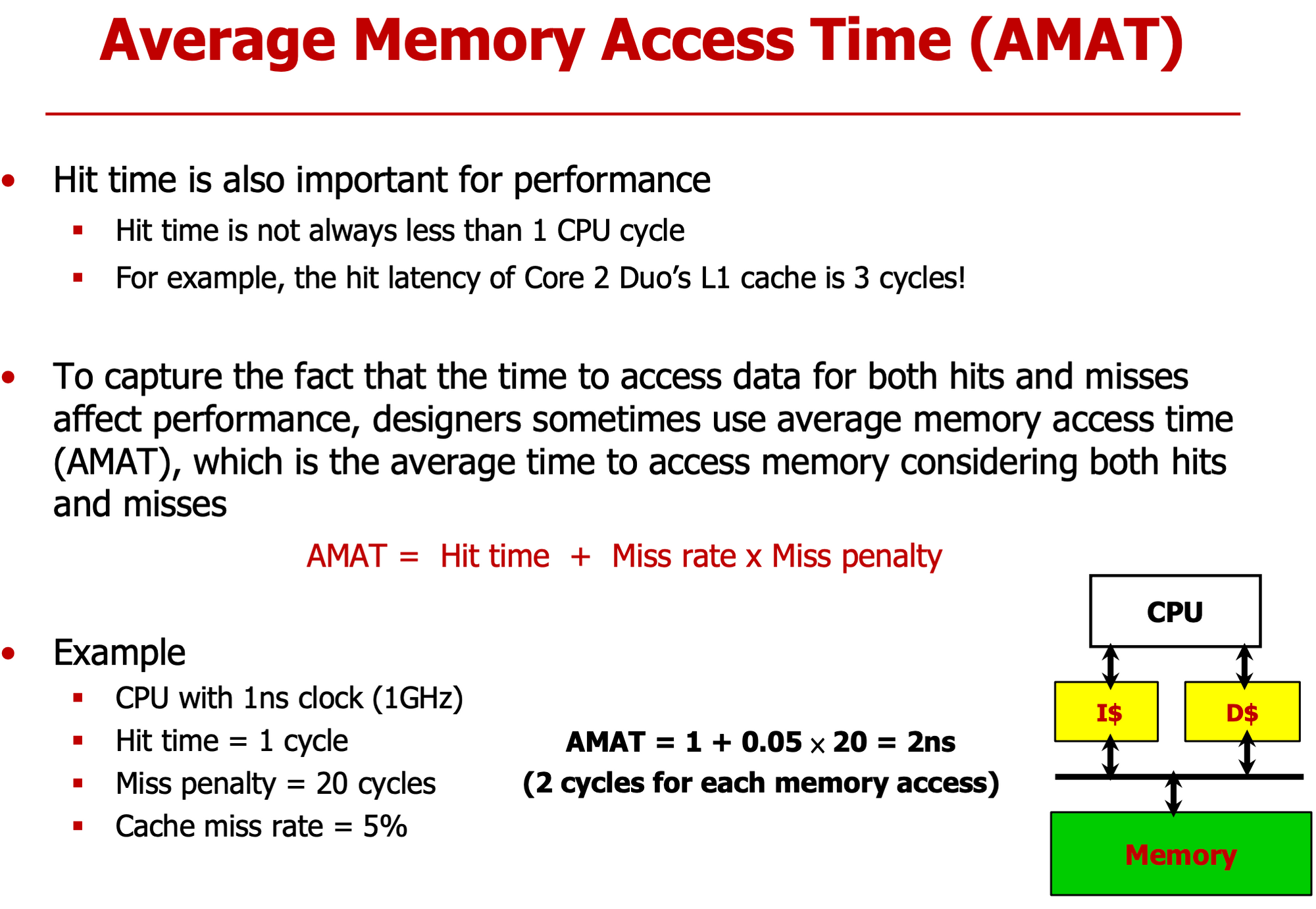
- hit time은 기본
- miss penalty == extra time, 부가적으로 더 걸리는 시간

- cache size를 키우면 cache에 접근하는데 걸리는 시간이 증가해 hit time 시간도 늘어난다
- Miss Rate or Miss Penalty를 줄여야한다

Direct Mapped Cache
- memory와 cache가 일대일 mapping → 하나의 cahce line 공유하기 때문에 Conflict 발생 →Conflict Miss 발생
- one-way
Fully Associative Cache
- cache내의 아무 block에 mapping할 수 있다
- all-way
