이 글은 Set에 대한 저의 선입견으로 인해 생긴 오개념과 해결 과정에서 학습한 내용을 공유하고자 작성되었습니다.
문제 상황
백트래킹 문제를 풀던 도중 비교적 간단한 기능 구현을 위해 채택한 자료 구조의 차이가 생각보다 큰 영향을 끼치는 것을 경험했습니다.
- 문제 설명
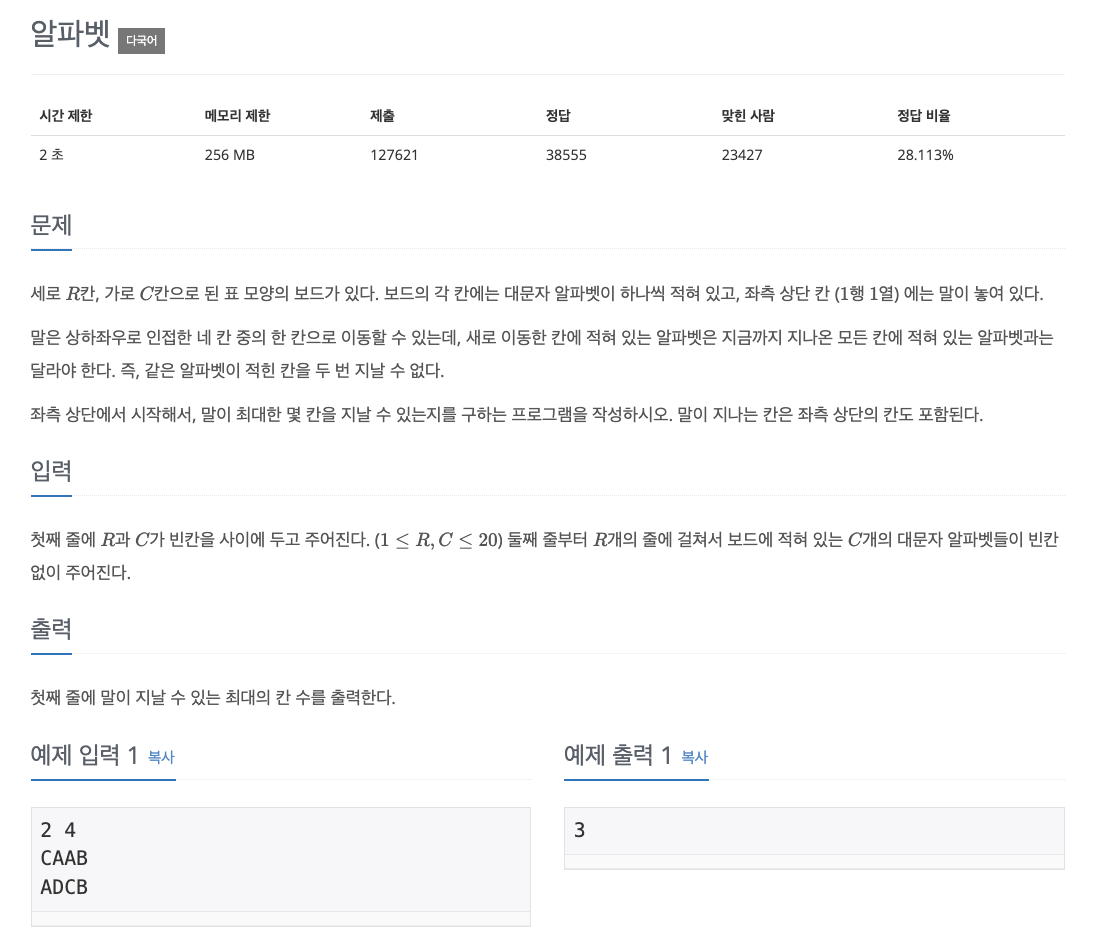
- 문제 요약: (0, 0) 좌표에서 출발해 알파벳 대문자로 구성된 보드를 이미 방문한 적 있는 문자를 방문하지 않고 최대 몇 번 이동할 수 있는가?
