gRPC 등장 배경
-
Server-Client Model
- 기존의 메인프레임 하나에서만 동작하는 Monolothic 구조가 PC, 워크스테이션 서버와 같은 소형 컴퓨터 장비들의 탄생함에 있어 해당 구조의 변경의 필요성이 대두
- 하나의 메인프레임을 여러 개의 워크스테이션으로 분리하기 위해 Server-Client Model 구조가 탄생하였다.
- Server와 Client간의 연결/통신이 중요해짐
-
IPC
-
프로세스들은 상호독립적이므로 서로 메모리를 공유하지 않는다. 하지만, 여러 프로세스가 협업하여 일을 처리하려면 상호 메모리에 존재하는 데이터를 공유할 필요가 생긴다. 이를 해결하기 위해 IPC라는 통신 방법론이 등장
-
이러한 IPC 기법에는 크게 socket, RPC라는 2가지 방법이 존재
-
Socket
-
Socket이란, 앞서 언급한 OSI 7 layer 구조의 Application Layer(L7)에서 Transport Port(L4)의 TCP 또는 UDP를 이용하기 위한 수단이다.
-
Socket은 protocol, IP주소, port 번호로 정의된다.
- Protocol : 통신에서 어떤 시스템이 다른 시스템과 통신을 원활하게 수용하도록 해주는 통신 규약, 약속
- IP : 전 세계 컴퓨터에 부여된 고유의 식별 주소
- Port: 포트(Port)는 네트워크 상에서 통신하기 위해서 호스트 내부적으로 프로세스가 할당받아야 하는 고유한 숫자이다. 한 호스트 내에서 네트워크 통신을 하고 있는 프로세스를 식별하기 위해 사용되는 값이므로, 같은 호스트 내에서 서로 다른 프로세스가 같은 포트 넘버를 가질 수 없다. 즉, 같은 컴퓨터 내에서 프로그램을 식별하는 번호이다.
-
Socket은 역할에 따라 Server socket, Client socket 으로 구분된다.
-
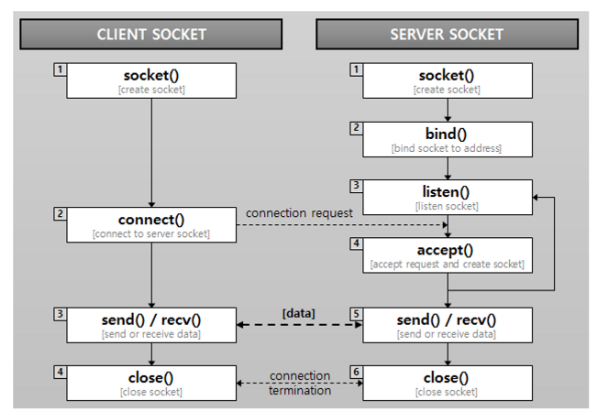
Socket 통신 흐름
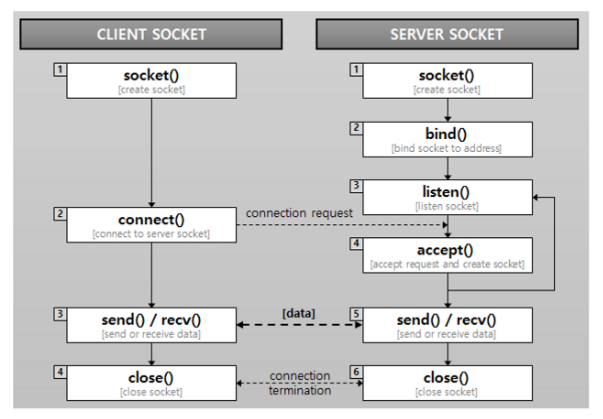
- Server Client socket의 연결 요청을 대기하고, 연결 요청이 오면 client socket을 생성하여 통신이 가능하게 한다.
- socket() 함수를 이용하여 socket 생성
- bind() 함수로 ip와 port 번호를 설정
- listen() 함수로 client의 접근 요청에 수신 대기열을 만들어 몇 개의 client를 대기 시킬지 결정
- accept() 함수를 사용하여 client와의 연결을 기다림
- Client 실제로 데이터 송수신이 일어나는 것은 client socket이다.
- socket() 함수로 socket을 연다
- connect() 함수를 이용하여 통신 할 server의 설정된 ip와 port번호에 통신을 시도
- 통신을 시도 시, server가 accept() 함수를 이용하여 클라이언트의 socket descriptor를 반환
- 이를 통해 client와 server가 서로 read(), write() 하며 통신이 끝날 때까지 이 과정을 반복
- Server Client socket의 연결 요청을 대기하고, 연결 요청이 오면 client socket을 생성하여 통신이 가능하게 한다.