N-Way Set Associative Cache
- 위 두 형태의 중간
- cache를 여러 set로 나누고, 그 set는 n개 way로 구성된다. n-way
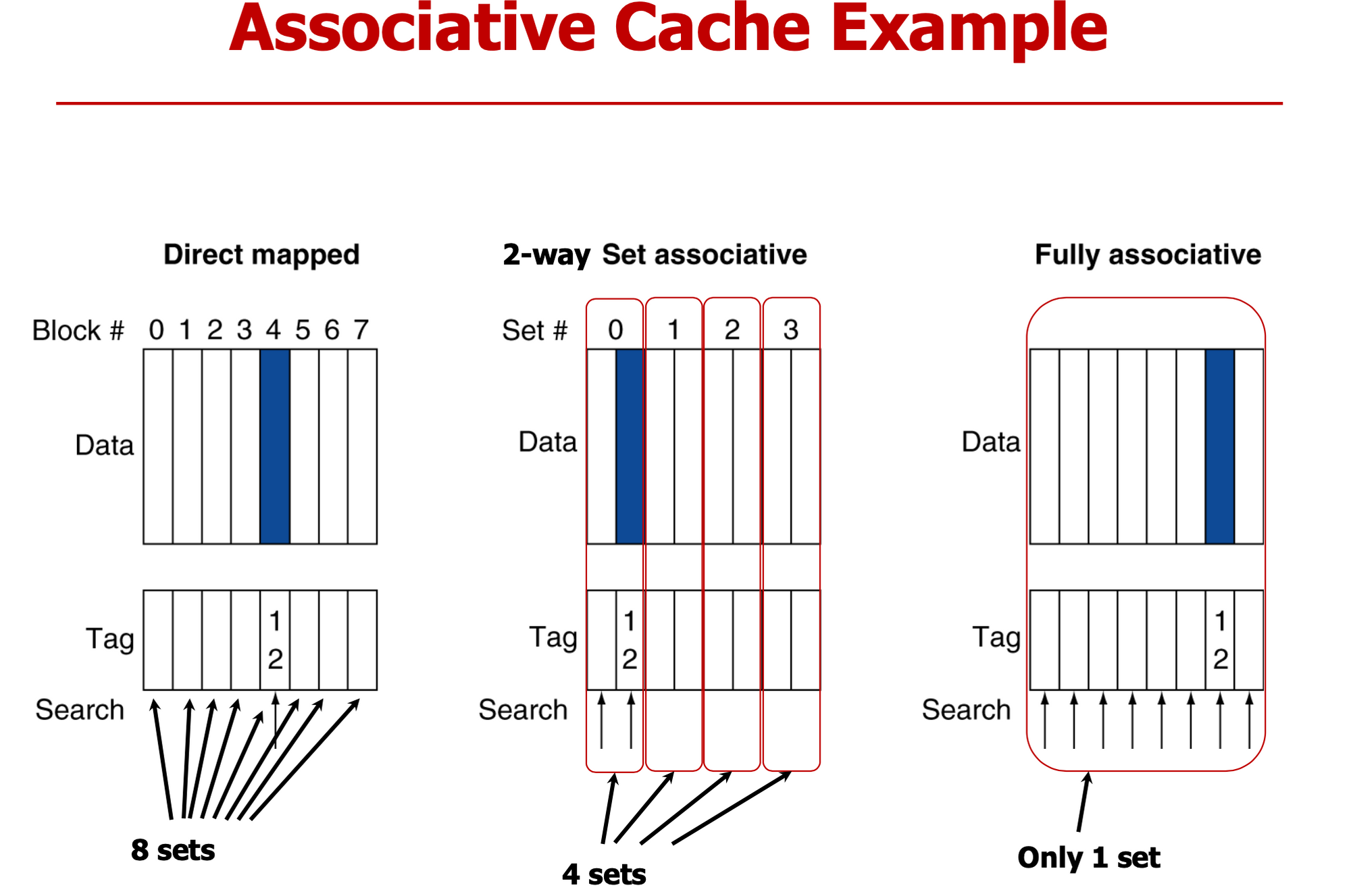
DM
- 한곳만 서치
- 8세트 1웨이
2-way
- set 찾아
- 똑같은 set여도 꼭 방출할 필요없음
- 4세트 2웨이
FA
- set는 1개
- 다 찾아야해
- 1세트 8웨이
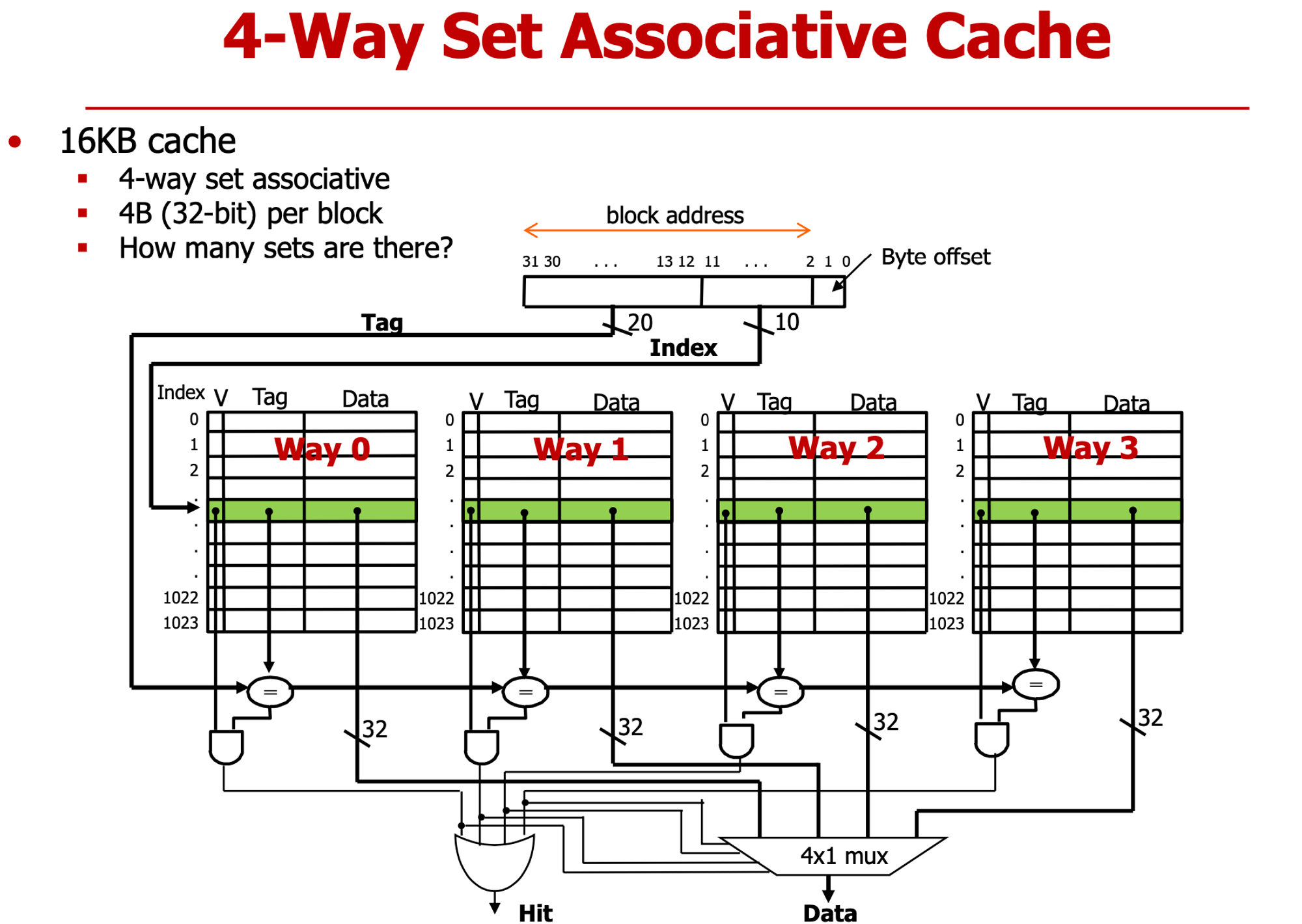
- set당 4 way로 구성, way 당 4바이트, → set는 16바이트 정보 담고 있다.
- cache 크기 16kb ⇒ 1024 sets 필요 → 하위 10bit가 index
- tag일치 하는지 모든 set에서 다 확인 (4번 해야)