- 위 문제를 풀이하기 위해 백트래킹 조건으로 이미 방문한 적이 있는 문자를 Set을 이용해 판별하려고 했습니다.
- Set 자료 구조 사용 이유
- 내장 메서드(add)를 이용하면 중복처리를 간단하게 할 수 있음. (Array와 같은 자료구조를 선택할 경우 중복처리를 위한 구현이 추가적으로 필요하다.)
- 해쉬 알고리즘을 이용한 자료구조이기 때문에 시간 복잡도가 짧다: 추가(O(1)), 요소 조회(O(1))
- Set 자료 구조 사용 이유
- 하지만 Set을 이용하면 시간 초과가 발생했습니다.
해결: Array를 이용한 방문처리
- 위 문제의 경우 보드에서 주어질 수 있는 문자가 A-Z로 26개로 고정되어 배열로도 충분히 방문 처리가 가능합니다.(ex. A → visitedArr[0] = true)
의문점 발생
- Set하고 Array를 통해 구현하고자 하는 행위는 방문처리와 관련된 행위들로 같다. 그리고 시간 복잡도도 같다.
- 시나리오 별, Set 시간 복잡도
- 방문처리 → Set.prototype.add(): O(1)
- 방문처리 제거 → Set.prototype.delete(): O(1)
- 방문여부 조회 → Set.prototype.has(): O(1)
- 시나리오 별, Array 시간 복잡도
- 방문처리 → Array[idx] = true 할당: O(1)
- 방문처리 제거 → Array[idx] = false 할당: O(1)
- 방문여부 조회 → Array[idx] 값 조회: O(1)
- 시나리오 별, Set 시간 복잡도
❓그런데도 문제는 Set을 이용하면 시간초과가 발생하고 Array를 사용하면 통과가 된다.
의문점을 발생시킨 오개념: 시간 복잡도는 수행시간과 같다.
- 시간 복잡도가 로직의 수행시간이 비례한 것은 맞다.
- 하지만
실제 수행시간 → 해당 시간복잡도 * 해당 행위에 소요되는 시간일 것이다.- 위에서 설명한 시나리오에 따른 시간복잡도는 같더라도 내부적으로 처리되는 과정이 다르기 때문에 자료 구조 별 소요시간이 다를 수밖에 없다. 앞서 제시한 시나리오 중 Set 자료구조의 add 메서드의 내부 동작을 살펴보자.
Set의 명세로 보는 방문처리 시, 내부 동작
Set.prototype.add의 내부 동작을 살펴보기 전에 추상 연산에 대한 이해가 필요하다.
- RequireInternalSlot(객체, [[SetData]])

- 요약: 첫 번째 인자의 객체에 두 번째 인자로 주어지는 내부 슬롯이 존재하는지 여부를 확인하는 추상 연산(Abstract Operation)
- 내부 슬롯: ECMAScript 객체의 내부 상태를 나타내는 특수한 속성으로, 일반적으로 외부에서 접근할 수 없다.
ECMAScript® 2025 Language Specification-RequireInternalSlot
- CanonicalizeKeyedCollectionKey(Key)
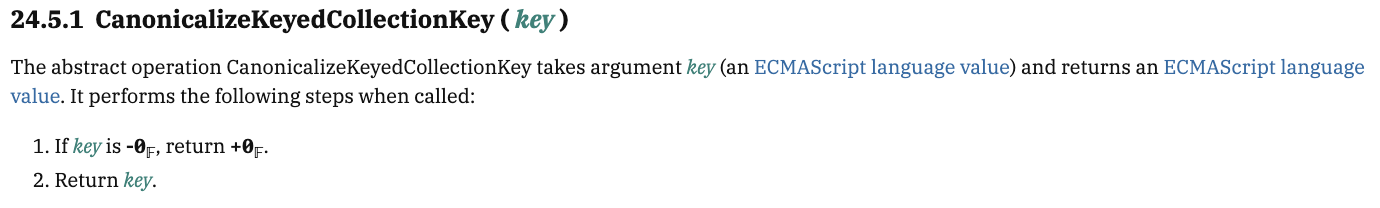
- 요약: 부동 소수점 숫자에서 발생할 수 있는 음과 양의 0을 하나의 값으로 표준화하는 추상연산.
