파이썬 <Getting & Knowing Data>
Q1. Data Read하라.
import pandas as pd
DriveUrl = 'https://drive.google.com/uc?id=1kXeXtquJ-TDHa6c4tx-iOwJmjufyqe2P'
df = pd.read_csv(DriveUrl)
type(df)pandas.core.frame.DataFrame
↪️ 데이터를 읽어온다.
pd - pandas를 지칭하는 별칭
Q2. 상위 5개의 행을 출력하시오.
df.head()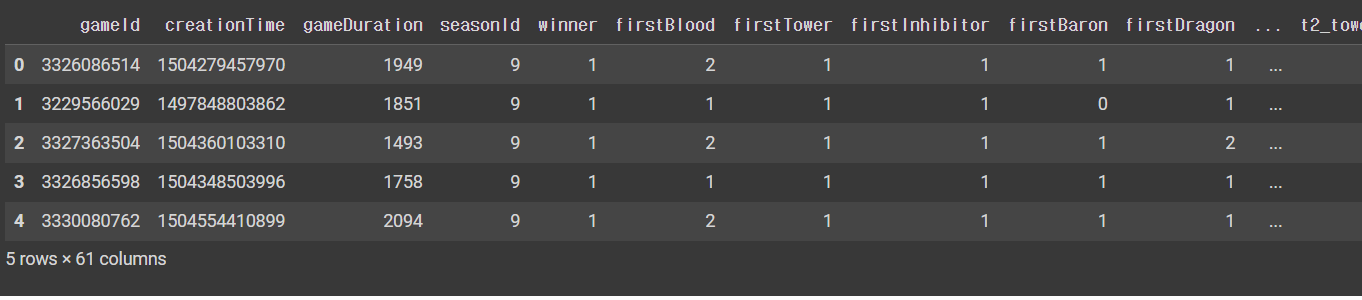
Q3. 데이터의 행과 열의 갯수를 파악하시오.
print(df.shape)(51490, 61)
↪️ 데이터 전체의 행과 열의 개수
Q4. 전체 컬럼을 출력하라
df.columns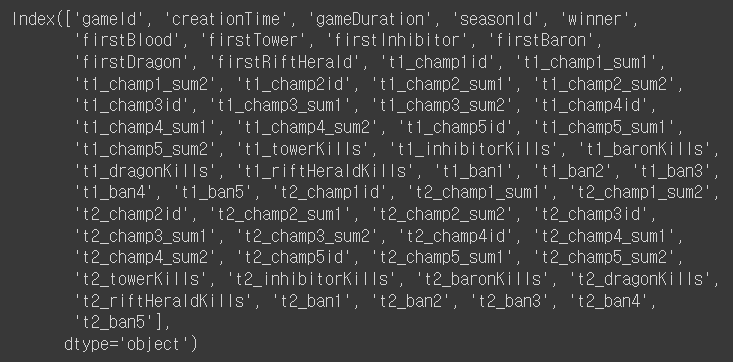
↪️ 여기서 게임 데이터임을 알 수 있다.
Q5. 6번째 컬럼을 출력하라
df.columns[5]firstBlood
↪️ 0부터 시작이라 6번째 컬럼 출력하려면 5를 입력해줘야한다.
Q6. 6번째 컬럼의 데이터 타입을 확인하라
df.iloc[:,5]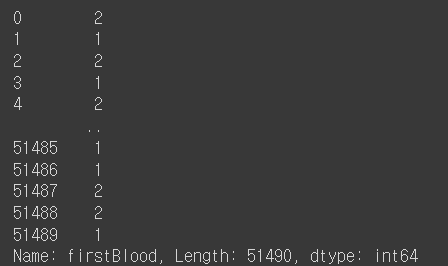
↪️모든 행에 접근하고 뒤에 6번째 열에 접근
📌iloc- 순서를 기반으로 해서 내가 원하는 데이터에 접근하는 방법
앞에 ':' 를 놓으면 모든 행을 가져오겠다는 약속의 언어
df.iloc[:,5].dtype dtype('int64')
dtype - data type의 줄임말
Q7. 데이터셋의 인덱스 구성을 확인하라
📌 인덱스
- 데이터 제일 앞단에 있어서 데이터에 대한 색인이나 목차를 검색할 수 있게 부여되는 숫자
- 특별한 처리를 안했을 때 0부터 시작을 해서 하나씩 숫자가 증가하는 방향으로 나아간다.
