✅ 들어가기 앞서 사전지식
- Redshift 특징
1. PostegreSQL & ParAccel 데이터베이스 기반 데이터 분석 최적화
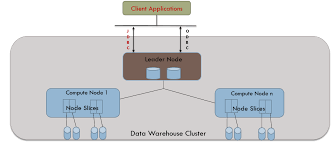
2. MPP 아키텍처 - Massively Parallel Processing - 작업 프로세스 간 시스템 자원을 공유하지 않음 - Shared nothing 아키텍처
❗️ 반대개념으로 SMP (Symmetric Multi-Processing) 가 존재
✅ 일반적으로 한 서버에 CPU , 메모리 , I/O 등 공유하게 된다면 데이터가 증가함에 따라 더 큰 인프라 자원이 필요함
✅ 제한된 자원을 공유해 수행을 하다보니 프로세스간에 race condition 발생
➡️ 저렴한 서버를 여러 대 연결하여 데이터를 분산해 처리하는 MPP 방식의 필요성 대두
3. 데이터 최적화 DW / DM 구성을 위한 데이터 적재 및 데이터 최적화 - 테이블 분산 방식 - 소트키
4. 클러스터 최적화 클러스터 관리 , 시스템 및 데이터 안정성을 높게 유지 WLM , VACUUM 구성
5. redshift 보안 - 사용자 인증 / 권한설정 -> 데이터 접근 통제 - S3 저장되는 데이터 암호화 -> 정보보안 향상 - SSL 클라이언트 연결 설정
6. column based database - 컬럼 기반 스토리지 - 집계 함수 등 컬럼 대상 작업에 최적화 - 일반적인 디스크 블록에 행으로 저장되는 방식이 아닌 컬럼 기반 스토리지를 제공함으로써 , 레코드 수가 동일하다고 가정할 때 동일한 수의 열 필드 값을 읽어오는 데 필요한 I/O 작업이 행 방향 스토리지에 비해 1/3로 줄어듭니다. 실제로 열과 행의 수가 매우 많은 테이블을 사용하면 스토리지 효율성이 더욱 커집니다.AWS DOCS https://docs.aws.amazon.com/ko_kr/redshift/latest/dg/c_columnar_storage_disk_mem_mgmnt.html