-
HTTP 통신 vs Socket 통신
- HTTP 통신
- Client의 요청(Request)이 있을 때만 서버가 응답(Response)하여 해당 정보를 전송하고 곧바로 연결을 종료하는 방식
- Client가 요청을 보내는 경우에만 Server가 응답하는 단방향 통신이다.
- Server로부터 응답을 받은 후에는 연결이 바로 종료된다.
- 실시간 연결이 아니고, 필요한 경우에만 Server로 요청을 보내는 상황에 유용하다.
- 요청을 보내 Server의 응답을 기다리는 어플리케이션의 개발에 주로 사용된다.
- Socket 통신
- Server와 Client가 특정 Port를 통해 실시간으로 양방향 통신을 하는 방식
- Server와 Client가 계속 연결을 유지하는 양방향 통신이다.
- Server와 Client가 실시간으로 데이터를 주고받는 상황이 필요한 경우에 사용된다.
- 실시간 동영상 Streaming이나 온라인 게임 등과 같은 경우에 자주 사용된다.
- HTTP 통신
-
-
RPC
-
Remote Procedure Call의 약자
-
Socket의 한계를 극복하기 위해 등장
-
네트워크로 연결된 서버 상의 프로시저(함수, 메서드 등)를 원격으로 호출할 수 있는 기능이다.
-
통신 방식은 신경쓰지 않고 원격지의 자원을 내 것처럼 사용할 수 있게 해주는 기술이다.
-
RPC의 핵심 개념은 stub이다. 서버와 클라이언트는 서로 다른 주소 공간을 사용 하므로, 함수 호출에 사용된 매개 변수를 꼭 변환해줘야 한다. 안그러면 메모리 매개 변수에 대한 포인터가 다른 데이터를 가리키게 된다. 이 변환을 담당하는게 스텁이다.
-
client stub은 함수 호출에 사용된 파라미터의 변환(Marshalling, 마샬링) 및 함수 실행 후 서버에서 전달 된 결과의 변환을, server stub은 클라이언트가 전달한 매개 변수의 역변환(Unmarshalling, 언마샬링) 및 함수 실행 결과 변환을 담당한다.
-
Stub를 이용한 RPC 통신 과정
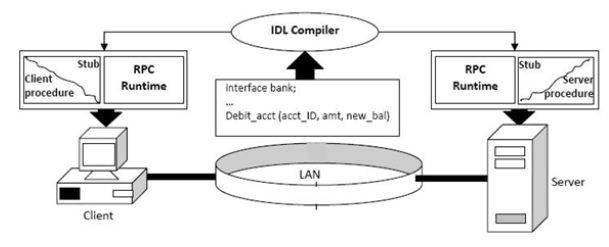
RPC 구조 (출처 :https://middlewares.files.wordpress.com/2008/04/17.jpg)
① IDL(Interface Definition Language)을 사용하여 호출 규약 정의합니다.- 함수명, 인자, 반환값에 대한 데이터형이 정의된 IDL 파일을 rpcgen으로 컴파일하면 stub code가 자동으로 생성됩니다.
② Stub Code에 명시된 함수는 원시코드의 형태로, 상세 기능은 server에서 구현됩니다.
- 만들어진 stub 코드는 클라이언트/서버에 함께 빌드합니다.
③ client에서 stub 에 정의된 함수를 사용할 때,
④ client stub은 RPC runtime을 통해 함수 호출하고
⑤ server는 수신된 procedure 호출에 대한 처리 후 결과 값을 반환합니다.
⑥ 최종적으로 Client는 Server의 결과 값을 반환받고, 함수를 Local에 있는 것 처럼 사용할 수 있습니다.
-
-
REST
- REpresentational State Transfer의 약자
- REST는 HTTP/1.1 기반으로 URI를 통해 모든 자원(Resource)을 명시하고 HTTP Method를 통해 처리하는 아키텍쳐 이다.
- 자원 그 자체를 표현하기에 직관적이고, HTTP를 그대로 계승하였기에 별도 작업 없이도 쉽게 사용할 수 있다
- 주로 XML, json으로 데이터를 구성하여 보낸다.
- REST는 일종의 스타일이지 표준이 아니기 때문에 parameter와 응답 값이 명시적이지 않고 HTTP 메소드의 형태가 제한적이기 때문에 세부 기능 구현에는 제약이 있다.
