✅ 데이터분산
레드 시프트는 테이블에 데이터를 적재하면서 테이블 분산 스타일에 따라 컴퓨팅 노드에 분산시켜 저장한다.
- 노드 간 작업량을 균일하게 분산
데이터 스큐 발생 시 성능 저하 , 노드에 저장되는 데이터를 고르게 분산시키되 데이터 크기 뿐 아니라 데이터의 조회량을 함께 분산시켜야 함- 데이터의 네트워크 전송을 최소화
레드시프트는 쿼리 수행에 데이터 로컬리티(locality)를 선호
즉 조인 쿼리를 수행하면서 다른 노드에 저장된 데이터를 네트워크로 전송하기보다 처리 대상 데이터를 미리 같은 노드로 복사한 다음 쿼리를 수행
✅ 테이블 분산 방식
- AUTO (기본 자동 설정)
- EVEN : 데이터를 각 슬라이스에 라운드로빈(RR) 방식으로 균등하게 저장한다. 조인에 참여하지 않는 테이블이거나 키 분산 또는 전체 분산을 적용하지 못할 때 사용
- KEY : 테이블 크기가 크고 , 변동이 잦으면서 자주 참여하는 팩트(fact) 테이블 , 디멘전(Dimension) 테이블에 적합하다.
- ALL : 테이블의 전체 데이터를 모든 노드에 복제, 각 컴퓨팅 노드의 슬라이스 중 하나를 선택해 저장한다 .
클러스터의 노드 수 만큼 데이터 크기가 늘어나므로 그만큼 많은 디스크 공간을 사용하게 되고, 데이터 적재와 변경을 모든 노드에서 작업해야 하므로 데이터 변경이 잦은 테이블에는 적합하지 않다. (ex: 우편번호 )
✅ 소트키 (Sort Key)
데이터를 정렬하고 디스크에 저장
정렬 비율이 높은 테이블은 쿼리 플래너가 보다 정확한 실행 게획을 생성할 수 있다 -> 레드시프트의 경우 존맵 (Zone map) 사용
각 데이터 별 블록에 컬럼별 데이터 범위 (최댓값 ,최솟값) 를 저장해서 검색하는 방법
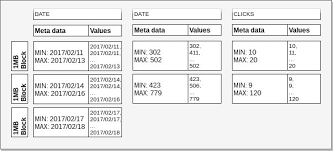
✅ 컴파운드 소트키
테이블에 정의된 소트키 순서로 데이터를 정렬해서 저장
1. 첫 번째 소트키로 데이터를 정렬
2 컬럼 값이 같으면 다음 소트키 컬럼으로 정렬
ex ) 대여소 번호 , 대여 일자
❗️ 컴파운드 소트키는 소트키를 선언하는 순서가 매우중요
그러나 조건절에서 컬럼 순서는 중요하지 않다. 성능 차이는 없음
SORTKEY(A,B)="WHERE A=1 AND B=2"="WHERE B=2 AND A=1"
✅ 인터리브 소트키
인터리브 정렬 키는 정렬 키에서 각 열, 즉 열의 하위 집합에 똑같은 가중치를 부여합니다
인터리브 정렬은 WHERE 절에서 1개 이상의 정렬 키를 기준으로 필터링하여 선택의 폭이 매우 제한적인 쿼리를 실행할 때 가장 효과적입니다(예: select c_name from customer where c_region = 'ASIA'). 이때는 제한적으로 정렬되는 열의 수와 함께 인터리브 정렬의 이점도 커집니다.
- 인터리브 소트키에 좋은 후보 컬럼을 선정하기 위해서는 STV_BLOCKLIST 시스템 뷰를 조회해 블록 수가 가장 많고 가능한 모든 슬라이스에 분산돼 있는 컬럼을 선정할 수 있음.