- miss면 4개 다 0
- hit면 3개 0 1개 1

- way의 개수가 cache line의 개수와 일치
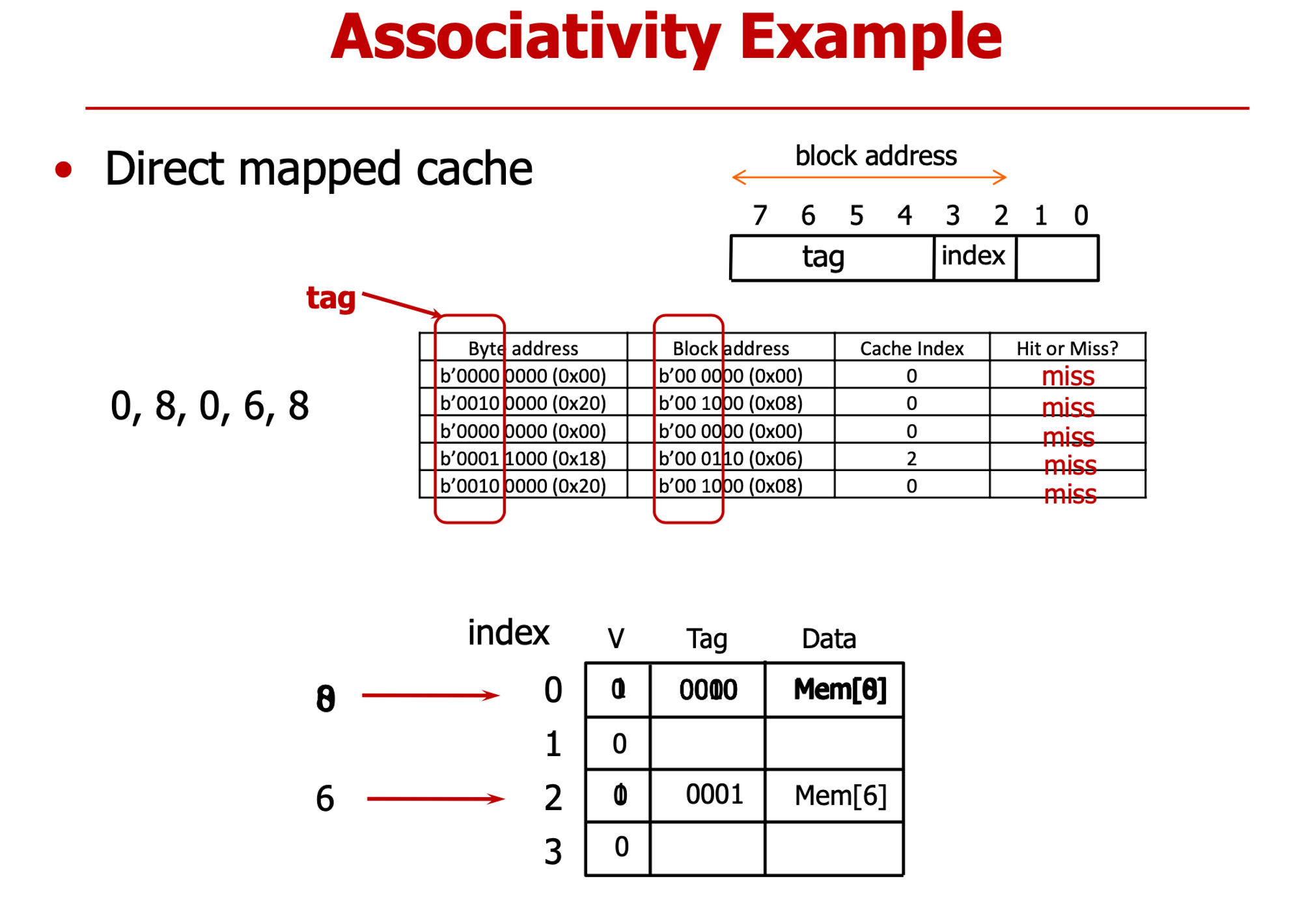
- cache index 0에 자주 접근해 → conflict 가능성 크다
- 첫 0, 8, 6 → cold miss (처음 접근했기 떄문에 무조건 cold miss 발생한다)
- 두번째 0, 8 → Conflict Miss
- 두번째 0: 첫번째 8이 index0을 차지하고 있기 때문에
- 두번째 8 : 두번째 0이 index0 차지
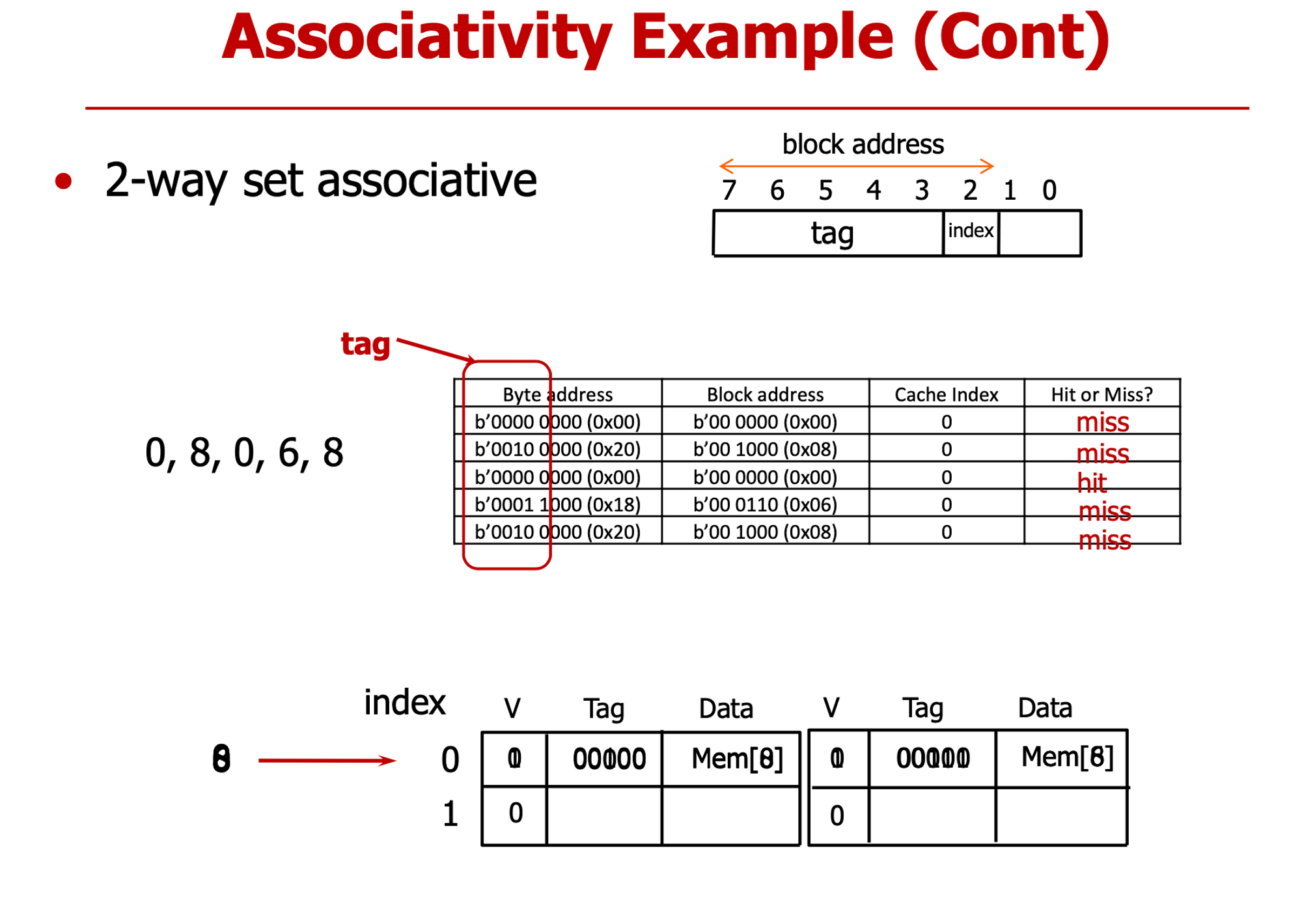
- index에 필요한 비트 수 : 2bit → 1bit
- Tag 비트는 1비트 증가