df.index RangeIndex(start=0, stop=51490, step=1)
↪️ 여기서 step = 1은 1씩 증가한다는 말
Q8. 6번째 컬럼의 3번째 값은 무엇인가?
df.iloc[2,5]``2```
✔️ 확인
df.head() 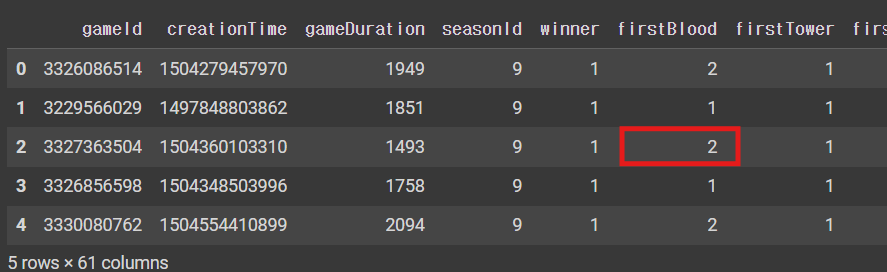
Q9. 데이터를 로드하라. 컬럼이 한글이기에 적절한 처리해줘야함
# DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/Jeju.csv'
import pandas as pd
DriveUrl = 'https://drive.google.com/uc?id=1PUmB7uspU5R-bYDtKW_6eodBTwCVYG_s'
df = pd.read_csv(DriveUrl, encoding = 'euc-kr')
type(df)pandas.core.frame.DataFrame
Q10. 데이터 마지막 3개행을 출력하라
df.tail(3)
head <-> tail(뒤에서 부터 출력한 거)
tail 할때 아무것도 안쓰면 5가 default값이다.
Q11. 수치형 변수를 가진 컬럼을 출력하라 (수치형 변수 - 숫자로 이루어진 것)
df.select_dtypes(exclude=object).columns
object 타입의 문자열 형태를 제외하고 데이터들을 선택을 하는데 그 선택한 데이터의 컬럼만 보겠다는 뜻
🗒️알아두기
select_dtypes - 우리가 데이터 타입을 선택을 하겠다는 명령어
exclude - 제외한다는 뜻
object - 파이썬 데이터프레임에서 문자열 형태의 데이터들을 말함
Q12. 범주형 변수를 가진 컬럼을 출력하라(범주형 변수 -문자열로 이루어진 형식의 데이터)
df.select_dtypes(include=object).columnsIndex(['일자', '시도명', '읍면동명'], dtype='object')
📌 참고
float - 소수점이 있는 데이터
int - 소수점이 없는 데이터
보통 exclude=object로 수치형 변수를 뽑고 include=object로
범주형 변수를 뽑는다.
Q13. 각 컬럼의 결측치 숫자를 파악하라(결측치-데이터에 값이 없다. 보통 null value 나 na라도고 한다. )
df.isnull().sum()
↪️ 널값이 있으면 실행이 안돼는 코드들이 많아서 확인을 해보는 것이다.
📌참고
isnull().sum() - 이 두개의 명령어를 같이 쓰게되면
isnull()은 널값이 있냐없냐를 알려주는 명령어
그 값을 다 더해주는 게 sum()이라는 명령어 이다.
널 값에 대한 처리를 해줘야한다.