- IEEE 754 표준에서 부동 소수점 숫자 -0와 +0이 다르게 표현될 수 있지만, 키드 컬렉션(KeyedCollection: Map, Set)에서 이 두 값을 동일하게 취급해야 한다.
1. 키가 음의 0(-0𝔽)인 경우, 이를 양의 0(+0𝔽)으로 변환합니다.- 그 외의 경우에는 키를 그대로 반환합니다.
ECMAScript® 2025 Language Specification-CanonicalizeKeyedCollectionKey
- Set.prototype.add 내부 동작

this값을S로 설정합니다(S는 메서드가 호출된Set객체).RequireInternalSlot(S, [[SetData]])를 수행하여S가[[SetData]]내부 슬롯을 가지고 있는지 확인합니다. 이 슬롯이 없으면TypeError예외를 던집니다.value를CanonicalizeKeyedCollectionKey(value)로 설정하여,value를 표준화합니다.S.[[SetData]]의 각 요소e에 대해,e가EMPTY가 아니고SameValue(e, value)가 참이면S를 반환합니다. 즉,Set에 이미 같은 값이 존재하면 아무 작업도 하지 않고S를 반환합니다.value를S.[[SetData]]에 추가합니다.- 최종적으로
S를 반환합니다. 이는 메서드 체이닝을 가능하게 합니다.
ECMAScript® 2025 Language Specification-Set Object
Array의 방문처리 시, 내부 동작
- Array의 시작 주소에서 index에 대응되는 메모리 공간에 true 할당.
Set의 add가 훨씬 복잡한 내부 동작을 수반한다. 그렇기 때문에 앞서 언급한 실제 수행 시간은 Set.prototype.add를 사용했을 때 더 클 수 있다.
실험: 방문처리 시나리오 처리 시, Array, Set 실행시간 비교
- 실행 환경: 백준의 실행 환경과 맞춰 시간을 측정했다.

- 명령어 :
nvm run 16.13.1 --stack-size=65536 testArrayAndSetAddDelete.js > testResult.txt - 테스트의 결과를 testResult.txt에 저장.
- 시뮬레이션 설계
- A에서 Z에 해당하는 Array의 인덱스, Set의 원소를 랜덤으로 접근.
- 방문처리
- Array: true / false 방문 여부 토글
- Set: add, delete로 방문 여부 토글
- 10회 반복 시행 후 평균 값 도출
const N = 10_000_000;
// N을 1000만으로 설정
function arrTest() {
const arr = new Array(26).fill(true);
for (let i = 0; i < N; i++) {
const randomIdx = parseInt(Math.random() * 26);
// 0부터 25까지 랜덤으로 인덱스 접근
arr[randomIdx] = !arr[randomIdx];
// 해당 인덱스
}
}
function setTest() {
const set = new Set();
for (let i = 0; i < N; i++) {
const getRandomChar = parseInt("A".charCodeAt() + Math.random() * 26);
const char = String.fromCharCode(getRandomChar);
if (set.has(char)) {
set.delete(char);
} else {
set.add(char);
}
}
}
let sum1 = 0;
for (let i = 0; i < 10; i++) {
const arrStartHour = new Date();
arrTest();
const arrEndHour = new Date();
const tt1 = arrEndHour - arrStartHour;
console.log(`arr: ${i}` + "times:" + tt1);
sum1 += tt1;
}
console.log(`10 times average: ${sum1 / 10}`);
let sum2 = 0;
for (let j = 0; j < 10; j++) {
const setStartHour = new Date();
setTest();
const setEndHour = new Date();
const tt2 = setEndHour - setStartHour;
console.log(`set: ${j}` + "times:" + tt2);
sum2 += tt2;
}
console.log(`10 times average: ${sum2 / 10}`);
- 실행 결과: 같은 시나리오 아래, 약 1.6배 정도 실행시간의 차이가 발생했다.