- 첫번 째 0,8,6 : cold miss
- 6 들어올 떄 index0의 모든 way에 이미 저장되어 있다
- 어떤 걸 방출? → 가장 최근에 사용한(Mostly recent used) 0번을 남겨, 8번 방출해
- 결과 : cold, cold, hit, cold, conflict
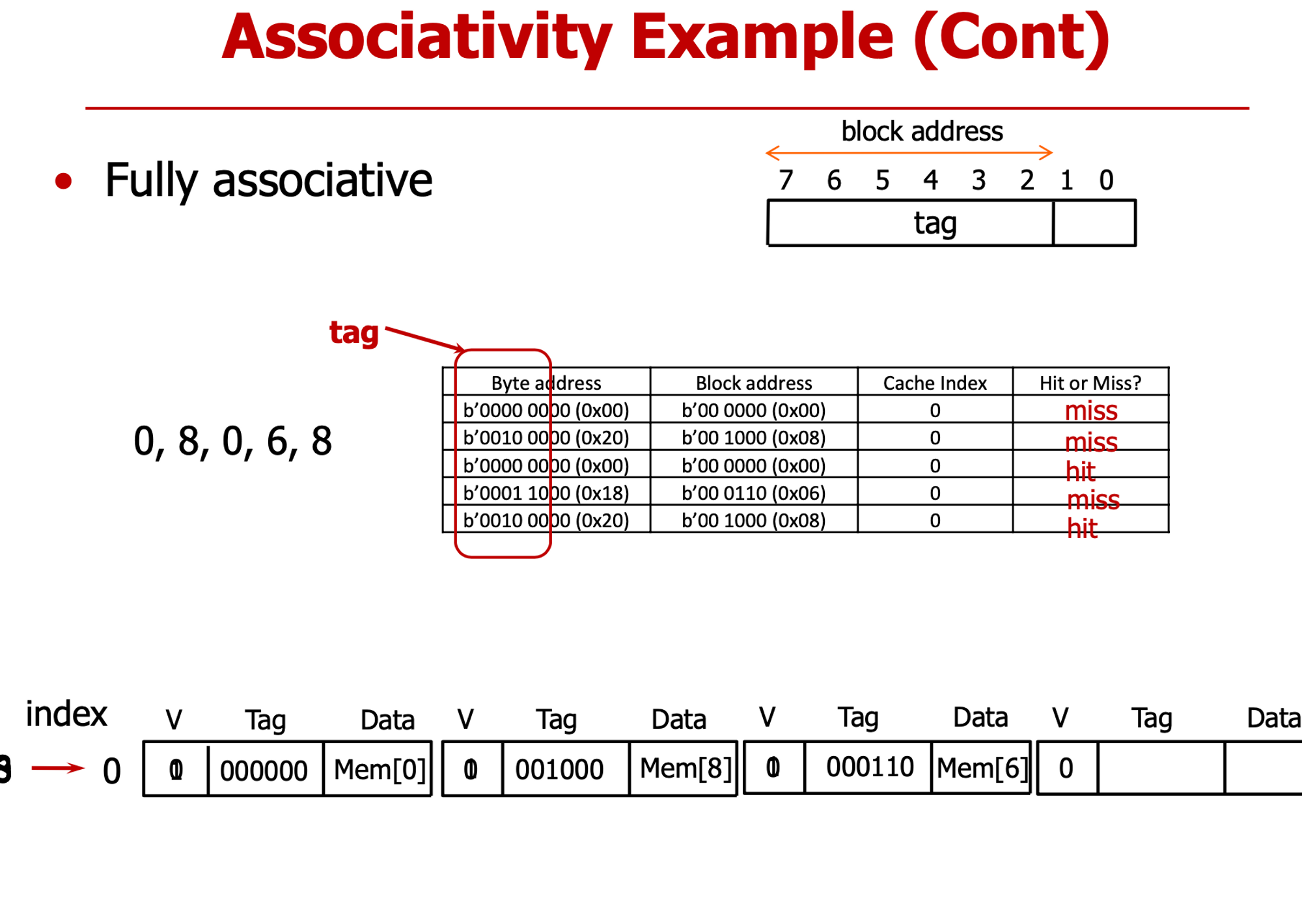
- index 필요 없다 → block address가 tag 그 자체
- 결과 : cold, cold, hit, cold, hit

- Cache 크기는 고정된 상태에서,
- block 2배 증가 & set 절반으로 감소 → index 1bit 감소 , tag 1bit 증가

- LRU - temporal locality