-
-
gRPC란
- gRPC는 google 사에서 개발한 오픈소스 RPC(Remote Procedure Call) 프레임워크이다. 이전까지는 RPC 기능은 지원하지 않고, 메세지(JSON 등)을 Serialize할 수 있는 프레임워크인 PB(Protocol Buffer, 프로토콜 버퍼)만을 제공해왔는데, PB 기반 Serizlaizer에 HTTP/2를 결합하여 RPC 프레임워크를 탄생시킨 것이다.
- REST와 비교했을 때 기반 기술이 다르기에 특징도 많이 다르지만, 가장 두드러진 차이점은 HTTP/2를 사용한다는 것과 프로토콜 버퍼로 데이터를 전달한다는 점이다. 그렇기에 Proto File만 배포하면 환경과 프로그램 언어에 구애받지 않고 서로 간의 데이터 통신이 가능하다.
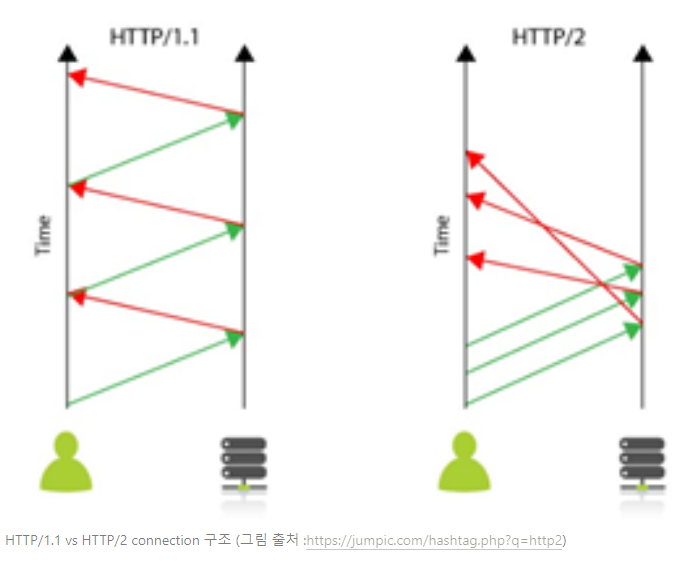
- HTTP/2
- http/1.1은 기본적으로 클라이언트의 요청이 올때만 서버가 응답을 하는 구조로 매 요청마다 connection을 생성해야만 한다. cookie 등 많은 메타 정보들을 저장하는 무거운 header가 요청마다 중복 전달되어 비효율적이고 느린 속도를 보여준다. 이에 http/2에서는 한 connection으로 동시에 여러 개 메시지를 주고 받으며, header를 압축하여 중복 제거 후 전달하기에 version1에 비해 훨씬 효율적이다. 또한, 필요 시 클라이언트 요청 없이도 서버가 리소스를 전달할 수도 있기 때문에 클라이언트 요청을 최소화 할 수 있다.
2. ProtoBuf (Protocol Buffer, 프로토콜 버퍼)
- Protocol Buffer는 google 사에서 개발한 구조화된 데이터를 직렬화(Serialization)하는 기법이다.
- 직렬화란, 데이터 표현을 바이트 단위로 변환하는 작업을 의미한다. 아래 예제처럼 같은 정보를 저장해도 text 기반인 json인 경우 82 byte가 소요되는데 반해, 직렬화 된 protocol buffer는 필드 번호, 필드 유형 등을 1byte로 받아서 식별하고, 주어진 length 만큼만 읽도록 하여 단지 33 byte만 필요하게 된다.

{kind=link}
- Proto File
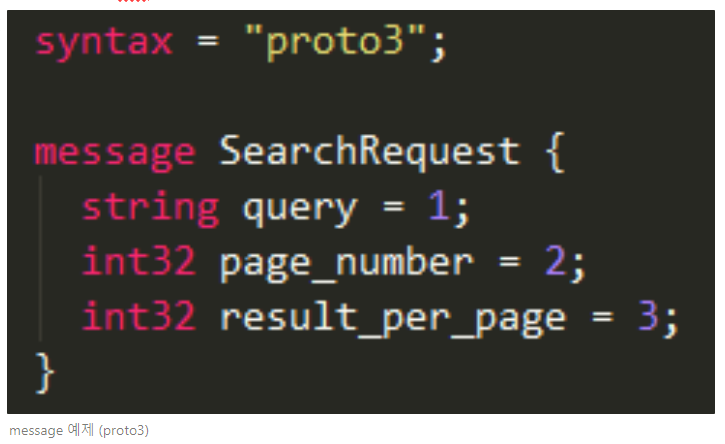
1)Message and Field
Proto File에서는 주고 받는 data들을 message 라는 것으로 정의한다. 이 메시지는 여러가지 타입의 필드로 구성된다. 아래 예시로 query, page_number, result_per_page 라는 필드를 가지는 SearchRequest 라는 메시지가 정의되어있다.