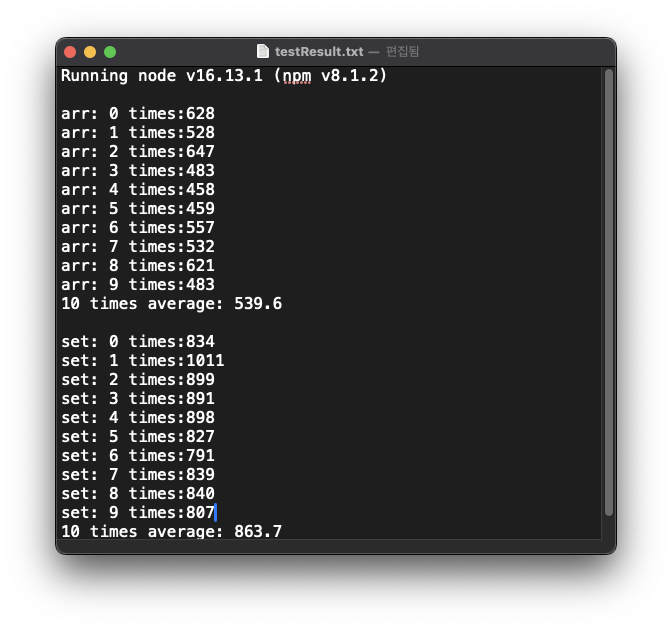
같은 시나리오 아래, 같은 시간복잡도를 가진 동작임에도 거의 1.6배 정도 실행시간의 차이가 발생했다.
그럼에도 Set을 사용해야하는 이유.
- 코드를 읽는 사람으로 하여금 직관적으로 해당 자료구조의 특징을 알 수 있게 한다. Set의 경우 담긴 값들이 중복 처리되어 있을 것이라는 것을 알 수 있습니다.
- 이 문제에서는 요소의 후보군의 종류가 고정되어 있어 배열의 인덱스로 처리가 가능했지만, 후보군의 종류가 무궁무진한 경우 이를 처리하기 어렵다. 또는 이를 처리하기 위해 해쉬 알고리즘을 이용해 직접 중복처리를 구현해야하는데, 이보다는 내장 메서드를 이용하는 것이 구현 시간 절약이나 신뢰성 차원에서 더 좋다고 생각한다.
- ECMAScript 2025부터 기존에 존재하지 않았던, 집합의 연산을 메서드로 지원하기 시작했다. 기존에는 폴리필을 직접 구현 후 사용 가능했지만, 내장 메서드가 등장함으로써 집합연산에 있어 Set은 더욱 강점을 가지게 되었다.
- 교집합, 합집합, 차집합, 대칭차집합 등…
- 관련 자료: (번역) 자바스크립트 Set 의 새로운 메서드
반성
- 기계적으로 시간 복잡도를 계산하면 안되겠다. 문제 풀이를 위해 복잡도를 계산해 알고리즘을 선택하기도 하고, 구현의 검증을 위해 시간 복잡도를 계산하기도 했다. → 경험상 이를 통해 많은 경우 문제를 해결할 수 있었다. 하지만 문제에서 요구하는 시간 제한은 문제 풀이를 위해 채택한 알고리즘의 시간 복잡도가 아닌 실제 채점 서버에서 해당 로직을 실행한 시간의 제약사항이다.
- 실제 서비스에서도 알고리즘의 시간 복잡도와 자료구조의 특성을 고려해 성능 개선에 대한 아이디어를 얻을 수있다. 다만 성능적 개선이 제대로 이뤄졌는지 검증이 꼭 필요하다.
결론
- 시간 복잡도가 로직의 수행시간이 비례한 것은 맞다.
- 하지만 시간 복잡도가 같다고 수행시간이 같은 것은 아니다.
- Hash 알고리즘으로 구현된 컬렉션들이 무조건 빠른 것은 아니다.
- 현실은 쓰다. 서버의 비용은 시간복잡도가 아니라 실제 수행 시간에 달려있다. 알고리즘, 자료구조를 통한 성능개선을 추구하되 꼭 검증을 거쳐 실제로 성능 개선이 이뤄졌는지 검증하자.

자신을 개발하는 개발자!