- if 4way → 가능한 사용된 순서의 경우의 수 : 4! = 24 ⇒ 5비트 필요하다
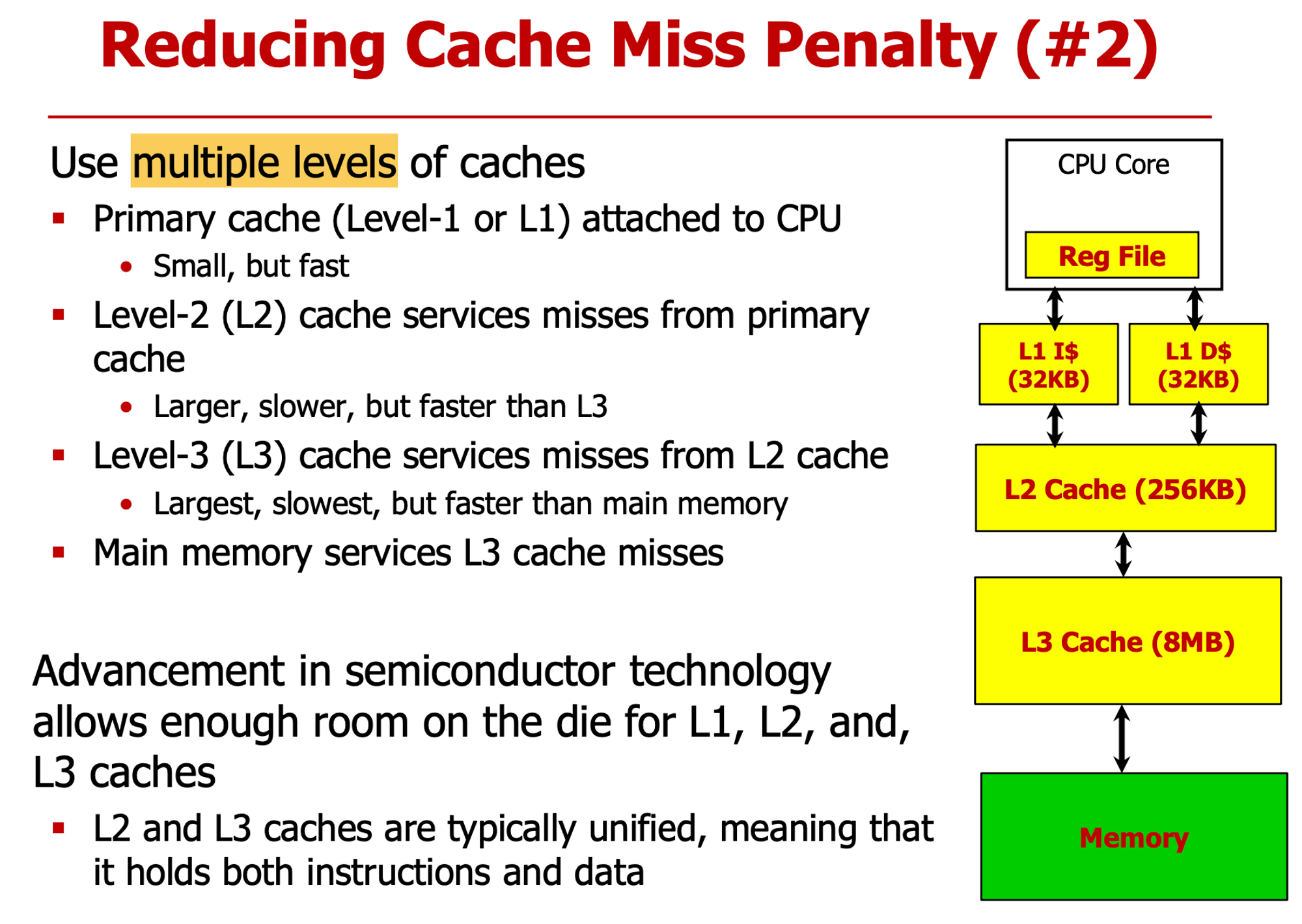
- 여러 cache를 계층적으로 구성
- L1에서 miss 나면 L2에서 해결하도록
- L1은 Structure Hazard 때문에 Instrcution/Data Cache 분리

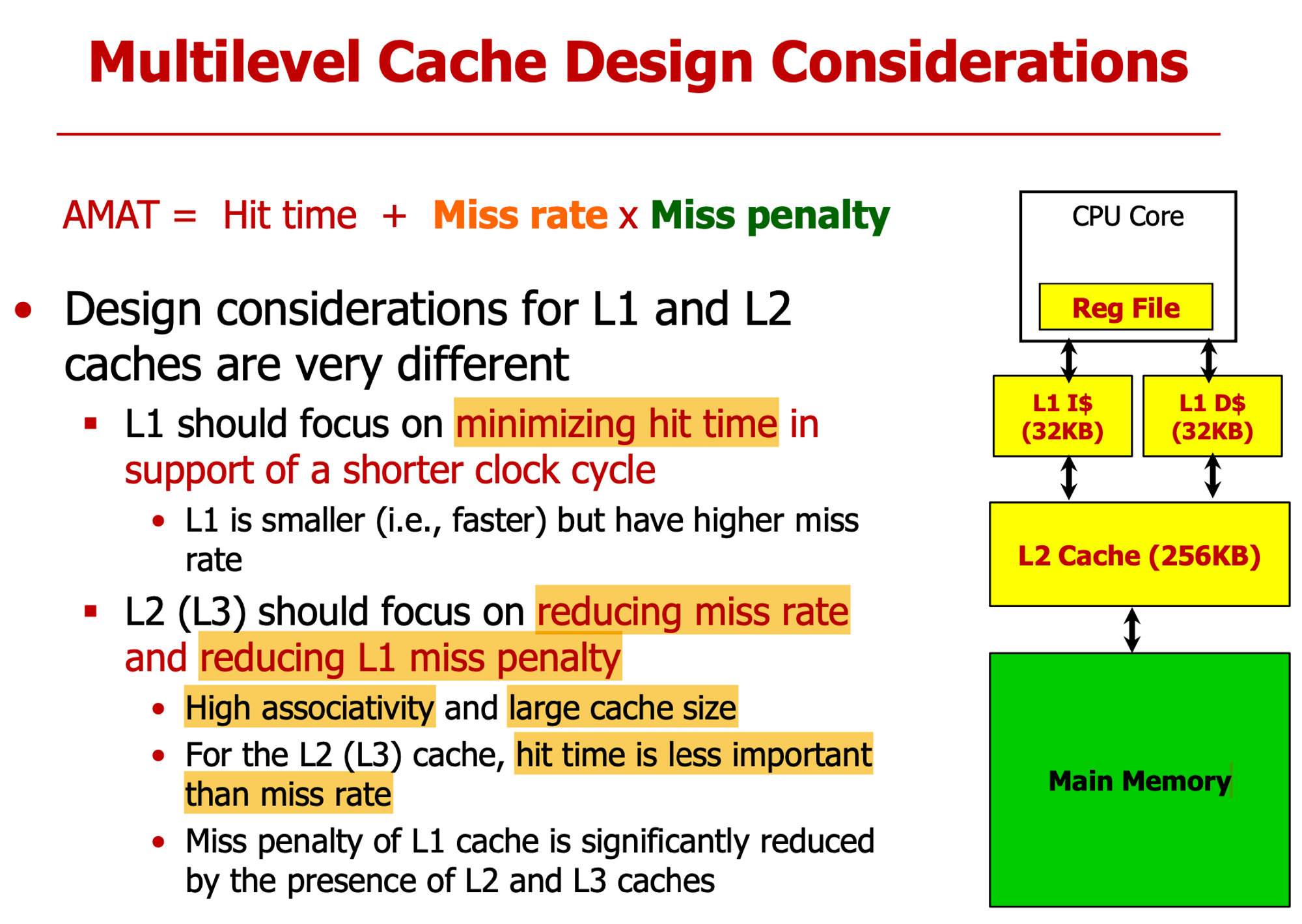
- L1 : 항상 접근, hit time 줄여야해
- L2,L3 : main memory로 접근을 최소화 만들어, conflict 줄이기 위해 associativity 키운다
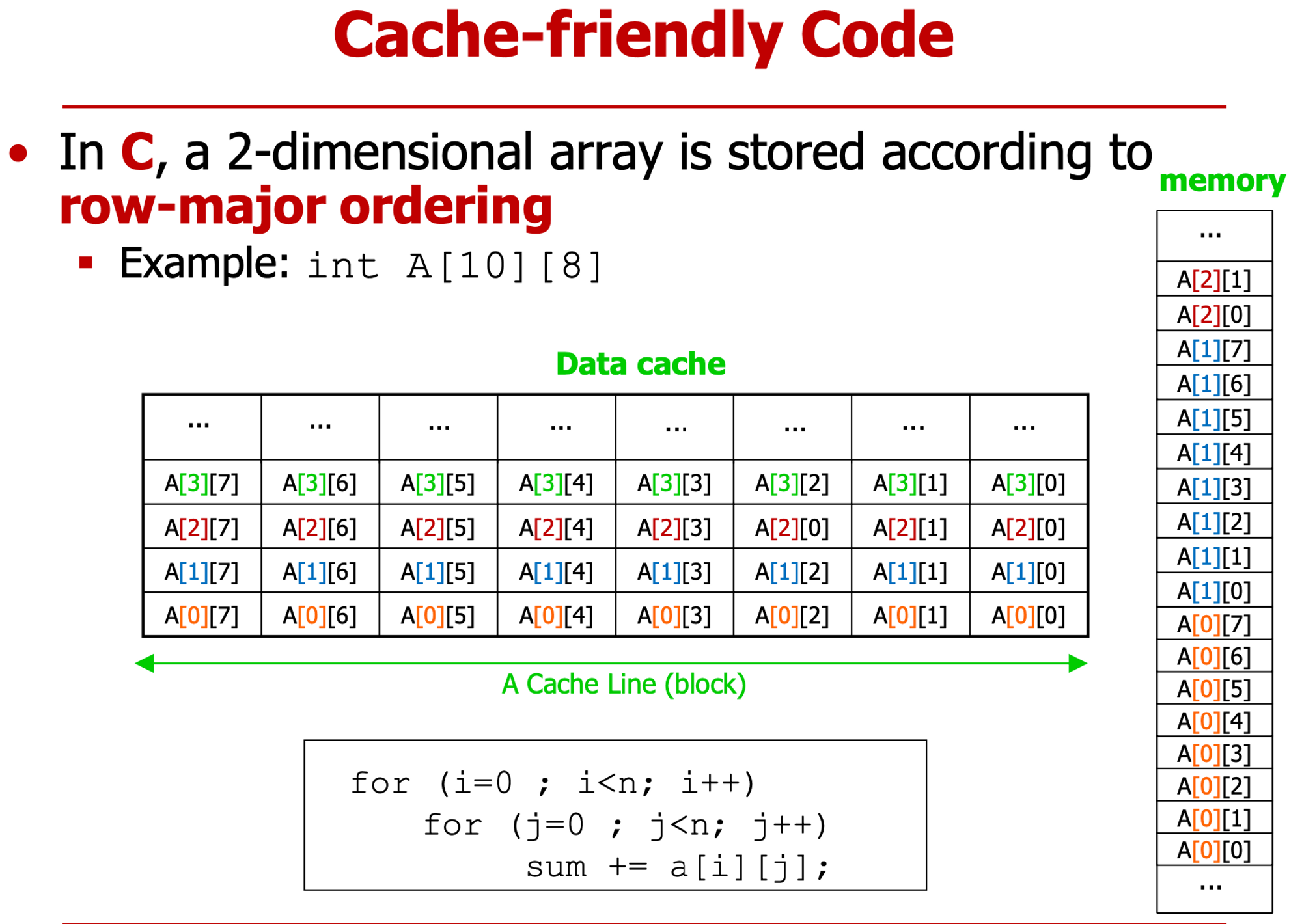
- row-major (대부분 언어) vs col-major