▶ Naming
message 이름은 CamelCase 형태, field 이름은 under_bar 형태로 사용할 것을 권장하고 있다. 유의할 것은 field 이름은 숫자로 시작할 수 없다는 점이다. 숫자를 표기해야 할 경우 꼭 문자 뒤에 표기해주어야한다.
ex) query_1 (o) / 1_query (x)
▶ Field Tag (= Field number)
메시지에 정의된 필드들은 각각 고유한 번호를 가지게되고 이는 Enconding 이후 binary data에서 필드를 식별하는데 사용된다. Field Tag는 최소 1, 최대 536,870,911(=229–1) 로 지정 가능하며, 19000 ~ 19999는 프로토콜 버퍼 구현을 위해 reserved 된 값이므로 사용할 수 없다.
필드 번호가 1~15일 때는 1byte, 16~2047은 2byte를 Tag로 가져간다. 때문에 자주 호출되는 필드에 대해선 1~15로 지정해두는 것이 좋다.
▶ proto2 VS proto3
위 예제에서는 첫 줄에 syntax = “proto3”을 지정해줌으로써 proto version 3의 규약을 따르겠다고 선언했다. 이를 명시하지 않으면 default로 version2 문법을 따르게 된다. 아래와 같이 지원 언어도 다르지만, message 작성 시 field rule 지정 등 문법에도 차이가 나타난다.
- Proto2 지원 언어 : C++, Java, Python, Go
- Proto3 지원 언어 : C++, Java, Python, Go, Ruby, Objectice-C, C#, JavaScript, PHP, Dart
▶ Proto File Field Rule
- required : 필수로 가져야 할 필드 (only use proto2)
- optional : 해당 필드를 가지지 않거나 하나만 가짐 (only use proto2)
- repeated : 임의 반복 가능한 필드 (번호 및 값의 순서는 보존)
- [packed=true] 옵션 : key-value 쌍 형태에서 value만 반복
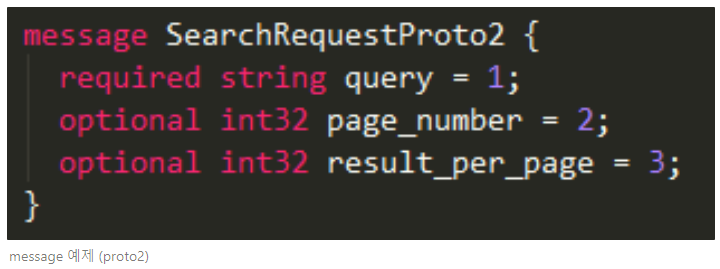
위 예시처럼 proto2의 경우 required, optional를 필드 별로 꼭 명시해주어야 한다. proto3에선 required, optional은 사라지고, repeated 만 사용됩니다. proto2도 계속 기술지원이 되고 있으나, 지원 언어 및 새로운 기능 지원을 위해 proto3을 사용할 것을 권장한다.
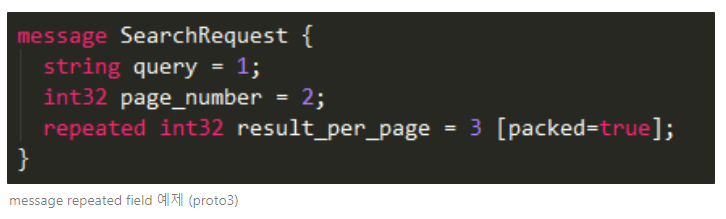
위와 같이 repeated rule을 주게되면 Field를 배열의 형태로도 사용할 수 있게 된다. 필드는 Key-Value 구조로 저장되어 repeated field를 사용할 때도 key가 계속 붙게되는데, reqeated 뒤에 packed 옵션을 주면 value만 반복하게끔 할 수 있다. 어차피 필드 번호는 바뀌지 않으니 되도록 이 옵션을 주면 보다 효율적인 Enconding이 된다.