Q14. 각 컬럼의 데이터수, 데이터타입을 한번에 확인하라
df.info()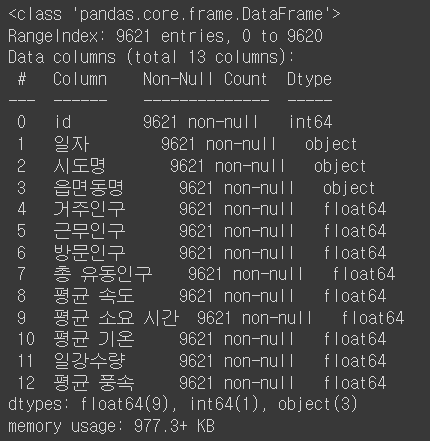
↪️ info() - 데이터를 한번에 확인가능
Q15. 각 수치형 변수의 분포(사분위, 평균, 표준편차, 최대 , 최소)를 확인하라 (기술 통계량을 확인 할 수 있는 명령어 describe())
df.describe()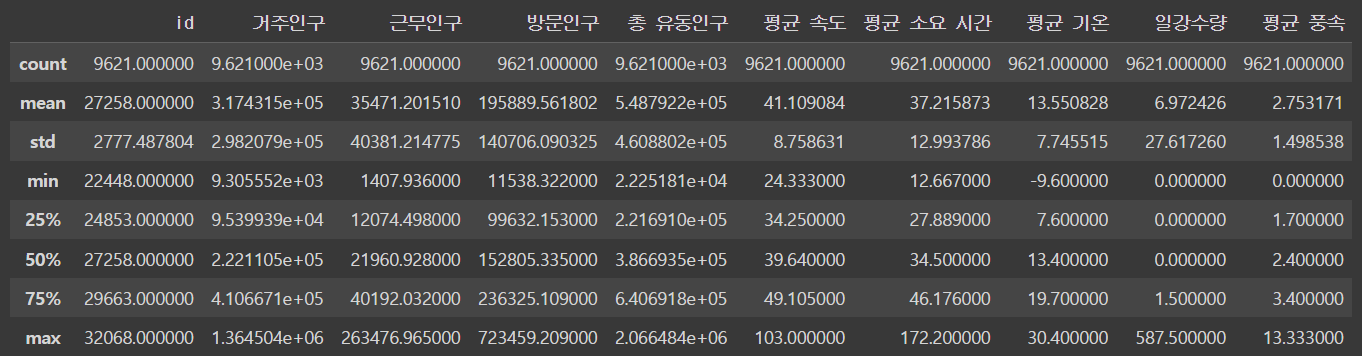
Q16. 거주인구 컬럼의 값들을 출력하라
df['거주인구']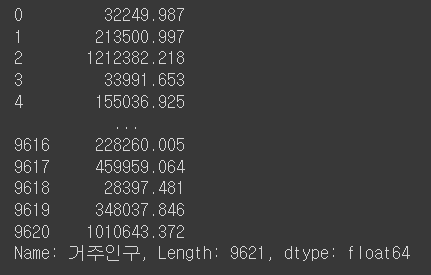
↪️ df['거주인구']-컬럼에 대한 값들을 합쳐서 확인 가능
Q17. 평균 속도 컬럼의 4분위 범위(IQR) 값을 구하여라
df['평균 속도'].quantile(0.75) - df['평균 속도'].quantile(0.25)14.854999999999997
↪️ IQR - 75% 위치에서 25% 데이터 위치를 뺀 것이다.
quantile - 그 위치의 데이터를 뽑아낼 수 있는 명령어
Q18. 읍면동명 컬럼의 유일값 갯수를 출력하라
df['읍면동명'].nunique()41
Q19. 읍면동명 컬럼의 유일값을 모두 출력하라
df['읍면동명'].unique()
📌 유일값을 모두보고 싶을 때는 nunique()가 아니라 unique()를 적어주면 된다.