- row 고정 col 변경 or col 고정
- cache freindly
- a[0][0] 가져왔으면 다음에도 a사용
- cache line을 가져오는 순서에 맞게 코딩
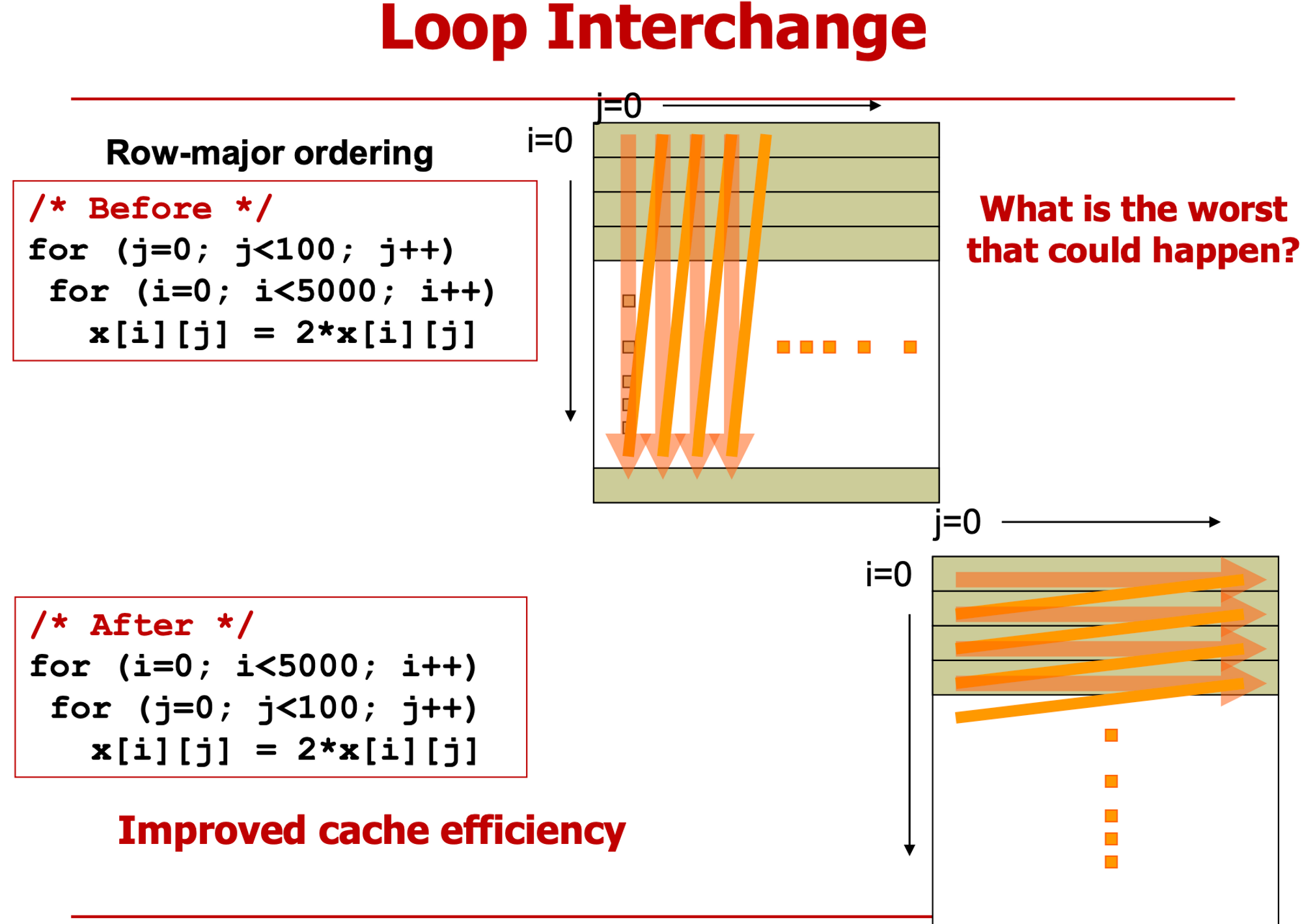
출처 : 홍익대 권건우 교수님 강의록

막상 하면 모르니까 일단 하자.
https://www.fitday.com/fitness/forums/members/chinabamboo.html
https://forum.jatekok.hu/User-chinabamboo
https://diaperedanime.com/forum/member.php?u=72899
https://www.akaqa.com/account/profile/19191784157
https://kktix.com/user/7669950
https://www.plotterusati.it/user/chinabamboo
https://mecabricks.com/en/user/chinabamboo
https://www.vidlii.com/user/chinabamboo
https://forum.battleforces.com/user/chinabamboo
https://forum.herozerogame.com/index.php?/user/119946-chinabamboo/
https://www.bikemap.net/de/u/bothbest/routes/created/
https://secondstreet.ru/profile/chinabamboo/
https://ilm.iou.edu.gm/members/chinabamboo/
https://www.atozed.com/forums/user-41726.html
https://www.buckeyescoop.com/users/0a3d1a4d-a253-466e-b0ee-9fcd0f6c026b
http://www.jbt4.com/home.php?mod=space&uid=8640686
https://petitlyrics.com/profile/chinabamboo
https://magentoexpertforum.com/member.php/147946-chinabamboo
https://crowdsourcer.io/profile/D1yIRK3l
https://savelist.co/profile/users/chinabamboo