2) Package
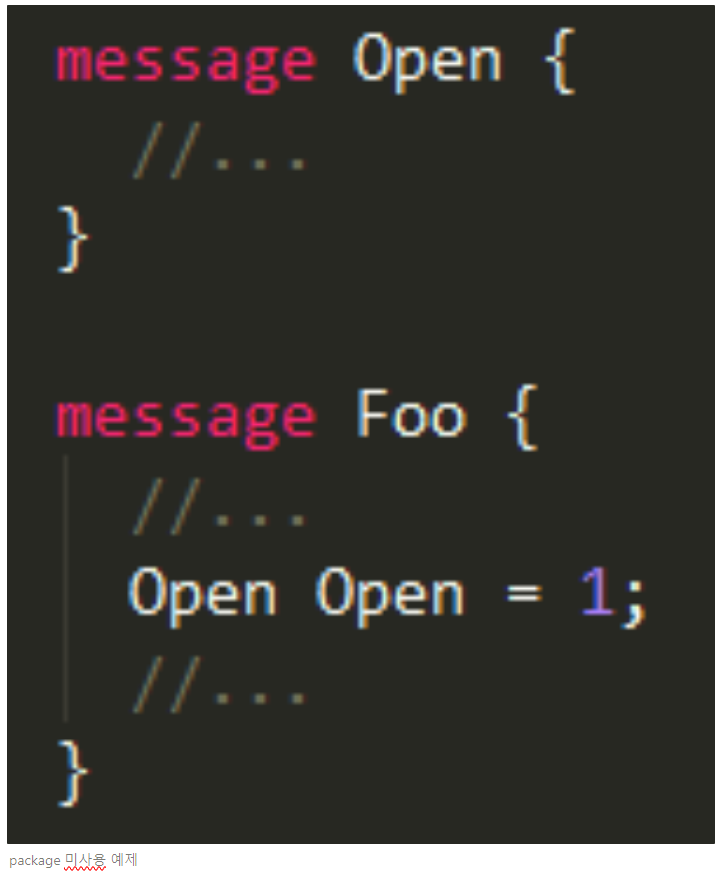
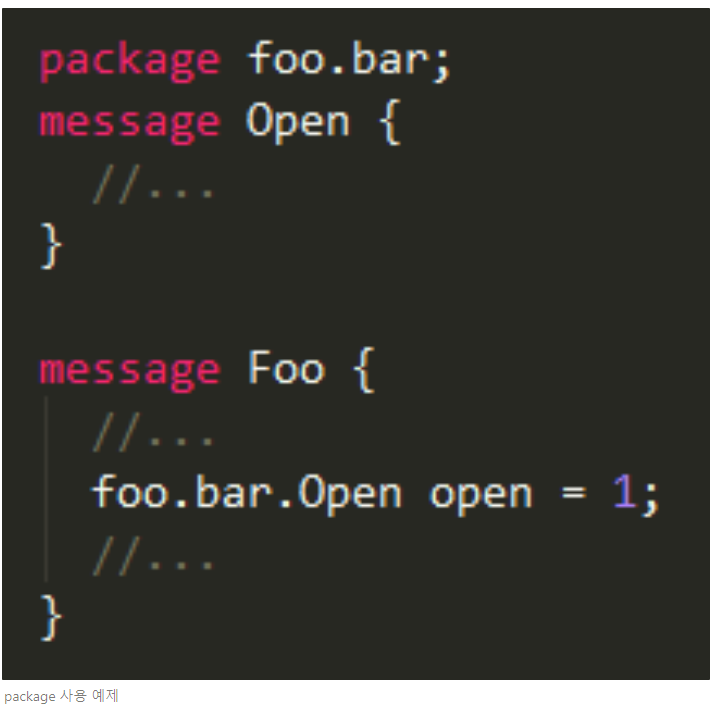
package는 message type 이름을 중첩없이 구분할 때 사용한다. 메시지 사용 시 package를 명시함으로써 필드와 명확히 구분한다. 아래 예제에서는 Open이라는 message를 타입으로 하는 field 이름을 open으로 주어 모호한 정의를 package로 구분한다. 사실 foo.bar라는 package를 굳이 쓰지 않는다고 사용이 불가한 것은 아니지만, 구성 메시지가 많다면 명확하게 구분될 수 있게 명시해 주는 것이 좋다.
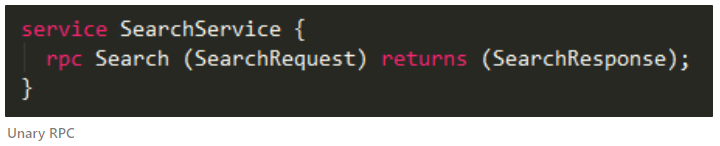
3) Service
Service는 RPC를 통해 서버가 클라이언트에게 제공할 함수의 형태를 정의한다. 서비스명과 RPC 메소드명 모두 CamelCase 형태를 권장한다. 옵션을 주지 않으면 단일 요청/응답으로 동작하지만, stream 옵션을 주면 RPC를 구현할 수 있다.