Redshift DW를 운영하는 과정에서 발생하는
테이블 성능 개선 및 최적화 방안에 대해서 작성하였다.
MPP Architecture
Massively Parallel Processing
: 하나의 큰 작업(쿼리, 데이터 처리)을 여러 개의 노드(Node)로 분산 처리하는 아키텍처
각 노드는 자신만의 CPU, 메모리, 스토리지를 갖고 독립적으로 동작
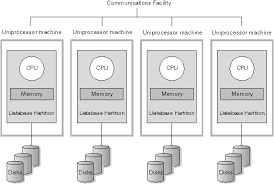
Redshift는 MPP 아키텍처로 이루어져있다.
각 노드는 독립적으로 자원을 보장 받으며 데이터를 처리 할 수 있다.
DB 서버 1대에 병목현상이 발생하면 사용에 제한이 있기에
여러개의 서버와 스토리지로 분할하여 각 노드에서 분산 처리를 진행한다.
| 장점 | 설명 |
|---|---|
| 선형적 확장성(Scalability) | 노드 추가 시 성능이 비례적으로 증가 → 데이터가 커져도 노드를 늘리면 대응 가능 Scale Out |
| 고성능 처리 | 수십~수백 개 노드가 동시에 연산 → 대규모 데이터 집계, 조인, ML 학습 속도 ↑ |
| 병렬 쿼리 실행(Paralleism) | 대형 쿼리도 작은 단위로 나눠 병렬 처리 → 응답 시간 단축 |
| 분산 스토리지 | 데이터를 분산 저장하여 I/O 병목 최소화 |
| Fault Tolerance | 일부 노드 장애 시에도 전체 서비스 중단 없이 복구 가능 (Snowflake, BigQuery 등) Shared Noting |
컬럼 기반(Columnar) 스토리지
컬럼 기반 스토리지란 같은 컬럼(column)의 값들이 디스크에 연속적으로 저장되는 형태이다. → 분석성(OLAP)에 유리
일반적인 RDBMS는 (Oracle)과 같은 raw기반 스토리지는 한 행에 모든 컬럼이 디스크에 연속적으로 저장되어 OLTP에 적합하다
| 구분 | Row-Oriented (행 기반) | Column-Oriented (열 기반) |
|---|---|---|
| 저장 방식 | 한 행 단위로 모든 컬럼 저장 | 동일 컬럼 값들을 모아서 저장 |
| 장점 | - 단일 행 조회 빠름 - 트랜잭션 처리 적합(INSERT, UPDATE) | - 특정 컬럼만 읽을 때 빠름 - 고압축률 가능 - 대규모 집계/분석에 최적 |
| 단점 | - 많은 컬럼 중 일부만 필요해도 전체 읽음 - 압축률 낮음 | - 단일 행 조작 비효율적 - UPDATE/DELETE 성능 낮음 |
| 활용 사례 | OLTP 시스템 (은행, 쇼핑몰 주문 처리) | OLAP 시스템 (DW, BI, 분석 플랫폼) |
컬럼 기반 스토리지를 사용할때는 몇가지 기본적인 규칙이 있는데,
정확히 읽고 type casting을 최소화 하는것이다.
| 구분 | 특징 | 사용 기본 사항 |
|---|---|---|
| 컬럼 단위 I/O | 필요한 컬럼만 읽어서 디스크 I/O 최소화 | SELECT * 지양, 필요한 컬럼만 조회 |
| 데이터 압축 (Encoding) | 같은 타입이 연속 저장되어 압축률 높음 | ANALYZE COMPRESSION 활용, COPY 자동 압축 권장, 숫자형→AZ64, 문자열→LZO |
| Zone Map (Predicate Pushdown) | 블록별 최소/최대값 메타데이터 기반 스캔 최적화 | WHERE 절에 범위 조건 (BETWEEN, >=, <=) 사용, 카디널리티 높은 컬럼 필터링 |
데이터 분산 목표
앞서 MPP 아키텍처와 컬럼 기반 스토리지에서 설명하였다 .
결국 Redshift 운영의 방점은 자원의 낭비없이 모든 Node와 slice를 활용하는 것이다.
1. 병렬처리 극대화를 위해 데이터를 균등하게 분배
2. 노드의 처리양
3. 쿼리 처리 중 데이터 이동 최소화 (Zone Map)
Redshift 분산 스타일
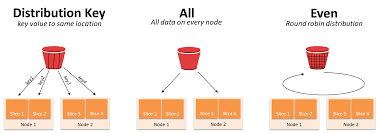
redshift 는 테이블을 생성할때 diststyle을 설정하게 된다.
설정에 따라 분산 방식이 달라지게 된다.
운영하는 사이트의 비즈니스를 잘 이해하고 있다면 무리없이 설정이 가능하지만 그게 아니라면 적절한 가이드 아래에 테이블 설계가 필요하다 .
| 분산 방식 | 동작 방식 | 장점 | 단점 | 적합한 경우 |
|---|---|---|---|---|
| KEY | 지정한 분산 키 컬럼 값을 해시(Hash)하여 노드/슬라이스에 분산 저장 | - 조인 시 동일한 키 기준으로 데이터가 같은 노드에 위치 → 네트워크 I/O 최소화 - 대규모 테이블 조인 최적 | - 분산 키 컬럼 값이 불균형하면 데이터 스큐(Skew) 발생 가능 | 조인 조건에 자주 쓰이는 컬럼 (예: customer_id, product_id) |
| ALL | 테이블 전체 데이터를 모든 노드에 복제 | - 소규모 Lookup 테이블 조인 시 네트워크 I/O 없음 | - 대규모 테이블은 복제 비용↑ (저장 공간 낭비, 로드 시 느림) | 작은 차원 테이블 (예: 지역 코드, 카테고리 코드) |
| EVEN | 라운드 로빈(Round Robin) 방식으로 행을 균등하게 분산 | - 데이터가 균등 분산되어 스큐 방지 | - 조인 시 대부분 네트워크 I/O 발생 (노드 간 데이터 재분배 필요) | 분산 키를 특정하기 어려운 경우, 임시 테이블 |
| AUTO | Redshift가 테이블 크기 및 사용 패턴을 기반으로 자동 선택 | - 관리 편리 (작은 테이블 → ALL, 큰 테이블 → EVEN) | - 원하는 방식 강제 불가 (자동 선택이 항상 최적 아닐 수 있음) | 권장 기본값 (특히 초기에 스키마 설계 시) |
잘못된 key 설정은 자칫하면 skew가 발생되며 이를 피하기 위해서는
높은 카디널리티 (high cardinality)를 가지는 컬럼을 key로 설정해줘야 한다.
Zone Maps & Sort Key
Redshift는 데이터를 컬럼별로 columnar block에 저장한다. (보통 1MB 단위 블록)
Zone Map 생성
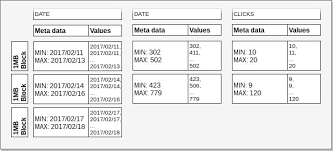
각 블록마다 해당 블록 내 최소값(MIN), 최대값(MAX) 정보를 메타데이터로 저장합니다.
즉, Block = [Min, Max] 구간을 갖게 됨.
쿼리 실행 시 블록 스킵
예: WHERE order_date BETWEEN '2023-01-01' AND '2023-01-31'
Redshift는 각 블록의 Zone Map을 확인해서,
조건에 해당하지 않는 블록은 읽지 않고 스킵합니다. (I/O 절감)
즉, 인덱스는 아니지만 프루닝(pruning) 효과를 제공.
| Block | Min | Max |
|---|---|---|
| 1 | 2022-01-01 | 2022-03-31 |
| 2 | 2022-04-01 | 2022-06-30 |
| 3 | 2022-07-01 | 2022-09-30 |
SELECT COUNT(*)
FROM orders
WHERE order_date BETWEEN '2022-07-10' AND '2022-07-20';Redshift는 Zone Map을 확인 후 Block 1, 2는 스킵하고 Block 3만 읽음.
따라서 전체 스캔보다 훨씬 빠름.
SORT KEY 설정이 중요
Zone Map은 Sort Key 기준으로 효과적
예를 들어 order_date 기준으로 Sort Key를 설정하면,
날짜 순으로 블록이 쌓이기 때문에 기간 조건 WHERE에서 스킵 효과 극대화.
sort key가 여러개라면 낮은 카디널리티 -> 높은 카디널리티 순서로 작성
Table Skew 확인하기
최초에 설계를 잘못해서 노드간 분산이 잘 이루어지지 않았다.
하지만 괜찮다.
svv_table_info를 통해 현재 설정된 key정보와
skew_rows를 확인 기준치를 잡아 일정 기준치를 넘는 table 대상으로
distkey 수정 필요
SVV_TABLE_INFO.skew_rows
1.00 ~ 1.10 → 사실상 균등 (정상, 개선 불필요)
1.10 ~ 2.00 → 경미한 skew, 대부분 무시 가능
2.00 ~ 4.00 → 다소 skew 있음 → 대용량 fact 테이블이면 개선 검토
4.00 이상 → 심각한 skew → 반드시 개선 필요
select "table", encoded, diststyle, sortkey1, skew_sortkey1, skew_rows
from svv_table_info
order by 1;
table | encoded | diststyle | sortkey1 | skew_sortkey1 | skew_rows
---------------+---------+-----------------+--------------+---------------+----------
category | N | EVEN | | |
date | N | ALL | dateid | 1.00 |
event | Y | KEY(eventid) | dateid | 1.00 | 1.02
listing | Y | KEY(listid) | dateid | 1.00 | 1.01
sales | Y | KEY(listid) | dateid | 1.00 | 1.02
users | Y | KEY(userid) | userid | 1.00 | 1.01
venue | N | ALL | venueid | 1.00 |
(7 rows)Alter table ~ 구문을 이용해서 설정된 키를 수정한다.
ALTER TABLE "TABLE_NAME"
ALRER DISTSTYLE KEY DISTKEY "COLUMN_NAME"